







导言
墨西哥的员工流动率在世界上排名第八,平均每年的流失率约为17%,然而某些行业如:食品服务,则达到50%。根据Catalyst的一项研究,更换员工的成本平均约为员工年薪的50%-75%。考虑到月薪为20,000比索(pesos)的中层职位,更换员工的总成本约为140,000比索(pesos)。平均而言,更换员工需要大约50天,而由于生产力损失而产生的成本将不断增加。对于像everis这样拥有20,000多名员工的大公司,考虑到15%的人员流动率和15,000比索(pesos)的平均工资,每年的总营业成本将上升到至少2.7亿比索(pesos)。
在本文中,我们提供了一个神经网络模型的详细信息,该模型能够识别具有高风险的员工候选人,完成此任务的准确率约为96%。
方法
我们使用了数据集HR Employee Attrition and Performance,这是IBM数据科学家创建的虚构数据集。它包含1,470行员工历史数据。
进行了探索性数据分析,以确定与员工流动率具有最高相关性的特征。这些是最近发现的最重要的功能:
年龄
离家很近
随着时间的推移
教育
婚姻状况
在公司工作的公司数量
总工作年限
月收入
这些特征用于 训练模型以预测周转风险。数据集已经包含一个名为attrition的功能,该功能指示员工是否离开了该职位并且必须进行更换。该特征是one-hot encoded(在将数据分成训练集和测试集之后显示),并且被用作神经网络预测的目标。一下是用于one-hot encoded 的辅助函数:
1from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder 2### One Hot Encoding 3def one_hot_values(values): 4 ''' 5 takes array and returns one hot encoding with label encoder for inverse transform 6 ''' 7 label_encoder = LabelEncoder() 8 integer_encoded = label_encoder.fit_transform(values) 9 onehot_encoder = OneHotEncoder(sparse=False)10 integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)11 onehot_encoded = onehot_encoder.fit_transform(integer_encoded)12 return onehot_encoded, label_encoder13def inverse_one_hot(label_encoder, one_hot):14 inverse = []15 for i in range(len(one_hot)):16 inverse.append(label_encoder.inverse_transform([np.argmax(one_hot[i, :])])[0])17 return inversefrom sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder
2### One Hot Encoding
3def one_hot_values(values):
4 '''
5 takes array and returns one hot encoding with label encoder for inverse transform
6 '''
7 label_encoder = LabelEncoder()
8 integer_encoded = label_encoder.fit_transform(values)
9 onehot_encoder = OneHotEncoder(sparse=False)
10 integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
11 onehot_encoded = onehot_encoder.fit_transform(integer_encoded)
12 return onehot_encoded, label_encoder
13def inverse_one_hot(label_encoder, one_hot):
14 inverse = []
15 for i in range(len(one_hot)):
16 inverse.append(label_encoder.inverse_transform([np.argmax(one_hot[i, :])])[0])
17 return inverse
由于数据集的不平衡性(标记为营业额的员工约占人口的16%,或1,470个案例中的237个),采用上采样技术重复周转案例,因此数据有1,233个案例有营业额,1,233个案例没有周转。
对数据集进行上采样避免了模型每次都学会预测“无周转”的情况;在这种情况下,通过这样做可以达到大约84%的准确度(这个准确度作为基线)。
1# Separate majority and minority classes 2data_empleados_majority = data_empleados[data_empleados.Attrition_Num==0] 3data_empleados_minority = data_empleados[data_empleados.Attrition_Num==1] 4# Upsample minority class 5data_empleados_minority_upsampled = resample(data_empleados_minority, 6 replace=True, # sample with replacement 7 n_samples=len(data_empleados_majority), # to match majority class 8 random_state=123) # reproducible results 9# Combine majority class with upsampled minority class10data_empleados_upsampled = pd.concat([data_empleados_majority, data_empleados_minority_upsampled])11data_empleados_upsampled = data_empleados_upsampled.sample(frac=1)12data_empleados_upsampled.index = range(len(data_empleados_upsampled))13# Display new class counts14data_empleados_upsampled.Attrition.value_counts()# Separate majority and minority classes
2data_empleados_majority = data_empleados[data_empleados.Attrition_Num==0]
3data_empleados_minority = data_empleados[data_empleados.Attrition_Num==1]
4# Upsample minority class
5data_empleados_minority_upsampled = resample(data_empleados_minority,
6 replace=True, # sample with replacement
7 n_samples=len(data_empleados_majority), # to match majority class
8 random_state=123) # reproducible results
9# Combine majority class with upsampled minority class
10data_empleados_upsampled = pd.concat([data_empleados_majority, data_empleados_minority_upsampled])
11data_empleados_upsampled = data_empleados_upsampled.sample(frac=1)
12data_empleados_upsampled.index = range(len(data_empleados_upsampled))
13# Display new class counts
14data_empleados_upsampled.Attrition.value_counts()
接下来,StandardScaler 用于将数据标准化为(-1,1)的范围,以避免异常值以不成比例的方式影响预测。
1class standard_scaler: 2 def __init__(self, name): 3 self.name = name # candidato o empleado 4 self.scalers = {} # asignar cada scaler con el nombre de la columna (ej.'Age') 5 def add_scaler(self, scaler, name): 6 self.scalers[name] = scaler 7# Initialize a standard_scaler class to hold all scalers for future reverse scaling 8scalers_empleados = standard_scaler('empleados') 9def scale_and_generate_scaler(data):10 standard_scaler = StandardScaler()11 scaled = standard_scaler.fit_transform(data.astype('int64').values.reshape(-1, 1))12 return scaled, standard_scaler13def scale_array(scaler, array):14 return scaler.transform([array])15def inverse_scale_array(scaler, array):16 return scaler.inverse_transform([array])17def scale_append(data, scalers, name):18 scaled, scaler = scale_and_generate_scaler(data[name])19 scalers.add_scaler(scaler, name)20 return scaled, scalers21# Select features to scale22var_empleados_num = [23 'Age',24 'BusinessTravel_Num',25 'DistanceFromHome',26 'EnvironmentSatisfaction',27 'JobInvolvement',28 'JobSatisfaction',29 'MonthlyIncome',30 'OverTime_Num',31 'YearsAtCompany',32 'WorkLifeBalance',33 'Education',34 'MaritalStatus_Num',35 'NumCompaniesWorked',36 'RelationshipSatisfaction',37 'TotalWorkingYears'38]39# Scale each feature, save each feature's scaler40for var in var_empleados_num:41 data_empleados_upsampled[var], scalers_empleados = scale_append(data_empleados_upsampled, scalers_empleados, var)class standard_scaler:
2 def __init__(self, name):
3 self.name = name # candidato o empleado
4 self.scalers = {} # asignar cada scaler con el nombre de la columna (ej.'Age')
5 def add_scaler(self, scaler, name):
6 self.scalers[name] = scaler
7# Initialize a standard_scaler class to hold all scalers for future reverse scaling
8scalers_empleados = standard_scaler('empleados')
9def scale_and_generate_scaler(data):
10 standard_scaler = StandardScaler()
11 scaled = standard_scaler.fit_transform(data.astype('int64').values.reshape(-1, 1))
12 return scaled, standard_scaler
13def scale_array(scaler, array):
14 return scaler.transform([array])
15def inverse_scale_array(scaler, array):
16 return scaler.inverse_transform([array])
17def scale_append(data, scalers, name):
18 scaled, scaler = scale_and_generate_scaler(data[name])
19 scalers.add_scaler(scaler, name)
20 return scaled, scalers
21# Select features to scale
22var_empleados_num = [
23 'Age',
24 'BusinessTravel_Num',
25 'DistanceFromHome',
26 'EnvironmentSatisfaction',
27 'JobInvolvement',
28 'JobSatisfaction',
29 'MonthlyIncome',
30 'OverTime_Num',
31 'YearsAtCompany',
32 'WorkLifeBalance',
33 'Education',
34 'MaritalStatus_Num',
35 'NumCompaniesWorked',
36 'RelationshipSatisfaction',
37 'TotalWorkingYears'
38]
39# Scale each feature, save each feature's scaler
40for var in var_empleados_num:
41 data_empleados_upsampled[var], scalers_empleados = scale_append(data_empleados_upsampled, scalers_empleados, var)
准备好数据后,使用随机种子将其随机分成训练数据(80%)和测试数据(20%),以获得可重复性。
1X_train, X_test = train_test_split(data_empleados_upsampled, test_size=0.2, random_state=RANDOM_SEED) 2X_train = data_empleados_upsampled 3y_train = X_train['Attrition_Num'] 4X_train = X_train.drop(['Attrition_Num', 'Attrition', 'BusinessTravel', 'OverTime', 'MaritalStatus', 'YearsAtCompany'], axis=1) 5y_test = X_test['Attrition_Num'] 6X_test = X_test.drop(['Attrition_Num', 'Attrition', 'BusinessTravel', 'OverTime', 'MaritalStatus','YearsAtCompany'], axis=1) 7X_train = X_train.values 8X_test = X_test.values 9# One-Hot encoding10y_train_hot, label_encoder = one_hot_values(y_train)11y_test_hot, label_encoder_test = one_hot_values(y_test)0.2, random_state=RANDOM_SEED)
2X_train = data_empleados_upsampled
3y_train = X_train['Attrition_Num']
4X_train = X_train.drop(['Attrition_Num', 'Attrition', 'BusinessTravel', 'OverTime', 'MaritalStatus', 'YearsAtCompany'], axis=1)
5y_test = X_test['Attrition_Num']
6X_test = X_test.drop(['Attrition_Num', 'Attrition', 'BusinessTravel', 'OverTime', 'MaritalStatus','YearsAtCompany'], axis=1)
7X_train = X_train.values
8X_test = X_test.values
9# One-Hot encoding
10y_train_hot, label_encoder = one_hot_values(y_train)
11y_test_hot, label_encoder_test = one_hot_values(y_test)
然后,使用Keras构建神经网络。其架构如下:
1nb_epoch = 200 2batch_size = 64 3input_d = X_train.shape[1] 4output_d = y_train_hot.shape[1] 5model = Sequential() 6model.add(Dense(512, activation='relu', input_dim=input_d)) 7model.add(Dropout(0.5)) 8model.add(Dense(128, activation='relu', input_dim=input_d)) 9model.add(Dropout(0.5))10model.add(Dense(64, activation='relu'))11model.add(Dropout(0.3))12model.add(Dense(output_d))13model.add(Activation('softmax'))14sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)15rms = 'rmsprop'16model.compile(loss='categorical_crossentropy',17 optimizer=sgd,18 metrics=['accuracy'])200
2batch_size = 64
3input_d = X_train.shape[1]
4output_d = y_train_hot.shape[1]
5model = Sequential()
6model.add(Dense(512, activation='relu', input_dim=input_d))
7model.add(Dropout(0.5))
8model.add(Dense(128, activation='relu', input_dim=input_d))
9model.add(Dropout(0.5))
10model.add(Dense(64, activation='relu'))
11model.add(Dropout(0.3))
12model.add(Dense(output_d))
13model.add(Activation('softmax'))
14sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
15rms = 'rmsprop'
16model.compile(loss='categorical_crossentropy',
17 optimizer=sgd,
18 metrics=['accuracy'])
这是一个简单的三层神经网络,在最后一层有两个神经元,根据用作模型目标的one-hot encoded 消息预测正确的类;no attrition = [0,1] 和attrition = [0,1]磨损。
使用随机梯度下降优化器,学习率为0.01,批量大小为64,损失函数为
categorical_crossentropy。它经过200个阶段的训练,达到了96.15%的验证准确度(与总预测周转率的基线84%相比)。
每个预测的输出是一个大小为2的数组,该数组的元素总和为1.为了提取预测类,采用数组中的最高元素。如果第一个元素较大,则预测的类没有磨损。类似的,如果第二大元素大于第一元素,则预测类具有属性。该函数 inverse_one_hot() 用于从one-hot encoded 模型预测中获得预测类。这是一个例子:
1# Get predictions2preds = model.predict(X_test)3# Reverse the One-Hot encoding4res = [inverse_one_hot(label_encoder_test,np.array([list(preds[i])])) for i in range(len(preds))]# Get predictions
2preds = model.predict(X_test)
3# Reverse the One-Hot encoding
4res = [inverse_one_hot(label_encoder_test,np.array([list(preds[i])])) for i in range(len(preds))]
以下是如何对自定义配置文件执行预测的示例,一个潜在的工作候选人:
1perfil = ['26', '2', '1', '1', '1', '1', '2500', '1', '1', '2', '2', '6', '1', '2'] 2data_vars = [ 3 'Age', 4 'BusinessTravel_Num', 5 'DistanceFromHome', 6 'EnvironmentSatisfaction', 7 'JobInvolvement', 8 'JobSatisfaction', 9 'MonthlyIncome',10 'OverTime_Num',11 'WorkLifeBalance',12 'Education',13 'MaritalStatus_Num',14 'NumCompaniesWorked',15 'RelationshipSatisfaction',16 'TotalWorkingYears']17scaled_input = []18# Note: the scalers_empleados object can be saved with pickle.dump for later use.19for i in range(len(perfil)):20 scaled_input.append(scalers_empleados.scalers[data_vars[i]].transform(perfil[i]))21scaled_input = np.array(scaled_input).flatten().reshape(1,len(data_vars))22pred = model.predict(scaled_input)23res = [inverse_one_hot(label_encoder,np.array([list(pred[i])])) for i in range(len(pred))]24res = np.reshape(res, len(res))25print({'pred':str(res[0])})'26', '2', '1', '1', '1', '1', '2500', '1', '1', '2', '2', '6', '1', '2']
2data_vars = [
3 'Age',
4 'BusinessTravel_Num',
5 'DistanceFromHome',
6 'EnvironmentSatisfaction',
7 'JobInvolvement',
8 'JobSatisfaction',
9 'MonthlyIncome',
10 'OverTime_Num',
11 'WorkLifeBalance',
12 'Education',
13 'MaritalStatus_Num',
14 'NumCompaniesWorked',
15 'RelationshipSatisfaction',
16 'TotalWorkingYears']
17scaled_input = []
18# Note: the scalers_empleados object can be saved with pickle.dump for later use.
19for i in range(len(perfil)):
20 scaled_input.append(scalers_empleados.scalers[data_vars[i]].transform(perfil[i]))
21scaled_input = np.array(scaled_input).flatten().reshape(1,len(data_vars))
22pred = model.predict(scaled_input)
23res = [inverse_one_hot(label_encoder,np.array([list(pred[i])])) for i in range(len(pred))]
24res = np.reshape(res, len(res))
25print({'pred':str(res[0])})
建立了一个类似的神经网络来预测,该变量对应于员工预期的公司中持续的总年数。结构是相同的,除了最后一层,它有五个神经元而不是两个预测0,1,2,4或10年。
这是一个了解模型性能的功能:
1def evaluate_model(model, X_train): 2 preds = model.predict(X_train) 3 y_train_inv = [inverse_one_hot(label_encoder_train,np.array([list(y_train_hot[i])])) for i in range(len(y_train_hot))] 4 #y_train_inv = np.round(scalers_empleados_yac.scalers['YearsAtCompany'].inverse_transform([y_train_inv])) 5 y_train_inv = np.array(y_train_inv).flatten() 6 preds_inv = [inverse_one_hot(label_encoder_train,np.array([list(preds[i])])) for i in range(len(preds))] 7 #preds_inv = scalers_empleados_yac.scalers['YearsAtCompany'].inverse_transform([preds_inv]) 8 preds_inv = np.array(preds_inv).flatten() 9 correct = 010 over = 011 under = 012 errors = []13 for i in range(len(preds_inv)):14 if preds_inv[i] == y_train_inv[i]:15 correct += 116 elif (preds_inv[i]) < (y_train_inv[i]):17 under += 118 elif (preds_inv[i]) > (y_train_inv[i]):19 over += 120 errors.append(((preds_inv[i]) - (y_train_inv[i])))21 print("correct: {}, over {}, under {}, accuracy {}, mse {}".format(correct, over, under, round(correct/len(preds_inv),3), np.round(np.array(np.power(errors,2)).mean(),3)))22 print("errors:",pd.Series(np.array([abs(i) for i in errors if i != 0])).describe())23 print("preds",pd.Series(preds_inv).describe())24 print("y_train",pd.Series(y_train_inv).describe())25 print(pd.Series(preds_inv).value_counts())26 print(pd.Series(y_train_inv).value_counts())27 print(sns.boxplot(np.array([abs(i) for i in errors if i != 0])))28 return y_train_inv, preds_invdef evaluate_model(model, X_train):
2 preds = model.predict(X_train)
3 y_train_inv = [inverse_one_hot(label_encoder_train,np.array([list(y_train_hot[i])])) for i in range(len(y_train_hot))]
4 #y_train_inv = np.round(scalers_empleados_yac.scalers['YearsAtCompany'].inverse_transform([y_train_inv]))
5 y_train_inv = np.array(y_train_inv).flatten()
6 preds_inv = [inverse_one_hot(label_encoder_train,np.array([list(preds[i])])) for i in range(len(preds))]
7 #preds_inv = scalers_empleados_yac.scalers['YearsAtCompany'].inverse_transform([preds_inv])
8 preds_inv = np.array(preds_inv).flatten()
9 correct = 0
10 over = 0
11 under = 0
12 errors = []
13 for i in range(len(preds_inv)):
14 if preds_inv[i] == y_train_inv[i]:
15 correct += 1
16 elif (preds_inv[i]) < (y_train_inv[i]):
17 under += 1
18 elif (preds_inv[i]) > (y_train_inv[i]):
19 over += 1
20 errors.append(((preds_inv[i]) - (y_train_inv[i])))
21 print("correct: {}, over {}, under {}, accuracy {}, mse {}".format(correct, over, under, round(correct/len(preds_inv),3), np.round(np.array(np.power(errors,2)).mean(),3)))
22 print("errors:",pd.Series(np.array([abs(i) for i in errors if i != 0])).describe())
23 print("preds",pd.Series(preds_inv).describe())
24 print("y_train",pd.Series(y_train_inv).describe())
25 print(pd.Series(preds_inv).value_counts())
26 print(pd.Series(y_train_inv).value_counts())
27 print(sns.boxplot(np.array([abs(i) for i in errors if i != 0])))
28 return y_train_inv, preds_inv
执行及结果
设计了一个前端,供用户输入候选人的特征,两个模型都会产生一个结果:首先确定候选人是否有转换风险,然后预测候选人预计将保留多少年的潜力位置。
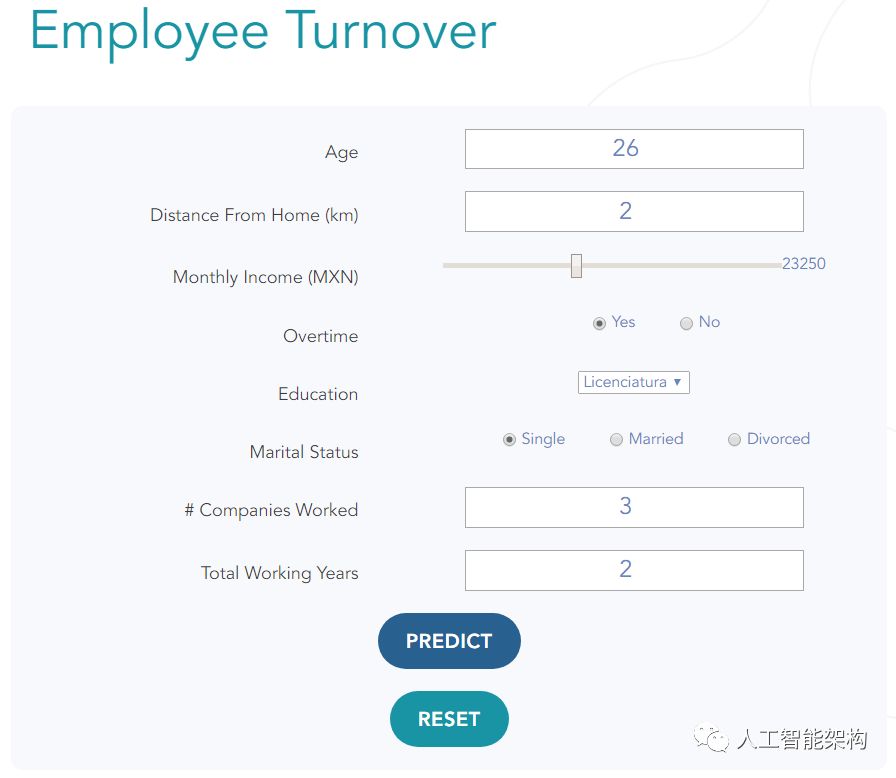
还创建了一个图标,用于将候选人特征的标准化值与数据集中所有员工的平均值进行比较。这用于查看哪些特征与正常值的差异最大。

结论
用来自墨西哥公司的真实数据测试这些模型非常棒。此外,与周转风险具有更高相关性的特征可能因数据集而异,同时,还可以添加其他功能,例如每月杂货和住房费用,以及基于行业和候选人适用的职位的更详细分析。
公司预测的预期年份也可能更具体,特别是前两年。目前,该模型只能预测一年或者另一年,但也许有必要预测几个月而不是几年来使用更多信息来区分候选人。
不过,招聘人员可以从这些工具中获益匪浅,他们可以掌握客观的信息,做出更明智的决策,如果候选人的营业额风险很高,至少可以与候选人直接讨论,以协商双方如何受益。通过这些工具和心得策略来应对,世界各地的公司可以大幅尖山营业额,可能会增加数百万的收入。
长按订阅更多精彩▼















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









