










之前介绍了我在Ubuntu下组合虚拟机Centos6.4搭建hadoop2.7.2集群,为了做mapreduce开发,要使用eclipse,并且需要对应的hadoop插件hadoop-eclipse-plugin-2.7.2.jar,首先说明一下,在hadoop1.x之前官方hadoop安装包中都自带有eclipse的插件,而如今随着程序员的开发工具eclipse版本的增多和差异,hadoop插件也必须要和开发工具匹配,hadoop的插件包也不可能全部兼容.为了简化,如今的hadoop安装包内不会含有eclipse的插件.需要各自根据自己的eclipse自行编译.
使用ant制作自己的eclipse插件,介绍一下我的环境和工具
Ubuntu 14.04,(系统不重要Win也可以,方法都一样)ide工具eclipse-jee-mars-2-linux-gtk-x86_64.tar.gz

ant(这个也随意,二进制安装或者apt-get安装都可以,配置好环境变量)
export ANT_HOME=/usr/local/ant/apache-ant-1.9.7
export PATH=$PATH:$ANT_HOME/bin
如果提示找不到ant的launcher.ja包,添加环境变量
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/toos.jar:$ANT_HOME/lib/ant-launcher.jar
hadoop@hadoop:~$ ant -version
Apache Ant(TM) version 1.9.7 compiled on April 9 2016
https://github.com/winghc/hadoop2x-eclipse-plugin
以zip格式下载,然后解压到一个合适的路径下.注意路径的权限和目录所有者是当前用户下的
三个编译工具和资源的路径如下
hadoop@hadoop:~$ cd hadoop2x-eclipse-plugin-master
hadoop@hadoop:hadoop2x-eclipse-plugin-master$ pwd
/home/hadoop/hadoop2x-eclipse-plugin-master
hadoop@hadoop:hadoop2x-eclipse-plugin-master$ cd /opt/software/hadoop-2.7.2
hadoop@hadoop:hadoop-2.7.2$ pwd
/opt/software/hadoop-2.7.2
hadoop@hadoop:hadoop-2.7.2$ cd /home/hadoop/eclipse/
hadoop@hadoop:eclipse$ pwd
/home/hadoop/eclipse
根据github说明部分:如何制作,按照操作进行ant
解压下载过来的hadoop2x-eclipse-plugin,进入其中目录hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin/执行操作
How to build
[hdpusr@demo hadoop2x-eclipse-plugin]$ cd src/contrib/eclipse-plugin
# Assume hadoop installation directory is /usr/share/hadoop
[hdpusr@apclt eclipse-plugin]$ ant jar -Dversion=2.4.1 -Dhadoop.version=2.4.1 -Declipse.home=/opt/eclipse -Dhadoop.home=/usr/share/hadoop
final jar will be generated at directory
${hadoop2x-eclipse-plugin}/build/contrib/eclipse-plugin/hadoop-eclipse-plugin-2.4.1.jar但是此时我需要的是2.7.2的eclilpse插件,而github下载过来的hadoop2x-eclipse-plugin配置是hadoop2.6的编译环境,所以执行ant之前需要需要修改ant的build.xml配置文件以及相关文件
第一个文件: hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin/build.xml
在第83行 找到 <target name="jar" depends="compile" unless="skip.contrib">标签,添加和修改copy子标签标签一下内容
也就是127行下面
<copy file="${hadoop.home}/share/hadoop/common/lib/htrace-core-${htrace.version}-incubating.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/servlet-api-${servlet-api.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-io-${commons-io.version}.jar" todir="${build.dir}/lib" verbose="true"/>然后找到标签<attribute name="Bundle-ClassPath"在齐总的value的列表中对应的添加和修改lib,如下
lib/servlet-api-${servlet-api.version}.jar,
lib/commons-io-${commons-io.version}.jar,
lib/htrace-core-${htrace.version}-incubating.jar"/>保存退出.注意如果不修改这个,即便你编译完成jar包,放到eclipse中,配置链接会报错的
但是只是添加和修改这些lib是不行的,hadoop2.6到hadoop2.7中share/home/common/lib/下的jar版本都是有很多不同的,因此还需要修改相应的jar版本..这个耗费了我半天的时间啊.一个个的对号修改.
注意这个版本的环境配置文件在hadoop2x-eclipse-plugin-master跟目录的ivy目录下,也就hihadoop2x-eclipse-plugin-master/ivy/libraries.properties中
最终修改如下所示

为了方便大家,我复制过来,#覆盖的就是原来的配置
hadoop.version=2.7.2
hadoop-gpl-compression.version=0.1.0
#These are the versions of our dependencies (in alphabetical order)
apacheant.version=1.7.0
ant-task.version=2.0.10
asm.version=3.2
aspectj.version=1.6.5
aspectj.version=1.6.11
checkstyle.version=4.2
commons-cli.version=1.2
commons-codec.version=1.4
# commons-collections.version=3.2.1
commons-collections.version=3.2.2
commons-configuration.version=1.6
commons-daemon.version=1.0.13
# commons-httpclient.version=3.0.1
commons-httpclient.version=3.1
commons-lang.version=2.6
# commons-logging.version=1.0.4
commons-logging.version=1.1.3
# commons-logging-api.version=1.0.4
commons-logging-api.version=1.1.3
# commons-math.version=2.1
commons-math.version=3.1.1
commons-el.version=1.0
commons-fileupload.version=1.2
# commons-io.version=2.1
commons-io.version=2.4
commons-net.version=3.1
core.version=3.1.1
coreplugin.version=1.3.2
# hsqldb.version=1.8.0.10
# htrace.version=3.0.4
hsqldb.version=2.0.0
htrace.version=3.1.0
ivy.version=2.1.0
jasper.version=5.5.12
jackson.version=1.9.13
#not able to figureout the version of jsp & jsp-api version to get it resolved throught ivy
# but still declared here as we are going to have a local copy from the lib folder
jsp.version=2.1
jsp-api.version=5.5.12
jsp-api-2.1.version=6.1.14
jsp-2.1.version=6.1.14
# jets3t.version=0.6.1
jets3t.version=0.9.0
jetty.version=6.1.26
jetty-util.version=6.1.26
# jersey-core.version=1.8
# jersey-json.version=1.8
# jersey-server.version=1.8
jersey-core.version=1.9
jersey-json.version=1.9
jersey-server.version=1.9
# junit.version=4.5
junit.version=4.11
jdeb.version=0.8
jdiff.version=1.0.9
json.version=1.0
kfs.version=0.1
log4j.version=1.2.17
lucene-core.version=2.3.1
mockito-all.version=1.8.5
jsch.version=0.1.42
oro.version=2.0.8
rats-lib.version=0.5.1
servlet.version=4.0.6
servlet-api.version=2.5
# slf4j-api.version=1.7.5
# slf4j-log4j12.version=1.7.5
slf4j-api.version=1.7.10
slf4j-log4j12.version=1.7.10
wagon-http.version=1.0-beta-2
xmlenc.version=0.52
# xerces.version=1.4.4
xerces.version=2.9.1
protobuf.version=2.5.0
guava.version=11.0.2
netty.version=3.6.2.Final
进入src/contrib/eclipse-plugin/执行ant命令,如下
hadoop@hadoop:hadoop2x-eclipse-plugin-master$ cd src/contrib/eclipse-plugin/
hadoop@hadoop:eclipse-plugin$ ls
build.properties build.xml.bak ivy.xml META-INF resources
build.xml ivy makePlus.sh plugin.xml src
hadoop@hadoop:eclipse-plugin$ ant jar -Dhadoop.version=2.7.2 -Declipse.home=/home/hadoop/eclipse -Dhadoop.home=/opt/software/hadoop-2.7.2
当最终显示如下,就表示ant制作成功
compile:
[echo] contrib: eclipse-plugin
[javac] /home/hadoop/hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin/build.xml:76: warning: 'includeantruntime' was not set, defaulting to build.sysclasspath=last; set to false for repeatable builds
jar:
[jar] Building jar: /home/hadoop/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin/hadoop-eclipse-plugin-2.7.2.jar
BUILD SUCCESSFUL
Total time: 4 seconds
hadoop@hadoop:eclipse-plugin$ 然后重启eclipse或者shell命令行刷新eclipse如下,同时也可以在shell中显示eclipse的运行过程,以及出错后及时发现原因
hadoop@hadoop:eclipse-plugin$ cp /home/hadoop/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin/hadoop-eclipse-plugin-2.7.2.jar /home/hadoop/eclipse/plugins/
hadoop@hadoop:eclipse-plugin$ /home/hadoop/eclipse/eclipse -clean


打开MR Locations窗口,出现了亲切的大象图标,然后选择添加一个M/R配置,并且配置如下
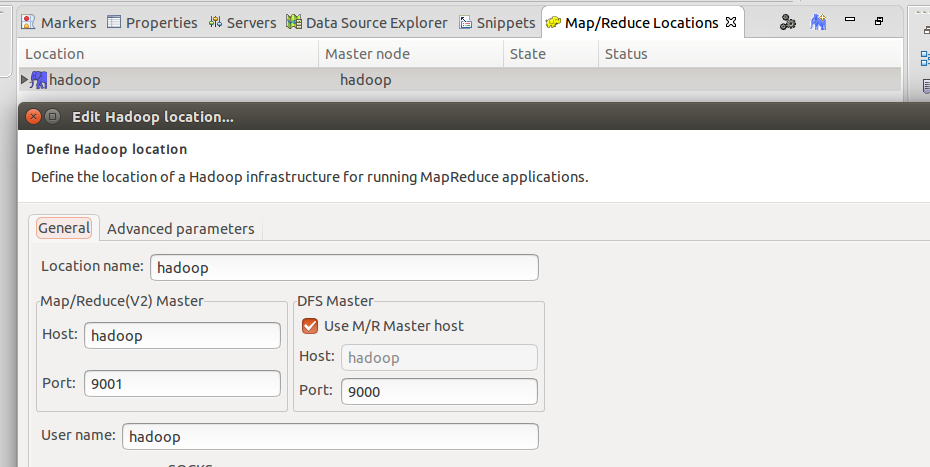
当然这里的Location name随便填,然后是Map/Reduce的Master这里要和你自己配置的hadoop集群或者为分布式的core-site.xml和mapred-sitexml文件一一对应,配置错了就会显示链接失败
我的配置如下,所以Host为hadoop(主节点名称),这个也可以写自己的配置主节点的ip地址,端口号分别是9000(文件系统的主机端口号)和9001(Mapreduce的管理节点joptracker主机端口号)

然后启动hadoop集群,在shell中简单测试一下然后通过eclipse的DFS Locations进行文件传输测试,以及使用FileSystem接口编程和MapReduce的API编程测试,这里只是为了验证这个插件是否可用,hdfs自己测试一下,很简单,这里测试一个mr程序.电话统计,格式如下,左边是拨打电话,右面是被打电话,统计被打的电话次数排名,并显示拨打者
11500001211 10086
11500001212 10010
15500001213 110
15500001214 120
11500001211 10010
11500001212 10010
15500001213 10086
15500001214 110package hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MR extends Configured implements Tool {
enum Counter{
LINESKIP,
}
public static class WCMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
try {
String[] lineSplit = line.split(" ");
String anum = lineSplit[0];
String bnum = lineSplit[1];
context.write(new Text(bnum), new Text(anum));
} catch (Exception e) {
context.getCounter(Counter.LINESKIP).increment(1);//出错计数器+1
return;
}
}
}
public static class IntSumReduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
String valueString;
String out="";
for(Text value: values){
valueString = value.toString();
out+=valueString+"|";
}
context.write(key, new Text(out));
}
}
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] strs = new GenericOptionsParser(conf, args).getRemainingArgs();
Job job = parseInputAndOutput(this, conf, args);
job.setJarByClass(MR.class);
FileInputFormat.addInputPath(job, new Path(strs[0]));
FileOutputFormat.setOutputPath(job, new Path(strs[1]));
job.setMapperClass(WCMapper.class);
job.setInputFormatClass(TextInputFormat.class);
//job.setCombinerClass(IntSumReduce.class);
job.setReducerClass(IntSumReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public Job parseInputAndOutput(Tool tool, Configuration conf, String[] args) throws Exception {
// validate
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output> \n");
return null;
}
// step 2:create job
Job job = Job.getInstance(conf, tool.getClass().getSimpleName());
return job;
}
public static void main(String[] args) throws Exception {
// run map reduce
int status = ToolRunner.run(new MR(), args);
// step 5 exit
System.exit(status);
}
}hadoop@hadoop:~$ hdfs dfs -mkdir -p /user/hadoop/mr/wc/input
hadoop@hadoop:~$ hdfs dfs -put top.data /user/hadoop/mr/wc/input
在eclipse中进行运行mr程序

执行成功,在eclipse控制台输出执行步骤,查看执行结果
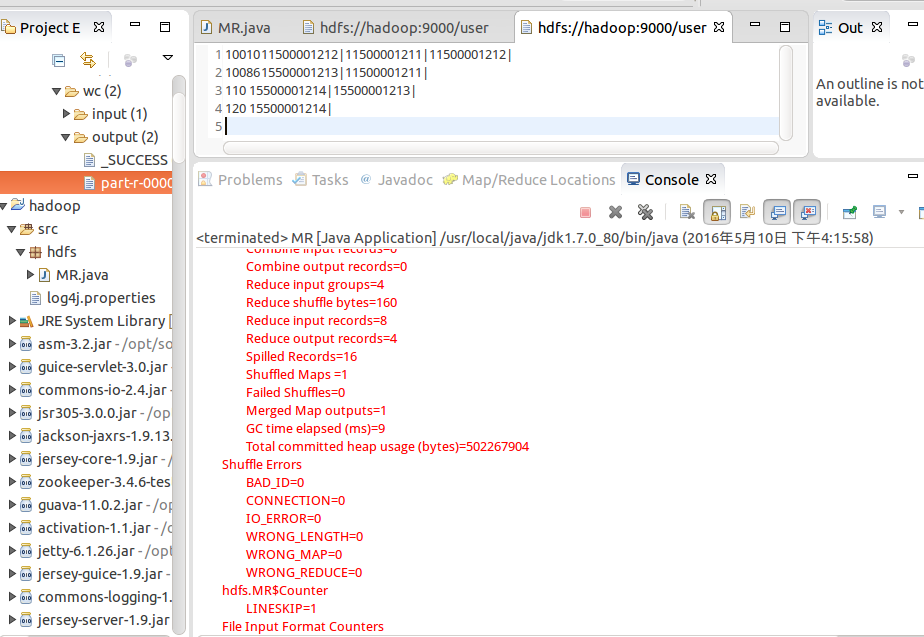
说明插件没有任何问题














 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









