






目录
LocalGPT的简介、安装、使用方法
1、工作原理是什么?
2、如何选择不同的LLM模型?
3、Star History
4、免责声明
LocalGPT的安装
1、环境设置
2、Docker部署
3、测试数据集
摄入您自己的数据集的说明
4、向您的文档提问,本地方式!
5、在CPU上运行
6、为M1/M2运行量化
故障排除
7、运行UI
8、系统要求
Python版本
C++编译器
对于Windows 10/11
NVIDIA驱动问题:
LocalGPT的使用方法
1、基础用法
2、进阶用法
LocalGPT的简介、安装、使用方法
2023年5月29日,Prompt Engineering发布了LocalGPT项目,主要是受到原始privateGPT的启发。这里的大部分描述都受到原始privateGPT的启发。在这个模型中,我用Vicuna-7B模型替换了GPT4ALL模型,并且我们使用了InstructorEmbeddings,而不是原始privateGPT中使用的LlamaEmbeddings。无论是嵌入还是LLM都将在GPU上运行,而不是CPU。如果您没有GPU,它也支持CPU(请参见下面的说明)。
在没有互联网连接的情况下,使用LLMs的能力向您的文档提问。100%私密,任何时候都不会有数据离开您的执行环境。您可以在没有互联网连接的情况下摄取文档并提问!使用LangChain和Vicuna-7B(加上很多其他内容!)以及InstructorEmbeddings构建。
有关项目的详细概述,请观看以下视频:
>> 详细的代码演示:
https://www.youtube.com/watch?v=MlyoObdIHyo&feature=youtu.be
>> 使用LocalGPT的Llama-2:
https://www.youtube.com/watch?v=lbFmceo4D5E
>> 添加聊天历史记录:
https://www.youtube.com/watch?v=d7otIM_MCZs
GitHub地址:
GitHub - PromtEngineer/localGPT: Chat with your documents on your local device using GPT models. No data leaves your device and 100% private.
1、工作原理是什么?
通过选择合适的本地模型和LangChain的功能,您可以在本地运行整个流程,而不会有任何数据离开您的环境,并且具有合理的性能。
ingest.py使用LangChain工具解析文档并在本地使用InstructorEmbeddings创建嵌入。然后,它使用Chroma向量存储将结果存储在本地向量数据库中。
run_localGPT.py使用本地LLM理解问题并生成答案。答案的上下文是从本地向量存储中提取的,使用相似性搜索来定位来自文档的正确上下文片段。
您可以用HuggingFace中的任何其他LLM替换这个本地LLM。请确保您选择的任何LLM都符合HF格式。
2、如何选择不同的LLM模型?
以下提供了如何选择不同的LLM模型来生成响应的说明:
(1)、在您选择的编辑器中打开constants.py。
(2)、更改MODEL_ID和MODEL_BASENAME。如果您正在使用量化模型(GGML,GPTQ),您需要提供MODEL_BASENAME。对于未量化的模型,请将MODEL_BASENAME设置为NONE
(3)、已经有许多经过测试,可以与原始训练模型(以HF结尾或其“Files and versions”中有.bin的)以及量化模型(以GPTQ结尾或其“Files and versions”中有.no-act-order或.safetensors的)一起运行的示例模型。
(4)、对于以HF结尾或其“Files and versions”中有.bin的模型。
>> 确保选择了model_id。例如 -> MODEL_ID = "TheBloke/guanaco-7B-HF"
>> 如果转到其HuggingFace存储库并转到“Files and versions”,您会注意到以.bin扩展名结尾的模型文件。
>> 任何包含.bin扩展名的模型文件将在找到# load the LLM for generating Natural Language responses的代码时运行。
>> MODEL_ID = "TheBloke/guanaco-7B-HF"
(5)、对于包含GPTQ在名称中的模型,或其“Files and versions”中有.no-act-order或.safetensors扩展名的模型。
>> 确保选择了model_id。例如 -> model_id = "TheBloke/wizardLM-7B-GPTQ"
>> 您还需要选择其模型基本名称文件。例如 -> model_basename = "wizardLM-7B-GPTQ-4bit.compat.no-act-order.safetensors"
>> 如果转到其HuggingFace存储库并转到“Files and versions”,您会注意到一个以.safetensors扩展名结尾的模型文件。
>> 任何包含no-act-order或.safetensors扩展名的模型文件将在找到# load the LLM for generating Natural Language responses的代码时运行。
>> MODEL_ID = "TheBloke/WizardLM-7B-uncensored-GPTQ"
MODEL_BASENAME = "WizardLM-7B-uncensored-GPTQ-4bit-128g.compat.no-act-order.safetensors"
(6)、注释掉所有其他实例的MODEL_ID="其他模型名称",MODEL_BASENAME=其他基本模型名称,以及llm = load_model(args*)
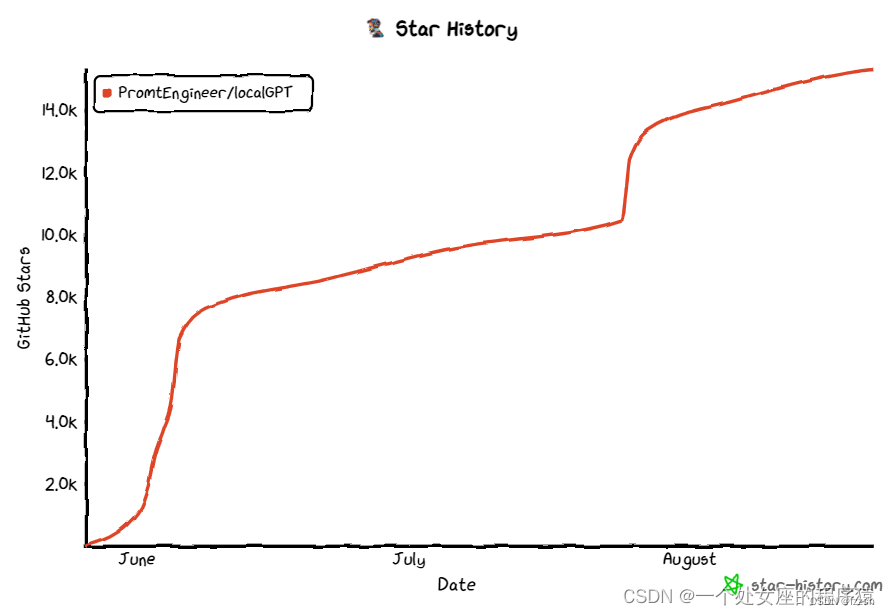
3、Star History
4、免责声明
这是一个测试项目,旨在验证使用LLMs和向量嵌入进行问题回答的完全本地解决方案的可行性。它不适用于生产环境,并且不应该在生产中使用。Vicuna-7B基于Llama模型,因此具有原始Llama许可证。
LocalGPT的安装
1、环境设置
安装conda
conda create -n localGPT
激活环境
conda activate localGPT
为了设置您的环境以运行此处的代码,请首先安装所有要求:
pip install -r requirements.txt
如果您想要在llama-cpp中使用BLAS或Metal,可以设置适当的标志:
例如:cuBLAS
CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install -r requirements.txt
2、Docker部署
为Nvidia GPU上的GPU推理安装所需的软件包(如gcc 11和CUDA 11)可能会导致与系统中的其他软件包冲突。
作为Conda的替代方案,您可以使用附带的Dockerfile使用Docker。它包含CUDA,您的系统只需安装Docker,BuildKit,Nvidia GPU驱动程序和Nvidia容器工具包。使用docker build . -t localgpt进行构建,需要BuildKit。
Docker BuildKit目前在docker build时不支持GPU,只在docker run时支持。使用docker run -it --mount src="$HOME/.cache",target=/root/.cache,type=bind --gpus=all localgpt运行。
3、测试数据集
该存储库使用美国宪法作为示例。
摄入您自己的数据集的说明
将所有的.txt、.pdf或.csv文件放入load_documents()函数中的SOURCE_DOCUMENTS目录中,用您源文档目录的绝对路径替换docs_path。
当前的默认文件类型为.txt、.pdf、.csv和.xlsx,如果您想使用其他文件类型,您需要将其转换为默认文件类型之一。
运行以下命令以摄入所有数据。
默认为cuda
python ingest.py
使用设备类型参数来指定给定的设备。
python ingest.py --device_type cpu
使用help获取支持的设备的完整列表。
python ingest.py --help
它将创建包含本地向量存储的索引。所需时间取决于您的文档大小。您可以摄入任意数量的文档,所有文档都将累积在本地嵌入数据库中。如果您想从空数据库开始,请删除索引。
注意:第一次运行时,由于需要下载嵌入模型,这会花费时间。在随后的运行中,没有数据会离开您的本地环境,可以在没有互联网连接的情况下运行。
4、向您的文档提问,本地方式!
为了提问,运行如下命令:
python run_localGPT.py
然后等待脚本需要您的输入。
> Enter a query:
按下Enter键。等待LLM模型消耗提示并准备答案。完成后,它将打印答案以及它从您的文档中提取的上下文中使用的4个源;然后您可以继续提问而无需重新运行脚本,只需等待提示即可。
注意:第一次运行时,它将需要互联网连接来下载vicuna-7B模型。之后,您可以关闭互联网连接,脚本推理仍然可以正常工作。没有数据会离开您的本地环境。
输入exit以结束脚本。
5、在CPU上运行
默认情况下,localGPT将使用GPU来运行ingest.py和run_localGPT.py脚本。但是,如果您没有GPU并且希望在CPU上运行,现在您可以这样做(警告:速度会很慢!)。您需要在两个脚本中使用--device_type cpu标志。
对于摄入,请运行以下命令:
python ingest.py --device_type cpu
为了提问,运行如下命令:
python run_localGPT.py --device_type cpu
6、为M1/M2运行量化
通过llama-cpp库支持Apple Silicon(M1/M2)的GGML量化模型,示例。基于auto-gptq的GPTQ量化模型将无法工作,详见此处。GGML模型将适用于CPU或MPS。
故障排除
安装MPS:
1-按照此页面的说明构建支持Metal Performance Shaders(MPS)的PyTorch。PyTorch使用新的MPS后端来加速GPU训练。使用提供的链接中提到的简单Python脚本验证mps支持是一个好的实践。
2-按照页面的说明,以下是您可能在终端中启动的示例内容
xcode-select --install
conda install pytorch torchvision torchaudio -c pytorch-nightly
pip install chardet
pip install cchardet
pip uninstall charset_normalizer
pip install charset_normalizer
pip install pdfminer.six
pip install xformers
升级软件包:您的langchain或llama-cpp版本可能过时。通过再次运行install来升级您的软件包。
pip install -r requirements.txt
如果仍然遇到错误,请尝试使用这些标志安装最新的llama-cpp-python,并查看线程。
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install -U llama-cpp-python --no-cache-dir
7、运行UI
(1)、在您选择的编辑器中打开constants.py,并根据选择添加您想要使用的LLM。默认情况下,将使用以下模型:
MODEL_ID = "TheBloke/Llama-2-7B-Chat-GGML"
MODEL_BASENAME = "llama-2-7b-chat.ggmlv3.q4_0.bin"
(2)、在维护了从requirements.txt安装的依赖项的Python环境中,打开一个终端。
(3)、导航到/LOCALGPT目录。
(4)、运行以下命令 python run_localGPT_API.py。API应该开始运行。
(5)、等到一切加载完毕。您应该会看到类似INFO:werkzeug:Press CTRL+C to quit.的内容。
(6)、打开第二个终端并激活相同的Python环境。
(7)、导航到/LOCALGPT/localGPTUI目录。
(8)、运行命令 python localGPTUI.py。
(9)、在Web浏览器中打开地址http://localhost:5111/。
8、系统要求
Python版本
要使用此软件,您必须安装Python 3.10或更高版本。较早版本的Python将无法编译。
C++编译器
如果在pip安装过程中构建wheel时遇到错误,则可能需要在计算机上安装C++编译器。
对于Windows 10/11
要在Windows 10/11上安装C++编译器,请按照以下步骤操作:
(1)、安装Visual Studio 2022。
(2)、确保选择了以下组件:
>> 通用Windows平台开发
>> 用于Windows的C++ CMake工具
(3)、从MinGW网站下载MinGW安装程序。
(4)、运行安装程序并选择“gcc”组件。















 2206
2206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









