







目录
浅记录一下~~~~~有错误的地方希望大家可以指正,共同进步呀!
一、需要引入的包
import html2canvas from 'html2canvas';
import { saveAs } from 'file-saver';
import PizZip from 'pizzip';
import Docxtemplater from 'docxtemplater';
import ImageModule from 'docxtemplater-image-module-free';- html2canvas: 是一个将 HTML 元素截图并转换为图像的 JavaScript 库。其核心功能是将指定的HTML元素渲染为一个可用于下载或展示的图像(通常为PNG格式)。当需要将网页中的某些部分以图像形式保存或展示时使用。使用 canvas 技术来绘制和导出图像。支持自定义分辨率和图像格式。适用于前端项目,无需依赖服务器。支持大多数 HTML 和 CSS 特性。能够处理动态内容。
- saveAs:saveAs是一个函数,专门用于在浏览器中保存文件。它允许用户通过前端生成或处理的文件,在客户端直接触发下载。核心功能是提供文件下载功能,解决不同浏览器对文件下载操作的兼容性问题。file-saver可以用来保存 Blob 文件:当前端生成了二进制文件(Blob),需要触发文件下载时使用;支持多种格式的文件下载:可以下载文本、图片、音频、视频等多种格式的文件;可跨浏览器兼容性:解决了不同浏览器(如 Chrome、Firefox、IE 等)对文件下载操作的兼容问题。
- pizzip:PizZip是一个JavaScript库,用于处理ZIP文件(读取、解压、操作和重新压缩)。核心功能:解压和读取ZIP文件内容;创建和修改ZIP文件;与其他工具(如docxtemplater)结合,操作基于ZIP格式的文档(如DOCX、PPTX)。
- docxtemplater:Docxtemplater 是一个 JavaScript 库,用于操作 Microsoft Word 文档(DOCX 文件),通过模板引擎替换变量或动态生成内容。核心功能:模板化文档生成:通过在 DOCX 模板文件中设置占位符(如 {name}),结合数据填充功能生成个性化文档。文档内容替换:动态修改 Word 文档中的文本、表格、图片等内容。与 ZIP 文件操作库结合:与 PizZip 搭配使用,解压和操作 DOCX 文件(DOCX 本质上是一个 ZIP 包含多种文件)。
- ImageModule:在使用 docxtemplater 库处理 Word 文档模板时,ImageModule是一个附加模块,它是
docxtemplater-image-module-free提供的一个功能模块,用于在生成的 Word 文档中插入图片。这是一个 "插件" 式的功能扩展。通过 ImageModule,你可以指定图片的来源(如 Base64 编码、URL、文件路径等)以及图片的大小和布局。原始的 docxtemplater 库只支持文本的动态填充。如果需要插入图片,就需要额外安装并配置 ImageModule。docxtemplater-image-module-free这是一个 npm 包的名称,它是docxtemplater的一个插件模块。核心功能允许将图片动态插入到 Word 模板中。适用配合docxtemplater使用,基于模板生成包含图片的 Word 文档。
二、具体实现代码
1、主程序代码
export async function ScreenShot(elID: string) {
const element = document.getElementById(elID);
if (!element) {
console.error('Element not found!');
return;
}
try {
// 使用 html2canvas 截取元素并生成 Canvas
const canvas = await html2canvas(element, {
useCORS: true,
scale: window.devicePixelRatio < 3 ? window.devicePixelRatio : 2,
allowTaint: true,
});
// 将 Canvas 转换为 Base64 图片
const imageBase64 = canvas.toDataURL('image/png');
const imageblob = canvas.toBlob(function () { }, 'image/png')
// 加载 Word 模板文件
const response = await fetch('/template.docx'); // 模板路径
const arrayBuffer = await response.arrayBuffer();
// 使用 PizZip 解压模板
const zip = new PizZip(arrayBuffer);
const imageOptions = {
getImage(tagValue: any) {
return base64Parser(tagValue);
},
getSize(img: any, tagValue: any, tagName: any, context: any) {
return [400, 240];
},
centered: true,
};
const doc = new Docxtemplater(zip, {
modules: [new ImageModule(imageOptions)],
});
// 渲染模板
doc.render({
image: imageBase64, // 仅保留 Base64 数据部分
});
// 生成 Word 文件并下载
const out = doc.getZip().generate({
type: 'blob',
mimeType:
'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
});
saveAs(out, 'screenshot.docx');
} catch (error) {
console.error('Error generating Word document:', error);
}
}这段代码实现了一个截图功能,将 HTML 页面中的某个元素(由 elID 指定)截图并保存到Word文档中。具体步骤包括:
- 使用 html2canvas 将指定 HTML 元素转换为图片。
- 加载Word模板文件(template.docx)。
- 使用 docxtemplater 和 docxtemplater-image-module-free 插件将图片插入 Word 文档模板中。生成新的 Word 文件,并允许用户下载。
接下来进行拆解主程序代码,详细说明每一段代码实现的意义:
(1)函数的定义和参数:
定义一个异步函数ScreenShot,接受一个参数elID(要截图的HTML元素的 ID)。首先通过document.getElementById获取指定的DOM元素。如果找不到目标元素,打印错误并终止函数。
export async function ScreenShot(elID: string) {
const element = document.getElementById(elID);
if (!element) {
console.error('Element not found!');
return;
}(2)使用htmlcanvas截图:
html2canvas将 HTML 元素渲染为 Canvas 图像。useCORS: true:启用跨域支持,允许加载跨域的图片资源。scale: window.devicePixelRatio < 3 ? window.devicePixelRatio : 2:根据设备像素比调整图像分辨率,限制最大缩放比为2。allowTaint: true:允许跨域图片资源渲染到 Canvas(潜在安全问题)。输出一个Canvas 对象包含 HTML 元素的渲染结果。
const canvas = await html2canvas(element, {
useCORS: true,
scale: window.devicePixelRatio < 3 ? window.devicePixelRatio : 2,
allowTaint: true,
});(3)获取图片的 Base64数据和Blob:
toDataURL:将 Canvas 转换为 Base64 编码的 PNG 图片。用于将图片数据以文本形式嵌入到 Word 文档。toBlob:将 Canvas 转换为二进制 Blob 对象。可以用作图片文件保存或进一步操作。
const imageBase64 = canvas.toDataURL('image/png');
const imageblob = canvas.toBlob(function () { }, 'image/png');(4)加载Word模板:
通过 fetch 请求加载 Word 模板文件。.docx 是 Word 文档的文件格式,本质上是一个 ZIP 文件。将响应转换为 arrayBuffer(字节数组),用于后续操作。(这里的template.docx是自己预先创建的文档,需要将该文档放在public根目录下,文档里需要写入图片的占位符{%image})
const response = await fetch('/template.docx');
const arrayBuffer = await response.arrayBuffer();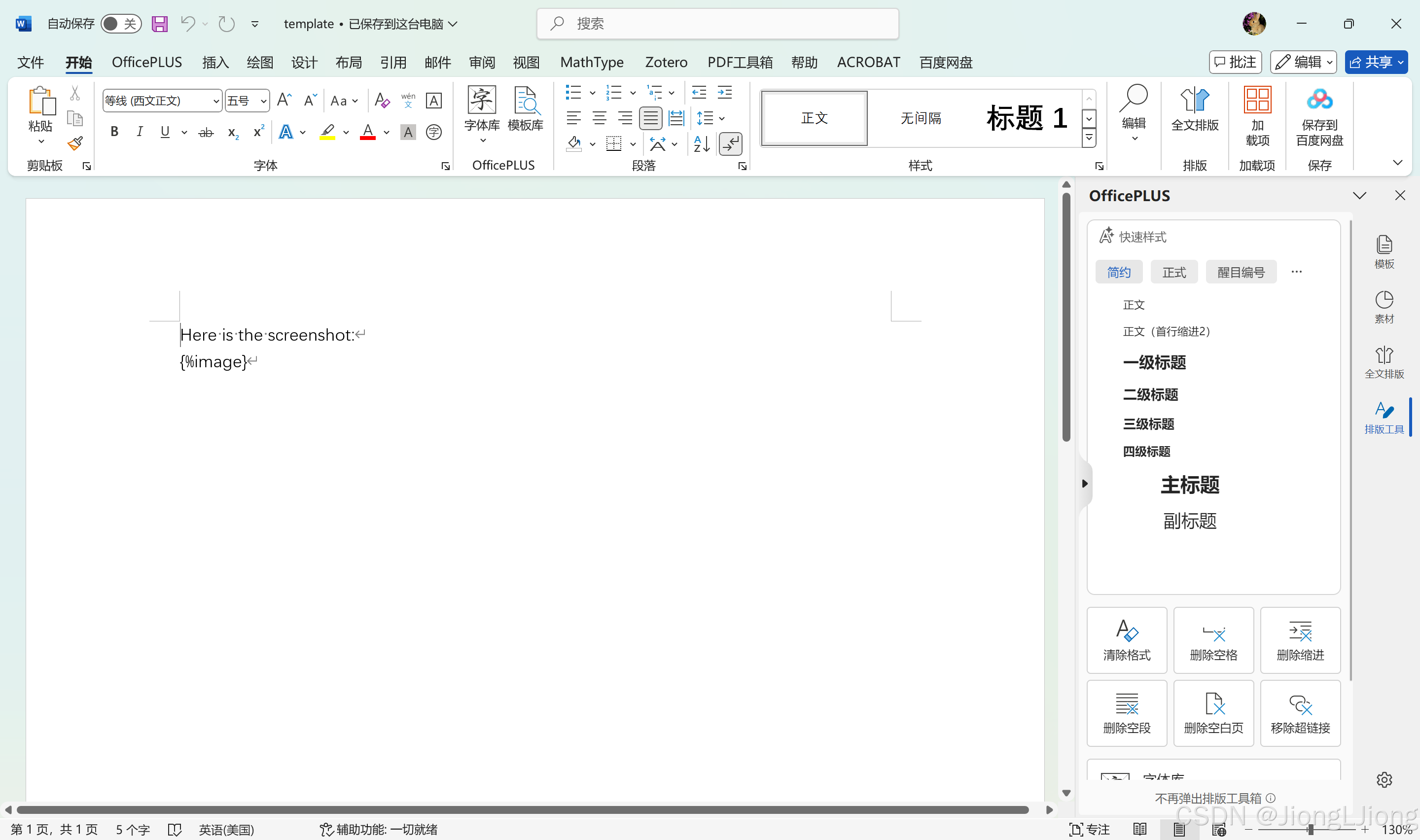
(5)解压模板文件:
PizZip 是一个 ZIP 文件处理库,用于解压和操作 Word 模板。arrayBuffer 是模板文件的字节内容。解压后的 ZIP 文件结构,供 Docxtemplater 使用。
const zip = new PizZip(arrayBuffer);
(6)配置图片模板:
getImage:定义如何解析模板中的图片占位符数据。调用 base64Parser(自定义函数,后续会提到)解析 Base64 数据。getSize:定义图片尺寸。这里固定为宽 400px,高 240px。centered:指定图片在 Word 文档中的对齐方式,设置为居中。
const imageOptions = {
getImage(tagValue: any) {
return base64Parser(tagValue);
},
getSize(img: any, tagValue: any, tagName: any, context: any) {
return [400, 240];
},
centered: true,
};
(7)渲染模板:
Docxtemplater 是一个模板引擎,用于动态填充 Word 文档。ImageModule 插件支持插入图片到 Word 模板。将 imageBase64(截图的 Base64 数据)绑定到模板中的图片占位符。
const doc = new Docxtemplater(zip, {
modules: [new ImageModule(imageOptions)],
});
doc.render({
image: imageBase64,
});
(8)生成并下载Word文件:
type: 'blob':指定输出文件类型为二进制 Blob。mimeType:指定文件为 Word 文档(docx 格式)。使用 file-saver 库的 saveAs 方法将生成的 Word 文件提供给用户下载,文件名为 screenshot.docx。
const out = doc.getZip().generate({
type: 'blob',
mimeType:
'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
});
saveAs(out, 'screenshot.docx');
(9)错误处理:
捕获并处理任何可能在截图、模板渲染或文件生成过程中发生的错误。保障代码在异常情况下不会崩溃,并提供调试信息。
catch (error) {
console.error('Error generating Word document:', error);
}
2、相关函数代码
const base64Regex =
/^(?:data:)?image\/(png|jpg|jpeg|svg|svg\+xml);base64,/;
const validBase64 =
/^(?:[A-Za-z0-9+/]{4})*(?:[A-Za-z0-9+/]{2}==|[A-Za-z0-9+/]{3}=)?$/;
function base64Parser(tagValue: any) {
if (
typeof tagValue !== "string" ||
!base64Regex.test(tagValue)
) {
return false;
}
const stringBase64 = tagValue.replace(base64Regex, "");
if (!validBase64.test(stringBase64)) {
throw new Error(
"Error parsing base64 data, your data contains invalid characters"
);
}
// For nodejs, return a Buffer
if (typeof Buffer !== "undefined" && Buffer.from) {
return Buffer.from(stringBase64, "base64");
}
// For browsers, return a string (of binary content) :
const binaryString = window.atob(stringBase64);
const len = binaryString.length;
const bytes = new Uint8Array(len);
for (let i = 0; i < len; i++) {
const ascii = binaryString.charCodeAt(i);
bytes[i] = ascii;
}
return bytes.buffer;
}这段代码定义了一个函数 base64Parser,用于解析和验证 Base64 格式的图片数据。
它主要完成以下任务:
1、检查输入数据是否是有效的 Base64 图片数据。
2、解析并将 Base64 数据转换为适合运行环境的格式:
(1)在 Node.js 环境下,返回 Buffer 对象。
(2)在浏览器环境下,返回 ArrayBuffer(二进制内容)。
下面将对相关函数代码进行逐步解析,以便读者理解。
(1)正则表达式定义:
base64Regex: 匹配 Base64 图片数据的前缀部分,确保数据格式正确。结构解析:(?:data:)?:可选的 data: 前缀。image\/(png|jpg|jpeg|svg|svg\+xml):匹配常见的图片 MIME 类型,包括 png、jpg、jpeg 和 svg。;base64,:固定部分,表示后续内容是 Base64 编码数据。
const base64Regex =
/^(?:data:)?image\/(png|jpg|jpeg|svg|svg\+xml);base64,/;
validBase64: 匹配纯 Base64 数据(即编码内容部分)。[A-Za-z0-9+/]{4}:每组 4 个字符,由字母、数字和 + 或 / 组成。末尾部分允许补齐字符:{2}==:2 个有效字符,后跟 2 个 =。{3}=:3 个有效字符,后跟 1 个 =。
const validBase64 =
/^(?:[A-Za-z0-9+/]{4})*(?:[A-Za-z0-9+/]{2}==|[A-Za-z0-9+/]{3}=)?$/;
(2)函数主体:
(a)验证输入数据是否为字符串,并且符合 Base64 图片数据的格式。条件 1:tagValue 必须是字符串。条件 2:tagValue 必须匹配 base64Regex。如果不符合上述条件,返回 false,表示数据无效。
function base64Parser(tagValue: any) {
if (
typeof tagValue !== "string" ||
!base64Regex.test(tagValue)
) {
return false;
}
(b)将 Base64 数据的前缀部分移除,仅保留纯 Base64 编码内容。
示例:
输入:data:image/png;base64,ABC123...
输出:ABC123...
const stringBase64 = tagValue.replace(base64Regex, "");(c)检查提取的base64数据是否有效格式,使用validbase64正则表达式验证纯base64数据。如果不匹配,抛出错误,提示数据包含无效字符。
if (!validBase64.test(stringBase64)) {
throw new Error(
"Error parsing base64 data, your data contains invalid characters"
);
}
(3)数据解析:
(a)在node.js的环境下,将base64数据解析为Buffer,仅当全局buffer对象存在,并且支持Buffer.from方法时执行,Buffer对象,适合在服务器端处理二进制数据。
if (typeof Buffer !== "undefined" && Buffer.from) {
return Buffer.from(stringBase64, "base64");
}
(b)在浏览器环境下,将base64数据解析为ArrayBuffer。使用window.atob解码八涩数据为二进制字符串。创建Unit8Array,逐字节填充二进制数据。binaryString.charCodeAt(i): 获取字符的ASCII码值。返回Unit8Array.buffer,即ArrayBuffer对象。
const binaryString = window.atob(stringBase64);
const len = binaryString.length;
const bytes = new Uint8Array(len);
for (let i = 0; i < len; i++) {
const ascii = binaryString.charCodeAt(i);
bytes[i] = ascii;
}
return bytes.buffer;
三、存在的一些问题(还能在继续优化)
- 图片尺寸调整:动态计算图片尺寸以适配模板占位符。
- 错误提示友好化:在 UI 层提示用户错误信息,而非仅打印到控制台。
- 模板路径动态化:允许用户选择模板文件,而非硬编码路径。
- 错误提示优化:如果
base64Regex不匹配,明确指出格式问题。提供示例说明正确的 Base64 图片数据格式。 - 性能提升:在浏览器环境下,考虑使用更高效的
TextDecoder替代window.atob。 - 兼容性增强:如果目标环境是浏览器,考虑移除
Node.js部分的代码,减少代码体积。
四、完整代码
import html2canvas from 'html2canvas';
import { saveAs } from 'file-saver';
import PizZip from 'pizzip';
import Docxtemplater from 'docxtemplater';
import ImageModule from 'docxtemplater-image-module-free';
export async function ScreenShot(elID: string) {
const element = document.getElementById(elID);
if (!element) {
console.error('Element not found!');
return;
}
try {
// 使用 html2canvas 截取元素并生成 Canvas
const canvas = await html2canvas(element, {
useCORS: true,
scale: window.devicePixelRatio < 3 ? window.devicePixelRatio : 2,
allowTaint: true,
});
// 将 Canvas 转换为 Base64 图片
const imageBase64 = canvas.toDataURL('image/png');
const imageblob = canvas.toBlob(function () { }, 'image/png')
// 加载 Word 模板文件
const response = await fetch('/template.docx'); // 模板路径
const arrayBuffer = await response.arrayBuffer();
// 使用 PizZip 解压模板
const zip = new PizZip(arrayBuffer);
const imageOptions = {
getImage(tagValue: any) {
return base64Parser(tagValue);
},
getSize(img: any, tagValue: any, tagName: any, context: any) {
return [400, 240];
},
centered: true,
};
const doc = new Docxtemplater(zip, {
modules: [new ImageModule(imageOptions)],
});
// 渲染模板
doc.render({
image: imageBase64, // 仅保留 Base64 数据部分
});
// 生成 Word 文件并下载
const out = doc.getZip().generate({
type: 'blob',
mimeType:
'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
});
saveAs(out, 'screenshot.docx');
} catch (error) {
console.error('Error generating Word document:', error);
}
}
const base64Regex =
/^(?:data:)?image\/(png|jpg|jpeg|svg|svg\+xml);base64,/;
const validBase64 =
/^(?:[A-Za-z0-9+/]{4})*(?:[A-Za-z0-9+/]{2}==|[A-Za-z0-9+/]{3}=)?$/;
function base64Parser(tagValue: any) {
if (
typeof tagValue !== "string" ||
!base64Regex.test(tagValue)
) {
return false;
}
const stringBase64 = tagValue.replace(base64Regex, "");
if (!validBase64.test(stringBase64)) {
throw new Error(
"Error parsing base64 data, your data contains invalid characters"
);
}
// For nodejs, return a Buffer
if (typeof Buffer !== "undefined" && Buffer.from) {
return Buffer.from(stringBase64, "base64");
}
// For browsers, return a string (of binary content) :
const binaryString = window.atob(stringBase64);
const len = binaryString.length;
const bytes = new Uint8Array(len);
for (let i = 0; i < len; i++) {
const ascii = binaryString.charCodeAt(i);
bytes[i] = ascii;
}
return bytes.buffer;
}参考网址:Image module | docxtemplater

















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









