







前言
该文章记录了近些年常见的数据结构相关笔试题,不涉及繁琐算法题或逻辑题
该文章适合有学习过C语言与数据结构的朋友阅读,主要是针对本科应届生。
链表
该部分较为基础,主要出现在一些中小公司的笔试大题。有时会在面试中询问解决方案。该部分所有链表均为单向有头链表,结点结构如下:
typedef struct Node {
int data; //数据域,报错数据
struct Node *next; //指针域,指向下一个结点的地址
}node_t;链表的排序
方案一、将原有链表打断,重新按顺序插入
//有序插入 将node结点按顺序插入到链表中
void insert_linklist_order(node_t *head, node_t *node)
{
node_t *p = NULL;
for (p = head; p != NULL; p = p->next) {
if (p->next == NULL || node->data < p->next->data) {
node->next = p->next;
p->next = node;
break;
}
}
}
//给链表排序
void sort_linklist(node_t* head)
{
if (head == NULL) {
return;
}
node_t *p = head->next; //将链表打断,p指向链表后面部分
head->next = NULL;
while (p != NULL) { //依次将后面的部分按顺序重新插入到链表中
node_t *tmp = p->next;
insert_linklist_order(head, p);
p = tmp;
}
}方案二、只交换链表内数据,不更换指针域,此处以冒泡排序举例
void sort_linklist(node_t *head)
{
if (head == NULL) {
return;
}
node_t *end = NULL; //保存尾值
for (node_t *i = head->next; i->next != NULL; i = i->next) {
for (node_t *j = list->next; j->next != end; j = j->next) {
if (j->data > j->next->data) {
int tmp = j->data;
j->data = j->next->data;
j->next->data = tmp;
}
}
end = j; //更新尾值,提高性能
}
}链表的逆序
将链表看成两个链表,第一个链表只有头结点与第一个元素,第二个链表从第二个元素开始,将第二个链表的元素以头插法的形式依次插入到第一个链表中即可
void reverse_linklist(node_t *head)
{
if (head == NULL || head->next == NULL) {
return;
}
//保存第二个有效数据的地址
node_t *p = head->next->next;
//把第一个有效数据的next置为NULL 拆分成两个链表操作
head->next->next = NULL;
//将p看成链表的头结点,将p中元素依次头插进list中
node_t *tmp = NULL;
while (p != NULL) {
tmp = p;
p = p->next;
tmp->next = head->next;
head->next = tmp;
}
return;
}两个有序链表合并成一个有序链表
node_t* and_linklist(node_t *list1, node_t *list2)
{
if (list1 == NULL) {
return list2;
}
if (list2 == NULL) {
return list1;
}
node_t *p1 = list1->next;
node_t *p2 = list2->next;
node_t *tmp = list;
free(list2); //以list1为结点,释放list2
while (1) {
if (p1->data > p2->data) { //比较两个链表每个结点大小
tmp->next = p2;
p2 = p2->next;
tmp = tmp->next;
if (p2 == NULL) { //list2结点遍历结束后连接list1后所有数据退出
tmp->next = p1;
break;
}
}
else {
tmp->next = p1;
p1 = p1->next;
tmp = tmp->next;
if (p1 == NULL) {
tmp->next = p2;
break;
}
}
}
return list1; //返回合并后链表首地址
}判断链表是否成环
使用快慢指针,有环必相遇。
int if_loop(node_t *head)
{
node_t *quick = head;
node_t *slow = head;
if (head == NULL || head->next == NULL) {
return 0;
}
do
{
quick = quick->next->next; //快指针每次前进两格
slow = slow->next; //慢指针每次前进一格
if (quick == slow) {
return 1; //相遇表示成环
}
}while(quick);
return 0;
}已知f为单链表的表头指针,链表中存储的都是整形数据,试写出求所有整数的平均值的递归算法
// 递归函数计算链表中所有整数的平均值
float calculateAverage(node_t* head, int count, int sum)
{
if (head == NULL) {
return (float)sum / count;
}
else {
sum += head->data;
count++;
return calculateAverage(head->next, count, sum);
}
}二叉树
该部分相对来说较为少见,一般出现在大厂的笔试大题中,基础部分在笔试中可能也要求编写。
二叉树的前中后序遍历
//二叉树结点定义
struct Node {
int data;
struct Node* left;
struct Node* right;
};
//前序遍历
void preOrder(struct Node* root) {
if (root == NULL) {
return;
}
printf("%d ", root->data);
preOrder(root->left);
preOrder(root->right);
}
//中序遍历
void inOrder(struct Node* root) {
if (root == NULL) {
return;
}
inOrder(root->left);
printf("%d ", root->data);
inOrder(root->right);
}
//后序遍历
void postOrder(struct Node* root) {
if (root == NULL) {
return;
}
postOrder(root->left);
postOrder(root->right);
printf("%d ", root->data);
}定义二叉树数据结构并编写C函数foo():遍历计算二叉树所有节点及其叶子节点的数值之和
// 定义二叉树节点结构
struct Node
{
int data;
struct Node* left;
struct Node* right;
};
// 返回数值之和,参数为二叉树根节点
int foo(struct Node* root)
{
if (root == NULL) {
return 0;
}
return root->data + foo(root->left) + foo(root->right);
}查找与排序算法
该部分非常常见,各种级别的公司中都会出现1~2道算法题目。没有记录过于少见或难度较高的算法题。
写一个函数找出一个整数数组中,第二大的数
方案一、使用INT_MIN宏(不推荐)
int findSecondLargest(int *arr, int size)
{
assert((arr != NULL));
int first = -2147483648; //int最小的数 可以用INT_MIN代替
int second = -2147483648;
for (int i = 1; i < size; i++) {
if (arr[i] > first) {
second = first;
first = arr[i];
}
else if (arr[i] > second && arr[i] != first) {
second = arr[i];
}
}
assert((second != -2147483648));
return second;
}方案二、不使用INT_MIN宏(推荐)
int findSecondLargest(int *arr, int size) {
int firstLargest = arr[0];
int secondLargest = arr[0];
for (int i = 1; i < size; i++) {
if (arr[i] > firstLargest) {
secondLargest = firstLargest;
firstLargest = arr[i];
}
else if (arr[i] > secondLargest && arr[i] != firstLargest) {
secondLargest = arr[i];
}
}
return secondLargest;
}希尔排序(shell)
用于排序,适合新人背诵,切记不要在排序题中写冒泡或选择排序。
void shellSort(int *buf, int size)
{
int gap = 0; //表示增量变化
int temp = 0; //记录当前待排序的数据
int i = 0, j = 0;
//增量依次变小
for (gap = size / 2; gap > 0; gap /= 2) {
//直接插入排序
for (i = gap; i < size; ++i) {
temp = buf[i];
for (j = i - gap; j >= 0 && buf[j] > temp; j -= gap) {
buf[j + gap] = buf[j];
}
buf[j + gap] = temp;
}
}
return;
}快速排序(快排)
用于排序,适合进阶一点的人使用,最少要掌握其递归的思想
/*
* buf为数组首地址
* low为待排序数组的最小下标
* high为待排序数组的最大下标
*/
void quickSort(int *buf, int low, int high)
{
int first = low;
int last = high;
int key = buf[first]; //设置第一个数为key
if (low >= high) { //找到中介这一轮判断结束
return ;
}
//使用first与last判断,比key大的放左边,比key小的放右边
while (first < last) {
//从右往左,找到比key小的数,若比key大则继续往左
while (first < last && buf[last] >= ket) {
--last;
}
//将比key小的数放到buf[first]位置
buf[first] = buf[last];
//从左往右,找到比key大的数,若比key小则继续往右
while (first < last && buf[last] <= ket) {
++first;
}
//将比key大的数放到buf[last]位置
buf[last] = buf[first];
}
//first和last相遇 或 first > last 表示该轮结束,将备份的key值赋给buf[first]
buf[first] = key;
quickSort(buf, low, first-1); //对前一半进行排序
quickSort(buf, first+1, high); //对后一半进行排序
}堆排序
用于排序,对思维要求较高,建议有能力的同学背诵,笔试题写此排序算法将非常亮眼
// 调整堆,使以节点i为根的子树成为最大堆
void heapify(int arr[], int n, int i) {
int largest = i; // 初始化最大值为根节点
int left = 2 * i + 1;
int right = 2 * i + 2;
// 如果左子节点比根节点大
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
// 如果右子节点比根节点大
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
// 如果最大值不是根节点,交换根节点和最大值节点
if (largest != i) {
int temp = arr[i];
arr[i] = arr[largest];
arr[largest] = temp;
// 递归调整交换后的子树
heapify(arr, n, largest);
}
}
// 堆排序
void heapSort(int arr[], int n) {
// 构建最大堆
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
// 逐个取出堆顶元素,再调整堆
for (int i = n - 1; i > 0; i--) {
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
heapify(arr, i, 0);
}
}几种排序的复杂度与稳定性
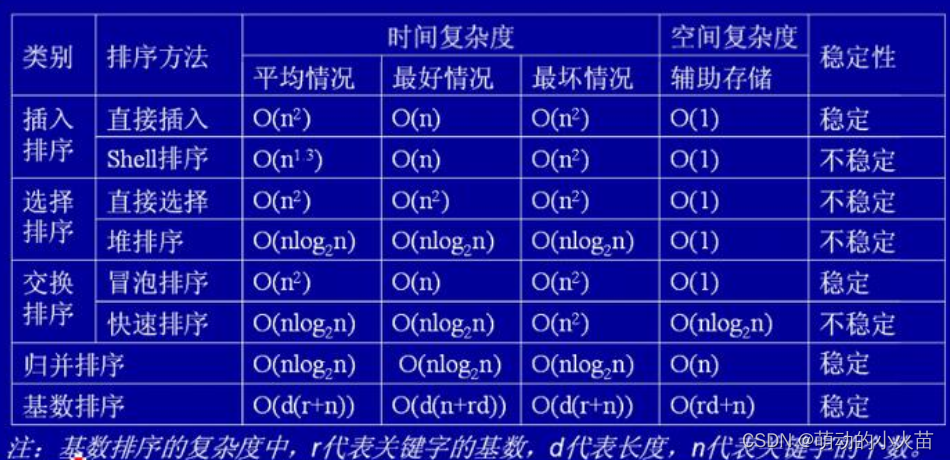
建议至少选择一种排序算法和对应复杂度背诵
(C++) 给定一个n个元素的有序(升序)整型数组nums和一个目标值target,写一个函数搜索nums中的target,如果目标存在则返回下标,否则返回-1。使用二分法。函数原型:int search(vector<int>& nums, int target);
int search(vector<int>& nums, int target)
{
int left = 0;
int right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
return mid;
}
else if (nums[mid] < target) {
left = mid + 1;
}
else {
right = mid - 1;
}
}
return -1;
}结语
编写该文章目的主要为想从事相关工作的同学找到一份好的工作,以上题目在笔试中经常出现,如果有在外面试的朋友发现有更常见更经典的题目也可以私信告知,后续也会更新到博客当中。
如果有朋友想系统的学习嵌入式相关知识,从事相关的行业,可以私信我,有一些经典的电子档书籍资料和开源网课学习链接。















 1766
1766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









