







1、背景
Spark作为分布式内存计算框架,可以广泛应用在数据处理、分析等应用场景。因此,希望借助Spark高性能的处理项目中的数据,搭建此开发环境,深入了解Spark的处理能力与实现机制。
2、开发环境
在windows10上使用Anaconda作为Python运行与开发环境,搭建PySpark3.0.1的Python开发环境,并执行PI.py和WordCount.py示例程序。
3、下载Spark和Hadoop安装包
1、前往Spark官网,下载spark-3.0.1-bin-hadoop2.7.tgz安装包
2、前往Hadoop官网,下载与Spark对应的hadoop-2.7.1.tar.gz安装包
3、在网上下载winutils.exe工具,windows下使用Hadoop接口需要依赖winutils.exe
4、PySpark环境搭建
1、安装JDK8
2、解压spark-3.0.1-bin-hadoop2.7.tgz到安装目录,例如D:\install
3、解压hadoop-2.7.1.tar.gz到安装目录,例如D:\install
4、将winutils.exe拷贝到hadoop安装目录下的bin目录中
5、在windows环境变量中,设置环境变量:
| 变量项 | 变量值 |
| HADOOP_HOME | D:\install\hadoop-2.7.1 |
| CLASSPATH | %HADOOP_HOME%\bin\winutils.exe |
| SPARK_HOME | D:\install\spark-3.0.1-bin-hadoop2.7 |
6、打开Anaconda,创建新的环境env_spark,指定Python版本为3.8
7、在env_spark环境中打开CMD窗口,执行pip install pyspark==3.0.1,指定安装PySpark3.0.1版本。
5、执行PySpark示例程序
打开Anaconda,打开Spyder(Python代码IDE),分别执行PI.py和WordCount.py示例。
PI.py代码如下:
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_: int) -> float:
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()
Spyder中执行结果如下:
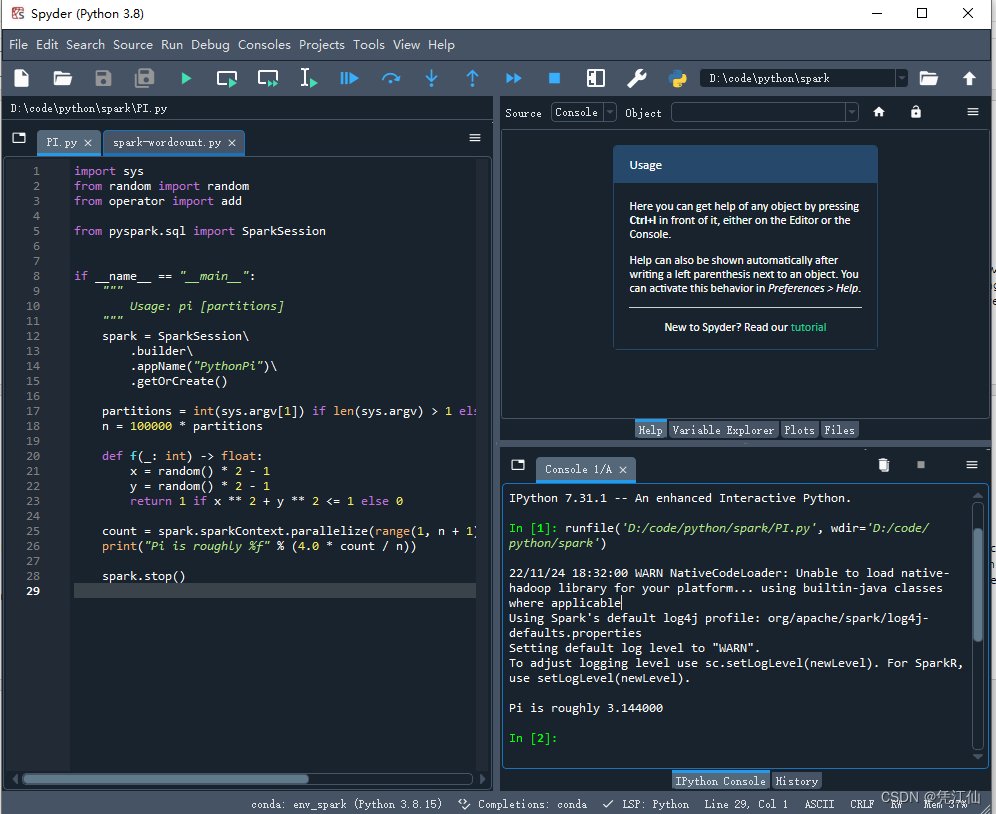
WordCount.py代码如下:
from pyspark.sql import SparkSession
from pyspark import SparkContext
sparksession = SparkSession.builder.appName("SimpleApp").getOrCreate()
sc = sparksession.sparkContext
lines = sc.textFile('D:\install\hadoop-2.7.1\README.txt')
rdd = lines.flatMap(lambda line : line.split(' ')).map(lambda word : (word, 1)).reduceByKey(lambda agg, cur: agg+cur)
print(rdd.collect())
sc.stop()WordCount.py执行结果如下:
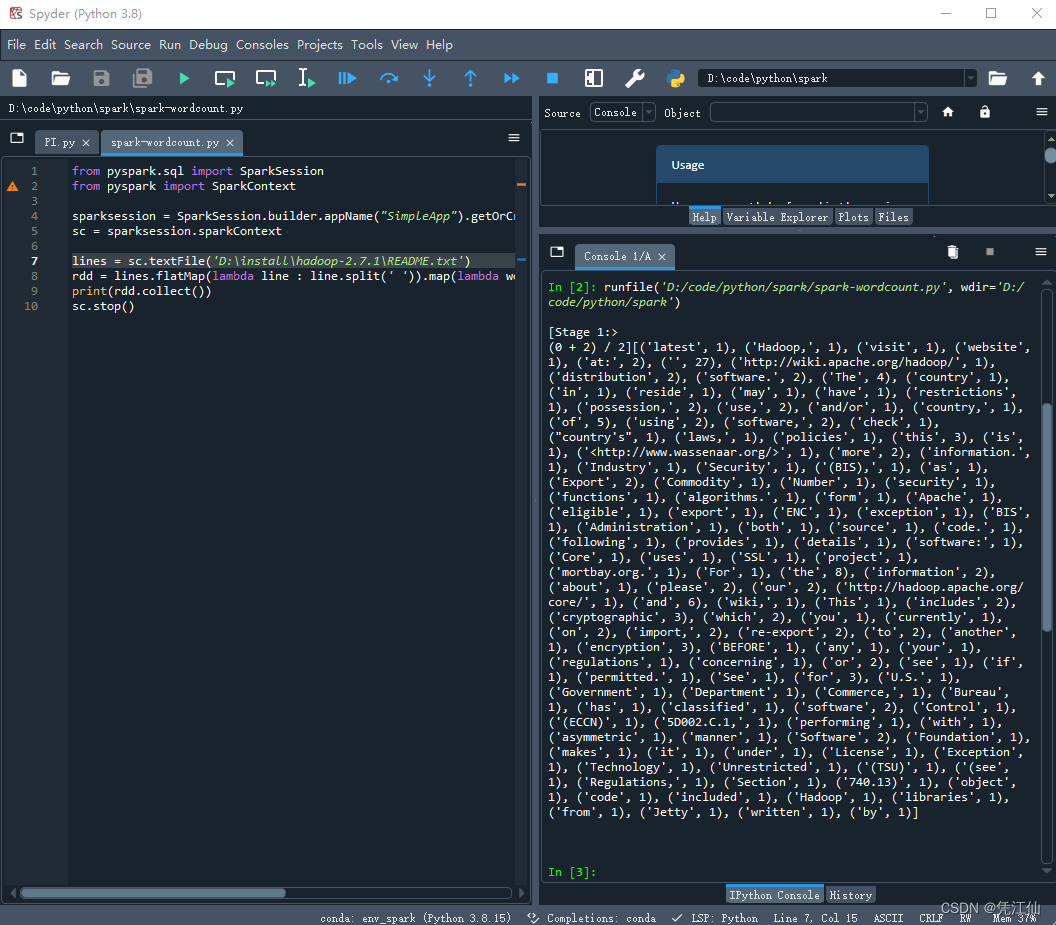
6、注意事项
1、安装高版本的PySpark3.3.1后,执行WordCount.py 时报异常org.apache.spark.SparkException: Python worker failed to connect back。因此使用PySpark3.0.1版本。















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









