







Golang的诞生
go语言的核心开发者—三位大牛

Google为什么要创造go语言?
1)认为现在的编程语言不能充分发挥硬件的优势
2)软件复杂程度越来越高,缺乏一个足够简洁高效的编程语言
3)企业运行维护很多c/c++的项目,c/c++程序运行速度虽然快,但编译速度很慢,同时还存在内存泄漏问题。
Golang的特性
go语言保证了既能到达静态编译语言的安全和性能,又达到动态语言开发维护的高效率,使用一个表达式来形容,Go=C+Python,说明Go语言既有c静态语言程序的运行速度,又能达到Python动态语言的快速开发
1)新理念
从c语言中继承了很多理念,包括表达式语法,控制结构,基础数据类型,调用参数传值,指针等等,要也保留了和C语言一样的编译执行方式及弱化的指针。
例子:
//go语言的指针使用特点(体验)
func testPtr(num *int) {
*num = 20
}
2)引入包的概念
用于组织程序结构,Go语言的一个文件都要归属一个包,而不能单独存在。
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
3)垃圾回收机制
内存自动回收,不需要开发人员管理
4)天然并发(重要特点)
从语言层面支持并发,实现简单。
goroutine,轻量级线程,可实现大并发处理,高效利用多核。
基于CSP并发模型(CommunicatingSequentialProcesses)实现。
关于CSP并发模型
goroutine 是Go语言中并发的执行单位。其实就是协程
Go的CSP并发模型解释;线程和协程的解释 ;TCB的解释 ;
注意:在线程中
1.涉及到同步锁。
2.涉及到线程阻塞状态和可运行状态之间的切换。
3.涉及到线程上下文的切换。
以上涉及到的任何一点,都是非常耗费性能的操作。
所以引申出协程:一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
协程与线程主要区别是它将不再被内核调度,而是交给了程序自己而线程是将自己交给内核调度,所以也不难理解golang中调度器的存在。
5)吸收了管道通信机制
形成go语言特有的管道channel,通过管道channel,可以实现不同的gorouter之间的相互通信。
6)函数返回多个值
func getSumAndSub(n1 int, n2 int) (int, int) {
sum := n1 + n2
sub := n1 - n2
return sum, sub
}
7)新的创意
(切片slice(动态数组,类似Java中的集合)、延时执行defer(方便回收资源)等)
go快速入门
项目文件结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OIu3xGy3-1646573975868)(http://h9x14s4c.xyz/img/202111211546286.png)]
goproject
|
--src
|
--go_code
|
--prj1
|
--main
--package
...
--prj2
|
--
...
约定俗成:go总项目-src-go_code–项目1/项目2----包-具体.go文件
package main //表示该文件所在的包是main
import "fmt" //表示引入一个包:fmt 作用:引入该包后,可以使用该包中的函数
func main() { //func 是一个关键字,表示一个函数,main是函数名,是一个主函数,即是我们的函数入口
fmt.Println("Hello World!")
}
go build hello.go #编译go文件
go build -o myhello.exe hello.go #指定名称编译
#生成hello.exe文件,
hello.exe #运行.exe文件
###########
#或者使用go run hello.go
go run hello.go
###########
#使用gofmt hello.go来缩进代码
gofmt -w hello.go
生产模式中,通常先编译成.exe文件再执行
golang执行流程分析
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nIlrBU6I-1646573975869)(http://h9x14s4c.xyz/img/202111211546158.png)]](https://img-blog.csdnimg.cn/2fb4381ee32f48bc988e8e52fc97459f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
注意:
- go源文件以.go为扩展名
- go应用程序的执行入口为main()函数
- go方法由一条条语句构成,每个语句后面不需要分号(编译时会在每一行后自动添加分号,不需要手动添加
- go语言定义的变量或者import的包没有使用到,代码不能编译通过
golang转义字符
go语言转义字符有:
1、“\t”,表示一个制表符,通常使用它可以排版;
2、“\n”,表示换行符;
3、“\\”,表示一个\符号;
4、“\"”,表示一个双引号";
5、“\r”,表示一个回车。从当前行的最前面开始输出,覆盖掉以前的内容
dos中的一些操作
md prj1 #创建一个目录
rd /q/s prj1 #不询问按层级删除所有目录
echo a.txt #创建一个文件
copy a.txt prj1 #复制a.txt到prj1中
del a.txt #删除a.txt文件
del *.txt #删除所有.txt的文件
cls #清屏【苍老师】
exit #退出dos
golang变量
变量的几种定义:
单变量、多变量、全局变量
package main
import "fmt"
//定义全局变量
var username = "张三"
var token = "sdfsdf"
var (
u1 = "张三"
u2 = "sdfsdfsdfsdf"
)
func main() {
//golang使用变量方式
//1、指定变量类型,声明后不赋值,使用默认值
var i int
fmt.Println("i = ", i)
//2、根据值自动判断变量类型(类型推导)
var num = 1.111
fmt.Println("num = ", num)
//3、省略var,注意 := 左侧的变量应该是未声明的,否则会报错
name := "Tom"
fmt.Println("name = ", name)
//多变量的定义
var n1, n2, n3 int
fmt.Println("n1 = ", n1, "n2 = ", n2, "n3 = ", n3)
//多变量定义 --对应关系
var age, city = 12, "广州"
fmt.Println("age = ", age, "city = ", city)
//多变量定义 --对应关系2
age1, city1 := 121, "广州1"
fmt.Println("age1 = ", age1, "city1 = ", city1)
//程序中"+"的使用:数值类型时相加,字符串类型时为拼接
fmt.Println("张" + "三")
}
注意:
- 变量在同一作用域中不能重名
- 变量 = 变量名+值+数据类型
- 变量在同一作用域中,该数值可以在同类型里不断变化(覆盖)
- 变量在没有赋值的情况下,编译器会使用默认值,例如int默认0,string默认空串,小数默认0
具体变量类型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kg0zEVQk-1646573975870)(http://h9x14s4c.xyz/img/202111211546321.png)]](https://img-blog.csdnimg.cn/edb30f4fc0cf4610ad41b7e92c18edc1.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
基本数据类型:
- 数值型
- 整数类型(int,int8,int16,int32,int64,uint,uint8,uint16,uint32,uint64,byte)
- 浮点类型(float32,float64)
- 字符型(没有专门的字符型,使用byte来保存单个字母字符)
- 布尔型
- 字符串型(string)[官方将string归属到基本数据类型,带看…]
派生/复杂数据类型
- 指针(Pointer)
- 数组
- 结构体(struct)[类似class]
- 管道(Channel)
- 函数(也是一种类型)
- 切片(slice)[类似动态数组]
- 接口(interface)
- map [类似集合]
1)整型
图解:
有符号:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-58xg3DfX-1646573975870)(http://h9x14s4c.xyz/img/202111211546490.png)]](https://img-blog.csdnimg.cn/be43ab35922241cab10b065cfaade7c3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
无符号:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-35X7CkVs-1646573975871)(http://h9x14s4c.xyz/img/202111211546999.png)]](https://img-blog.csdnimg.cn/6e7cf7a3124c490b9a86d4ff7ec31cf1.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
ps:一个字节8位
其他类型:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lojxk6mY-1646573975873)(http://h9x14s4c.xyz/img/202111211546240.png)]](https://img-blog.csdnimg.cn/41571e3910af4179a23c52f587688aff.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
整型使用细节:
- golang各整数类型分:有符号和无符号,int,uint的大小和系统有关。
- golang的整型默认声明为int型
- 如何在程序查看某个变量的字节大小和数据类型
//简单查看类型方法:格式化输出
var testTypeNum = 1000
fmt.Printf("这个测试值的类型是:%T" ,testTypeNum)
//在程序中查看某个变量占用字节大小,和数据类型
//使用unsafe.Sizeof(testTypeNum)可以返回变量占用的字节数,需要引入unsafe包
var testTypeNum = 1000
fmt.Printf("这个测试值的类型是:%T ,并且占用的字节数是:%d", testTypeNum, unsafe.Sizeof(testTypeNum))
- golang程序运行中整型变量在使用时,遵守保小不保大的原则,即:在保证程序正常运行下,尽量使用占用空间小的数据类型。如年龄。
- bit:计算机中最小的存储单位。byte:计算机中基本的存储单位。【二进制】
1byte = 8bit
2)小数类型/浮点型
用于存放小数:1.2,1.31,-1.19

浮点类型的分类
-
单精度float32
-
双精度float64

说明:浮点数 = 符号位+指数位+尾数位
尾数位可能丢失,造成精度损失
float64比float32更精确
浮点类型使用细节:
- 浮点类型有固定的范围和字段长度,不受具体os的影响
- 浮点型默认声明float64类型
- 浮点型常量有两种表示形式
- 十进制数形式:如:5.12 ,.512(必须有小数点)
- 科学计数法形式:如:5.1234e2 = 5.12*10的2次方,5.12E-2 = 5.12/10的2次方
- 通常情况下,应该使用float64,因此它比float32更精确
3)字符类型
golang中没有专门的字符类型,如果要存储单个字符(字母),一般使用byte来保存。(ASCII)
//当我们直接输出byte值时,就是输出对应的字符码值(ASCII)
var byte1 byte = 'a'
fmt.Println(byte1)
//如果需要输出对应的字符,需要使用格式化输出
fmt.Printf("byte1 = %c", byte1)
//溢出测试 var byte2 byte = '北'
var byte2 int = '北'
fmt.Printf("byte2 = %d", byte2)
如果我们保存的字符在ASCII表的,如[0-1,1-z,A-Z]则可以保存到byte;
如果我们保存的字符对应码值大于255,这时我们可以考虑使用int类型保存;
如果我们需要安装字符的方式输出,这时我们需要格式化输出,即fmt.Printf(“byte1 = %c”, byte1)
字符类型使用细节
- 字符常量是使用单引号’'括起来的单个字符,例如var c1 byte = ‘a’ var c2 int = ‘中’
- Go中允许使用转义字符’\‘来将其后的字符转变为特殊字符型常量。例如 var c3 char = ‘\n’ //’\n’表示换行符
- go语言的字符使用utf-8编码
英文字母1个字节,汉字3个字节
- 在go中,字符的本质是一个整数,直接输出时,是该字符对应的utf-8编码的码值
- 直接可以给某个变量夫一个数字,然后按格式化输出时%c,会对应输出该字符的unicode字符
- 字符类型是可以进行运算的,相当于一个整数,因为它都对应有unicode码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CdMSQf5T-1646573975876)(http://h9x14s4c.xyz/img/202111211632922.png)]
4)布尔类型
也叫bool类型,bool类型数据只允许取值true和false。
bool类型占1个字节。
bool类型适合于逻辑运算,一般用于程序流程控制
不可以0或非0整数替代false和true,这点和c语言不同
5)字符串类型
字符串类型使用细节
- go语言的字符串字节使用utf-8编码表示unicode文本,这样golang统一使用utf-8编码,乱码的问题不会再困扰程序员
- 字符串一旦赋值了,字符串就不能修改了:在go中字符串是不可变的。
- 字符串的两种表示形式
- 双引号:会识别转移字符
- 反引号,以字符串的原生形式输出,包括换行和特殊字符,可以实现防止攻击、输出源代码等效果
- 字符串拼接方式
- 多行使用+进行拼接时,加号留在前一行
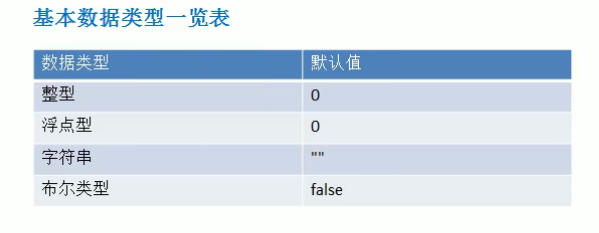
基本数据类型默认值
基本数据类型转换
go在不同类型的变量之间赋值时需要显式转换(强制转换)。也就是说golang中数据类型不能自动转换
基本语法:
表达式T(v):将v转换为类型T
//强制转换
var ii int32 = 100
var n11 float32 = float32(ii)
fmt.Printf("测试类型输出:%v", n11)
细节说明
- go中,数据类型的转换可以从表示范围小->表示范围大,也可以 范围大->范围小
- 被转换的是变量存储的数据(即值),变量本身的数据类型并没有变化!
- 在转换中,比如将int64转成int8,编译时不会报错,只是转换结果是按溢出处理,和我们希望的结果不一样
ps:如果想忽略未定义的包,请在未引用的包前加下划线’_‘
基本数据类型转string类型
- 使用Springf转换
func Sprintf
func Sprintf(format string, a ...interface{}) string
Sprintf根据format参数生成格式化的字符串并返回该字符串。
var num1 int = 99
var num2 float64 = 23.456
var b bool = true
var myChar byte = 'h'
// 使用fmt.Sprintf方法转换
var str string
str = fmt.Sprintf("%d", num1)
str = fmt.Sprintf("%f", num2)
str = fmt.Sprintf("%t", b)
str = fmt.Sprintf("%c", myChar)
fmt.Printf("str的type:%T,值为 %q", str, str)
- 使用 package strconv转换
func strconv
strconv包实现了基本数据类型和其字符串表示的相互转换。
// 使用strconv包转换
var num3 int = 99
var num4 float64 = 23.456
var num5 int64 = 99123
var b1 bool = true
var str2 string
str2 = strconv.FormatInt(int64(num3), 10)
// FormatFloat(num4, 'f', 10, 64)中
// 说明:'f'格式(-ddd.dddd);10表示小数保留位数;64表示这个小数是float64按照float64进行取舍
str2 = strconv.FormatFloat(num4, 'f', 10, 64)
str2 = strconv.FormatBool(b1)
// 将整型转换为string,Itoa是FormatInt(i, 10) 的简写。
str2 = strconv.Itoa(int(num5))
fmt.Printf("str2的type:%T,值为 %q", str2, str2)
string类型转基本数据类型
使用 strconv包进行转换
// string -> 其他基本数据类型
var str string = "true"
var b bool
// b, _ = strconv.ParseBool(str)说明:
// strconv.ParseBool(str)函数会返回两个值,(value bool, err error)
// 只需要接收value值,因此使用_ 忽略err值
b, _ = strconv.ParseBool(str)
fmt.Printf("b的type:%T,值为 %v\n", b, b)
var str2 string = "151542"
var n1 int64
n1, _ = strconv.ParseInt(str2, 10, 64)
n2 := int(n1)
fmt.Printf("b的type:%T,值为 %v\n", n1, n1)
fmt.Printf("b的type:%T,值为 %v\n", n2, n2)
var str3 string = "1.2356"
var f1 float64
f1, _ = strconv.ParseFloat(str3, 64)
fmt.Printf("b的type:%T,值为 %v\n", f1, f1)
如果的到的返回值是float64,但是希望得到的是float32,可以再进行一部float32(num)的转换
基本数据类型和string的转换细节说明
注意:
在将string类型转成基本数据类型时,要确保string类型能够转成有效的数据,比如我们可以把’123’转成一个整数,但不能把’hello’转成一个整数,如果这样做,golong会直接将其转成0.(不能成功转型的会转成默认值)
6)指针
指针与基本数据类型的区别
对于基本数据类型,变量存的就是值,也叫值类型
获取变量的地址,用&,比如var num int,获取num的地址:&num
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XhGP4ybX-1646573975879)(http://h9x14s4c.xyz/img/202111212017136.png)]](https://img-blog.csdnimg.cn/20dae4dd40fe4c3d83e82cd57d15c303.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
- 指针类型,指针变量存的是一个地址,这个地址指向的空间存的才是值;比如:var ptr *int = &num
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xhs3FvEH-1646573975880)(http://h9x14s4c.xyz/img/202111212035536.png)]](https://img-blog.csdnimg.cn/04a58724fbb543e8acdcd0edb56f6712.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
- 获取指针类型所指向的值,使用: *,比如var ptr *int,使用 *ptr获取ptr指向的值
// golang 中指针类型转换
var i int = 10
// i 的地址是什么,&i
fmt.Println("i的地址:", &i)
// 下面是var ptr *int = &i
// 1、ptr是一个指针变量
// 2、ptr的类型是 *int
// 3、ptr本身的值是&i
// 4、ptr本身也存在一个地址
var ptr *int = &i
fmt.Printf("ptr的值:%v\n", ptr)
fmt.Printf("ptr的地址:%v\n", &ptr)
fmt.Printf("ptr指向的值:%v\n", *ptr)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4g8ZCuIk-1646573975881)(http://h9x14s4c.xyz/img/202111212050584.png)]](https://img-blog.csdnimg.cn/c2493ba58002418ba3afc76d1beb3f49.png)
练习:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aKuoV1vr-1646573975881)(http://h9x14s4c.xyz/img/202111212057413.png)]](https://img-blog.csdnimg.cn/e723dec2c48a487d81b587ab22954d17.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hhCTfxCe-1646573975882)(http://h9x14s4c.xyz/img/202111212101831.png)]](https://img-blog.csdnimg.cn/b9e788bb388d48bcaf429d2e9014f989.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
指针的使用细节
- 值类型,都有对应的指针类型,形式为 *数据类型,比如int的对应的指针就是 *int,float32对应的指针类型就是*float32,依此类推
- 值类型包括:基本数据类型,int系列,float系列,bool,string、数组和结构体struct
7)值类型和引用类型
- 值类型:基本数据类型int系列,float系列,bool,string、数组和结构体struct
- 引用类型:指针、slice切片、map、管道chan、interface等都是引用类型
值类型和引用类型的特点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tL5uJnav-1646573975882)(http://h9x14s4c.xyz/img/202111212115016.png)]](https://img-blog.csdnimg.cn/abf94591e40042f29d23cd2066c96f0a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
内存的栈区和堆区的示意图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kcXLzegG-1646573975883)(http://h9x14s4c.xyz/img/202111212117845.png)]](https://img-blog.csdnimg.cn/d892e2e6f2a744b889b5fa9079efc362.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_19,color_FFFFFF,t_70,g_se,x_16)
栈区和堆区都是逻辑的概念 —编译器使用’逃逸分析’,进行自动分配
8)常量
- 常量使用const修改
- 常量在定义的时候,必须初始化
- 常量不能修改
- 常量智能修饰bool、数值类型(int、float系列)、string类型
- 语法:
const identifier [type] = value
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZGmMnjMI-1646573975883)(http://h9x14s4c.xyz/img/202112071951523.png)]](https://img-blog.csdnimg.cn/930522c5f1b345a09895cee03fe6c54d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
- golang中没有常量名必须大写的规定,比如TAX_RATE
- 仍然通过首字母的大小写来控制常量的访问范围
标识符的命名规范
- golang对各种变量、方法等命名时使用的字符序列称为标识符
- 凡是自己可以起名字的地方都叫标识符 例: var name string
标识符的命名规则:
- 由26个英文字母大小写,0-9,_组成
- 数字不能开头
- golang中严格区分大小写
- 标识符不能包含空格
- 下划线"_"本身在go中是一个特殊的标识符,称为空标识符。可以代表任何其他的标识符,但是它对应的值会被忽略(比如:忽略某个返回值)。所以仅能被作为占位符使用,不能作为标识符使用。
- 不能以系统保留关键字作为标识符,比如break,if等等…
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lg82V41t-1646573975883)(http://h9x14s4c.xyz/img/202111212131862.png)]](https://img-blog.csdnimg.cn/b6ef3dc305d94eeaa1f0ebb21f966b79.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
预定义标识符:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p3d6qIsi-1646573975884)(http://h9x14s4c.xyz/img/202111220937328.png)]](https://img-blog.csdnimg.cn/0b684557217646d59f947e8dd0d01ef9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
案例:

标识符命名注意事项:
- 包名:保持package的名字和目录保持一致,尽量采取有意义的包名,简短,有意义,不要和标准库产生冲突
- 变量名、函数名、常量名:采用驼峰法。
- 如果变量名、函数名、常量名首字母大写,则可以被其他的包访问;如果首字母小写,则只能在本包中使用
**注意:**可以简单的理解成,首字母大写是公有的(类似public),首字母小写是私有的(类似private)。
golang运算符
运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等
- 算术运算符
- 赋值运算符
- 比较运算符
- 逻辑运算符
- 位运算符
- 其他运算符
- 三元运算符
1)算术运算符
对数值类型的变量进行运算,比如加减乘除
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vkAPeALr-1646573975885)(http://h9x14s4c.xyz/img/202111220943123.png)]](https://img-blog.csdnimg.cn/bb891588cd6945f2bdba60d7cb0e3ade.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
注意:golang中没有–a的运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 相加 | A + B 输出结果 30 |
| - | 相减 | A - B 输出结果 -10 |
| * | 相乘 | A * B 输出结果 200 |
| / | 相除 | B / A 输出结果 2 |
| % | 求余 | B % A 输出结果 0 |
| ++ | 自增 | A++ 输出结果 11 |
| – | 自减 | A-- 输出结果 9 |
运算符:/、%
- /
如果运算的数都是整数,那么除后,去掉小数部分,保留整数部分(类Java、c)
如果我们希望保留小数部分,则需要有浮点数参与运算
- %
看一个公式:a%b = a - a/b*b
// 取模运算%
fmt.Println("10 % 3 = ", 10 % 3)//1
fmt.Println("-10 % 3 = ", -10 % 3)//-1
fmt.Println("10 % -3 = ", 10 % -3)//1
fmt.Println("-10 % -3 = ", -10 % -3)//-1
算术运算符细节说明
- 对于除号’/’,它的整数除和小数除是有区别的:整数之间做除法时,只保留整数部分而舍弃小数部分。例如:19/5=3
- 当对一个数取模时,可以等价a % b = a - a / b * b ,这样我们可以看到取模的本质运算
- golang的自增自减只能当做一个独立语言使用时,不能这样使用
- b:=a++ 错误
- b:=a– 错误
- golang的++和–只能写在变量的后面,不能写在变量的前面,即:只有a++ a–没有++a --a
- golang的设计者去掉c/java中的自增自减的容易混淆的写法,让golang更简洁同一
2)关系运算符
- 运算符结果都是bool型,也就是true 或 false
- 在关系表达式中经常使用,或者循环结构中
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个值是否相等,如果相等返回 True 否则返回 False。 | (A == B) 为 False |
| != | 检查两个值是否不相等,如果不相等返回 True 否则返回 False。 | (A != B) 为 True |
| > | 检查左边值是否大于右边值,如果是返回 True 否则返回 False。 | (A > B) 为 False |
| < | 检查左边值是否小于右边值,如果是返回 True 否则返回 False。 | (A < B) 为 True |
| >= | 检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 | (A >= B) 为 False |
| <= | 检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 | (A <= B) 为 True |
关系运算符细节说明
-
关系运算符的结果都是bool型,也就是要么true,要么false
-
关系运算符组成的表达式 --> 关系表达式:a>b
-
比较运算符 “==” 不能写成 “=”
3)逻辑运算符
用于连接多个条件,一般来讲就是关系表达式,最终结果也是一个bool值
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 逻辑 AND 运算符。 如果两边的操作数都是 True,则条件 True,否则为 False。 | (A && B) 为 False |
| || | 逻辑 OR 运算符。 如果两边的操作数有一个 True,则条件 True,否则为 False。 | (A || B) 为 True |
| ! | 逻辑 NOT 运算符。 如果条件为 True,则逻辑 NOT 条件 False,否则为 True。 | !(A && B) 为 True |
逻辑运算符细节说明
- &&也叫短路与:如果第一个条件为false,则第二个条件不会判断,最终结果为false
- ||也叫短路或:如果第一个条件为true,则第二个条件不会判断,最终结果为true
4)赋值运算符
赋值运算符就是将某个运算后的值,赋给指定的变量
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等于 C = C + A |
| -= | 相减后再赋值 | C -= A 等于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等于 C = C * A |
| /= | 相除后再赋值 | C /= A 等于 C = C / A |
| %= | 求余后再赋值 | C %= A 等于 C = C % A |
| <<= | 左移后赋值 | C <<= 2 等于 C = C << 2 |
| >>= | 右移后赋值 | C >>= 2 等于 C = C >> 2 |
| &= | 按位与后赋值 | C &= 2 等于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
| |= | 按位或后赋值 | C |= 2 等于 C = C | 2 |
赋值运算符特点
- 运算顺序从右往左
- 赋值运算符的左边,这能是变量,右边可以是变量、表达式、常量值
- 复合赋值运算符等价于下面的效果:a+=3 =>a = a+3
// 不使用第三变量,将ab互换
a := 10
b := 20
a = a + b
b = a - b //b = a + b - b ==>b = a
a = a - b //a = a + b ,a是总和,b是a,所以a=b
fmt.Printf("a: %v,b: %v", a, b)
运算符优先级
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t9e5cSut-1646573975886)(http://h9x14s4c.xyz/img/202111221041816.png)]](https://img-blog.csdnimg.cn/4cc47f2830784689beb005468ba99553.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
| 先级 | 运算符 |
|---|---|
| 5 | * / % << >> & &^ |
| 4 | + - | ^ |
| 3 | == != < <= > >= |
| 2 | && |
| 1 | || |
5)位运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符"&"是双目运算符。 其功能是参与运算的两数各对应的二进位相与。 | (A & B) 结果为 12, 二进制为 0000 1100 |
| | | 按位或运算符"|"是双目运算符。 其功能是参与运算的两数各对应的二进位相或 | (A | B) 结果为 61, 二进制为 0011 1101 |
| ^ | 按位异或运算符"^"是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。 | (A ^ B) 结果为 49, 二进制为 0011 0001 |
| << | 左移运算符"<<“是双目运算符。左移n位就是乘以2的n次方。 其功能把”<<“左边的运算数的各二进位全部左移若干位,由”<<"右边的数指定移动的位数,高位丢弃,低位补0。 | A << 2 结果为 240 ,二进制为 1111 0000 |
| >> | 右移运算符">>“是双目运算符。右移n位就是除以2的n次方。 其功能是把”>>“左边的运算数的各二进位全部右移若干位,”>>"右边的数指定移动的位数。 | A >> 2 结果为 15 ,二进制为 0000 1111 |
位运算符和移位运算符
位运算:

位运算案例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9wEEWFA5-1646573975887)(http://h9x14s4c.xyz/img/202111221315856.png)]](https://img-blog.csdnimg.cn/66bd9067c6b2404998bfc18c4bb2f14f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_15,color_FFFFFF,t_70,g_se,x_16)
移位运算:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hneWzJEr-1646573975888)(http://h9x14s4c.xyz/img/202111221320557.png)]](https://img-blog.csdnimg.cn/a495aaaba45540e88c1fbf8826d7f791.png)
移位运算案例:
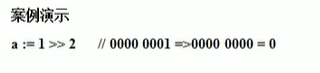
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AdQnDcRR-1646573975889)(http://h9x14s4c.xyz/img/202111221321109.png)]](https://img-blog.csdnimg.cn/ae0093b85041475884c02127977f4535.png)
6)其他运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 返回变量存储地址 | &a; 将给出变量的实际地址。 |
| * | 指针变量。 | *a; 是一个指针变量 |
三元运算符
本质上是if/else的判断
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4RqPQatI-1646573975890)(http://h9x14s4c.xyz/img/202111221048387.png)]](https://img-blog.csdnimg.cn/7f358d60cc024718a85aeaf61dad0f85.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
从键盘输入语句
- 导入fmt包
- 调用fmt.Scanln()或者fmt.Scanf()
// 从键盘输入 使用fmt.Scanln()
var name string
var age byte
var sal float32
var isPass bool
fmt.Println("请输入姓名:")
fmt.Scanln(&name)
fmt.Println("请输入年龄:")
fmt.Scanln(&age)
fmt.Println("请输入薪水:")
fmt.Scanln(&sal)
fmt.Println("是否通过考试:")
fmt.Scanln(&isPass)
//使用fmt.Scanf()
//fmt.Scanf("%s %d %f %t",&name ,&age ,&sal ,&isPass)
fmt.Printf("名字是 %v ,年龄是 %v,薪水是 %v,是否通过考试:%v", name, age, sal, isPass)
进制
对于整数,有四种表示方式:
- 二进制:0,1,满2进1
- 十进制:0-9,满10进1
- 八进制:0-7,满8进1,以数字0开头表示
- 十六进制:0-9及A-F,满16进1,以0x或0X开头表示。注意:此处的A-F不区分大小写。如:0x21AF+1=0X21B0
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O6nZX3pL-1646573975891)(http://h9x14s4c.xyz/img/202111221115739.png)]
进制图示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hng9bIfw-1646573975891)(http://h9x14s4c.xyz/img/202111221117360.png)]](https://img-blog.csdnimg.cn/93c584cceaea4edeabfcc678ed0712c8.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fuIv7SQu-1646573975892)(http://h9x14s4c.xyz/img/202111221117330.png)]](https://img-blog.csdnimg.cn/c9e535e5f986455d949dcc278d9c35b5.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_19,color_FFFFFF,t_70,g_se,x_16)
进制转换
其他进制转十进制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IWJcpyRv-1646573975893)(http://h9x14s4c.xyz/img/202111221120626.png)]](https://img-blog.csdnimg.cn/9ad7c535f2fd417598db4e07d0bd6c9e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
二进制转十进制
规则:从最低位开始(右边的),将每个位上的数提取出来,乘以2的(位数-1)次方,然后求和。
1011=> 1*1+1*2+0*2*2+1*2*2*2=11
对比:134(十进制转换)
134 => 4*1+3*10+1*10*10=4+30+100=134
八进制转十进制
规则:从最低位开始(右边的),将每个位上的数提取出来,乘以8的(位数-1)次方,然后求和。
十六进制转十进制
规则:从最低位开始(右边的),将每个位上的数提取出来,乘以16的(位数-1)次方,然后求和。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TF2hgUro-1646573975893)(http://h9x14s4c.xyz/img/202111221137578.png)]](https://img-blog.csdnimg.cn/0762ba01d9494dbc9b37edf401401f2b.png)
十进制转其他进制
十进制转换成二进制
规则:将该数不断除以2,直到商为0为止,然后将每步得到的余数倒过来,就是对应的二进制。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dTS4Ejti-1646573975895)(http://h9x14s4c.xyz/img/202111221141556.png)]](https://img-blog.csdnimg.cn/b07592a19f53421a9634e2e2174a80e3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
十进制转换成八进制
规则:将该数不断除以8,直到商为0为止,然后将每步得到的余数倒过来,就是对应的八进制。
二进制转换成八进制、十六进制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CezvqKCD-1646573975895)(http://h9x14s4c.xyz/img/202111221143044.png)]](https://img-blog.csdnimg.cn/fea6f76834634cfd94d5ef51738a235f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
二进制转成八进制
规则:将二进制数每三位一组(从低位开始组合),转成对应的十进制数,再将其得到的数组合即可。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WZ5TBLHW-1646573975896)(http://h9x14s4c.xyz/img/202111221147879.png)]](https://img-blog.csdnimg.cn/8d79d15ab5404c51a2d5efdc85326b95.png)
二进制转换成十六进制
规则:将二进制数每四位一组(从低位开始组合),转成对应的十进制数,再将其得到的数组合即可。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bYIjl3aW-1646573975896)(http://h9x14s4c.xyz/img/202111221154607.png)]](https://img-blog.csdnimg.cn/0783736561ba4a4a995a410c3c51a0cc.png)
八进制、十六进制如何转二进制
八进制转二进制
规则:将八进制数的每一位数,转成对应的一个3位的二进制数即可。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EPGq1TVp-1646573975897)(http://h9x14s4c.xyz/img/202111221156869.png)]](https://img-blog.csdnimg.cn/a9292d1eb12641729ed9ad44d380c1a9.png)
十六进制转二进制
规则:将十六进制数的每一位数,转成对应的一个4位的二进制数即可。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F8EXHACO-1646573975897)(http://h9x14s4c.xyz/img/202111221157563.png)]](https://img-blog.csdnimg.cn/78601eae89de4aff86a76ca6fb77ba51.png)
源码、反码、补码
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gWpU6wJW-1646573975897)(http://h9x14s4c.xyz/img/202111221211745.png)]](https://img-blog.csdnimg.cn/4fa1032e2de041778b7a21f04af308a4.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
运用最多的二进制运算符是位运算符和移位运算符,只要设计运算,都使用二进制中的补码进行
流程控制
-
顺序控制
- 从上到下,按需引用
-
分支控制
-
单分支
if
-
双分支
if/else
-
多分支
if/else if /else
-
-
循环控制
switch 分支结构
- switch基于不同条件执行不同的动作,每个case分支都是唯一的,从上到下,逐一测试,直到匹配为止
- 匹配项后面也不需要加break
//测试语句
var key string
fmt.Scanln(&key)
switch key {
case "a":
fmt.Println("周一")
default:
fmt.Println("else")
}
switch 分支细节
- case后是一个表达式(即:常量值、变量、一个有返回值的函数等都可以)
- case后的各个表达式的值的数据类型,必须和switch的表达式数据类型一致
- case后面可以带多个表达式,使用逗号间隔。比如case表达式1,表达式2…
- case后面的表达式如果是常量值(字面量),则要求不能重复
- case后面不需要带break,程序匹配到一个case后就会执行对应的代码块,然后退出switch,如果一个都匹配不到,则执行default
- default语句不是必须的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gyjU6kyp-1646573975898)(http://h9x14s4c.xyz/img/202111221459645.png)]](https://img-blog.csdnimg.cn/9433049dc70146919281a5bdf4ad20f0.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d34vMIe7-1646573975899)(http://h9x14s4c.xyz/img/202111221459684.png)]](https://img-blog.csdnimg.cn/adaf42f9033d427f8f89a4c6f4d11878.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_11,color_FFFFFF,t_70,g_se,x_16)
- switch后也可以不带表达式,类似if-else分支来使用
- switch后也可以直接声明/定义一个变量,分号结束,但不推荐
- switch穿透 - fallthrough,如果再case语句块后增加fallthrough,则会执行下一个case,也叫switch穿透
- type switch :switch语句还可以被用于type-switch来判断某个interface变量中实际指向的变量类型
总结: 什么情况使用switch,什么情况使用if
- 如果判断的具体数值不多,而且符合整数,浮点数、字符、字符串这几种类型,建议使用switch
- 其他情况:对区间判断和结果为bool类型的判断,使用if,if的使用范围更广
for循环控制
//demo
for i := 0; i < 10; i++{
fmt.Println("测试", i)
}
for循环四要素:
- 循环变量初始化
- 循环条件
- 循环条件
- 循环操作语句,(循环体)
- 循环变量迭代
for循环执行顺序说明:
- 执行循环变量初始化:i:=1
- 执行循环条件:i<=10
- 如果循环条件为真,就执行循环操作:fmt.Println()…
- 执行循环变量迭代:i++
- 反复执行2,3,4,直到循环条件为False,就退出for循环
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-clpGpD2T-1646573975899)(http://h9x14s4c.xyz/img/202111221528321.png)]](https://img-blog.csdnimg.cn/bc90c8b612cb4a85b6b156a98942b371.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_13,color_FFFFFF,t_70,g_se,x_16)
for循环注意事项和细节说明
- 循环条件是返回一个布尔值的表达式
- for循环的第二种使用方式
j := 0
for j < 5 {
fmt.Println("sss", j)
j++
}
- for循环的第三种使用方式
i := 1
for {// 这里等价于for ; ;{}
if i <= 5 {
fmt.Println("ss")
}else {
break
}
i++
}
- golang提供for-range的方式,可以方便遍历字符串和数组
//传统方式遍历字符串
str := "hello"
for i:=0; i<len(str); i++{//默认按字节进行遍历,如果出现汉字,则会出现乱码
fmt.Printf("输出:%c \n",str[i])
}
//for-range方式遍历
for index, val := range str{//下表会按照汉字的占字节数进行显示
fmt.Printf("index=%d val=%c\n", index, val)
}
注意:传统方式遍历字符串,默认按字节进行遍历,如果出现汉字,则会出现乱码,因为一个汉字对应3个字节,解决方案:
需要将字符串转成[]rune切片
//传统遍历,改进
str := "hello背景"
str2 := []rune(str)
for i:=0; i<len(str2); i++{
fmt.Printf("输出:%c \n",str2[i])
}
while和do…while的实现
go中没有while和do…while语法,实现这两种操作,我们可以通过for循环来实现效果
while:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5HcxNoL6-1646573975899)(http://h9x14s4c.xyz/img/202111221601473.png)]
do…while:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qnQOcagW-1646573975900)(http://h9x14s4c.xyz/img/202111221602759.png)]
多重循环控制
- 将一个循环放在另一个循环体内,就形成了嵌套循环。再外边的for称为外层循环,在里面的for循环称为内层循环。【建议使用两层,最多不要超过3层】
- 实质上,嵌套循环就是把内层循环当成外层循环的循环体。只有当内层循环的循环体条件为false时,才会完全跳出内层循环,才可结束外层的当次循环,开始下一次循环
- 设外层循环次数为m次,内层为n次,则内层循环体实际上需要执行m*n=mn次。
打印金字塔训练
//层数:5
var num int = 5
for i := 1 ; i <= num; i++ {
for k := 1; k <= num - i; k++ {
fmt.Printf(" ")
}
for j := 1; j <= 2*i-1; j++ {
//fmt.Printf("*")//打印实心的金字塔
if j == 1 || j == 2*i-1 || i == num{// 打印镂空的金字塔
fmt.Printf("*")
}else {
fmt.Printf(" ")
}
}
fmt.Println()
}
九九乘法表练习:
//九九乘法表
for i := 1; i <= 9; i++ {
for j := 1; j <= i; j++ {
fmt.Printf("%v * %v = %v \t", j, i, j*i)
}
fmt.Println()
}
跳转控制语句
break
//随机生成,跳出
var count int = 0
for{
// time.Now().Unix()返回一个从1970:1:1到现在所经过的秒数
rand.Seed(time.Now().UnixNano())
n := rand.Intn(100) + 1
count ++
if n == 20{
break
}
}
fmt.Println(count)
break注意事项和细节说明
- break 语句出现在多层嵌套语句块中,可以通过标签指名要终止的是哪一层语句块
- 标签的基本使用
label: //指明一个循环标记
for i := 0; i < 5; i++ {
for j := 0; j < 6;j++{
if j == 2 {
break label //默认会跳出最近的一个标签,但是指明标签后,会跳出指明的标记的循环
}
fmt.Println("j=",j)
}
}
练习:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FXcnCvrN-1646573975900)(http://h9x14s4c.xyz/img/202111221726956.png)]](https://img-blog.csdnimg.cn/53b4b9f736ba467ba72c30a2c3860070.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
continue
- continue语句用于结束本次循环,继续执行下一次循环
- continue语句出现在多层嵌套的循环语句体中,可以通过标签指明要跳过的是那一层循环,和break用法一样
goto
- goto语句可以无条件地转移到程序中指定的行
- goto语句通常与条件语句配合使用。可以用来实现条件转移,跳出循环体等功能
- 一般在go程序中不主张使用goto语句,以免造成程序流程混乱
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zFkkl4WX-1646573975901)(http://h9x14s4c.xyz/img/202111221738238.png)]](https://img-blog.csdnimg.cn/1bbeecca6dcd44888905efaae4fab004.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_16,color_FFFFFF,t_70,g_se,x_16)
goto label2
fmt.Println("ok1")
fmt.Println("ok2")
fmt.Println("ok3")
label2:
fmt.Println("ok4")
fmt.Println("ok5")
fmt.Println("ok6")
return
return使用在方法或者函数中,表示跳出所在的函数或方法
函数和方法
//基本语法:
func 函数名 (形参列表) (返回值列表){
执行语句...
return 返回值列表
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3JzRxHcD-1646573975901)(http://h9x14s4c.xyz/img/202111221855571.png)]](https://img-blog.csdnimg.cn/2c0a51dad07b45aca8c2f3b461453d4a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_12,color_FFFFFF,t_70,g_se,x_16)
包
包的本质实际上就是创建不同的文件夹,用来存放程序文件
//包的引入
import (
"fmt"
"go_code/chapter01/model"
)
//使用
testModel := model.TestModelName
fmt.Println(testModel)
包的使用细节
- 在给一个文件打包时,该包对应一个文件夹,比如这里的utils文件夹对应的包名就是utils,文件的包名通常和文件所在的文件夹一致,一般为小写字母
- 当一个文件要使用其他包函数或变量时,需要先引入对应的包
- package指令在文件第一行,然后时import指令
- 在import包时,路径从$GOPATH的src下开始,不用带src,编译器会自动从src下开始引入
- 为了让其他包的文件可以访问到本包的函数,则该函数名的首字母需要大写,类似其他语言的public,这样才能跨包访问
- 在访问其他包函数时,其语法是包名.函数名,比如这里的main.go文件中
- 如果包名较长,go支持给包名取别名,注意细节:取别名后,原来的包名就不能用了
import (
"fmt"
util "go_code/chapter01/model"
)
-
在同一包下,不能有相同的函数名,(也不能有相同的全局变量)否则报重复定义
-
如果你要编译成一个可执行程序文件,就需要将这个包声明为main,即package main 这个就是一个语法规范,如果你是写一个库,包名可以自定义。
库
在打包完成后,会一并生成一个库文件,在这个库文件中,我们可以使用这个库中所有定义的函数方法(二进制)
函数的调用过程
对函数调用机制的说明:
- 在调用一个函数时,会给该函数分配一个新的空间,编译器会通过自身的处理让这个新的空间和其他的栈的空间区分开
- 在每个函数对应的栈中,数据空间时是空间的,不会混淆
- 当一个函数调用完毕(执行完毕)后,程序会销毁这个函数对应的栈空间。
return语句
go函数支持返回多个值,这一点是其他编程语言没有的
- 如果返回多个值时,在接收时希望忽略某个值,可以用_符号表示忽略
- 如果返回值只有一个,返回值类型列表可以不写
递归调用
一个函数在函数体内又调用了本身
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HdvF3OtL-1646573975902)(http://h9x14s4c.xyz/img/202111221950179.png)]](https://img-blog.csdnimg.cn/87e6babfb9074d0a93bac5674713700d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IERMtkBY-1646573975902)(http://h9x14s4c.xyz/img/202111221953353.png)]](https://img-blog.csdnimg.cn/2897dcc631ce4803b643200047474a95.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
递归需要遵守的重要原则:
- 执行一个函数时,就创建一个新的受保护的独立空间(新函数栈)
- 函数的局部变量是独立的,不会相互影响
- 递归必须向退出递归的条件逼近,否则就是无限递归
- 当一个函数执行完毕,或者遇到return,就会返回,遵守谁调用,就将结果返回给谁,同时当函数执行完毕或者返回时,该函数本身也会被系统销毁
练习:
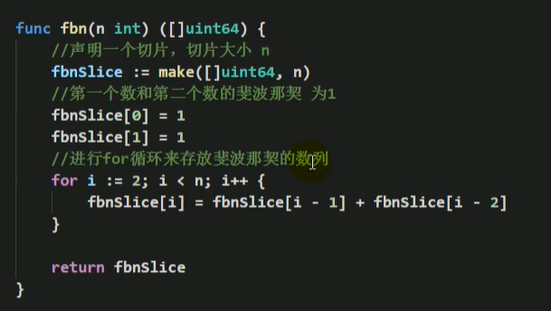
斐波那契数:
func fbn(n int) int {
if n == 1 || n == 2 {
return 1
} else {
return fbn(n-1) + fbn(n-2)
}
}
函数注意事项和使用细节
- 函数的形参列表可以时多个,返回值类型也可以是多个
- 形参列表和返回值列表的数据类型可以是值类型和引用类型
- 函数的命名遵循表示符命名规范,首字母不能是数字,首字母大写该函数可以被本包文件和其他包文件使用,类似public,首字母小写,只能被本包文件使用,类似private
- 函数中变量是局部的,函数外不生效
- 基本数据类型和数组默认都是值传递的,即进行值拷贝,在函数内修改,不会影响到原来的值
- 如果希望函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以指针的方式操作变量。从效果上类似引用
- go函数不支持重载
- 在go中,函数也是一种数据类型,可以赋值给一个变量,则该变量就是一个函数类型的变量了。通过该变量可以对函数的调用
- 函数既然是一种数据类型,因此在go中,函数可以作为形参并且调用
- 为简化数据类型定义,go支持自定义数据类型
基本语法: type 自定义数据类型名 数据类型//相当于别名
例子:type myInt int //这时myInt可以当作int使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c3zrClFG-1646573975903)(http://h9x14s4c.xyz/img/202111222231988.png)]
type mySum func(int, int) int
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5kh6Z1QW-1646573975904)(http://h9x14s4c.xyz/img/202111222233737.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-flzNU2kS-1646573975904)(http://h9x14s4c.xyz/img/202111222237686.png)]
-
支持对函数返回值命名
-
使用下划线_标识符,忽略返回值
-
go可支持可变参数
- 支持0到多个参数
- 支持1到多个参数
- 如果一个函数的形参列表中有可变参数,则可变参数需要放在形参列表最后
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H0LGxvWl-1646573975905)(http://h9x14s4c.xyz/img/202111222255738.png)]
init函数
每一个源文件都可以包含一个init函数,该函数会在main函数执行前,被go运行框架调用,也就是说init会在main函数前被调用,通常用于完成一些初始化操作
init使用细节
- 如果一个文件同时包含全局变量定义,init函数和main函数,则执行的流程是全局变量定义->init函数->main函数
- init函数最主要的作用,就是完成一些初始化的工作
//------ model.go
package model
import "fmt"
// TestModelName 首字母大写是公有的
var TestModelName string
func init() {
fmt.Println("model包的init()")
TestModelName = "测试值"
}
//----- main.go
package main
import (
"fmt"
util "go_code/chapter01/model"
)
func main() {
testModel := util.TestModelName
fmt.Println(testModel)
}
- 如果引入包中和main.go中都含有变量定义,init函数(初始化函数)那执行流程应该如何呢
A:先执行引入变量的全局变量定义,init函数,然后再执行本文件中的全局变量定义,init函数(先后顺序)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3ZcYvkRC-1646573975905)(http://h9x14s4c.xyz/img/202111230844099.png)]
匿名函数
go支持匿名函数,如果我们某个函数只希望使用一次,可以考虑使用匿名函数,匿名函数也可以实现多次调用
匿名函数使用方式
- 在定义匿名函数时就直接使用
// 定义匿名函数,在定义时直接使用
res1 := func(n1 int, n2 int) int{
return n1 + n2
}(0, 20)
- 将匿名函数赋给一个变量,再通过该变量来调用匿名函数
// 赋值给一个变量,可以用这个变量来返回调用
a := func(n1 int, n2 int) int{
return n1 - n2
}
res2 := a(0,20)
fmt.Println(res2)
全局匿名函数
如果将匿名函数赋给一个全局变量,那么这个匿名函数,就成为一个全局匿名函数,就可以在程序有效
var (
Func1 = func(n1 int, n2 int) int{
return n1 + n2
}
)
res3 := Func1(0,20)
fmt.Println(res3)
闭包
闭包就是一个函数和与其相关的引用环境组合的一个整体(实体)
// AddUpper 累加器
func AddUpper() func(int) int{
var n = 10
return func(x int) int{
n = n + x
return n
}
}
f := AddUpper()
fmt.Println(f(1))
fmt.Println(f(3))
由上可以得出:
-
AddUpper是一个函数,返回的数据类型是func (int) int,返回的是一个匿名函数,但这个函数引用到函数外的n,因此这个匿名函数就和n形成一个整体,构成闭包
-
也可以这样理解:闭包是一个类,函数是操作,n是字段,函数和它使用到的n构成闭包。
-
当我们反复的调用f函数时,因为n是初始化一次,因此我们没调用一次就进行累加
-
搞清楚闭包的关键,就是要分析出返回的函数它使用到哪些变量,因为函数和它引用到的变量共同构成闭包
-
也就是说:当我们反复调用闭包的时候,闭包里面定义的变量不会被反复初始化,而只会初始化一次
闭包的练习
// makeSuffix 判断文件名有无指定后缀,
//有则返回文件名全称,无则返回文件名加此后缀
func makeSuffix(suffix string) func(string) string {
return func(name string) string {
//判断传入文件名有无指定后缀
if !strings.HasSuffix(name, suffix) {
return name + suffix
} else {
return name
}
}
}
make := makeSuffix(".jpg")
str3 := make("winter.jpg")// 传入有.jpg 后缀的名称则返回全称,无则自动加上
fmt.Println(str3)
defer
在函数中,程序员需要经常创建资源,比如:数据库连接,文件句柄,锁等,为了在函数执行完毕后,及时的释放资源,go的设计者提供了defer(延时机制)
// sumDefer defer延时机制运行说明
func sumDefer(n1 int, n2 int) int{
// 当执行到defer时,暂时不执行,
//会将defer后面的语句压入到独立的栈(defer栈)
defer fmt.Println("ok1 n1=", n1)
defer fmt.Println("ok2 n2=", n2)
res := n1 + n2
fmt.Println("ok3 res = ", res)
return res
}
res4 := sumDefer(10, 20)
fmt.Println("res4=", res4)
defer的细节说明
- 当go执行到一个defer时,不会立即执行defer后的语句,而是将defer后的语句压入到一个栈中。然后继续执行函数的下一个语句。
- 当函数执行完毕后,在从defer栈中,依次从栈顶取出语句执行(注意:遵守栈先入后出的机制)
- 在defer将语句放入到栈时,也会将相关的值拷贝同时入栈;
释放资源演示:
// 关闭文件资源
func testDefer1(){
file = openFile(文件名)
defer file.close()
}
//关闭数据库资源
func testDefer2(){
connect = openDatabese(文件名)
defer connect.close()
}
函数参数的传递方式
在参数类型里,有值类型和引用类型,这里函数的参数传递类型里,也有值传递和引用传递,而函数传递的默认类型就是引用传递
- 值传递
- 引用传递
其实,不管是值传递还是引用传递,传递给函数的都是变量的副本,不同的是,值传递的是值的拷贝,引用传递的是地址的拷贝,一般来说,地址拷贝效率高,因为数据量小,而值拷贝决定拷贝的数据大小,数据越大,效率越低
变量作用域
- 函数内部声明/定义的变量叫局部变量,作用域仅限于函数内部
- 函数外部声明/定义的变量叫全局变量,作用域在整个包都有效,如果其首字母都为大写,则作用域在整个程序有效
- 如果变量是在一个代码块,比如for/if中,那么这个变量的作用域就在该代码块
注意:赋值语句不能在函数体外执行
字符串中常用的系统函数
- 统计字符串长度,按字节len(str)
- 字符串遍历r:=[]rune(str)
- 字符串转整数n,err:=strconv.Atoi(“12”)
n,err := strconv.Atoi("12")
if err == nil{//如果转换成功会错误会返回nil,我们可以对错误进行一个是否等于"nil"判断,来判断是否转换成功
fmt.Println("err:",n)
}else{
fmt.Println("err:",err)
}
- 整数转字符串str=strconv.Itoa(12345)
- 字符串转字节[]byte:var bytes=[]byte(“hello go”)
- 字节转字符串 :str=string([]byte{97,98,99})
- 十进制转2、8、16进制:str=strconv.FormatInt(123,2)//返回对应的字符串
- 查找子串是否在指定的字符串中strings.Contains(“seafood”,“foo”)//true
- 统计一个字符串有几个指定的字串:strings.Count(“ceheese”,“e”)//4
- 不区分大小写的字符串比较(==是区分字母大小写的):fmt.Println(strings.EqualFold(“abc”,“Abc”))//true
- 返回字串在字符串第一次出现的index值,没有则返回-1:strings.Index(“NLT_abc”,“abc”)//4
- 返回字串在字符串最后一次出现的index,没有则返回-1:strings.LastIndex(“go golang”,“go”)
- 将指定的字串替换成另外一个字串:strings.Replace(“go go hello”,“go”,“go语言”,n)n可以指定你希望替换几个,如果n=-1表示全部替换//值拷贝
- 按照指定的某个字段,为分割表示,将一个字符串拆分成字符串数组:strings.Split(“hello,word,ok”,",")//值拷贝
- 将字符串的字母进行大小写的转换:strings.ToLower(“Go”)//go strings.ToUpper(“Go”)//Go
- 将字符串左右两边的空格去掉:strings.TrimSpace(“tn a lone gopher ntrn”)
- 将字符串左右两边指定的字符去掉:stringsTrim("! hello!"," !")//[“hello”]//将左右两边!和""去掉
- 将字符串左边指定的字符去掉:stringsTrimLeft("! hello!"," !")//[“hello!”]//将左边!和""去掉
- 将字符串右边边指定的字符去掉:stringsTrimRight("! hello!"," !")//["!hello"]//将右边!和""去掉
- 判断字符串是否以指定的字符串开头:strings.HasPrefix(“ftp://192.168.10.1”,“ftp”)//true
- 判断字符串是否以指定的字符串结束:strings.HasSuffix(“aa.jpg”,“jpg”)//true
更多具体请查看手册
日期和时间相关函数
需要引入time包
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XK7x7c2V-1646573975906)(http://h9x14s4c.xyz/img/202111231125553.png)]](https://img-blog.csdnimg.cn/c153c8b614df4a5dbd7ecc82885f4027.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_12,color_FFFFFF,t_70,g_se,x_16)
格式化日期时间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uy4ymVeU-1646573975907)(http://h9x14s4c.xyz/img/202111231128445.png)]](https://img-blog.csdnimg.cn/eae6e0c8a2864684b5ed0eeed5c1c9b4.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FqCRnKq3-1646573975907)(http://h9x14s4c.xyz/img/202111231131015.png)]](https://img-blog.csdnimg.cn/4f63d4db8f304c69a1dc7aaa83fc7aec.png)
时间常量
在程序中可用于获取指定时间单位的时间,比如想得到100毫秒100*time.Millisecond
const (
Nanosecond Duration = 1
Microsecond = 1000 * Nanosecond
Millisecond = 1000 * Microsecond
Second = 1000 * Millisecond
Minute = 60 * Second
Hour = 60 * Minute
)
休眠
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NGFaNlkj-1646573975908)(http://h9x14s4c.xyz/img/202111231138422.png)]](https://img-blog.csdnimg.cn/ffe5249b83064337bb6eb51eaf0f6def.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_14,color_FFFFFF,t_70,g_se,x_16)
获取当前unix时间戳和unixnano时间戳
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w5cJpy1A-1646573975908)(http://h9x14s4c.xyz/img/202111231146044.png)]](https://img-blog.csdnimg.cn/d85e1683075d474b8e462a732caf7d89.png)
获取程序运行时间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qHFlMiaP-1646573975909)(http://h9x14s4c.xyz/img/202111231149703.png)]](https://img-blog.csdnimg.cn/e1c9c96fb9b64ecdaae28877912b8793.png)
内置函数
- len:用来求长度
- new:用来分配内存,主要用来分配值类型,比如int、float32(赋的值是一个指针类型)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NgYHo0cw-1646573975909)(http://h9x14s4c.xyz/img/202111231157467.png)]](https://img-blog.csdnimg.cn/4281ddd51dc144ce84f2c32e276877a0.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
- make:用来分配内存,主要用来分配引用类型,比如channel、map、slice
错误处理
- go中不支持传统的try…catch…finally这种处理
- go中引入的处理方式为:defer,panic,recover//recover是一个内置函数,可以捕获到异常
- go中可以抛出一个panic异常,然后再defer中通过recover捕获这个异常,然后正常处理
func testPanic(){
// 使用defer+recover 来捕获和处理异常
defer func(){
err := recover()
if err != nil {
fmt.Println("err=", err)
}
}()
num1 := 10
num2 := 0
res := num1/num2
fmt.Println("res=", res)
}
自定义错误
go中,也支持自定义错误,使用error.New和panic内置函数
- errors.New(“错误说明”),会返回一个error类型的值,表示一个错误
- panic内置函数,接收一个interface{}类型的值(也就是任何值)作为参数。可以接收error类型的变量,输出错误信息,并退出程序
数组和切片
数组
引入问题:为什么需要数组:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sKQSohN2-1646573975910)(http://h9x14s4c.xyz/img/202111241150441.png)]](https://img-blog.csdnimg.cn/2baf05c074be415786528ed7626ba395.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
数组可以存放多个同一类型数据,数组也是一种数据类型,在go中,数组是值类型
数组定义:
var 数组名 [数组大小] 数组类型
var a [5]int
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yD3JWcn2-1646573975911)(http://h9x14s4c.xyz/img/202111241301444.png)]](https://img-blog.csdnimg.cn/b66900336b154d9dac1c69c3dc66fa5c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
-
数组的地址可以通过数组名来获取&intArr
-
数组的第一个元素的地址,就是数组的首地址
-
第一个之后的数组元素地址就是在之前地址上+该数组的字节数
(数组的各个元素的地址间隔是依据数组的类型决定,比如int64->8个字节,int32->4个字节
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eVR7cMUJ-1646573975911)(http://h9x14s4c.xyz/img/202111241304649.png)]](https://img-blog.csdnimg.cn/abc49daca86649408b63c4a71f830b07.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
数组的使用
数组名[下标]:a[2]
四种数组初始化方式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dDhN8qBF-1646573975912)(http://h9x14s4c.xyz/img/202111241435852.png)]](https://img-blog.csdnimg.cn/3b1d66a5258b428abeb47c79bad1fc36.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_17,color_FFFFFF,t_70,g_se,x_16)
数组的遍历
- for循环常规遍历
- for-range结构遍历
bigDay := []int{1, 3, 5, 7, 8, 10, 12}
isEx := false
for _, eachItem := range bigDay { //大天数:31天
if eachItem == month { //存在这个月份开关为true
isEx = true
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q4glmrut-1646573975912)(http://h9x14s4c.xyz/img/202111241439635.png)]](https://img-blog.csdnimg.cn/d9866dcdf0a14554acf7dc432be90651.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
数组使用注意事项和细节
- 数组是多个相同类型数据的组合,一个数组一旦声明/定义了其长度是固定的,不能动态变化。
- var arr []int 这时arr就是一个slice切片,切片后面专门讲解
- 数组中的元素可以是任何数据类型,包括值类型和引用类型,但是不能混用
- 数组创建后,如果没有赋值,有默认值数值类型数组默认0,字符串类型默认"",bool类型默认false
- 使用数组步骤,声明数组并开辟空间,给数组各个元素赋值,使用
- 数组的下标是从0开始的
- 数组下标必须在指定范围内使用,否则报panic,数组越界
- go的数组属于值类型,在默认情况下是值传递,因此会进行值拷贝,数组间不会相互影响
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RjVCU0hd-1646573975913)(http://h9x14s4c.xyz/img/202111241456241.png)]](https://img-blog.csdnimg.cn/5c6efdcefde7491c8df5950047e029a3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
-
如想在其他函数中去去修改原来的数组,可以使用引用传递(指针方式)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-00jve0xH-1646573975913)(http://h9x14s4c.xyz/img/202111241456660.png)]](https://img-blog.csdnimg.cn/7db7b77652f246e1b2c8c220999c1ca6.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
-
长度是数组类型的一部分,在传递函数参数时,需要考虑数组的长度
练习:
- 循环打印A-Z
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CtRnwELv-1646573975914)(http://h9x14s4c.xyz/img/202111241502091.png)]](https://img-blog.csdnimg.cn/76b45df9f5c04fadba6b3be8e779133c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
- 查找数组中最大值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hDBOl9Tl-1646573975914)(http://h9x14s4c.xyz/img/202111241504168.png)]](https://img-blog.csdnimg.cn/c8e6b3fac2294343a23aa3ca3b910e02.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_18,color_FFFFFF,t_70,g_se,x_16)
- 数组求和及平均值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SAIj5pL1-1646573975915)(http://h9x14s4c.xyz/img/202111241507082.png)]](https://img-blog.csdnimg.cn/ec75bd618dd644459c5fca3817f5aef0.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
- 随机生成5个数,并将其反转打印
- 注意:随机生成数需要设置每次激活的种子,通常选用纳秒
- 数组反转的关键:第一个元素与最后一个元素进行交换,交换长度为数组的一半,最后一个元素为数组长度-1-i(为什么-1
- i,因为通过循环交换,在多次交换需要更换最后一位元素)
- 通过一个临时变量,将最后一个值赋给临时变量,第一个值赋给最后一个值,临时变量赋给第一个值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oazYzuay-1646573975915)(http://h9x14s4c.xyz/img/202111241523961.png)]](https://img-blog.csdnimg.cn/27b04e10c7e9441ba0faedb8b6e1b93f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
多维数组
二维数组
使用方式
先声明/定义再赋值
- 语法:var 数组名[大小][大小]类型
- 比如:var arr [2][3]int[][],再赋值
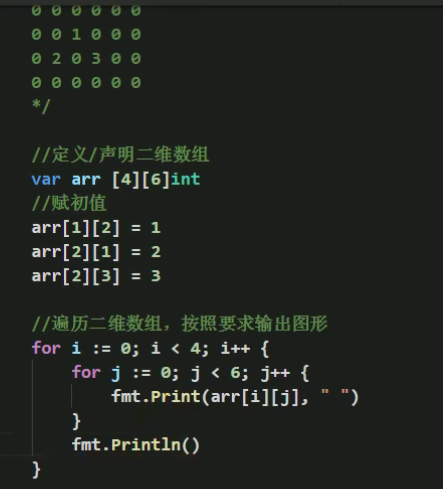
内存分布:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nF0xkOm3-1646573975916)(http://h9x14s4c.xyz/img/202111251035029.png)]](https://img-blog.csdnimg.cn/2e864bf1e3d5431382e718b76f2458db.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
直接初始化
- 声明:var 数组名 [][][长度][长度]类型 = [长度][长度]类型{{初值…},{初值…}}
- 赋值(有默认值,比如int 类型就是0)
- 二维数组在定义与声明时也有对应的四种写法【和一维数组类似】
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-06XoGR2u-1646573975916)(http://h9x14s4c.xyz/img/202111251042250.png)]](https://img-blog.csdnimg.cn/8ad5ec46016b499eba382177d0480b83.png)
二维数组遍历
- 双层for循环完成遍历
- for-range方式完成遍历

练习:
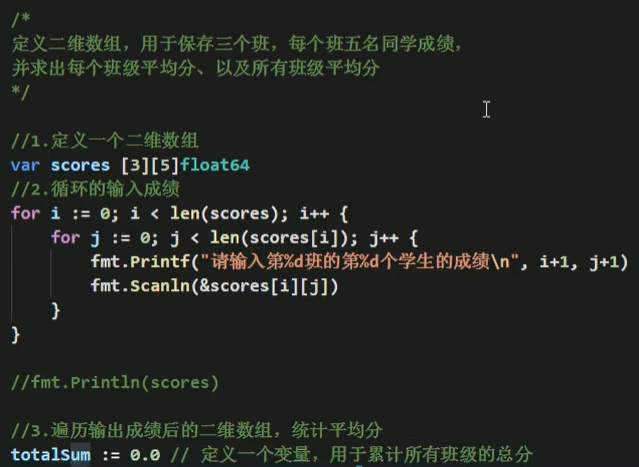

数组练习:

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o1oyLYPn-1646573975918)(http://h9x14s4c.xyz/img/202111251105232.png)]](https://img-blog.csdnimg.cn/3031504fa9344b2fb081b3018963abb3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5bI6iTCo-1646573975919)(http://h9x14s4c.xyz/img/202111251106258.png)]](https://img-blog.csdnimg.cn/f6c2623b26624d7183b7229f83ed3ea7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
切片
- 切片:slice
- 切片是数组的一个引用,因此切片是引用类型,在进行传递时,遵守引用传递的机制
- 切片的使用和数组类似,遍历切片、访问切片的元素和求切片长度len(slice)都一样
- 切片的长度时可以变化的,因此切片是一个可以动态变化的数组
- var 变量名 []类型 :var a []int
- 切片引用的范围不包括最后下标位置
- slice := intArr[1:3] //不包含下标3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fOj3UyRx-1646573975919)(http://h9x14s4c.xyz/img/202111241532697.png)]](https://img-blog.csdnimg.cn/73dfb7ac99c543fcbca0941e475a01ba.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
切片在内存中的形式
- 切片底层的数据结构可以理解成是一个结构体
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vLlsLN25-1646573975920)(http://h9x14s4c.xyz/img/202111241541914.png)]](https://img-blog.csdnimg.cn/dcfe96ab7fd749da9742deed75096693.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
切片的使用
- 定义一个切片,然后去引用一个已经创建好的数组
- 通过make来创建切片
- var 切片名 []type = make([],len,[cap])
- 说明:type是数据类型,len大小,cap指定切片容量(可选),cap>=len
- 如果没有给切片各个元素赋值,那么会使用默认值,数组默认0,字符串类型默认"",bool类型默认false
- 通过make创建的切片由make底层维护,对外不可见,只能通过slice去访问各个元素

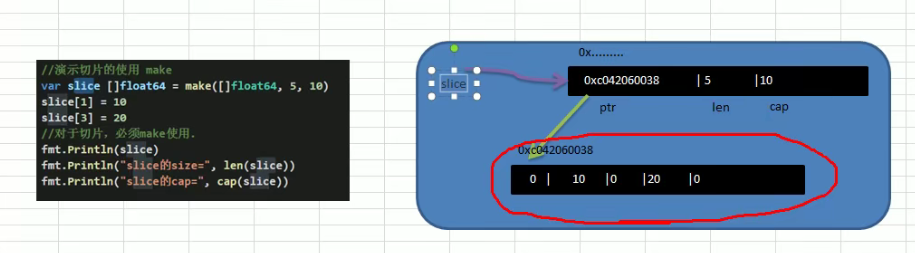
- 定义一个切片,直接就指定具体数组,原理类似make的方式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CgRxMDRS-1646573975922)(http://h9x14s4c.xyz/img/202111241552295.png)]](https://img-blog.csdnimg.cn/90da0761dfa64256aa4954f87f824265.png)
使用区别:
- 直接引用数组,这个数组是事先存在的,程序员可见
- 通过make来创建切片,make也会创建一个数组,但是又切片在底层进行维护,外部不可见
切片的遍历
- for循环常规遍历
- for-range结构遍历
切片注意事项和细节说明
-
切片初始化时,var slice = arr[startIndex:endIndex]
- 从arr数组下标为startIndex开始,取到下标为endIndex的元素结束(不含endIndex它本身)
- 切片初始化时,仍然不能越界,范围在[0-len(arr)]之间,但是可以动态增长
-
切片简写
- var slice = arr[0:end]->var slice = arr[:end]
- var slice = arr[start:len(arr)]->var slice = arr[start:]
- var slice = arr[0:len(arr)]->var slice = arr[:]
-
cap 是一个内置函数,用于统计切片的容量,即最大可以存放多少个元素
-
切片定义完后还不能使用,因为本身是一个空的,需要让其引用到一个数组或meke一个空间提供切片来使用
-
切片可以继续切片
-
用append内置函数,可以对切片进行动态追加
- 切片append操作的本质就是对数组扩容
- go底层会创建一下新的数组newArr(安装扩容后大小)
- 将slice原来包含的元素拷贝到新的数组newArr
- slice重新引用到newArr
- 注意newArr是在底层来维护的,程序员不可见


- 切片的拷贝操作copy ,注意拷贝类型都需要是切片类型,被拷贝到切片中的值会替换原来切片的值,切片容量在拷贝时不会改变,但是对应的值会根据相应的情况覆盖或被覆盖/不变
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XCiXYbwM-1646573975924)(http://h9x14s4c.xyz/img/202111241618314.png)]
string 和 slice
- string底层是一个byte数组,因此string也可以进行切片处理
- string和切片在内存的形式
- string是不可变的,也就说不能通过str[0] = 'z’方式来修改字符串
- 如果需要修改字符串,可以先将string ->[]byte /或者 []rune -> 修改 ->重写转成string
- byte通常用于修改二进制编码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pHwyJWNO-1646573975925)(http://h9x14s4c.xyz/img/202111241632608.png)]
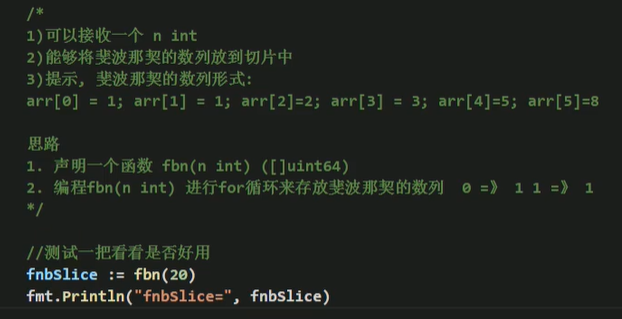
练习:使用切片存放斐波那契数:
排序和查找
排序
-
内部排序
- 指将需要处理的所有数据都加载到内部存储器中进行排序
- 包括(交换式排序法、选择式排序法和插入式排序法)
-
外部排序法:
- 数据量过大,无法全部加载到内存中,需要借助外部存储进行排序,包括(合并排序法和直接合并排序法)
交换式排序法
- 冒泡排序
- 快速排序
冒泡排序
一共会经过arr.length-1此轮数比较,每一轮将会确定一个数的位置,每一轮的比较次数在逐渐减少,当发现前面一个数比后面的一个数大的时候,就进行了交换
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zmp6mYAE-1646573975926)(http://h9x14s4c.xyz/img/202111241655141.png)]](https://img-blog.csdnimg.cn/710e25901a214f219674eb7e63467e7e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
// BubbleSort 冒泡排序
func BubbleSort(arr *[]int) {
fmt.Println("排序前:", *arr)
temp := 0 //临时变量
// 循环体
for i := 0; i < len(*arr)-1; i++ {
for j := 0; j < len(*arr)-1-i; j++ { //-i是为了节省内存
if (*arr)[j] > (*arr)[j+1] {
// 交换
temp = (*arr)[j] //第一个赋值给临时变量(最大)
(*arr)[j] = (*arr)[j+1] // 小的给大的
(*arr)[j+1] = temp // 最大的给最小的
}
}
}
fmt.Println("排序后:", *arr)
}
slices := []int{5, 15, 98, 8, 4, 7}
BubbleSort(&slices)
- 个人总结:先写出一层循环,将最大的一个放到最后,然后再套一层循环,用于重复操作直至排完,优化点:每次比较的长度都跟循环次数有关
快速排序
// QuickSort 快速排序
func QuickSort(arr []int, start, end int) {
if start < end {
i, j := start, end
key := arr[(start+end)/2] //划分基准值
fmt.Println("开始进入的arr:", arr)
fmt.Println("key:", key)
for i <= j {
for arr[i] < key { // 当arr[i]<key基准值,从左往右不断扫描
i++
}
for arr[j] > key { // 当arr[i]>key基准值,从右往左不断扫描
j--
}
if i <= j { //交换 arr[i]和 a[j]的元素
arr[i], arr[j] = arr[j], arr[i]
i++
j--
}
}
if start < j {
QuickSort(arr, start, j)
}
if end > i {
QuickSort(arr, i, end)
}
fmt.Println("交换后arr:", arr)
}
}
arr := []int{3, 7, 9, 8, 38, 93, 12, 222, 45, 93, 23, 84, 65, 2}
QuickSort(arr, 0, len(arr)-1)
fmt.Println(arr)
查找
- 顺序查找
- 二分查找(该数组是有序)
顺序查找
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zhhdcw8a-1646573975927)(http://h9x14s4c.xyz/img/202111241851684.png)]](https://img-blog.csdnimg.cn/5f7191e5c9cd4fb3addb47ea6be3db78.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)

二分查找
逻辑:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QuKFaXDY-1646573975929)(http://h9x14s4c.xyz/img/202111241905900.png)]](https://img-blog.csdnimg.cn/12cac97429d44b0bbb9481bd4fc4f05a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
map
map是key-value数据结构,又称为字段或者关联数组。类似其它编程语言的集合。(一种数据结构。是一个映射,也叫集合。)
基本语法
var map 变量名 map[keytype]valuetype
key可以是什么类型:(多种)bool,数字,string,指针,channel,还可以是只包含前面几个类型的接口,结构体,数组,通常为int、string
注意:slice,map,还有function不能作为key,因为这几个没法用==来判断
map声明是不会分配内存的,初始化需要make,分配内存后才能赋值和使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fidGheX7-1646573975929)(C:/Users/86150/AppData/Roaming/Typora/typora-user-images/image-20211125144535610.png)]
- map使用前一定要用make分配内存空间
- map中的key不能重复,如果重复,则以最后一个key-value为准
- map的value可以是相同的
- map的key-value是无序的
func make
func make(Type, size IntegerType) Type
内建函数make分配并初始化一个类型为切片、映射、或通道的对象。其第一个实参为类型,而非值。make的返回类型与其参数相同,而非指向它的指针。其具体结果取决于具体的类型:
切片:size指定了其长度。该切片的容量等于其长度。切片支持第二个整数实参可用来指定不同的容量;
它必须不小于其长度,因此 make([]int, 0, 10) 会分配一个长度为0,容量为10的切片。
映射:初始分配的创建取决于size,但产生的映射长度为0。size可以省略,这种情况下就会分配一个
小的起始大小。
通道:通道的缓存根据指定的缓存容量初始化。若 size为零或被省略,该信道即为无缓存的。
map的使用方式
-
方式1
- 声明,这是map=nil,需要用make分配内存空间
-
方式2
- 声明就直接make
- var cities = make(map[string][string])
- 声明就直接make
-
方式3
-
声明直接赋值
-
var cities map[string]string = map[string]string{
“no1”,“广东”}
-
-

map的CRUD
-
增加和更新
- 若key存在则更新,不存在则新增
-
map的删除
- 通过内置函数delete(map,“key”),delete是一个内置函数,如果key存在,就删除key-value,如果key不存在,不操作,但是也不会报错
func delete
func delete(m map[Type]Type1, key Type)内建函数delete按照指定的键将元素从映射中删除。若m为nil或无此元素,delete不进行操作。
-
如果想一次性删除所有key
- 遍历所有key
- make一个新空间 citys = make(map[string]string)
-
map的查找
val, ok := cities["no1"]//返回两个值分别是值和是否存在类型
if ok {
fmt.Println("...")
}
- map的遍历
使用for-range进行遍历
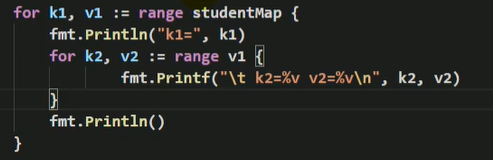
- map的长度
使用len()内置函数
map切片
动态存放map数据
如果切片的数据类型是map,则称为map切片,这样map个数就能动态变化了

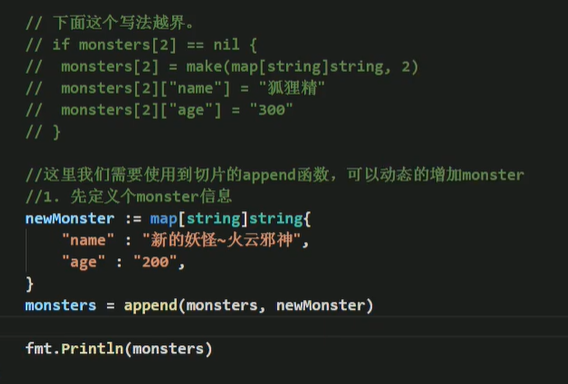
map排序
- golang中没有专门的方法对map的key进行排序
- golang中map默认是无序的,也不是按照存放的先后进行排序,每次遍历都有可能得到不一样的结果
- golang中map的排序,是先将key进行排序,然后根据key值遍历输出即可
- 做法通常先将key放进切片中,将其排序,然后再遍历切片,输出map即可
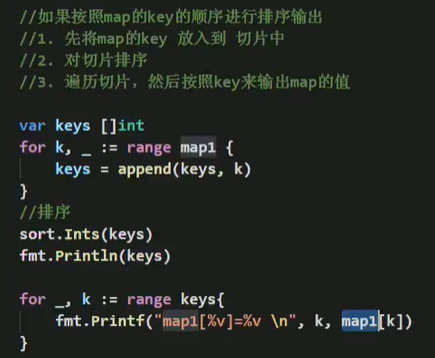
map使用细节
- map是引用类型,遵守引用类型传递机制,在一个函数接受map,修改后会直接修改原来的map
- map的容量达到后,再想map增加元素,会自动扩容,并不会发生panic,也就是说map能动态的增长键值对(key-value)
- map的value也经常使用struct类型,更适合管理复杂的数据(比前面value是一个map更好),比如value为Student结构体
//定义结构体,类似class
type Stu struct {
Name string
Age int
Address string
}
students := make(map[string]Stu)
stu1 := Stu{"tom", 18, "北京"}//注意用{}
stu2 := Stu{"mary", 21, "上海"}
students["no1"] = stu1
students["no2"] = stu2
fmt.Println(students)
for k,v := range students {
fmt.Printf("学生的编号是%v\n", k)
fmt.Printf("学生的名字是%v\n", v.Name)//调用结构体属性,类似调用json
fmt.Printf("学生的年龄是%v\n", v.Age)
fmt.Printf("学生的地址是%v\n", v.Address)
}
exe:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-09z1NWiV-1646573975933)(http://h9x14s4c.xyz/img/202111251936694.png)]
结构体
使用现有技术解决
- 单独定义变量解决 --复杂
- 使用数组解决 — 不好定位处理
结构体:对象
结构体说明:
- golang也支持面向对象编程(OOP),但是和传统的面向对象编程有区别,并不是纯粹的面向对象语言。所以我们说golang支持面向对象编程特性是比较准确的
- golang没有class,go语言的结构体(struct)和其他编程语言的类(class)有同等的地位,你可以理解golang是基于struct来实现OOP特性的
- golang面向对象编程非常简洁,去掉了传统OOP语言的继承、方法重载、构造函数和析构函数、隐藏的this指针等等
定义结构体


结构体和结构体变量(实例)的区别和联系
- 结构体是自定义的数据类型,代表一类事物
- 结构体变量(实例)是具体的,实际的,代表一个具体变量
- 结构体-值类型
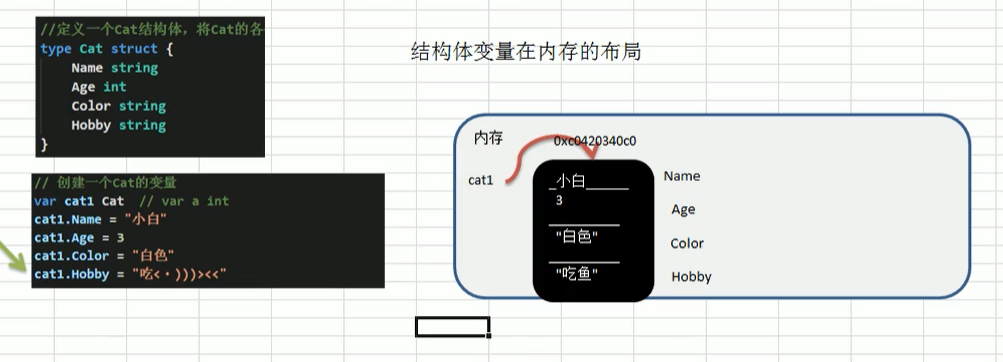
声明结构体
定义
type 结构体名称 struct{//这里遵循变量名大小写公私有定义规则
field1 type
field2 type
}
字段/属性
- 从概念或叫法上看:结构体字段=属性=field
- 字段是结构体的一个组成部分,一般是基本数据类型、数组,也可以是引用类型。
字段/属性注意事项和细节说明
- 字段声明语法同变量,例:字段名 字段类型
- 字段的类型可以为:基本类型、数组或引用类型
- 在创建一个结构体变量后,如果没有给字段赋值,都会对应一个默认值,规则同之前一样;注意:如果字段类型是引用类型如指针slice或map时,它们的默认值是nil,即还没有分配空间
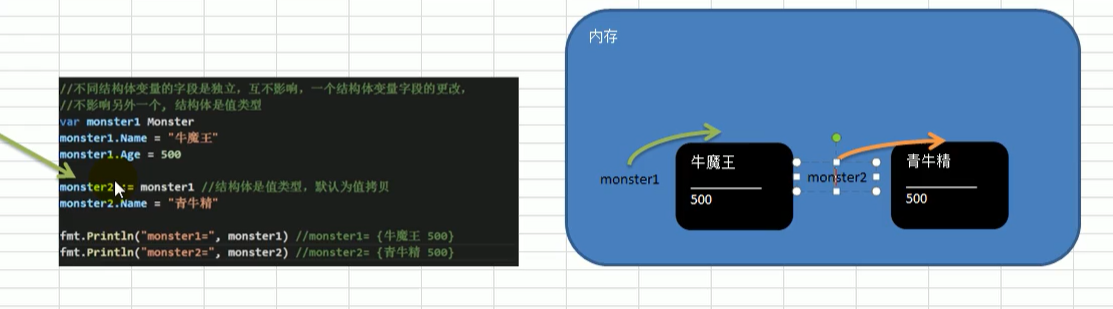
- 不同结构体变量的字段是独立,互不影响的,一个结构体变量字段的更改,不影响另外一个


注意:引用类型在赋值时一点要先make分配数据空间,因为结构体是值类型,所以在字段赋值时不会改变原来字段内容,这里做的操作是值拷贝
创建结构体变量和访问结构体字段
- 直接声明 varperson Person
- {} :var person Person = Person{}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GsLrDhA3-1646573975938)(http://h9x14s4c.xyz/img/202111260849748.png)]
- 使用指针 :var person *Person = new{Person}
- 使用指针,{}:var person *Person = &Person{}
说明:
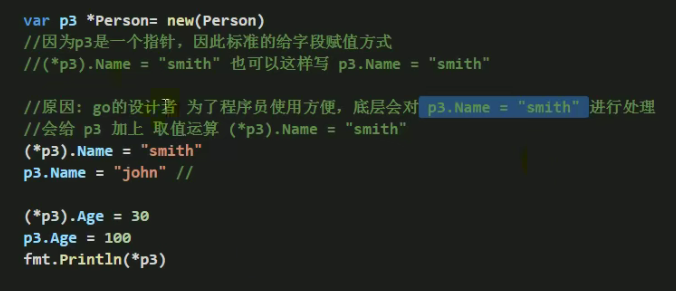
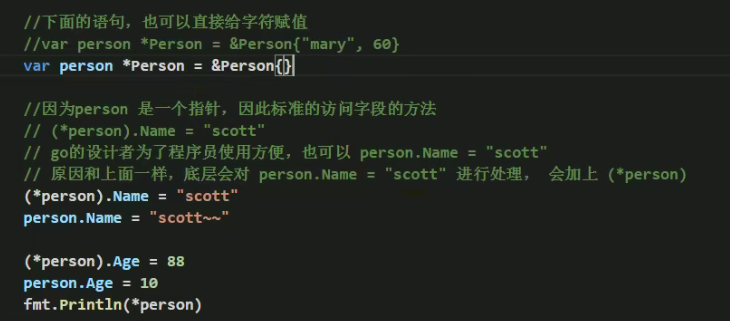
1)第3、4种方式返回的是结构体指针。
2)结构体指针访问字段的标准方式应该是:(*结构体指针).字段名。例:(*person).Name=“Tom”
3)但go做了一个简化,也支持结构体指针.字段名,例:person.Name=“tom”。更加符合程序员使用的习惯,go编译器底层对person.Name做了转化(*person).Name
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uTNyO6b4-1646573975939)(http://h9x14s4c.xyz/img/202111260910907.png)]
注意:为什么fmt.Println(*p2.Age)这样写是错误的,原因是运算符"."的优先级比*高,如果这样写,意思就是先取出p2.Age这个值再按照它的值当指针进行取值
结构体的注意事项和使用细节
- 结构体的所有字段在内存中是连续的,指针本身的地址还是连续的,但是指向的地址不一定是连续的
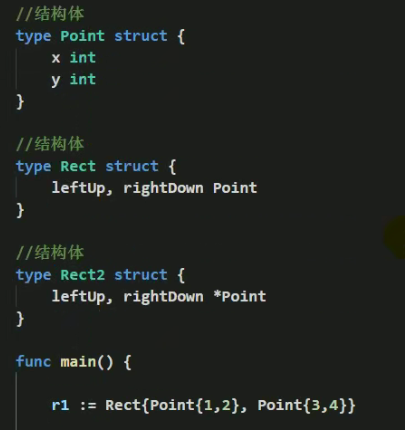
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4LGILQHl-1646573975940)(http://h9x14s4c.xyz/img/202111260923482.png)]
-
结构体是用户单独定义的类型,和其它类型进行转换时需要有完全相同的字段(名字、个数和类型)
-
结构体进行type重新定义(相当于取别名),go认为是新的数据类型,但是相互间可以强转

- struct的每个字段上,可以写上一个tag,该tag可以通过反射机制获取,常见的使用场景就是序列化和反序列化
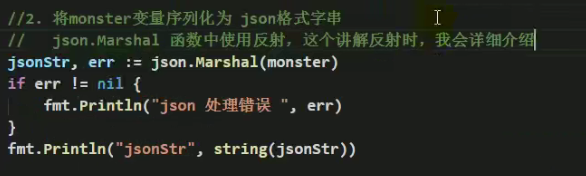
- 将struct变量进行json处理
- 使用tag标签解决
- 序列化处理:json.Marshal(monster)
type Tree struct { // `json:"name"`就是struct tag 用于修改结构体字段名称
Id int `json:"id"`
Name string `json:"name"`
Age int `json:"age"`
Children []Tree `json:"children"`
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yglZtKgX-1646573975941)(http://h9x14s4c.xyz/img/202111260958073.png)]
创建结构体变量时指定字段值
golang在创建结构体实例(变量)时,可以直接指定字段的值
type Person struct{
Name string
}
// 给Person类型绑定一方法
func (p Person) test(){
fmt.Println("test()",p.Name)
}
var p2 = Person{"tom"}
//调用方法
p2.test()
p3 := Person{"tom2"}
p3.test()
// 标明字段名称的写法不再依赖顺序
p4 := Person{
Name:"tom2",
}
p4.test()
// 返回结构体指针类型
var p5 = &Person{
Name: "zhangsan",
}
//带*符将它的值从空间里拿到,否则返回出来的带&号
(*p5).test()
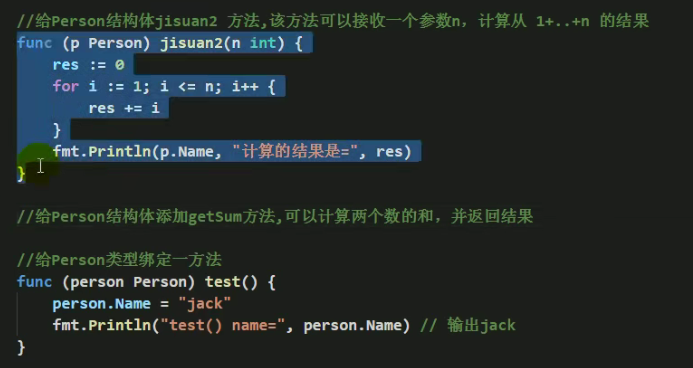
方法
某些情况下,我们需要声明方法,比如Person结构体:除了有一些字段外(年龄,姓名…),Person结构体还有一些行为,比如:可以说话、跑步…通过学习可以做算术题等等,这时需要用到方法
golang中方法是作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型,都可以有方法,而不仅仅struct
方法的简单定义:
type Person struct{
Num int
}
// 给Person类型绑定一方法
func (p Person) test(){
fmt.Println("test()",p.Num)
}
func main() {
var p Person
//调用方法
p.test()
}
-
test方法和Persion类型绑定
-
test方法只能通过Person类型的变量来调用,而不能直接调用,也不能使用其他类型变量来调用
-
func (p Person) test(){} …p表示哪个Person变量调用,这个p就是它的副本,这点和函数传参非常相似
-
p这个名字由程序员指定,不是固定

方法的调用和传参机制原理:
方法的调用和传参机制和函数基本一样,不一样的地方是方法调用时,会将调用方法的变量,当作实参也传递给方法

- 在通过一个变量去调用方法时,其调用机制和函数一样
- 不一样的地方是,变量调用方法时,该变量本身也会作为一个参数传递到方法(如果变量是值类型,则进行值拷贝,如果变量是引用类型,则进行地址拷贝
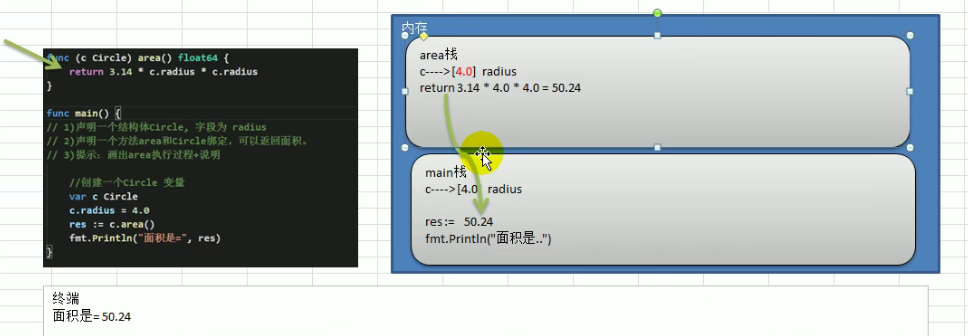
方法注意事项和细节讨论
- 结构体类型是值类型,在方法调用中,遵守值类型的传递机制,是值拷贝传递方式
- 如果程序员希望在方法中,修改结构体变量的值,可以通过结构体指针的方式来处理
- golang中的方法作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型,都可以有方法,而不仅仅是struct
- 方法的访问范围控制的规则,和函数一样。方法名首字母小写,只能在本包访问,方法首字母大写,可以在本包和其他包访问
- 如果一个变量实现了String()这个方法,那么fmt.Println默认会调用这个变量的String()进行输出


[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jL2Y5tBY-1646573975945)(http://h9x14s4c.xyz/img/202111262018278.png)]
练习:


[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4Iles6cC-1646573975946)(http://h9x14s4c.xyz/img/202111262023231.png)]
方法和函数的区别
- 调用方式不一样
- 函数的调用方式:参数名(实参列表)
- 方法的调用方式:变量.方法名(实参列表)
- 对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然
- 对于方法(如struct的方法),接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以(关键还是要看方法类型的定义)
不管调用形式如何,真正决定是值拷贝还是地址拷贝,看这个方法是和哪个类型绑定
如果是和值类型,比如(p Person),则是值拷贝,如果和指针类型,比如(p *Person)则是地址拷贝
面向对象编程应用实例
- 声明(定义)结构体,确定结构体名
- 编写结构体的字段
- 编写结构体的方法
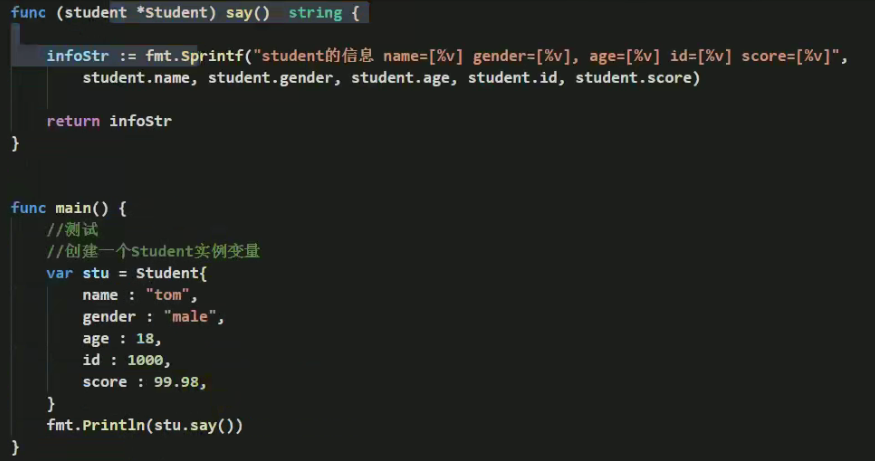
工厂模式–类似构造函数
golang的结构体没有构造函数,通常可以使用工厂模式来解决这个问题—(类似于构造函数)
场景使用:包1中有一个结构体定义了是私有,但在包2中希望使用包1中的结构体来创建实例,因为私有包是不允许在其他包中使用,所以这时可以使用工厂模式来解决
// 定义工厂
package model
// 因为定义的是私有属性,我们只能在本包使用
type student struct {
Name string
score float64 //如果定义的字段也是私有的,我们同样使用返回指针的方法解决
}
// PublicStudent 工厂模式
func PublicStudent(n string, s float64) *student {
return &student{
Name: n,
score: s,
}
}
// GetScore 返回私有字段的方法
func (s *student) GetScore() float64 {
return s.score
}
package main
import (
"fmt"
"go_code/chapter01/model"
)
//stu := model.student{
// Name: "zhangsan",
// Score: 99.6,
//}
// 通过方法,在堆内存中创建新的实例数据
stu := model.PublicStudent("tomm",89.89) //报错
//stu := model.PublicStudent("tomm",88.89)
fmt.Println(stu.GetScore())
//返回的是指针:&{} 需要使用*进行取值
fmt.Println(stu)
面向对象编程三大特性
golang让然有面向对象编程的继承,封装和多态的特性,只是实现的方式和其他OOP语言不一样
如何理解抽象
我们在前面定义一个结构体时候,实际上就是把一类事物的共有属性(字段)和行为(方法)提取出来,形成一个物理模型(模板)。这种研究问题的方法称为抽象
封装
封装就是把抽象出来的字段和对字段的操作封装在一起,数据被保护在内部,程序的其他包只有通过被授权的操作(方法)才能对字段进行操作
封装练习:
package model
import "fmt"
type person struct {
Name string
age int //其他包不能直接访问
sal float64
}
// NewPerson 创建工厂
func NewPerson(name string) *person {
return &person{
Name: name,
}
}
// SetAge 授权对年龄的设置操作(设置set方法)
func (p *person) SetAge(age int) {
if age > 0 && age < 150 {
p.age = age
} else {
fmt.Println("年龄范围不正确")
// 或者给一个默认值
}
}
// GetAge 获取用户年龄(设置get方法)
func (p *person) GetAge() int {
return p.age
}
// SetSal 设置薪水
func (p *person) SetSal(sal float64) {
if sal > 3000 && sal < 30000 {
p.sal = sal
} else {
fmt.Println("薪水范围不正确")
// 或者给一个默认值
}
}
// GetSal 获取薪水
func (p *person) GetSal() float64 {
return p.sal
}
func main() {
}
package main
import (
"fmt"
"go_code/chapter01/model"
)
func main() {
worker := model.NewPerson("smith")
worker.SetSal(5000)
worker.SetAge(19)
fmt.Println(worker)
fmt.Println(worker.Name, "age=", worker.GetAge(),
"sal=", worker.GetSal())
}
继承
继承可以解决代码复用,当多个结构体存在相同的属性(字段)和方法时,可以从这些结构体中抽象出结构体(比如刚刚的Student,在该结构体中定义这些相同的属性和方法。
其他结构体不需要重新定义这些属性和方法,只需嵌套一个Student匿名结构体即可
也就是说,在golang中,如果一个struct嵌套了另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现继承特性
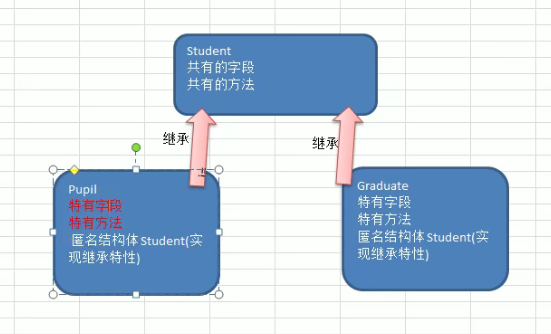
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mdn8s0QS-1646573975947)(http://h9x14s4c.xyz/img/202111271521110.png)]](https://img-blog.csdnimg.cn/52d1f8f513254b0ba6808b3335f69737.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_11,color_FFFFFF,t_70,g_se,x_16)
练习:
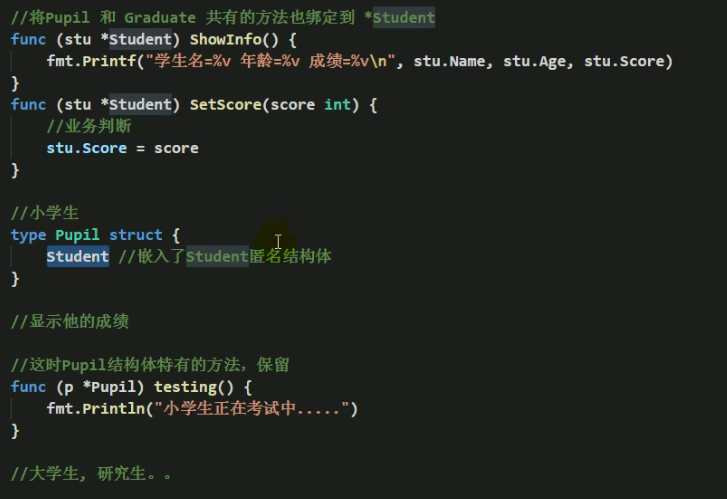
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wTArwLc1-1646573975948)(http://h9x14s4c.xyz/img/202111271528283.png)]
- 代码复用性提高
- 代码扩展性和维护性提高
继承的细节注意
- 结构体可以使用嵌套匿名结构体的所有的字段和方法,即:首字母大写或者小写的字段、方法,都可以使用
- 匿名结构体字段访问可以简化(不写)
- 当结构体和匿名结构体有相同的字段或者方法时,编译器采用就近访问原则访问,如希望访问匿名结构体的字段和方法,可以通过匿名结构体名来区分
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-14JqsdLj-1646573975949)(http://h9x14s4c.xyz/img/202111271534383.png)]
- 结构体嵌入两个(或多个)结构体,如两个匿名结构体有相同的字段和方法(同时结构体本身没有同名的字段和方法),在访问时,就必须明确指定匿名结构体名字,否则编译报错
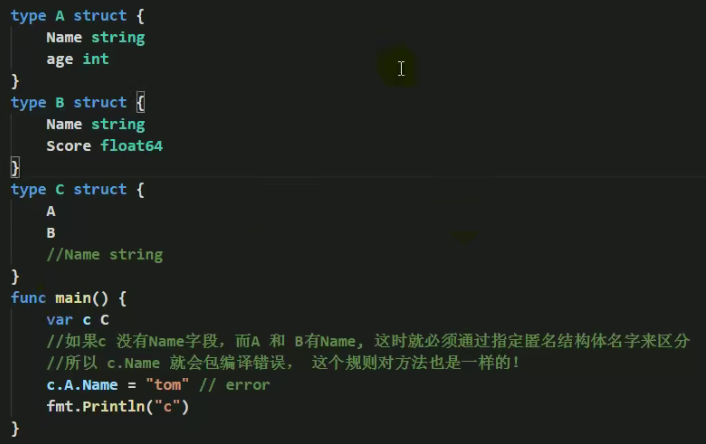
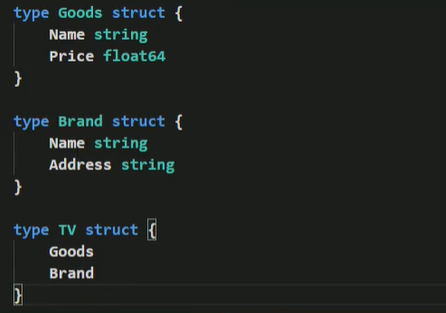
-
如果一个struct嵌套了一个有名结构体,这种模式就是组合,如果是组合关系,那么在访问组合的结构体的字段或方式时,必须带上结构体的名字
-
嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V6EaPoVP-1646573975950)(http://h9x14s4c.xyz/img/202111271602085.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bwNF3mlp-1646573975950)(http://h9x14s4c.xyz/img/202111271602620.png)]

- 同时,结构体也支持使用匿名字段
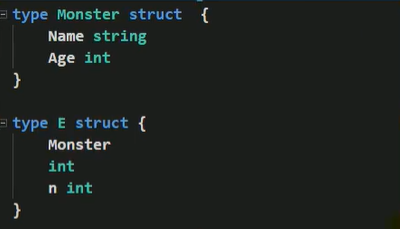

多重继承
如果一个struct嵌套了多个匿名结构体,那么该结构体可以直接访问嵌套的匿名结构体的字段和方法,从而实现多重继承
多重继承细节说明
- 如嵌入的匿名结构体有相同的字段名或者方法名,则在访问时,需要通过匿名 结构体类型名来区分
- 为了保证代码简洁性,建议尽量不适用多重继承
接口(interface)
golang中,多态的特性主要是通过接口来体现
package main
import "fmt"
// Usb 声明定义一个接口
//声明了两个没有实现的方法
type Usb interface{
Start()
Stop()
}
type Phone struct{
}
// 让Phone实现Usb接口方法
func (p Phone) Start(){
fmt.Println("手机开始工作..")
}
func (p Phone) Stop(){
fmt.Println("手机停止工作...")
}
// Computer 计算机
type Computer struct{
}
// Working 编写一个方法Working方法,接受一个Usb接口类型变量
// 只要实现了Usb接口(所谓实现了Usb接口,就是指实现了Usb接口声明所有方法)
func (c Computer) Working(usb Usb) {
//通过usb接口来调用Start和Stop方法
usb.Start()
usb.Stop()
}
func main() {
// 测试
computer := Computer{}
phone := Phone{}
computer.Working(phone)
}
基本介绍
interface类型可以定义一组方法,但是这些方法不需要实现,并且interface不能包含任何变量。到某个自定义类型(比如结构体Phone)要使用的时候,再根据具体情况把这些方法写出来

- 接口里的所有方法都没有方法体,即接口的的方法都是没有实现的方法,接口体现了程序设计的多态和高内聚低耦合的思想
- golang中的接口,不需要显示的实现。只要一个变量,含有接口类型中的所有方法,那么这个变量就实现这个接口。因此,golang中没有implement这样的关键字
接口的注意事项和细节
- 接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量
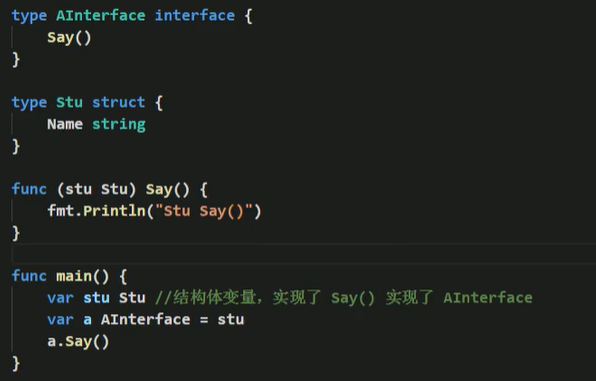
- 接口中所有的方法都没有方法体,即都是没有实现的方法
- 在golang中,一个自定义类型需要将某个接口的所有方法都实现,我们说这个自定义类型实现了该接口
- 一个自定义类型只有实现了某个接口,才能将该自定义类型的实例(变量)赋给接口类型
- 只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型
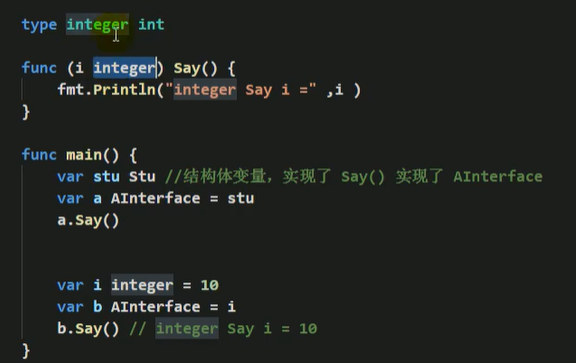
- 一个自定义类型可以实现多个接口
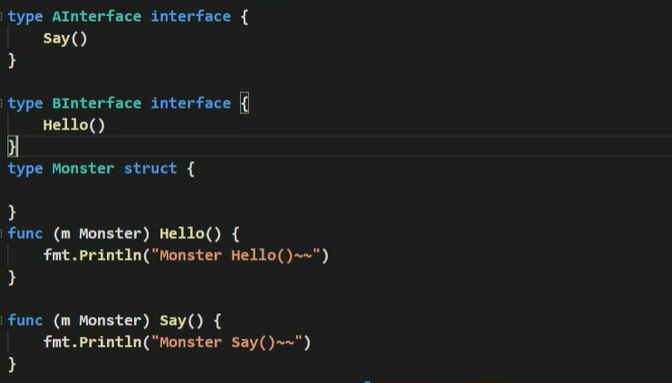
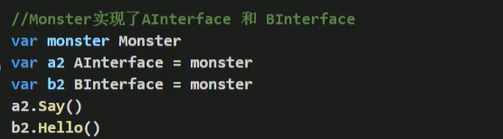
- golang接口中不能有任何变量
- 一个接口(比如A接口)可以继承多一个别的接口(比如B,C接口),这时如果要实现A接口,也必须将B,C接口的方法也全部实现。
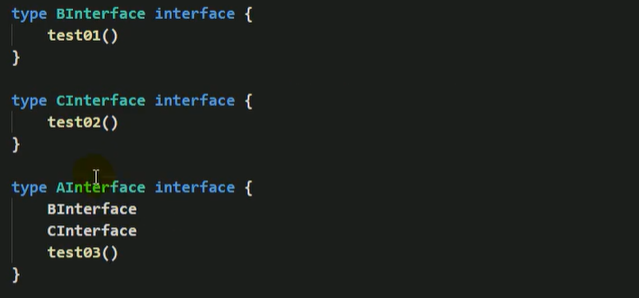
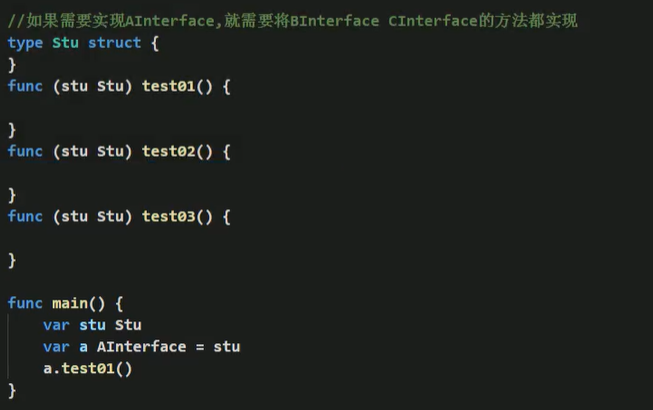
- interface类型某人是一个指针(引用类型),如果没有对interface初始化就使用,那么会直接输出nil
- 空接口interface{}没有任何方法,所以所有类型都实现了空接口,即我们可以把任何一个变量赋给空接口


接口妙用最佳实例
func Sort
func Sort(data Interface)
Sort排序data。它调用1次data.Len确定长度,调用O(n*log(n))次data.Less和data.Swap。本函数不能保证排序的稳定性(即不保证相等元素的相对次序不变)。
type Interface
type Interface interface {
// Len方法返回集合中的元素个数
Len() int
// Less方法报告索引i的元素是否比索引j的元素小
Less(i, j int) bool
// Swap方法交换索引i和j的两个元素
Swap(i, j int)
}
一个满足sort.Interface接口的(集合)类型可以被本包的函数进行排序。方法要求集合中的元素可以被整数索引。
代码演示
package main
import (
"fmt"
"math/rand"
"sort"
)
/**
调用sort方法实现接口
*/
// Hero 1、声明Hero结构体
type Hero struct {
Name string
Age int
}
// HeroSlice 2、声明一个Hero结构体切片类型
type HeroSlice []Hero
// Len 3、实现Interface接口
func (hs HeroSlice) Len() int {
return len(hs)
}
// Less 方法决定使用什么标准进行排序
// 按照年龄从小到大进行排序
func (hs HeroSlice) Less(i, j int) bool {
return hs[i].Age < hs[j].Age
// 修改成对Name排序
//return hs[i].Name < hs[j].Name
}
func (hs HeroSlice) Swap(i, j int) {
// 完成交换
//temp := hs[i]
//hs[i] = hs[j]
//hs[j] = temp
hs[i], hs[j] = hs[j], hs[i]
}
func main() {
// 声明一个HeroSlice切片,并循环赋值
var heroes HeroSlice
for i := 0; i < 10; i++ {
hero := Hero{
Name: fmt.Sprintf("英雄%d", rand.Intn(100)),
Age: rand.Intn(100),
}
heroes = append(heroes, hero)
}
// 未排序前
for _, v := range heroes {
fmt.Println(v)
}
// 排序后
sort.Sort(heroes)
for _, v := range heroes {
fmt.Println("===>", v)
}
}
接口和继承的比较
接口:实现一些本身没有的方法,而不破坏本身的继承关系,对功能的扩展,是继承的补充
继承:继承一些本身没有的属性
案例:
package main
import "fmt"
// Monkey 定义猴子的结构体
type Monkey struct {
Name string
}
// ChildMonkey 定义children猴子的结构体
type ChildMonkey struct {
Monkey
}
// 给Monkey绑定一个本身的方法
func (monkey *Monkey) climbing() {
fmt.Println(monkey.Name, "生来会爬树...")
}
// BirdAble 声明一个BirdAble飞的接口
type BirdAble interface {
Flying()
}
// FishAble 声明一个FishAble游泳的接口
type FishAble interface {
Swimming()
}
// Flying 让ChildMonkey实现BirdAble
func (monkey *ChildMonkey) Flying() {
fmt.Println(monkey.Name, "通过学习,会飞翔...")
}
// Swimming 让ChildMonkey实现FishAble
func (monkey *ChildMonkey) Swimming() {
fmt.Println(monkey.Name, "通过学习,会有用...")
}
// Learning 让ChildMonkey实现一个学习方法,这个学习方法接受一个BirdAble接口类型变量和一个FishAble接口类型变
// 实现了鸟儿的飞翔和鱼儿的游泳
func (monkey *ChildMonkey) Learning(fly BirdAble, swim FishAble) {
fly.Flying()
swim.Swimming()
}
func main() {
// 创建一个children猴子的实例
childMonkey := ChildMonkey{
Monkey{
Name: "悟空",
},
}
// 通过childMonkey调用继承Monkey的属性
childMonkey.climbing()
// childMonkey.Flying()
// childMonkey.Swimming()
// 这时,如果想在不破坏猴子的本身正常能力的方法,而增添其他功能的时候,可以使用接口方法
// 猴子通过接口学习了飞翔和游泳
childMonkey.Learning(&childMonkey, &childMonkey)
}
- 接口和继承解决的问题不同
- 继承的价值主要在于:解决代码的复用性和可维护性
- 接口的价值主要在于:设计,设计好各种规范(方法),让其他自定义类型去实现这些方法
- 接口比继承更加灵活
- 继承是满足is-a的关系,而接口只需满足like-a的关系
- 接口在一定程度上实现代码解耦
多态
变量(实例)具有多种形态。面向对象的第三大特征,在go中,多态特征是通过接口实现的。可以按照统一的接口来调用不同的实现。这时接口变量就呈现不同的形态
接口体现多态特征
多态参数
在变量Usb接口案例中,Usb usb,即可接收手机变量,又可接收相机变量,就体现了Usb接口多态[参数多态]
多态数组
能存放不同类型的接口数组,并且遍历数组找到特定数组能调用该数组特定方法。[参数多态]、[类型断言]
案例:
package main
import (
"fmt"
)
// Usb 声明定义一个接口
//声明了两个没有实现的方法
type Usb interface {
Start()
Stop()
}
type Phone struct {
Name string
}
type Caramel struct {
Name string
}
// Start 让Phone实现Usb接口方法
func (p Phone) Start() {
fmt.Println("手机开始工作..")
}
func (p Phone) Stop() {
fmt.Println("手机停止工作...")
}
// Start 让Caramel实现Usb接口方法
func (c Caramel) Start() {
fmt.Println("相机开始工作..")
}
func (c Caramel) Stop() {
fmt.Println("相机停止工作...")
}
// Computer 计算机
type Computer struct {
}
// Working 编写一个方法Working方法,接受一个Usb接口类型变量
// 只要实现了Usb接口(所谓实现了Usb接口,就是指实现了Usb接口声明所有方法)
func (c Computer) Working(usb Usb) {
//通过usb接口来调用Start和Stop方法
usb.Start()
usb.Stop()
}
func main() {
// 测试,体现了多态数组的特性
var usbArr [3]Usb
usbArr[0] = Phone{Name: "iphone"}
usbArr[1] = Phone{Name: "huawei"}
usbArr[2] = Caramel{Name: "佳能"}
fmt.Println(usbArr)
// 测试,体现了多态参数的特性
computer := Computer{}
phone := Phone{}
caramel := Caramel{}
computer.Working(phone)
computer.Working(caramel)
}
类型断言
案例:类型断言
package main
import (
"fmt"
)
// Point 类型断言
type Point struct {
x int
y int
}
func main() {
// test 类型断言
var a interface{}
var point = Point{1, 3}
a = point
var b Point
// b = a 不可以,原因a是空接口类型,不能直接赋值,需要将a进行类型断言,尝试转换为Point
b = a.(Point)
fmt.Println(b)
// test 类型断言(带检测)
var x interface{}
var b2 float32 = 1.14
x = b2
y, ok := x.(float32)
if ok {
fmt.Println("success")
fmt.Println(y)
}else{
fmt.Println("fail")
}
fmt.Println("继续执行...")
}
b = a.(Point)就是类型断言,表示判断a是否指向Point类型的变量,如果是就转成Point类型并且赋值给变量b,否则报错
类型断言在多态数组中的调用:
package main
import (
"fmt"
)
type Usb interface {
Start()
Stop()
}
type Phone struct {
Name string
}
type Caramel struct {
Name string
}
// Computer 计算机
type Computer struct {
}
// Start 让Phone实现Usb接口方法
func (p Phone) Start() {
fmt.Println("手机开始工作..")
}
func (p Phone) Stop() {
fmt.Println("手机停止工作...")
}
// Start 让Caramel实现Usb接口方法
func (c Caramel) Start() {
fmt.Println("相机开始工作..")
}
func (c Caramel) Stop() {
fmt.Println("相机停止工作...")
}
// Call 实现电话专有的方法
func (p Phone) Call() {
fmt.Println("手机开始打电话...")
}
// Working 编写一个方法Working方法,接受一个Usb接口类型变量
// 只要实现了Usb接口(所谓实现了Usb接口,就是指实现了Usb接口声明所有方法)
func (c Computer) Working(usb Usb) {
// 通过usb接口来调用Start和Stop方法
usb.Start()
// 添加类型断言
if phone, ok := usb.(Phone); ok {
phone.call()
}
usb.Stop()
}
func main() {
// 测试
var usbArr [3]Usb
usbArr[0] = Phone{Name: "iphone"}
usbArr[1] = Phone{Name: "huawei"}
usbArr[2] = Caramel{Name: "佳能"}
//fmt.Println(usbArr)
computer := Computer{}
for _, v := range usbArr {
computer.Working(v)
}
}

项目开发流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vmtcr9Xj-1646573975958)(http://h9x14s4c.xyz/img/202111281342716.png)]
模块程序设计框架图
思路分析:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JtjeYAts-1646573975958)(http://h9x14s4c.xyz/img/202111281439908.png)]
文件操作
文件在程序中以流的形式来操作的
流:数据在数据源(文件)和程序(内存)之间经历的路径
File
在go的os包中的File结构体中,封装了一系列关于文件的操作方法
常用文件的操作方法
func Open
func Open(name string) (file *File, err error)
Open打开一个文件用于读取。如果操作成功,返回的文件对象的方法可用于读取数据;对应的文件描述符具有O_RDONLY模式。如果出错,错误底层类型是*PathError。
func (*File) Close
func (f *File) Close() error
Close关闭文件f,使文件不能用于读写。它返回可能出现的错误。
简单案例:
package main
import (
"fmt"
"os"
)
func main(){
// test 打开,关闭文件
// 使用绝对路径打开
file, err := os.Open("W:/Studybag/cae/GoLang/codes/src/go_code/chapter04/test.txt")
if err != nil{
fmt.Println("error:", err)
}
fmt.Printf("file:%v\n", file)
// file:{0xc00007c780}
errClose := file.Close()
if errClose != nil{
fmt.Println("error:", errClose)
}
}
带缓冲区方式读取文件显示在终端
package bufio
import "bufio"
bufio包实现了有缓冲的I/O。它包装一个io.Reader或io.Writer接口对象,创建另一个也实现了该接口,且同时还提供了缓冲和一些文本I/O的帮助函数的对象。
func NewReader
func NewReader(rd io.Reader) *Reader
NewReader创建一个具有默认大小缓冲、从r读取的*Reader。
package main
import (
"bufio"
"fmt"
"io"
"os"
)
func main(){
// test 打开,关闭文件
// 使用绝对路径打开
file, err := os.Open("W:/Studybag/cae/GoLang/codes/src/go_code/chapter04/test.txt")
if err != nil{
fmt.Println("error:", err)
}
fmt.Printf("file:%v\n", file)
defer file.Close()
//errClose := file.Close()
//if errClose != nil{
// fmt.Println("error:", errClose)
//}
// 创建一个 *Reader,是带缓冲的
reader := bufio.NewReader(file)
for {
// 读到一个换行就就结束,(按行读取)
str, err := reader.ReadString('\n')
// io.EOF表示文件末尾
if err == io.EOF{
break
}
fmt.Printf(str)
}
}
一次性读取整个文件到内存中
使用ioutil一次性将整个文件读取到内存,适用于小文件
package ioutil
import "io/ioutil"
Package ioutil implements some I/O utility functions.
func ReadFile
func ReadFile(filename string) ([]byte, error)
ReadFile 从filename指定的文件中读取数据并返回文件的内容。成功的调用返回的err为nil而非EOF。因为本函数定义为读取整个文件,它不会将读取返回的EOF视为应报告的错误。
// 一次性读取所有内容
// 因为这种读取方式没有显式的Open文件,因此我们不需要Close文件
// 因为文件的Open和Close被封装到ioutil.ReadFile函数内部
content, errContent := ioutil.ReadFile("W:/Studybag/cae/GoLang/codes/src/go_code/chapter04/test.txt")
if errContent != nil{
fmt.Println("error:", errContent)
}else{
// 输出[]byte,强转string()输出原内容
fmt.Println(string(content))
}
写文件操作
读写模式:
Constants
const (
O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件
O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件
O_RDWR int = syscall.O_RDWR // 读写模式打开文件
O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部
O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件
O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在
O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O
O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件
)
权限模式:主要用在linux上
type FileMode
type FileMode uint32
FileMode代表文件的模式和权限位。这些字位在所有的操作系统都有相同的含义,因此文件的信息可以在不同的操作系统之间安全的移植。不是所有的位都能用于所有的系统,唯一共有的是用于表示目录的ModeDir位。
const (
// 单字符是被String方法用于格式化的属性缩写。
ModeDir FileMode = 1 << (32 - 1 - iota) // d: 目录
ModeAppend // a: 只能写入,且只能写入到末尾
ModeExclusive // l: 用于执行
ModeTemporary // T: 临时文件(非备份文件)
ModeSymlink // L: 符号链接(不是快捷方式文件)
ModeDevice // D: 设备
ModeNamedPipe // p: 命名管道(FIFO)
ModeSocket // S: Unix域socket
ModeSetuid // u: 表示文件具有其创建者用户id权限
ModeSetgid // g: 表示文件具有其创建者组id的权限
ModeCharDevice // c: 字符设备,需已设置ModeDevice
ModeSticky // t: 只有root/创建者能删除/移动文件
// 覆盖所有类型位(用于通过&获取类型位),对普通文件,所有这些位都不应被设置
ModeType = ModeDir | ModeSymlink | ModeNamedPipe | ModeSocket | ModeDevice
ModePerm FileMode = 0777 // 覆盖所有Unix权限位(用于通过&获取类型位)
)
这些被定义的位是FileMode最重要的位。另外9个不重要的位为标准Unix rwxrwxrwx权限(任何人都可读、写、运行)。这些(重要)位的值应被视为公共API的一部分,可能会用于线路协议或硬盘标识:它们不能被修改,但可以添加新的位。
案例:
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
path := "W:/Studybag/cae/GoLang/codes/src/go_code/chapter04/test.txt"
file ,err := os.OpenFile(path, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
// 写入语句,\r\n表示换行
str := "hello world!\r\n"
// 写入时使用带缓存的*Writer
writer := bufio.NewWriter(file)
for i:=0;i<5;i++{
writer.WriteString(str)
}
// 因为writer是带缓存,因此在调用WriteString(str)方法时内容是写入到缓存中,所以
// 这里需要到一个Flush方法,将缓冲的数据真正写入到文件中,否则文件中不会写入新数据
// 如果目标文件不存在,则会创建该文件
writer.Flush()
}
判断文件是否存在
func Stat
func Stat(name string) (fi FileInfo, err error)
Stat返回一个描述name指定的文件对象的FileInfo。如果指定的文件对象是一个符号链接,返回的FileInfo描述该符号链接指向的文件的信息,本函数会尝试跳转该链接。如果出错,返回的错误值为*PathError类型。
- 如果返回错误是nil,说明文件或文件夹存在
- 如果返回错误类型使用
os.IsNotExist()判断为true,说明文件或文件夹不存在 - 如果返回错误为其他类型,则不确定是否存在
// PathExists 判断文件是否存在
func PathExists(path string) (bool, error) {
_, err := os.Stat(path)
if err == nil {
// 文件或目录存在
return true, nil
}
if os.IsNotExist(err) {
return false, err
}
return false, nil
}
文件编程
当需要拷贝文件操作时(图片视频音频等),需要用到io.Copy()方法
func Copy
func Copy(dst Writer, src Reader) (written int64, err error)
将src的数据拷贝到dst,直到在src上到达EOF或发生错误。返回拷贝的字节数和遇到的第一个错误。
对成功的调用,返回值err为nil而非EOF,因为Copy定义为从src读取直到EOF,它不会将读取到EOF视为应报告的错误。如果src实现了WriterTo接口,本函数会调用src.WriteTo(dst)进行拷贝;否则如果dst实现了ReaderFrom接口,本函数会调用dst.ReadFrom(src)进行拷贝。
// CopyFile 复制资源方法
func CopyFile(dstFilePath string, srcFilePath string) (written int64, err error) {
srcFile, errSrcFile := os.Open(srcFilePath)
if errSrcFile != nil {
fmt.Println(errSrcFile)
return
}
defer srcFile.Close()
// 通过缓存拿到reader
reader := bufio.NewReader(srcFile)
// 打开dstFilePath
dstFile, errDstFile := os.OpenFile(dstFilePath, os.O_WRONLY|os.O_CREATE, 0666)
if errDstFile != nil {
fmt.Println(errDstFile)
return
}
writer := bufio.NewWriter(dstFile) //注意这里时调用bufio.NewWriter()创建写操作
defer dstFile.Close()
return io.Copy(writer, reader)
}
// 调用
srcPath := "W:/Studybag/cae/GoLang/codes/src/go_code/chapter04/test.txt"
dstPath := "W:/Studybag/cae/GoLang/codes/src/go_code/chapter04/main/test1.txt"
CopyFile(dstPath,srcPath)
练习:

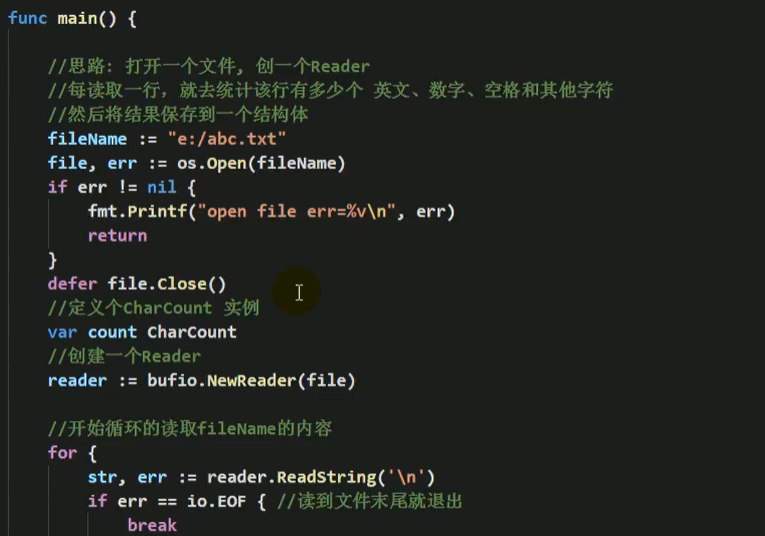
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IPIb7emX-1646573975960)(http://h9x14s4c.xyz/img/202111282115023.png)]
命令行参数获取
在build可执行文件后,通过命令行带的参数,可以通过以下方法传进二进制文件中
原生普通方式

通过flag包来解析命令行参数
func IntVar
func IntVar(p *int, name string, value int, usage string)
IntVar用指定的名称、默认值、使用信息注册一个int类型flag,并将flag的值保存到p指向的变量。
func Parse
func Parse()
从os.Args[1:]中解析注册的flag。必须在所有flag都注册好而未访问其值时执行。未注册却使用flag -help时,会返回ErrHelp。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xw2epjey-1646573975961)(http://h9x14s4c.xyz/img/202111282127436.png)]

JSON
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。
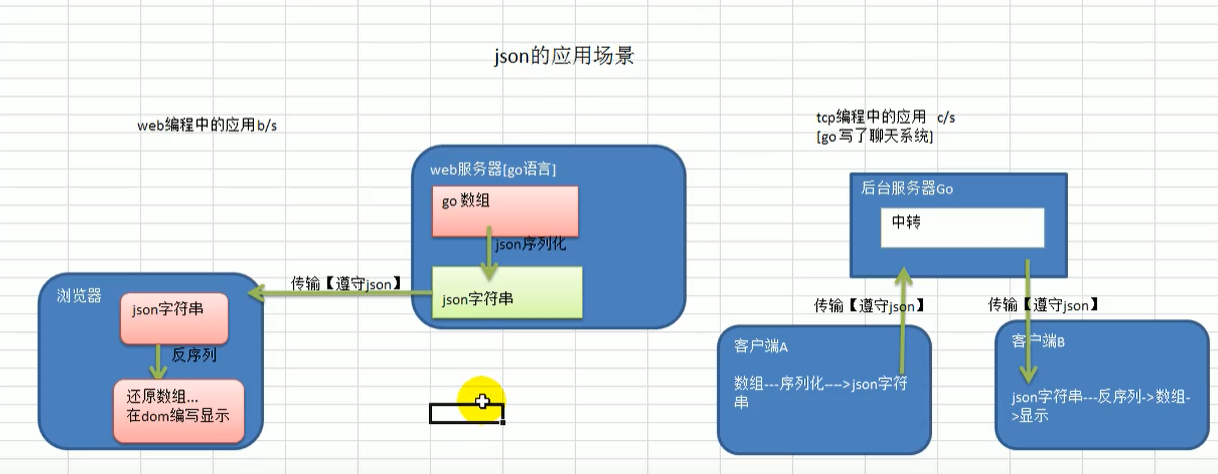
json序列化
json序列化是指,将有key-value结构的数据结构类型(比如:结构体、map、切片)序列化成json字符串的操作
func Marshal
func Marshal(v interface{}) ([]byte, error)
Marshal函数返回v的json编码。
Marshal函数会递归的处理值。如果一个值实现了Marshaler接口切非nil指针,会调用其MarshalJSON方法来生成json编码。nil指针异常并不是严格必需的,但会模拟与UnmarshalJSON的行为类似的必需的异常。
否则,Marshal函数使用下面的基于类型的默认编码格式:
布尔类型编码为json布尔类型。
浮点数、整数和Number类型的值编码为json数字类型。
字符串编码为json字符串。角括号"<“和”>“会转义为”\u003c"和"\u003e"以避免某些浏览器吧json输出错误理解为HTML。基于同样的原因,"&“转义为”\u0026"。
数组和切片类型的值编码为json数组,但[]byte编码为base64编码字符串,nil切片编码为null。
结构体的值编码为json对象。每一个导出字段变成该对象的一个成员,除非:
- 字段的标签是"-"
- 字段是空值,而其标签指定了omitempty选项
空值是false、0、""、nil指针、nil接口、长度为0的数组、切片、映射。对象默认键字符串是结构体的字段名,但可以在结构体字段的标签里指定。结构体标签值里的"json"键为键名,后跟可选的逗号和选项,举例如下:
// 字段被本包忽略
Field int `json:"-"`
// 字段在json里的键为"myName"
Field int `json:"myName"`
// 字段在json里的键为"myName"且如果字段为空值将在对象中省略掉
Field int `json:"myName,omitempty"`
// 字段在json里的键为"Field"(默认值),但如果字段为空值会跳过;注意前导的逗号
Field int `json:",omitempty"`
"string"选项标记一个字段在编码json时应编码为字符串。它只适用于字符串、浮点数、整数类型的字段。这个额外水平的编码选项有时候会用于和javascript程序交互:
Int64String int64 `json:",string"`
如果键名是只含有unicode字符、数字、美元符号、百分号、连字符、下划线和斜杠的非空字符串,将使用它代替字段名。
匿名的结构体字段一般序列化为他们内部的导出字段就好像位于外层结构体中一样。如果一个匿名结构体字段的标签给其提供了键名,则会使用键名代替字段名,而不视为匿名。
Go结构体字段的可视性规则用于供json决定那个字段应该序列化或反序列化时是经过修正了的。如果同一层次有多个(匿名)字段且该层次是最小嵌套的(嵌套层次则使用默认go规则),会应用如下额外规则:
1)json标签为"-"的匿名字段强行忽略,不作考虑;
2)json标签提供了键名的匿名字段,视为非匿名字段;
3)其余字段中如果只有一个匿名字段,则使用该字段;
4)其余字段中如果有多个匿名字段,但压平后不会出现冲突,所有匿名字段压平;
5)其余字段中如果有多个匿名字段,但压平后出现冲突,全部忽略,不产生错误。
对匿名结构体字段的管理是从go1.1开始的,在之前的版本,匿名字段会直接忽略掉。
映射类型的值编码为json对象。映射的键必须是字符串,对象的键直接使用映射的键。
指针类型的值编码为其指向的值(的json编码)。nil指针编码为null。
接口类型的值编码为接口内保持的具体类型的值(的json编码)。nil接口编码为null。
通道、复数、函数类型的值不能编码进json。尝试编码它们会导致Marshal函数返回UnsupportedTypeError。
Json不能表示循环的数据结构,将一个循环的结构提供给Marshal函数会导致无休止的循环。
序列化例子:结构体,map,数组
package main
import (
"encoding/json"
"fmt"
)
// Monster 定义一个结构体
type Monster struct {
Name string
Age int
}
// testStruct 对结构体的序列化操作
func testStruct() {
monster := Monster{
Name: "牛魔王",
Age: 500,
}
// 序列化
data, err := json.Marshal(&monster)
if err != nil {
fmt.Println(err)
}
fmt.Println("序列化结果:", string(data))
}
// testMap 对Map的序列化操作
func testMap() {
var a map[string]interface{}
a = make(map[string]interface{})
a["name"] = "红孩儿"
a["age"] = "300"
// 序列化
data, err := json.Marshal(a)
if err != nil {
fmt.Println(err)
}
fmt.Println("序列化结果:", string(data))
}
// testSlice 对切片的序列化操作
func testSlice() {
var slice []map[string]interface{}
var m1 map[string]interface{}
// make 操作
m1 = make(map[string]interface{})
m1["name"] = "jack"
m1["age"] = "20"
slice = append(slice, m1)
var m2 map[string]interface{}
// make 操作
m2 = make(map[string]interface{})
m2["name"] = "tom"
m2["age"] = "22"
m2["address"] = [2]string{"广东", "上海"}
slice = append(slice, m2)
// 序列化
data, err := json.Marshal(slice)
if err != nil {
fmt.Println(err)
}
fmt.Println("序列化结果:", string(data))
}
func main() {
testStruct()
testMap()
testSlice()
}
Tag映射
package main
import (
"encoding/json"
"fmt"
)
// Monster 定义一个结构体
type Monster struct {
Name string `json:"monster_name"` //反射机制
Age int `json:"monster_age"`
}
func main(){
}
json反序列化
json反序列化是指,将json字符串反序列化成对应的数组类型(比如结构体、map、切片)的操作
package main
import (
"encoding/json"
"fmt"
)
// Monster 定义一个结构体
type Monster struct {
Name string `json:"monster_name"` //反射机制
Age int `json:"monster_age"`
}
// 反序列化
// unmarshalStruct 反序列化成struct
func unmarshalStruct() {
// 定义一串json字符串,符合以上结构体
str := `{"monster_name":"牛魔王","monster_age":500}`
// 实例化结构体
var monster Monster
// 需要引用传递,将其变量改变
err := json.Unmarshal([]byte(str), &monster)
if err != nil {
fmt.Println(err)
}
fmt.Println("反序列化后的monster:", monster)
}
// unmarshalMap 反序列化成map
// 注意:反序列化map不需要make,因为make操作被封装到json.Unmarshal([]byte(str), &a)函数中,
// 原因是利用类型断言推导出来
func unmarshalMap() {
str := `{"age":"300","name":"红孩儿"}`
// 定义一个map
var a map[string]interface{}
// 进行反序列化
err := json.Unmarshal([]byte(str), &a)
if err != nil {
fmt.Println(err)
}
fmt.Println("反序列化后的a:", a)
}
// unmarshalSlice 反序列化切片
func unmarshalSlice() {
str := `[{"age":"20","name":"jack"},{"address":["广东","上海"],"age":"22","name":"tom"}]`
// 定义一个slice切片
var slice []map[string]interface{}
// 进行反序列化
err := json.Unmarshal([]byte(str), &slice)
if err != nil {
fmt.Println(err)
}
fmt.Println("反序列化后的slice:", slice)
}
func main() {
// 反序列化
unmarshalStruct()
unmarshalMap()
unmarshalSlice()
}
- 反序列化一个json字符串时,要确保反序列化后的数据类型和原来序列化前的数据类型一致
单元测试
如何确认一个模块的正确
go中自带有一个轻量级的测试框架testing和自带的go test命令来实现单元测试和性能测试,testing框架和其他语言中的测试框架类似,可以基于这个框架写针对相应函数的测试用例,也可以基于该框架写相应的压力测试用例。
- 确保每个函数是可运行,并且运行结果是正确的
- 确保写出来的代码性能是好的
- 单元测试能及时发现程序设计或实现的逻辑错误,使问题及早暴露,便于问题的定位解决,而性能测试的重点在于发现程序设计上的一些问题,让程序能够在高并发的情况下还能保持稳定
package testing
import "testing"
testing 提供对 Go 包的自动化测试的支持。通过 go test 命令,能够自动执行如下形式的任何函数:
func TestXxx(*testing.T)
其中 Xxx 可以是任何字母数字字符串(但第一个字母不能是 [a-z]),用于识别测试例程。
在这些函数中,使用 Error, Fail 或相关方法来发出失败信号。
要编写一个新的测试套件,需要创建一个名称以 _test.go 结尾的文件,该文件包含 TestXxx 函数,如上所述。 将该文件放在与被测试的包相同的包中。该文件将被排除在正常的程序包之外,但在运行 “go test” 命令时将被包含。 有关详细信息,请运行 “go help test” 和 “go help testflag” 了解。
如果有需要,可以调用 *T 和 *B 的 Skip 方法,跳过该测试或基准测试:
func TestTimeConsuming(t *testing.T) {
if testing.Short() {
t.Skip("skipping test in short mode.")
}
...
}
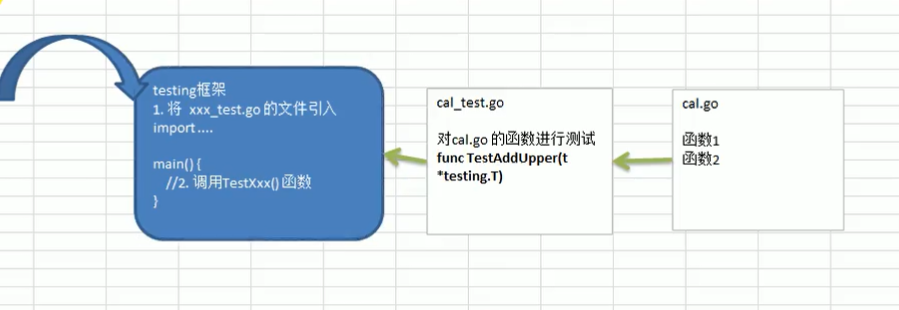
单元测试细节说明
- 测试用例文件名必须以
_test.go结尾。比如:cal_test.go,cal不是固定的。 - 测试用例函数必须以
Test开头,一般来说就是Test+被测试的函数名,比如:TestAddUpper()。 TestAddUpper(t *test.T)的形参类型必须是*testing.T。- 一个测试用例文件中,可以有多个测试用例函数,比如:
TestAddUpper()、TestSub()。 - 运行测试用例指令
- cmd > go test [如果运行正确,无日志,错误时,会输出日志]
- cmd > go test -v [运行正常或是错误,都输出日志]
- 当出现错误时,可以使用
t.Fatalf来格式化输出错误信息,并退出程序
*func (T) Fatalf
func (c *T) Fatalf(format string, args ...interface{})
调用 Fatalf 相当于在调用 Logf 之后调用 FailNow 。
-
t.Logf方法可以输出相应的日志 -
测试用例函数,并没有放在main函数中,也执行了,这时测试用例的方便之处
-
PASS表示测试用例运行成功,FAIL表示测试用例运行失败
-
测试单个文件,一定要带上被测试的原文件
go test -v cal_test.go cal.go -
测试单个方法
go test -v -test.run TestAddUpper
goroutine(协程)和channel(管道)
进程和线程说明
- 进程就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
- 线程是进程的一个执行实例,是程序执行的最小单元,他是比进程更小能独立运行的基本单位
- 一个进程可以创建和销毁多个线程,同一个进程中的多个线程可以并发执行
- 一个程序至少有一个进程,一个进程至少有一个线程
并发和并行
- 多线程程序在单核上运行,就是并发
- 多线程程序在多核上运行,就是并行

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dphsyem9-1646573975964)(http://h9x14s4c.xyz/img/202111290929368.png)]
go协程和go主线程
-
go主线程(线程):一个go线程上,可以起多个协程,可以这样理解,协程是轻量级的线程[编译器做优化]
-
go协程的特点
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级的线程
案例:
package main import ( "fmt" "strconv" "time" ) // goroutineTestDemo //test 编写一个函数每个一秒输出“hello world” func test() { for i:=1;i<=10;i++{ fmt.Println("test()hello world"+strconv.Itoa(i)) time.Sleep(time.Second) } } func main() { // 开启一个协程 go test() for i:=1;i<=10;i++{ fmt.Println("main()hello golang"+strconv.Itoa(i)) time.Sleep(time.Second) } }

小结:
- 主线程是一个物理线程,直接作用在cpu上。是重量级的,非常耗费cpu资源。
- 协程从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗相对小
- golang的协程机制是重要的特点,可以轻松的开启上万个协程。其他编程语言的并发机制是一般基于线程的。开启过多的线程,资源耗费大,这里就是突显golang在并发上的优势
MPG模式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kGO9HQPN-1646573975965)(http://h9x14s4c.xyz/img/202111290947358.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Bj2ShONi-1646573975965)(http://h9x14s4c.xyz/img/202111290957542.png)]
设置cpu运行个数
package runtime
import "runtime"
runtime包提供和go运行时环境的互操作,如控制go程的函数。它也包括用于reflect包的低层次类型信息;参见reflect报的文档获取运行时类型系统的可编程接口。
func NumCPU
func NumCPU() int
NumCPU返回本地机器的逻辑CPU个数。
func GOMAXPROCS
func GOMAXPROCS(n int) int
GOMAXPROCS设置可同时执行的最大CPU数,并返回先前的设置。 若 n < 1,它就不会更改当前设置。本地机器的逻辑CPU数可通过 NumCPU 查询。本函数在调度程序优化后会去掉。
channel(管道)与协程
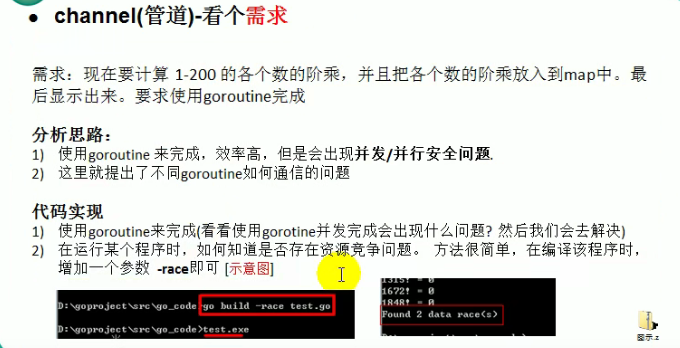

不同goroutine之间如何通讯
- 全局变量加锁同步
- channel
全局变量锁
package sync
import "sync"
sync包提供了基本的同步基元,如互斥锁。除了Once和WaitGroup类型,大部分都是适用于低水平程序线程,高水平的同步使用channel通信更好一些。
本包的类型的值不应被拷贝。
type Mutex
type Mutex struct {
// 包含隐藏或非导出字段
}
Mutex是一个互斥锁,可以创建为其他结构体的字段;零值为解锁状态。Mutex类型的锁和线程无关,可以由不同的线程加锁和解锁。
func (*Mutex) Lock
func (m *Mutex) Lock()
Lock方法锁住m,如果m已经加锁,则阻塞直到m解锁。
func (*Mutex) Unlock
func (m *Mutex) Unlock()
Unlock方法解锁m,如果m未加锁会导致运行时错误。锁和线程无关,可以由不同的线程加锁和解锁。
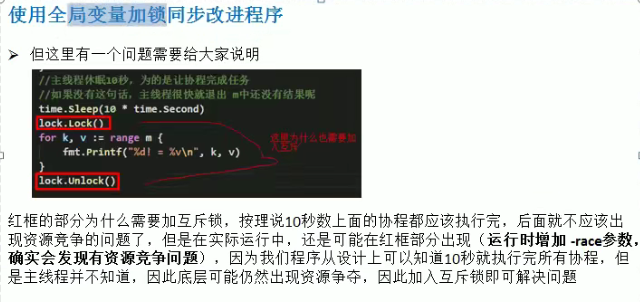
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eReH47hA-1646573975967)(http://h9x14s4c.xyz/img/202111291024500.png)]

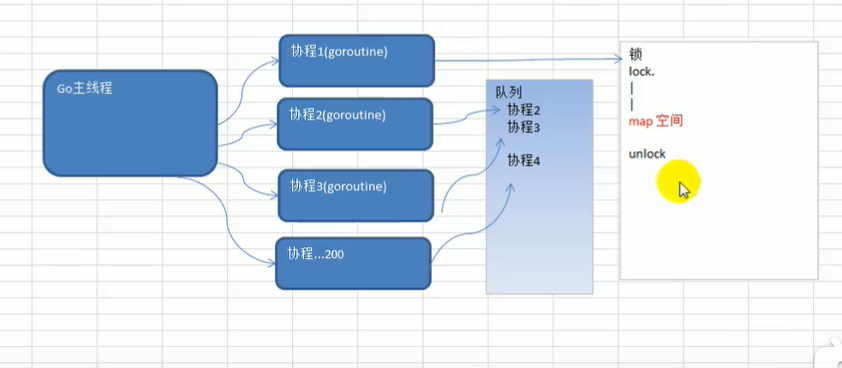
channel管道
- channel本质是一个数据结构队列
- 数据是先进先出[FIFO:first in first out]
- 线程安全,多goroutine访问时,不需要加锁,就是说channel本身就是线程安全的
- channel时有类型的,一个string的channel只能存放string类型数据
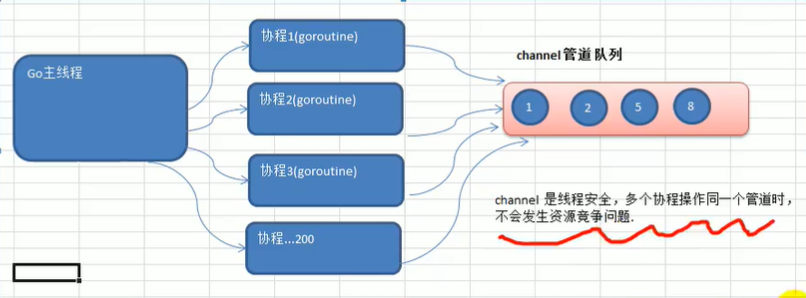
定义声明
var 变量名 chan 数据类型


channel管道使用的注意事项
- channel中只能存放指定的数据类型
- channel的数据类型放满后,就不能再放入了
- 如果从channel取出数据后,可以继续放入
- 在没有使用协程的情况下,如果channel数据取完了,再取,就会报dead lock

channel的遍历和关闭
- 这里的遍历,就是等价于从管道中取出数据
- 注意需要close管道,否则会出现deadlock
- 在for range 管道时,当遍历到最后的时候,发现有管道关闭了,就结束从管道读取数据的遍历工作,正常退出
- 在for range 管道时,当遍历到最后的时候,发现有管道没有关闭,程序会认为可能有数据继续写入,因此就会等待,如果程序没有数据写入,就会出现死锁。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YvBnq6TI-1646573975971)(http://h9x14s4c.xyz/img/202111291051587.png)]
协程与管道案例:
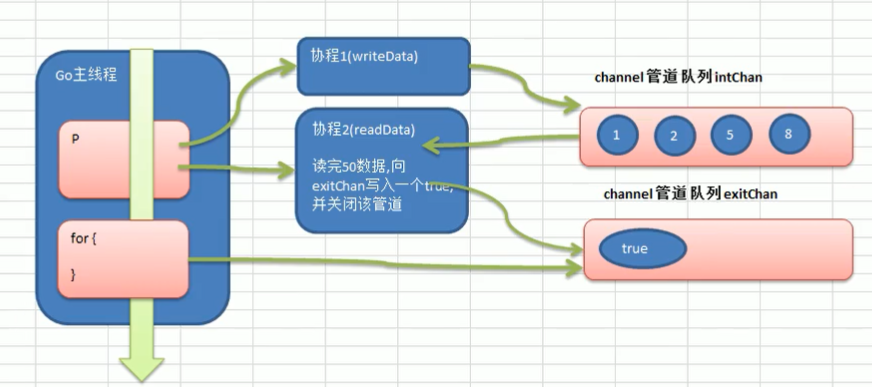
package main
import "fmt"
// Write Data 写数据
func writeData(intChan chan int) {
for i := 0; i < 50; i++ {
intChan <- i
fmt.Println("写到的数据===>", i)
}
close(intChan)
}
// Read Data 读数据
func readData(intChan chan int, exitChan chan bool) {
for {
v, ok := <-intChan
if !ok {
break
}
fmt.Println("读到的数据===>", v)
}
exitChan <- true
close(exitChan)
}
func main() {
// 创建两个管道
intChan := make(chan int, 50)
exitChan := make(chan bool, 1)
// 创建协程
go writeData(intChan)
go readData(intChan, exitChan)
// 设置阻塞条件
for {
_, ok := <-exitChan
if !ok {
break
}
}
}
练习:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l1HlM0Vr-1646573975972)(http://h9x14s4c.xyz/img/202112071141794.png)]

管道阻塞
如果管道一直写入数据,而没有任何读取,那么就会出现死锁问题dead lock,原因是管道容量比实际写入量小,出现溢出所以会出现阻塞现象
统计1-20000素数

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MFMxxg5i-1646573975974)(http://h9x14s4c.xyz/img/202112071204437.png)]
案例:
package main
import (
"fmt"
)
// 向 intChan中放入1-8000个数
func putNum(intChan chan int) {
for i := 1; i <= 8000; i++ {
intChan <- i
}
// 关闭intChan
close(intChan)
}
// 从intChan取出数据,并判断是否为素数,如果是,就放入到primeChan
func primeNum(intChan chan int, primeChan chan int, exitChan chan bool) {
var flag bool
for {
//time.Sleep(time.Millisecond )
num, ok := <-intChan
if !ok {
break
}
flag = true
// 判断num是不是素数
for i := 2; i < num; i++ {
if num%i == 0 {
// 说明该num不是素数
flag = false
break
}
}
if flag {
// 将这个数放入primeChan
primeChan <- num
}
}
fmt.Println("有一个协程因为取不到值已经退出")
exitChan <- true
}
func main() {
intChan := make(chan int, 10000)
primeChan := make(chan int, 5000) //放入结果
// 标识退出的管道
exitChan := make(chan bool, 10)
go putNum(intChan)
// 开启四个协程/十个
for i := 0; i < 10; i++ {
go primeNum(intChan, primeChan, exitChan)
}
// 主线程进行阻塞处理
go func() {
for i := 0; i < 10; i++ {
<-exitChan
}
// 当我们成功从exitChan中取出四个结果,就可以关闭primeChan管道
close(primeChan)
}()
//遍历primeNum ,取出结果
count := 0
for {
res, ok := <-primeChan
if !ok {
break
}
count++
fmt.Println(res)
}
println("main主线程退出,结果数量为:",count)
}
channel使用细节和注意事项
- channel可以声明为只读,或者只写性质
- channel只读和只写案例
// 管道可以声明为只读,或只写
// 默认情况下,管道是双向的
// 声明只写
var chan1 chan<- int
chan1 = make(chan int, 3)
chan1 <- 10
//num:= <- 20 错误,不可读
println(chan1)
// 声明只写
var chan2 <-chan int
//chan2 <- 10 错误,不可写
num := <-chan2
println(num)
- 使用select可以解决从管道取数据的阻塞问题
// 使用select可以解决从管道中取数据的阻塞问题
// 1、定义一个管道10个数据int
intChan := make(chan int, 10)
for i := 0; i < 10; i++ {
intChan <- i
}
// 2、定义一个管道 5个数据string
stringChan := make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello" + fmt.Sprintf("%d", i)
}
//select 方法解决
//label:
for {
select {
case val := <-intChan:
fmt.Println(val)
case val := <-stringChan:
fmt.Println(val)
default:
fmt.Println("都取不到数据,退出吧")
return
//break label //退出方法break
}
}
- goroutine中使用defer+recover,解决协程中出现panic,导致程序崩溃问题
package main
import (
"fmt"
"time"
)
// 正常函数
func sayHello() {
for i := 0; i < 10; i++ {
time.Sleep(time.Millisecond)
fmt.Println("hello world~")
}
}
// 可能出错函数
func test() {
// defer+recover
defer func() {
// 捕获test()抛出的panic
if err := recover(); err != nil {
fmt.Println("test()发生错误,", err)
}
}()
var myMap map[int]string
myMap[0] = "golang"
}
func main(){
// 使用defer+recover捕获可能出错的函数
go sayHello()
go test()
for i := 0; i < 10; i++ {
fmt.Println("main() ok=", i)
time.Sleep(time.Millisecond)
}
}
反射
- 反射可以在运动时动态获取变量的各种信息,比如变量的类型(type),类别(kind)
- 如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段,方法)
- 通过反射,可以修改变量的值,可以调用关联的方法
- 通过反射,需要import(“reflect”)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L4bEO2yM-1646573975974)(http://h9x14s4c.xyz/img/202112071726664.png)]
反射重要的函数和概念
-
reflect.TypeOf(变量名),获取变量的类型,返回reflect.Type类型
-
reflect.ValueOf(变量名),获取变量的值,返回reflect.Value是一个结构体类型。通过reflect.Value,可以获取到关于该变量的很多信息。
-
变量、interface{}和reflect.Value是可以相互转换的,这点在实际开发中,会经常使用到。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HL4YgZBu-1646573975975)(http://h9x14s4c.xyz/img/202112071740585.png)]
反射案例:
package main
import (
"fmt"
"reflect"
)
// 演示普通类型反射机制
func reflectTest01(b interface{}) {
// 需求:通过反射获取的传入的变量的type,kind,值
// 1、先获取到reflect.Type
rType := reflect.TypeOf(b)
fmt.Println("rType:", rType)
//2、获取到reflect.Value
rVal := reflect.ValueOf(b)
n2 := 2 + rVal.Int()
fmt.Println("n2:", n2)
fmt.Printf("rVal=%v rVal Type=%T\n", rVal, rVal)
// 下面将rVal 转成interface{}
iV := rVal.Interface()
num2 := iV.(int) //类型断言
fmt.Println("num2:", num2)
}
func main() {
// 定义一个int
var num int = 100
reflectTest01(num)
}
结构体反射案例:
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
}
// 演示结构体反射机制
func reflectTest02(b interface{}) {
// 需求:通过反射获取的传入的结构体变量的type,kind,值
// 1、先获取到reflect.Type
rType := reflect.TypeOf(b)
fmt.Println("rType:", rType)
//2、获取到reflect.Value
rVal := reflect.ValueOf(b)
//n2 := 2 + rVal.Int()
//fmt.Println("n2:", n2)
//fmt.Printf("rVal=%v rVal Type=%T\n", rVal, rVal)
// 下面将rVal 转成interface{}
iV := rVal.Interface()
fmt.Printf("iV=%v iV Type=%T\n", iV, iV)
//stu, ok := iV.(Student)
switch iV.(type) {
case bool:
case int:
case Student:
stu, _ := iV.(Student)
fmt.Println(stu.Name)
default:
println("类型断言没有此类型")
}
//fmt.Println("num2:", num2)
}
func main() {
// 定义一个Student的实例
stu := Student{
Name: "Naughty",
Age: 23,
}
reflectTest02(stu)
}
反射注意事项和细节说明
- reflect.Value.Kind,获取变量的类型,返回的是一个常量
- Type是类型,Kind是类别,Type和Kind可能是相同的,也可能是不同的,例如:
- var num int = 10 num的Type是int,Kind也是int
- var stu Student stu的Type是包名.Student,Kind是struct
- 通过反射机制可以在让变量在interface{}和Reflect.Value之间相互转换
- 使用反射的方式来获取变量的值(并返回对应的类型),要求数据类型匹配,比如x是int那么就应该使用reflect.Value(x).int(),而不能使用其它的否则报panic
- 通过反射的来修改变量,注意当使用SetXxx方法来设置需要通过对应的指针类型来完成,这样才能改变传入的变量的值,同时需要使用到reflect.Value.Elem()方法
- reflect.Value.Elem()应该如何理解?
通过映射修改普通类型数据:
package main
import (
"fmt"
"reflect"
)
// 通过反射修改原有传进来的值
func reflect01(b interface{}){
rVal := reflect.ValueOf(b)
fmt.Printf("rVal的Kind=%v\n",rVal.Kind())
// Elem返回v持有的接口保管的值的Value封装,或者v持有的指针指向的值的Value封装。
// 如果v的Kind不是Interface或Ptr会panic;如果v持有的值为nil,会返回Value零值。->panic: reflect: call of reflect.Value.Elem on int Value
rVal.Elem().SetInt(29)
}
func main(){
var num1 = 20
//reflect01(num1)
// panic: reflect: call of reflect.Value.Elem on int Value
reflect01(&num1)
fmt.Println(num1)
}
rVal.Elem()相当于拿到一个指针类型指向的值–>*ptr,在映射这里它会拿到指针指向的值,使用.SetXXX后会修改成对应的值
反射案例:
package main
import (
"fmt"
"reflect"
)
// 通过反射调用一系列对应的方法
// 定义一个结构体
type Monster struct {
Name string `json:"name"`
Age int `json:"monster_age"`
Score float32
Sex string
}
// 方法1,显示s的值
func (s Monster) Print() {
fmt.Println("----")
fmt.Println(s)
fmt.Println("----")
}
// 方法2,两数和
func (s Monster) GetSum(n1, n2 int) int {
return n1 + n2
}
// 方法3,接收四个值,给s赋值
func (s Monster) Set(name string, age int, score float32, sex string) {
s.Name = name
s.Age = age
s.Score = score
s.Sex = sex
}
func TestStruct(a interface{}) {
// 获取reflect.Type 类型
typ := reflect.TypeOf(a)
// 获取reflect.Value 类型
val := reflect.ValueOf(a)
// 获取a对应类型
kd := val.Kind()
// 判断传入参数是否是结构体
if kd != reflect.Struct {
fmt.Println("expect struct")
return
}
// 获取传入参数的所有字段数量
num := val.NumField()
fmt.Printf("struct has %d fields\n", num) //4
for i := 0; i < num; i++ {
// 遍历结构体所有字段
fmt.Printf("Field %d:值为=%v\n", i, val.Field(i))//可以使用类型断言转成对应类型进行操作
// 获取参数标签,注意需要通过reflect.Type来获取tag标签的值
tagVal := typ.Field(i).Tag.Get("json")
// 如果该字段有tag标签就显示,否则不显示
if tagVal != "" {
fmt.Printf("Field %d: tag为%v\n", i, tagVal)
}
}
// 获取该变量有多少个方法
numOfMethod := val.NumMethod()
fmt.Printf("struct has %d method\n", numOfMethod)// 3
// 获取第二个方法,并且调用它传入nil
// 这里调用方法会有一个原则,它会根据函数名ASCII码进行重排序,跟函数的位置无关
val.Method(1).Call(nil)
// 调用结构体的第一个方法Method(0)
// 因为调用参与反射参数的方法使用Call(),这个方法的传入参数是[]Value 返回参数是[]Value
var params []reflect.Value // 声明一个rValue切片
params = append(params, reflect.ValueOf(10)) // 将传入参数转成rValue
params = append(params, reflect.ValueOf(20))
res := val.Method(0).Call(params)// 传入的参数是[]reflect.Value类型
fmt.Println(res[0].Int())// 返回的参数是[]reflect.Value类型
}
func main() {
// 创建一个结构体实例
var m = Monster{
Name: "黄鼠狼精",
Age: 400,
Score: 38.2,
}
TestStruct(m)
}
通过反射操作任意结构体
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PRHR4Rtn-1646573975976)(http://h9x14s4c.xyz/img/202112081045990.png)]
定义了两个函数test1和test2,定义一个适配器函数用作统一处理接口

通过反射创建并操作结构体
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4Tof6eq8-1646573975976)(http://h9x14s4c.xyz/img/202112081044433.png)]
反射练习:

网络编程
网络编程有两种:
- TCP socket 编程,是网络编程的主流。之所以叫Tcp socket编程是因为底层是基于tcp/ip协议的,比如QQ聊天
- b/s结构的http编程,我们使用浏览器去访问服务器时,使用的就是http协议,而http底层依旧时是使用tcp socket实现的。比如京东商城
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0guDWXKw-1646573975977)(http://h9x14s4c.xyz/img/202112081154307.png)]
路由跟踪:tracert www.baidu.com

tcp网络编程
tcp 监听案例:
package main
import (
"fmt"
"net"
)
func main() {
fmt.Println("服务器开始监听...")
listen, err := net.Listen("tcp", "127.0.0.1:8888")
if err != nil {
fmt.Println("listen error", err)
return
}
defer listen.Close()
// 循环等待客户端来连接
for {
fmt.Println("等待客户端连接...")
conn, err := listen.Accept()
if err != nil {
fmt.Println("Accept() error=", err)
} else {
fmt.Println("Accept() conn=", conn)
}
}
}
使用telnet 127.0.0.1 8888测试
简单客户端服务端交互案例:
server
package main
import (
"fmt"
"net"
)
func process(conn net.Conn) {
// 这里循环客户端发送的数据
defer conn.Close()
for {
buf := make([]byte, 1024)
// 等待客户端通过conn发送信息
// 如果客户端没有wrtie[发送]那么协程就阻塞在这里
//fmt.Printf("服务器在等待客户端%s 发送信息\n"+conn.RemoteAddr().String())
n, err := conn.Read(buf)
if err != nil{
fmt.Println("服务器的Read err=",err)
return
}
// 显示客户端发送的内容到服务器终端
fmt.Print(string(buf[:n]))
}
}
func main() {
fmt.Println("服务器开始监听...")
listen, err := net.Listen("tcp", "127.0.0.1:8888")
if err != nil {
fmt.Println("listen error", err)
return
}
defer listen.Close()
// 循环等待客户端来连接
for {
//fmt.Println("等待客户端连接...")
conn, err := listen.Accept()
if err != nil {
fmt.Println("Accept() error=", err)
} else {
fmt.Println("Accept() conn=", conn.LocalAddr())
}
go process(conn)
}
}
client
package main
import (
"bufio"
"fmt"
"net"
"os"
"strings"
)
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:8888")
if err != nil {
fmt.Println("client dial err = ", err)
return
}
// 功能一:客户端可以发送单行数据,然后就退出
reader := bufio.NewReader(os.Stdin) //os.Stdin 代表标准输入[终端]
for {
line, err := reader.ReadString('\n')
if err != nil {
fmt.Println("readString err=", err)
}
// 如果用户输入的是exit,就退出
line = strings.Trim(line,"\n\r")
if line=="exit" {
fmt.Println("客户端退出..")
break
}
// 再将line发送给 服务器
n, err := conn.Write([]byte(line+"\n"))
if err != nil {
fmt.Println("conn.Write err=", err)
}
fmt.Printf("客户端发送了 %d 字节的数据\n", n)
}
}
http网络编程
package main
import (
"fmt"
"io"
"net/http"
)
func main() {
// 设置路由
http.HandleFunc("/user", func(writer http.ResponseWriter, request *http.Request) {
// 通过writer 将数据返回客户端
// request包含客户发来的数据
fmt.Println("request:", request)
_, _ = io.WriteString(writer, `{"name":"zhangsan"}`)
})
http.HandleFunc("/name", func(writer http.ResponseWriter, request *http.Request) {
fmt.Println("request:", request)
_, _ = io.WriteString(writer, `testName`)
})
http.HandleFunc("/address", func(writer http.ResponseWriter, request *http.Request) {
fmt.Println("request:", request)
_, _ = io.WriteString(writer, `{"address":"广州"}`)
})
// 设置监听
fmt.Println("Http Server start...")
if err := http.ListenAndServe("localhost:8089", nil); err != nil {
fmt.Println("http start failed,err:", err)
return
}
}
微服务
RPC协议
RPC(Remote Procedure Call)远程过程调用协议
IPC :进程间通信
RPC:远程进程通信
OSI7层模型架构:物、数、网、传、会、表、应
TCP/IP4层架构:链路层、网络层、传输层、应用层
RPC快速入门
回顾:Go一般性网络socket通信
server端:
net.Listen() --listener //创建监听
listener.Accpet()–conn //启用监听建立连接
conn.read()
conn.write()
conn.Close()/listener.Close()
client端:
net.Dial()–conn
conn.Write()
conn.Read()
defer conn.Close()
RPC使用步骤:
—服务端
1、注册rpc服务对象。给对象绑定方法(1.定义类,2.绑定类方法)
rpc.RegisterName("服务名",回调对象)
2、创建监听器
listener,err := net.Listen()
3、建立连接
conn, err := listener.Accept()
4、将连接绑定rpc服务
rpc.ServeConn(conn)
—客户端
1、用rpc连接服务器。rpc.Dial()
conn,err := rpc.Dial()
2、调用远程函数
conn.Call("服务名.方法名",传入参数,传出参数)
RPC相关函数
1.注册rpc服务
func RegisterName(name string, rcvr interface{}) error
//RegisterName函数类似Register函数,但使用提供的name代替rcvr的具体类型名作为服务名。
// 参1:服务名。字符串类型
// 参2:对应rpc对象。该对象绑定方法要满足如下条件
// 1)方法必须是导出的--包外可见。首字母大写
// 2)方法必须有两个参数,都是导出类型、内建类型
// 3)方法的第二个参数必须是"指针" (传出参数)
// 4)方法只有一个error 接口类型的返回值
// 举例:
type World struct{
}
func (world *World) HelloWorld(name string, resp *string) error{
}
rps.RegisterName("服务名",new(World))
2.绑定rpc服务
func ServeConn(conn io.ReadWriteCloser)
//ServeConn在单个连接上执行DefaultServer。ServeConn会阻塞,服务该连接直到客户端挂起。调用者一般应另开线程调用本函数:"go ServeConn(conn)"。ServeConn在该连接使用gob(参见encoding/gob包)有线格式。要使用其他的编解码器,可调用ServeCodec方法。
//conn:成功建立好的socket--conn
Redis 快速入门

C:\Users\86150>redis-cli # 启动redis
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set mykey1 helloWork # 存入一个键为mykey1的数据
OK
127.0.0.1:6379> get mykey1 # 获取一个键为mykey1 的数据
"helloWork"
127.0.0.1:6379> select 1 # 切换到1号数据库
OK
127.0.0.1:6379[1]> get mykey1 #此数据库中没有刚才所存的数据
(nil)
127.0.0.1:6379[1]> select 0 # 切回默认0号数据库
OK
127.0.0.1:6379> get mykey1
"helloWork"
127.0.0.1:6379> dbsize # 查询数据库数据总量
(integer) 1
127.0.0.1:6379> flushdb # 清空当前数据库
OK
127.0.0.1:6379> get mykey1
(nil)
127.0.0.1:6379> flushall # 清空所有数据库的数据
OK
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N16Efl9c-1646573975979)(http://h9x14s4c.xyz/img/202112081706661.png)]
字符串

127.0.0.1:6379> set address ᄍ ̄ᄊᆱ
OK
127.0.0.1:6379> get address
"\xb9\xe3\xb6\xab"
127.0.0.1:6379> set address guangdong
OK
127.0.0.1:6379> get address
"guangdong"
127.0.0.1:6379> del address
(integer) 1
127.0.0.1:6379> get address
(nil)
超时废除

127.0.0.1:6379> setex mess1 10 hello
OK
127.0.0.1:6379> get mess1
(nil)
同时设置多对键值对

127.0.0.1:6379> mset worker01 tom worker02 mary
OK
127.0.0.1:6379> get worker01
"tom"
127.0.0.1:6379> get worker02
"mary"
127.0.0.1:6379> mget worker02 worker01
1) "mary"
2) "tom"
hash


127.0.0.1:6379> hset
name "zhangsan"
(integer) 1
127.0.0.1:6379> hset user1 age 30
(integer) 1
127.0.0.1:6379> hset user1 job "golang"
(integer) 1
127.0.0.1:6379> hget user1 name
"zhangsan"
127.0.0.1:6379> hget user1 age
"30"
127.0.0.1:6379> hgetall user1
1) "name"
2) "zhangsan"
3) "age"
4) "30"
5) "job"
6) "golang"
127.0.0.1:6379> hdel user1 job
(integer) 1
127.0.0.1:6379> hgetall user1
1) "name"
2) "zhangsan"
3) "age"
4) "30"
127.0.0.1:6379> hmset user1 job golang address "guangdong"
OK
127.0.0.1:6379> hgetall user1
1) "name"
2) "zhangsan"
3) "age"
4) "30"
5) "job"
6) "golang"
7) "address"
8) "guangdong"
127.0.0.1:6379> hmget user1 name age job
1) "zhangsan"
2) "30"
3) "golang"
127.0.0.1:6379> hlen user1
(integer) 4
127.0.0.1:6379> hexists user1 name
(integer) 1
127.0.0.1:6379> hexists user1 name1
(integer) 0
list

指向总是从左往右
127.0.0.1:6379> lpush city beijing shanghai tianjing
(integer) 3
127.0.0.1:6379> lrange city 0 -1
1) "tianjing"
2) "shanghai"
3) "beijing"
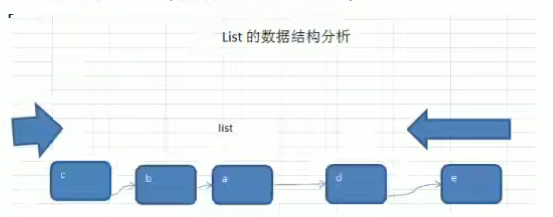
127.0.0.1:6379> lpush list1 aaa bbb ccc
(integer) 3
127.0.0.1:6379> lrange list1 0 -1
1) "ccc"
2) "bbb"
3) "aaa"
127.0.0.1:6379> rpush list1 ddd eee
(integer) 5
127.0.0.1:6379> lrange list1 0 -1
1) "ccc"
2) "bbb"
3) "aaa"
4) "ddd"
5) "eee"
127.0.0.1:6379> lpop list1
"ccc"
127.0.0.1:6379> lrange list1 0 -1
1) "bbb"
2) "aaa"
3) "ddd"
4) "eee"
127.0.0.1:6379> rpop list1
"eee"
127.0.0.1:6379> lrange list1 0 -1
1) "bbb"
2) "aaa"
3) "ddd"
list的使用细节
- lindex ,按照索引下标获得元素(从左到右,编号从0开始)
- LLEN key 返回列表的长度,如果key不存在,则key被解释为一个空列表,返回0
- list的其他说明
- list数据,可以从左或者右插入添加
- 如果值全移除,对应的键也就消失了
set
Redis的Set是string类型的无序集合
底层是HashTable数据结构,Set也是存放很多字符串元素,字符串元素是无序的,而且元素的值不能重复

127.0.0.1:6379> sadd emails tom@sohu.com jack@qq.com
(integer) 2
127.0.0.1:6379> smembers emails
1) "tom@sohu.com"
2) "jack@qq.com"
127.0.0.1:6379> sadd emails tom@sohu.com jack@qq.com
(integer) 0
127.0.0.1:6379> sismember emails tom@sohu.com
(integer) 1
127.0.0.1:6379> srem emails tom@sohu.com
(integer) 1
127.0.0.1:6379> smembers emails
1) "jack@qq.com"
golang中连接redis
下载redis官方驱动包
go get github.com/gomodule/redigo/redis
package main
import (
"fmt"
"github.com/gomodule/redigo/redis"
)
func main() {
// 1、连接redis
conn, err := redis.Dial("tcp", "localhost:6379")
if err != nil {
fmt.Println("redis.Dial err=", err)
return
}
defer conn.Close()
fmt.Println("conn suc..", conn)
// 2、通过go向redis写入数据string
_, errSet := conn.Do("Set", "name", "tom")
if errSet != nil {
fmt.Println("set err=", errSet)
return
}
fmt.Println("set操作ok")
// 3、通过go向redis读取数据string
res, errGet := redis.String(conn.Do("Get", "name"))
if errGet != nil {
fmt.Println("set err=",
)
return
}
// 因为返回 r是interface{}
// 因为name对应的值是string,因此我们需要转换
// nameString := res.(string) // 不建议用这种方法使用
fmt.Println("get操作ok:", res)
//4、使用Hash存放多个值
_, errHSet := conn.Do("HSet", "user01", "age",111)
if errHSet != nil {
fmt.Println("Hset err=", errHSet)
return
}
Hres, errHGet := redis.String(conn.Do("HGet", "user01","name"))
if errHGet != nil {
fmt.Println("Hget err=", errHGet)
return
}
fmt.Println("Hget操作ok:", Hres)
// 一次性取回多个值
HGAres, errHGetAll := redis.Strings(conn.Do("HMGet", "user01","name","age"))
if errHGetAll != nil {
fmt.Println("Hget err=", errHGetAll)
return
}
fmt.Println("HGAres操作ok:", HGAres)
}
redis连接池
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QikhVMiV-1646573975984)(http://h9x14s4c.xyz/img/202112091051492.png)]
package main
import (
"fmt"
"github.com/gomodule/redigo/redis"
)
// 定义一个全局的pool
var pool *redis.Pool
// 当启动程序时,就初始化连接池
func init() {
pool = &redis.Pool{
MaxIdle: 10, // 最大空闲连接数
MaxActive: 0, // 表示和数据库的最大,0表示没有限制
IdleTimeout: 100, // 最大空闲时间
Dial: func() (redis.Conn, error) { // 初始化链接代码,链接那个ip的redis
return redis.Dial("tcp", "localhost:6379")
},
}
}
func main() {
// 先从pool取出一个连接
conn := pool.Get()
defer conn.Close()
_, err := conn.Do("Set", "name", "小汤姆")
if err != nil {
fmt.Println(err)
return
}
// 取出
r, errGet := redis.String(conn.Do("Get", "name"))
if errGet != nil {
fmt.Println(errGet)
return
}
fmt.Println(r)
// 如果我们要从pool取出连接,一定要保证链接池是没有关系
}
及时通讯系统
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GbVP34u6-1646573975985)(http://h9x14s4c.xyz/img/202112081621948.png)]
数据结构(算法介绍)
稀疏数组
- 记录数组一共有几行几列,有多少个不同的值
- 把具有不同值的元素的行列及值在一个小规模的数组中,从而缩小程序规模
待更新…
ess
(nil)
### 超时废除
[外链图片转存中...(img-eBER4rya-1646573975980)]
```bash
127.0.0.1:6379> setex mess1 10 hello
OK
127.0.0.1:6379> get mess1
(nil)
同时设置多对键值对
[外链图片转存中…(img-feKcpSW3-1646573975980)]
127.0.0.1:6379> mset worker01 tom worker02 mary
OK
127.0.0.1:6379> get worker01
"tom"
127.0.0.1:6379> get worker02
"mary"
127.0.0.1:6379> mget worker02 worker01
1) "mary"
2) "tom"
hash
[外链图片转存中…(img-he0WceMD-1646573975981)]
[外链图片转存中…(img-BZsikt3p-1646573975981)]
127.0.0.1:6379> hset
name "zhangsan"
(integer) 1
127.0.0.1:6379> hset user1 age 30
(integer) 1
127.0.0.1:6379> hset user1 job "golang"
(integer) 1
127.0.0.1:6379> hget user1 name
"zhangsan"
127.0.0.1:6379> hget user1 age
"30"
127.0.0.1:6379> hgetall user1
1) "name"
2) "zhangsan"
3) "age"
4) "30"
5) "job"
6) "golang"
127.0.0.1:6379> hdel user1 job
(integer) 1
127.0.0.1:6379> hgetall user1
1) "name"
2) "zhangsan"
3) "age"
4) "30"
127.0.0.1:6379> hmset user1 job golang address "guangdong"
OK
127.0.0.1:6379> hgetall user1
1) "name"
2) "zhangsan"
3) "age"
4) "30"
5) "job"
6) "golang"
7) "address"
8) "guangdong"
127.0.0.1:6379> hmget user1 name age job
1) "zhangsan"
2) "30"
3) "golang"
127.0.0.1:6379> hlen user1
(integer) 4
127.0.0.1:6379> hexists user1 name
(integer) 1
127.0.0.1:6379> hexists user1 name1
(integer) 0
list
[外链图片转存中…(img-qTacs6R1-1646573975982)]
指向总是从左往右
127.0.0.1:6379> lpush city beijing shanghai tianjing
(integer) 3
127.0.0.1:6379> lrange city 0 -1
1) "tianjing"
2) "shanghai"
3) "beijing"
[外链图片转存中…(img-YFtODg0q-1646573975982)]
[外链图片转存中…(img-EJhH4dkM-1646573975983)]
127.0.0.1:6379> lpush list1 aaa bbb ccc
(integer) 3
127.0.0.1:6379> lrange list1 0 -1
1) "ccc"
2) "bbb"
3) "aaa"
127.0.0.1:6379> rpush list1 ddd eee
(integer) 5
127.0.0.1:6379> lrange list1 0 -1
1) "ccc"
2) "bbb"
3) "aaa"
4) "ddd"
5) "eee"
127.0.0.1:6379> lpop list1
"ccc"
127.0.0.1:6379> lrange list1 0 -1
1) "bbb"
2) "aaa"
3) "ddd"
4) "eee"
127.0.0.1:6379> rpop list1
"eee"
127.0.0.1:6379> lrange list1 0 -1
1) "bbb"
2) "aaa"
3) "ddd"
list的使用细节
- lindex ,按照索引下标获得元素(从左到右,编号从0开始)
- LLEN key 返回列表的长度,如果key不存在,则key被解释为一个空列表,返回0
- list的其他说明
- list数据,可以从左或者右插入添加
- 如果值全移除,对应的键也就消失了
set
Redis的Set是string类型的无序集合
底层是HashTable数据结构,Set也是存放很多字符串元素,字符串元素是无序的,而且元素的值不能重复
[外链图片转存中…(img-psIacFbG-1646573975983)]
127.0.0.1:6379> sadd emails tom@sohu.com jack@qq.com
(integer) 2
127.0.0.1:6379> smembers emails
1) "tom@sohu.com"
2) "jack@qq.com"
127.0.0.1:6379> sadd emails tom@sohu.com jack@qq.com
(integer) 0
127.0.0.1:6379> sismember emails tom@sohu.com
(integer) 1
127.0.0.1:6379> srem emails tom@sohu.com
(integer) 1
127.0.0.1:6379> smembers emails
1) "jack@qq.com"
golang中连接redis
下载redis官方驱动包
go get github.com/gomodule/redigo/redis
package main
import (
"fmt"
"github.com/gomodule/redigo/redis"
)
func main() {
// 1、连接redis
conn, err := redis.Dial("tcp", "localhost:6379")
if err != nil {
fmt.Println("redis.Dial err=", err)
return
}
defer conn.Close()
fmt.Println("conn suc..", conn)
// 2、通过go向redis写入数据string
_, errSet := conn.Do("Set", "name", "tom")
if errSet != nil {
fmt.Println("set err=", errSet)
return
}
fmt.Println("set操作ok")
// 3、通过go向redis读取数据string
res, errGet := redis.String(conn.Do("Get", "name"))
if errGet != nil {
fmt.Println("set err=",
)
return
}
// 因为返回 r是interface{}
// 因为name对应的值是string,因此我们需要转换
// nameString := res.(string) // 不建议用这种方法使用
fmt.Println("get操作ok:", res)
//4、使用Hash存放多个值
_, errHSet := conn.Do("HSet", "user01", "age",111)
if errHSet != nil {
fmt.Println("Hset err=", errHSet)
return
}
Hres, errHGet := redis.String(conn.Do("HGet", "user01","name"))
if errHGet != nil {
fmt.Println("Hget err=", errHGet)
return
}
fmt.Println("Hget操作ok:", Hres)
// 一次性取回多个值
HGAres, errHGetAll := redis.Strings(conn.Do("HMGet", "user01","name","age"))
if errHGetAll != nil {
fmt.Println("Hget err=", errHGetAll)
return
}
fmt.Println("HGAres操作ok:", HGAres)
}
redis连接池
![[外链图片转存中...(img-QikhVMiV-1646573975984)]](https://img-blog.csdnimg.cn/c083ffbcad0d47d4b4721210f7fdfb84.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_18,color_FFFFFF,t_70,g_se,x_16)
package main
import (
"fmt"
"github.com/gomodule/redigo/redis"
)
// 定义一个全局的pool
var pool *redis.Pool
// 当启动程序时,就初始化连接池
func init() {
pool = &redis.Pool{
MaxIdle: 10, // 最大空闲连接数
MaxActive: 0, // 表示和数据库的最大,0表示没有限制
IdleTimeout: 100, // 最大空闲时间
Dial: func() (redis.Conn, error) { // 初始化链接代码,链接那个ip的redis
return redis.Dial("tcp", "localhost:6379")
},
}
}
func main() {
// 先从pool取出一个连接
conn := pool.Get()
defer conn.Close()
_, err := conn.Do("Set", "name", "小汤姆")
if err != nil {
fmt.Println(err)
return
}
// 取出
r, errGet := redis.String(conn.Do("Get", "name"))
if errGet != nil {
fmt.Println(errGet)
return
}
fmt.Println(r)
// 如果我们要从pool取出连接,一定要保证链接池是没有关系
}
及时通讯系统
![[外链图片转存中...(img-GbVP34u6-1646573975985)]](https://img-blog.csdnimg.cn/c51d689ffe2f4c97b0dd50ccd130d242.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
数据结构(算法介绍)
稀疏数组
![[外链图片转存中...(img-PivTh7xn-1646573975985)]](https://img-blog.csdnimg.cn/11d3fa339d3a49e4885b90b9a79bcf9c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_20,color_FFFFFF,t_70,g_se,x_16)
- 记录数组一共有几行几列,有多少个不同的值
- 把具有不同值的元素的行列及值在一个小规模的数组中,从而缩小程序规模
![[外链图片转存中...(img-NJoT7Dze-1646573975986)]](https://img-blog.csdnimg.cn/0db06975cd2c437db49c3f492d146169.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmF1Z2h0eXl5,size_17,color_FFFFFF,t_70,g_se,x_16)
待更新…
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











