






今天咱们来聊一聊GBase8a数据模型和建表方法。
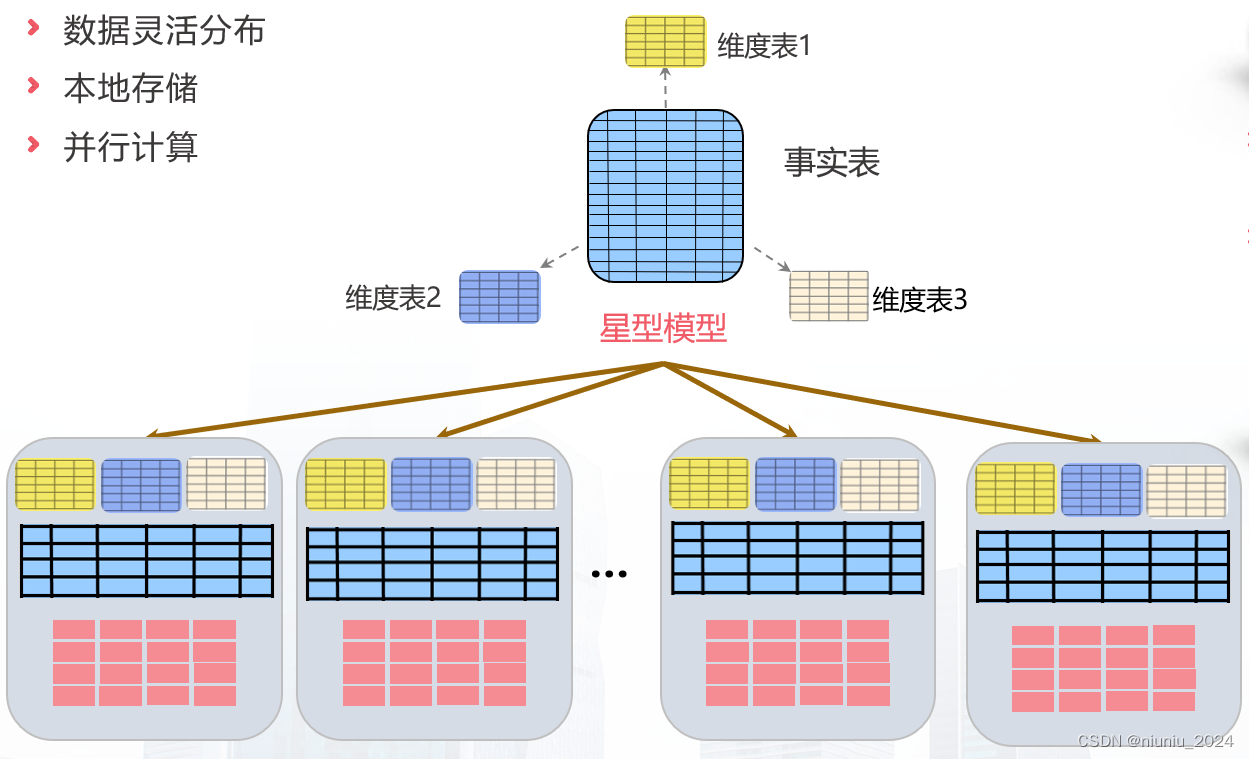
GBase8a作为一款分布式数据库,与传统数据库的最大不同之处在于,并不是由单个数据库实例提供服务,而是由每个节点上的数据库实例共同组成数据库集群,作为一个整体对外提供服务。这就涉及到数据应该如何存储到数据库实例集群的问题,GBase8a的数据模型有3种:复制表、随机分布表、hash分布表。
复制表,即为每个节点上的数据库实例上均存储了这张表的一份完整的数据。
随机分布表,即数据随机、且平均分散在数据库集群的各个实例(节点)上,譬如有node1、node2、node3、node4四个节点,则每个节点存储1/4的数据,计算时,由于无法确定数据应该在哪个节点上,所以调度进程(也就是gcluster)会将任务下发给每个gnode节点去执行。
hash分布表,即数据依据一列或多列进行hash运算后,计算该条数据应该落在哪个节点上,然后进行相应的存储。计算时,基于hash分布列作条件筛选时,可以明确计算出所需数据在哪个gnode节点上,gcluster就会将任务下发给相应的gnode节点执行,不在筛选范围内的gnode节点将不参与运算,避免不必要的资源开销,从而为其他任务提供更充分的计算资源。
数据仓库中通常采用星型或雪花型模型,这两种模型下,均有一些维表,数据量较少,一些事实表,数据量较大。在GBase8a中创建表,建议将维表/小表建为复制表,将事实表/大表建为随机分布表或hash分布表,建表的方法如下:
创建随机分布表
create table <table_name> ();
创建hash分布表
create table <table_name> () DISTRIBUTED BY ('<列名>');
创新建复制表
create table <table_name> () REPLICATED;
如此,您已经了解了GBase8a的数据模型和建表方法,那么如何将数据导入GBase8a呢,且听我下回分解。。。

















 6498
6498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









