






正文
想下载无水印视频当然要找到无水印的视频的地址 于是在抖音的视频右下方点击分享 会弹出很多的分享的方式 这里我们选择复制链接 这样就会得到这个

这段文字里的url地址复制手机浏览器打开会出现原视频 只是也会带水印的,但如果要是复制到电脑打开 就会惊喜的发现水印不见了~
所以使用桌面浏览器的ua访问这个url地址 得到的视频是无水印的,现在只要找到视频的下载地址 即可get到无水印的文件
访问视频地址https://v.douyin.com/dTJPrsy/
打开Network 清除所有已加载请求 然后点击视频播放按钮
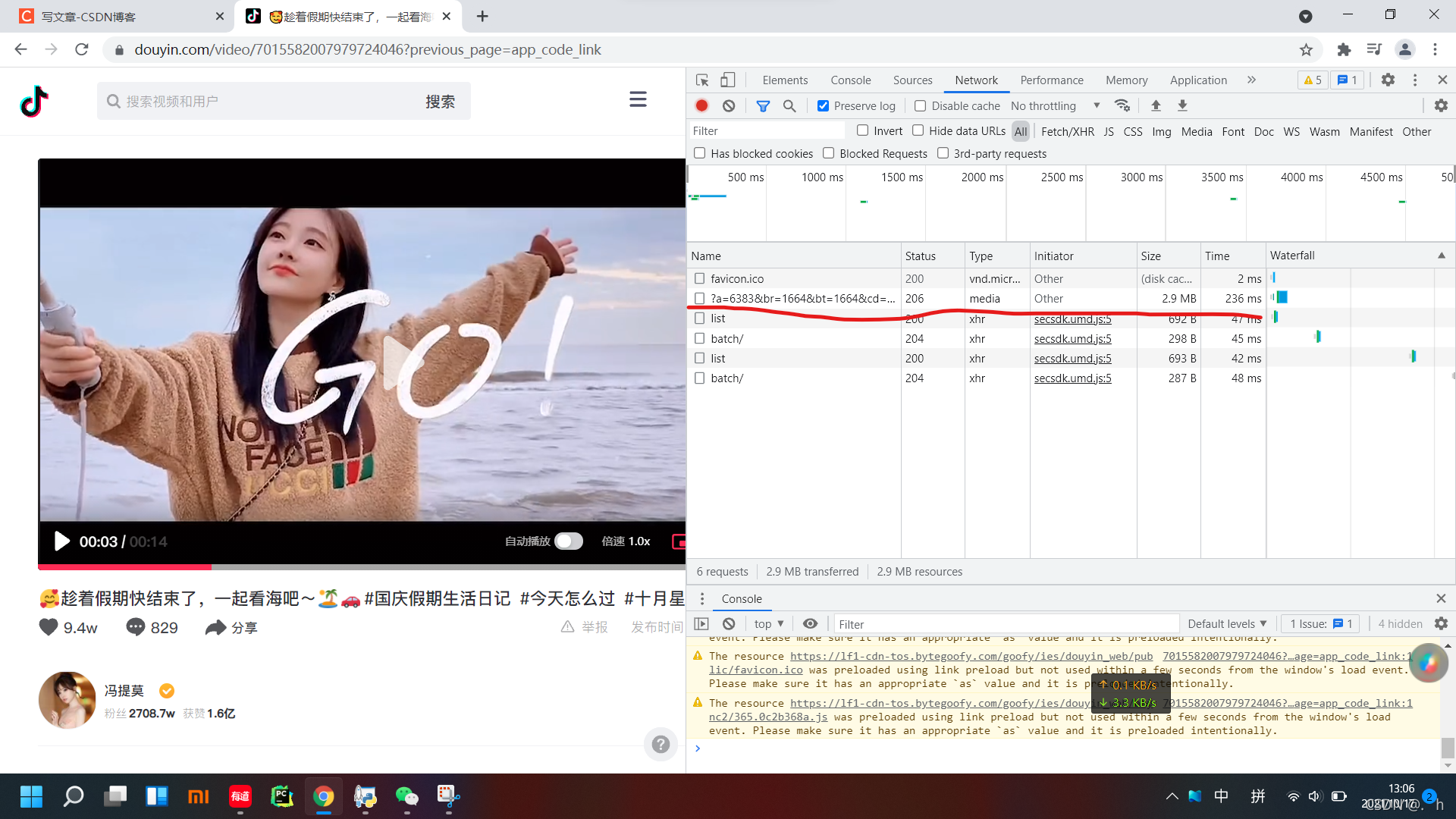
发现一个请求加载了2.9mb的资源,点开它 复制它的url地址打开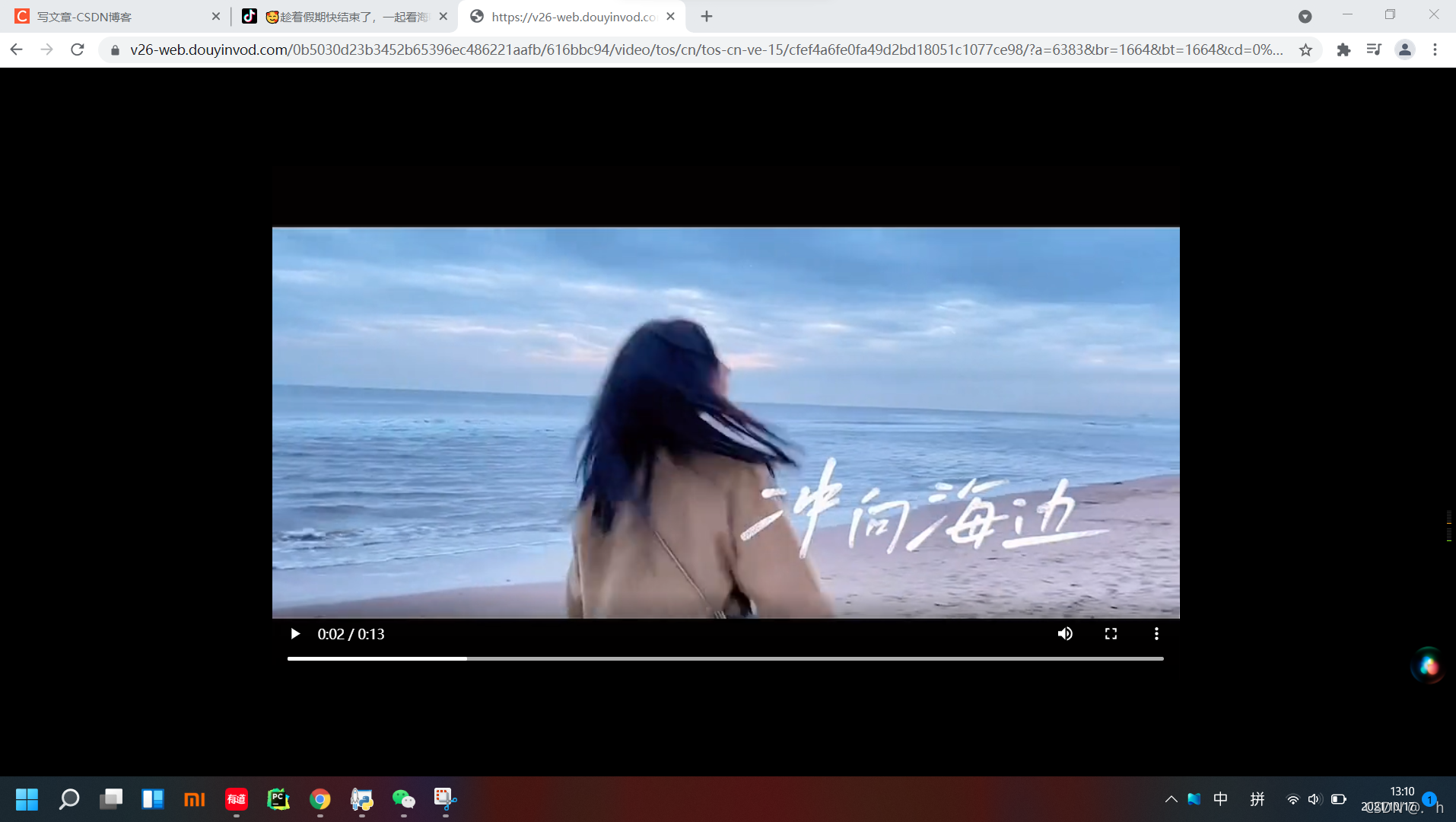
搞定 的确是无水印的视频
这时就要开始研究这个无水印的视频的url地址是什么时候加载的,找了大概3分钟 发现竟然就在第一个请求就加载了无水印视频的url地址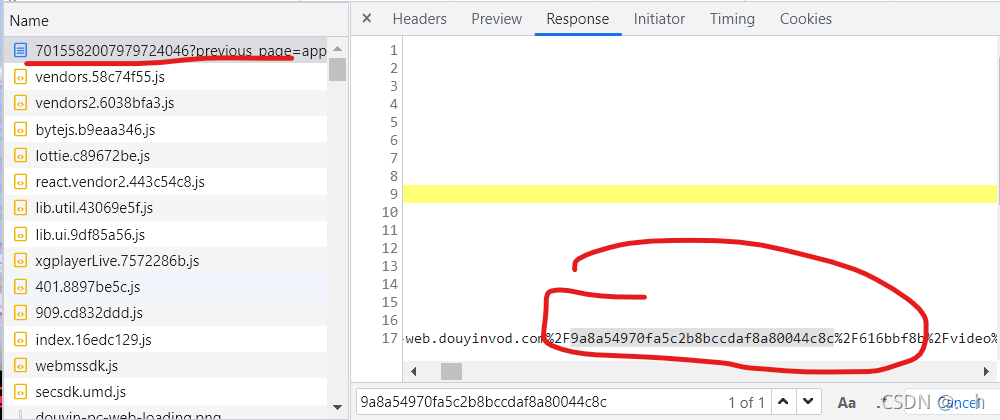
当然这里是被编码的
复制该条请求的url地址, 打开pycharm 用requests库请求然后解码输出一下,看看无水印视频的url地址在不在这里
不知道为什么,请求这个地址有时候会被重定向,但多试几次还是能get到的 这里可以在异常的时候,捕获异常 然后递归回去重新请求
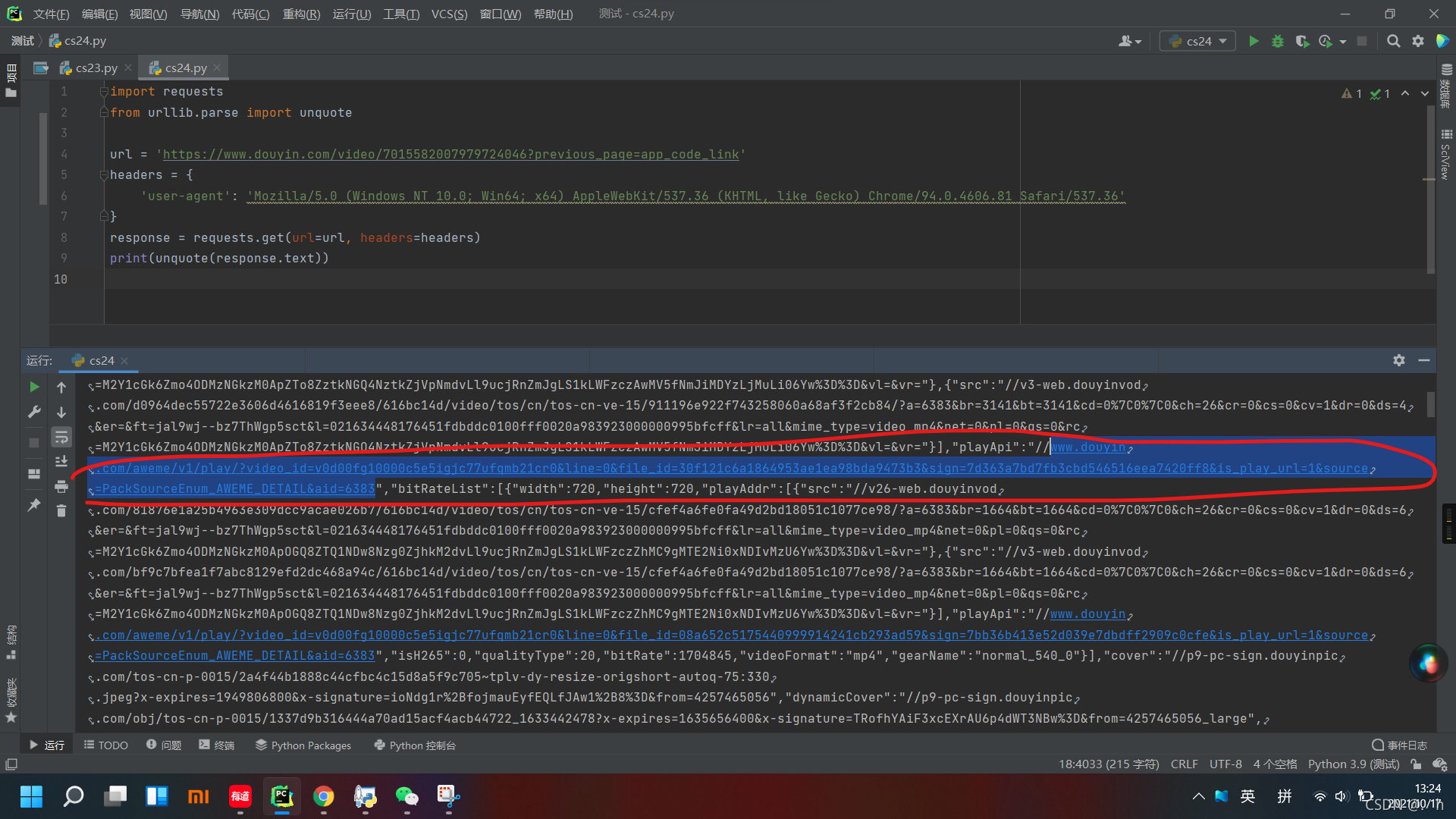
果然, 轻松找到,无水印视频的地址https://www.douyin.com/aweme/v1/play/?video_id=v0d00fg10000c5e5igjc77ufqmb21cr0&line=0&file_id=30f121c6a1864953ae1ea98bda9473b3&sign=7d363a7bd7fb3cbd546516eea7420ff8&is_play_url=1&source=PackSourceEnum_AWEME_DETAIL&aid=6383
所以现在只要把之前的流程串起来,就可以完成使用python下载无水印视频的需求
当我着手开始写代码我才发现,谷歌浏览器抓包工具第一个请求不是我输入进去的url
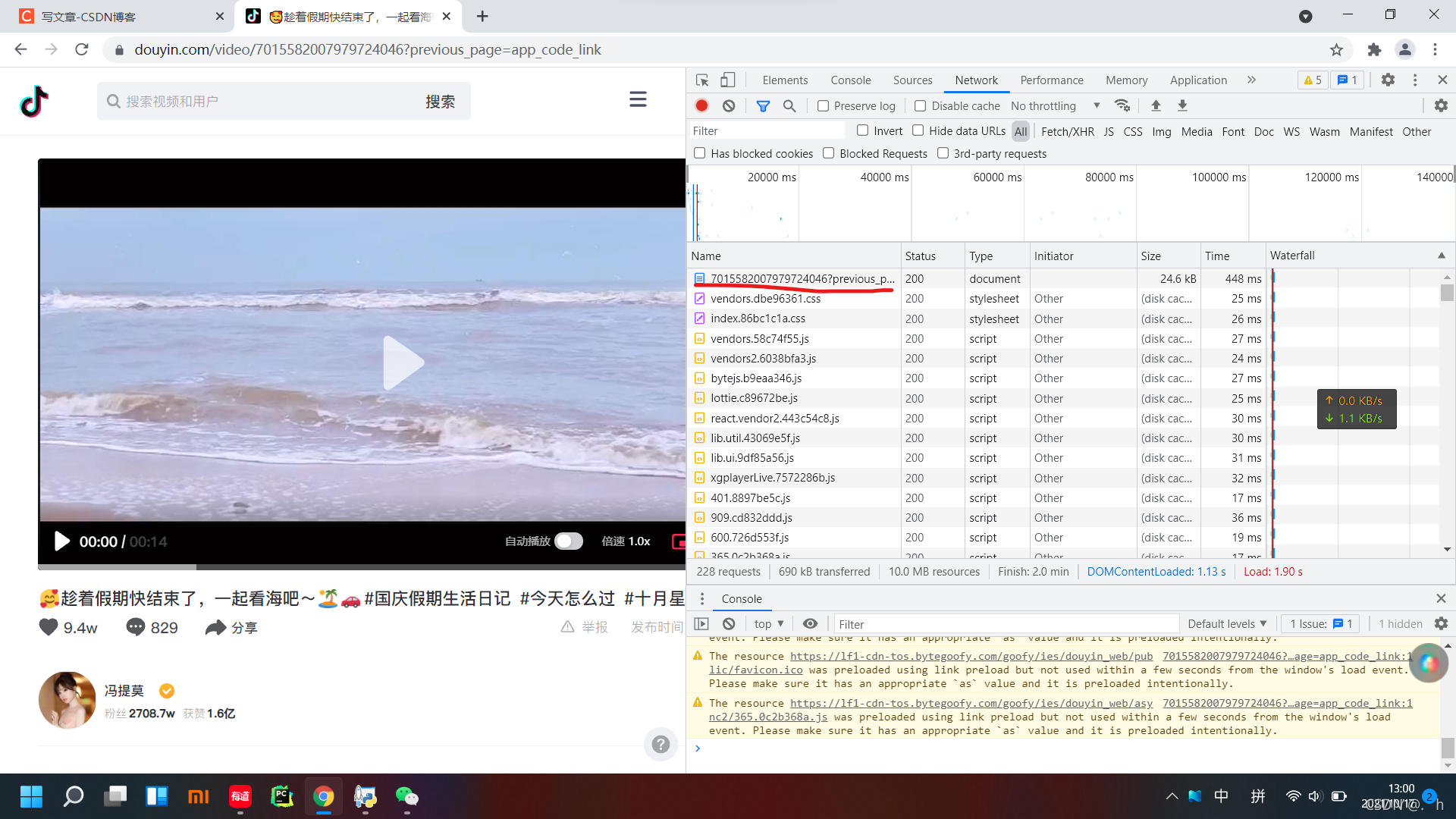
这时才发现该地址被重定向了
那勾选保留日志再请求一次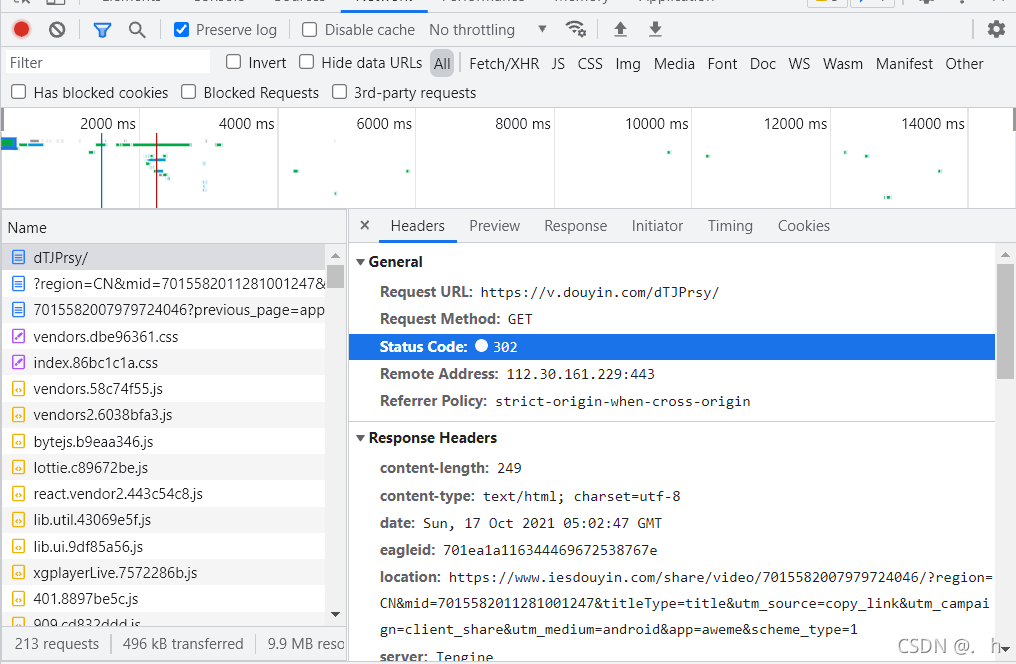
果然被重定向了 而且还是两次
知道原因就好办了,打开pytharm
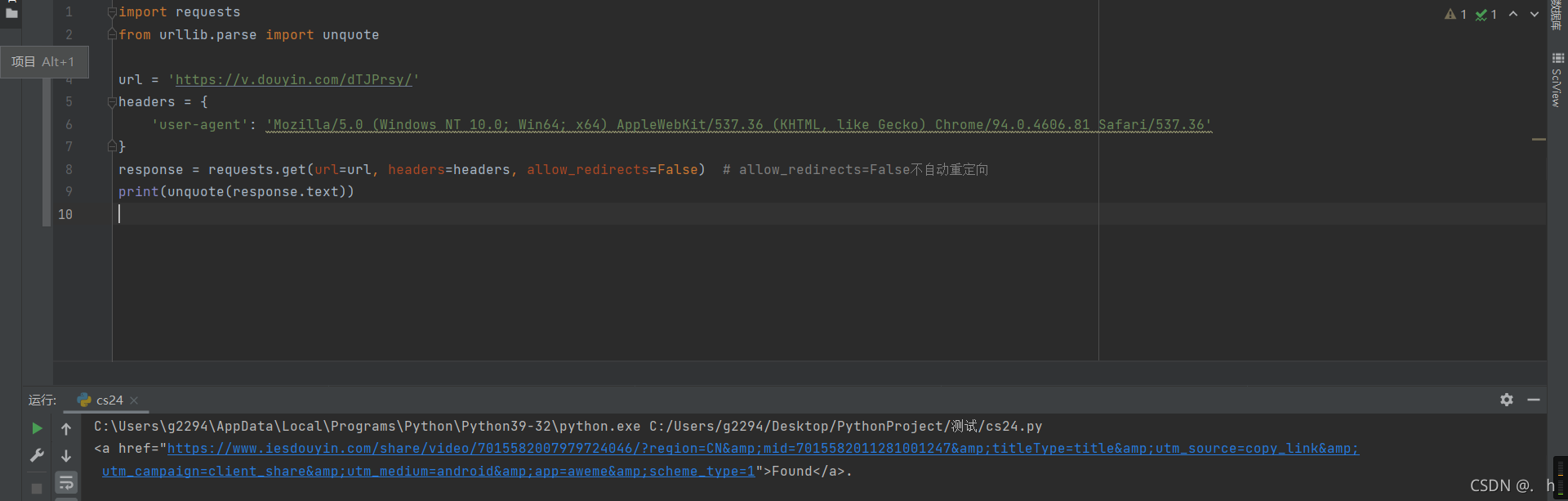
轻松得到第一次重定向后的地址
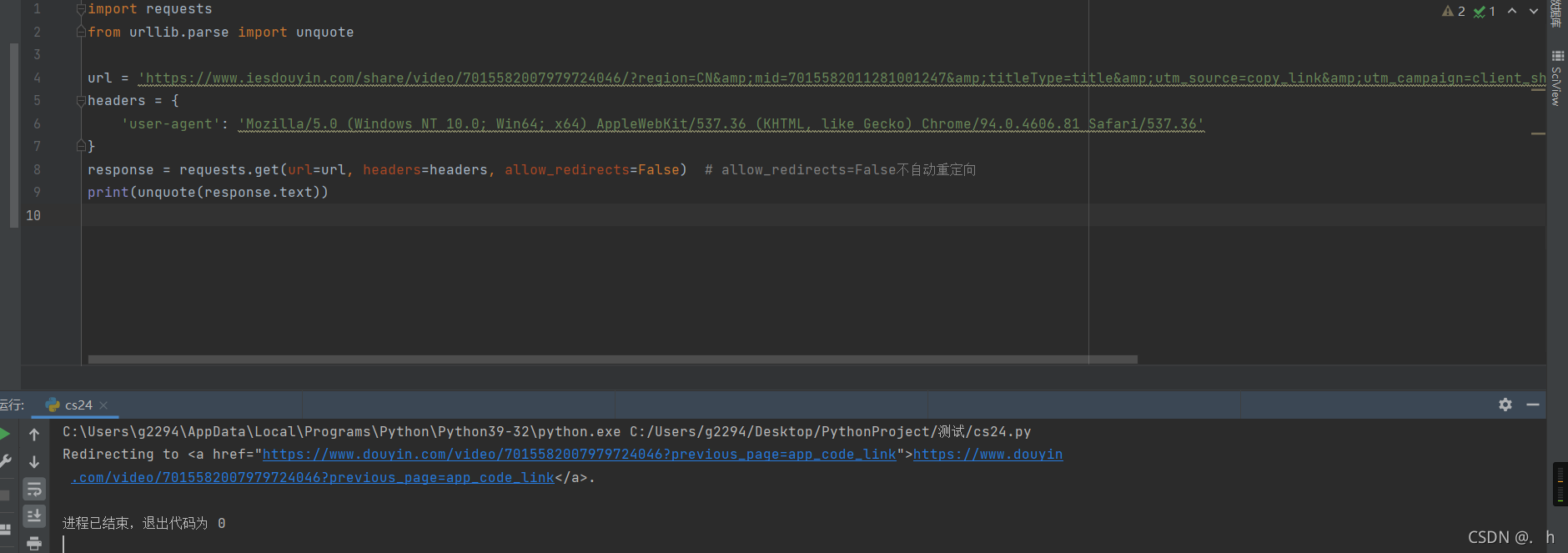
如法炮制得到第二次重定向后的地址,比对了一下 就是那个包含了无水印url的url
所以只要用正则提取出二次重定向后的url地址中的无水印视频的url再请求这个地址 就可以得到无水印视频
完整代码
import requests
import re
from urllib.parse import unquote
import time
import os
class GetDouYingVideo(object):
def __init__(self, url):
self.url = url
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.32'}
self.counter = 0
self.get_video_id()
def get_video_id(self):
if self.counter == 0:
print('重定向作品地址ing 请稍后...')
response0 = requests.get(self.url, headers=self.headers, allow_redirects=False)
response1 = requests.get(re.search(r'\"(.+)\"', response0.text).group(1), headers=self.headers,
allow_redirects=False)
response2 = requests.get(re.search(r'\"(.+)\"', response1.text).group(1), headers=self.headers)
# print(unquote(response2.text))
if self.counter != 0:
print(f'获取视频文件地址失败 正在{str(self.counter)}次重试')
else:
print('获取视频地址ing 请稍后...')
try:
# 因为请求这个地址有可能会被再次重定向 没办法 只得在失败后递归回来 再次请求
result = re.search(r'"playApi":"//(.+)","bitRateList"', unquote(response2.text)).group(1)
response3 = requests.get('https://' + result, headers=self.headers)
name = re.search('<head><title data-react-helmet="true">(.*)</title>', response2.text).group(1)
with open(name + '.mp4', 'wb') as f:
f.write(response3.content)
except AttributeError:
self.counter += 1
time.sleep(3)
self.get_video_id()
if __name__ == '__main__':
GetDouYingVideo(input('请输入要下载的视频地址'))
print('下载无水印视频成功!')
os.system('pause')
写博客的经验很少,有错误希望多多指正。 有问题也欢迎留言看到 看到一定会回复

















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









