







1.什么是webmagic
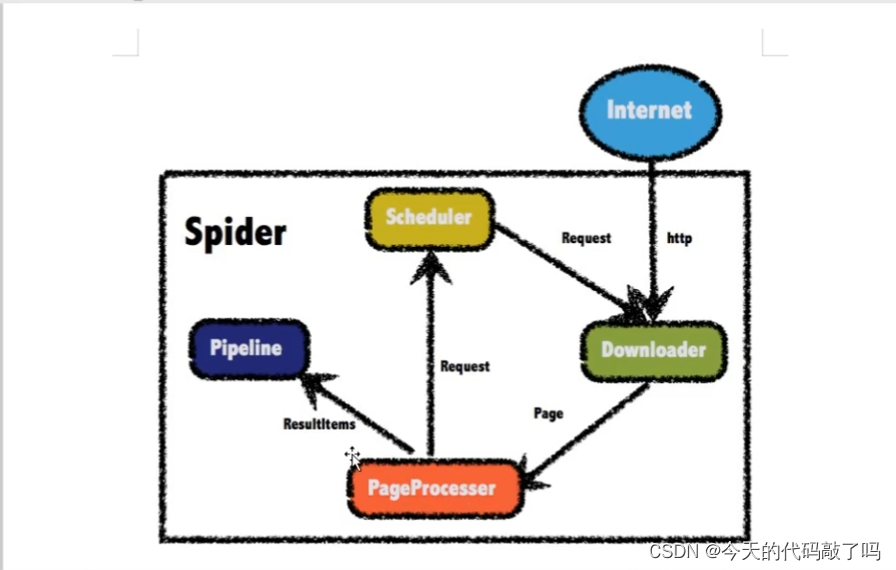
WebMagic是一款开源的Java爬虫框架,旨在简化网络爬虫的开发过程,使开发者更加高效便捷的构建网络爬虫程序。它采用了模块化的设计思想,将爬虫的整个生命周期划分为了四个核心组件:Downloader、PageProcessor、Scheduler、Pipeline。
2.四大核心组件
2.1Downloader下载器组件
负责网页的下载,通常基于HTTP协议与服务器进行交互,获取HTML、JSON或其他类型的数据。他是使用HttpClient实现,如果没有特殊需求不需要自定义,自定义时需要实现Downloader接口。他在给PageProcess传递数据时,将结果封装为Page对象。
Downloader组件负责发起HTTP请求,获取指定URL的内容。WebMagic默认采用Apache HttpClient作为下载器,可以发送GET、POST等请求,接收和处理服务器响应,返回的是网页的原始HTML内容或者其他格式的数据。
2.2PageProcesser页面分析组件
负责处理下载下来的网页内容,解析并提取其中需要的数据,同时定义如何抽取后续要抓取的链接。需要实现PageProcessor接口。
PageProcessor是页面处理接口,用户自定义实现此接口以完成网页内容的解析和数据抽取逻辑。在这个环节,开发者根据网页结构,利用HTML解析库(如Jsoup)来提取感兴趣的数据,并且定义新的URL链接放入Scheduler中等待抓取。
2.3Scheduler访问url组件
管理待抓取URL队列以及已抓取URL集合,控制爬虫的抓取策略,如广度优先、深度优先或自定义顺序抓取。
1.默认使用的内存队列
url数据量大时会占用大量的内存
2.文件形式的队列
需要制定保存队列文档的文件路径和文件名
3.redis分布式队列
实现分布式爬虫时 大规模爬虫时使用
可以通过QueueScheduler自定义设置加入布隆过滤器进行url去重
Scheduler组件用来管理和调度待抓取URL队列。它可以避免重复抓取,按照一定策略决定抓取顺序,比如先入先出(FIFO)、后入先出(LIFO)或根据URL的重要性排序等。
2.4Pipeline数据持久化组件
负责处理抽取结果,将抓取到的数据进行存储或者进一步处理,例如保存到文件、数据库或发送到消息队列中。
Pipeline则负责处理PageProcessor抽取的结果数据,进行持久化存储或其他后期处理操作,例如将数据写入数据库、CSV文件、JSON文件,或者发送到消息队列等目标系统。
3.webmagic工作流程
- 初始化Spider:创建Spider实例,设置初始URL,并注册相应的PageProcessor和其他配置项。
- 抓取循环:- Spider首先从Scheduler中取出一个待抓取的URL。
- Downloader根据该URL发起HTTP请求,获取网页内容并生成一个`ResultItems`对象和对应的`Request`对象。
- PageProcessor处理该`Request`对象,抽取数据并填充到`ResultItems`中,同时可能会发现新的链接并添加到Scheduler中。
- 抽取后的结果通过Pipeline传递出去,进行持久化或其他处理。
- 循环继续,直到Scheduler中的URL被全部抓取完毕,或者达到预设的抓取条件(如抓取数量限制、时间限制等)。
4.什么是Xpath
在WebMagic爬虫框架中,XPath作为一种强大的网页解析工具被广泛应用。XPath是一种在XML文档中查找信息的语言,也可以用于HTML文档,因为它可以视为特殊的XML。在WebMagic中,XPath主要用于定位和抽取网页中的特定元素及其内容。
具体应用步骤包括:
1. 解析HTML:
使用内置或集成的HTML解析器(如Jsoup或结合Xsoup扩展),将下载下来的网页内容转化为结构化的文档对象模型(DOM)。
2. 编写XPath表达式:
根据需要抽取的数据所在的HTML标签位置及属性特征,编写XPath表达式。例如,如果想要选取所有class属性为"match_list"的div元素之后的所有tr元素,可以使用如下XPath表达式:
```xpath
//div[@class="match_list"]/following-sibling::tr
```
3. 执行XPath查询:
在WebMagic中,可以通过Page类提供的方法执行XPath表达式,如`page.getHtml().xpath(xpathExpression)`。这将会返回一个包含匹配节点的集合,通常可以进一步转换为`List<Selectable>`类型,便于迭代和抽取节点的具体内容。
4. 抽取数据:
对于得到的每个匹配节点,可以调用相关方法抽取节点文本、属性值或其他嵌套节点的内容。
5.如何定制各个组件
在WebMagic爬虫框架中,各个核心组件都是可以进行定制的,以满足不同的爬虫需求。以下是各组件的定制方式:
1. Downloader 定制:
WebMagic默认使用了HttpClientDownloader作为下载器,如果你有特殊的需求,如需要使用Selenium进行动态渲染的网页抓取,或者自定义请求头、超时时间等,可以通过实现`Downloader`接口来自定义下载器。例如创建一个新的类继承`AbstractDownloader`,并在其中覆盖对应的方法。
2. PageProcessor 定制:
每个爬虫项目都需要实现`PageProcessor`接口来定义具体的页面处理逻辑。在这个类中,你需要重写`process(Page page, Site site)`方法,编写页面内容解析规则和数据抽取逻辑,并通过`page.addTargetRequests()`方法将新发现的链接加入抓取队列。
3. Scheduler 定制:
WebMagic提供了一些内置的Scheduler实现,如内存队列、Redis队列等。如果需要自定义URL队列管理策略,如优先级队列、带权重的队列等,可以实现`Scheduler`接口。例如创建一个新的类实现`Scheduler`接口,并在其中实现`push(Request request)`、`poll()`等方法。
4. Pipeline定制:
Pipeline负责处理抽取的结果数据,进行存储或其他处理。若需自定义Pipeline,只需创建一个新的类实现`Pipeline`接口,并实现`process(ResultItems resultItems, Task task)`方法,在其中编写数据持久化逻辑,如保存到数据库、文件或发送至远程服务等。
例如,自定义Pipeline的代码示例:
```java
public class MyCustomPipeline implements Pipeline {
@Override
public void process(ResultItems resultItems, Task task) {
// 获取抽取结果
String someData = resultItems.get("someKey");
// 将数据存入数据库
DatabaseService.saveToDatabase(someData);
// 或者写入本地文件
FileUtil.writeFileToFileSystem(someData, "output.txt", true);
}
}
```
然后在启动爬虫时,将自定义的组件注入到Spider中:
```java
Spider.create(new MyPageProcessor())
.setDownloader(customDownloader)
.addPipeline(new MyCustomPipeline())
// 其他配置...
.start();
```
6.常用方法
在WebMagic爬虫框架中,以下是一些常用的方法和概念:
1. **创建Spider**
- `Spider.create()`:创建一个爬虫实例,传入自定义的`PageProcessor`实例以处理每一页的内容。
2. **设置初始URL**
- `addUrl(String url)`:添加起始URL,爬虫会从这些URL开始抓取。
3. **设置PageProcessor**
- `setPageProcessor(PageProcessor pageProcessor)`:设置页面处理器,处理每个抓取到的页面,抽取数据并生成新的请求。
4. **添加Pipeline**
- `addPipeline(Pipeline pipeline)`:添加数据管道,用于处理抽取的结果数据,如将数据持久化到数据库、文件或其他地方。
5. **设置Downloader**
- `setDownloader(Downloader downloader)`:自定义下载器,控制如何下载网页内容,默认使用`HttpClientDownloader`。
6. **设置Scheduler**
- `setScheduler(Scheduler scheduler)`:设置URL管理器,控制抓取队列和避免重复抓取。
7. **启动爬虫**
- `start()`:启动爬虫,开始执行爬取任务。
8. **在PageProcessor中的方法**
- `process(Page page)`:这是必须实现的方法,用来处理每一个抓取到的页面,包括抽取数据和生成新的请求。
- `site.setRetryTimes(int retryTimes)`:设置重试次数,当下载失败时重新尝试。
- `page.addTargetRequest(Request request)`:将新的请求添加到待抓取队列中。
- `page.getHtml()`:获取HTML内容,进而可以使用CSS选择器或XPath等方式进行内容解析。
9. **抽取数据的方法**
- `page.getHtml().css(String selector)` 或 `.xpath(String xpath)`:使用CSS选择器或XPath表达式抽取页面元素。
- `Selectable.xpath(String xpath)` 或 `.css(String selector)`:在抽取到的元素上进一步提取子元素或属性。
10. **Request和ResultItems**
- `Request`:代表一个待抓取的网页请求,包含URL、Method、Header等信息。
- `ResultItems`:存储从页面中抽取的结果数据,可以通过`.putField(key, value)`方法添加抽取结果。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









