






引言
为什么要梳理服务之间的强弱依赖,有哪些作用和意义?有哪些方式能识别这些强弱依赖,本文主要内容有:
强弱依赖及其作用
治理强弱依赖措施
针对服务划分等级
强弱依赖自动感知
一、强弱依赖及其作用
1.强弱依赖含义
服务之间的依赖: 当前互联网公司以微服务架构为主,微服务之间的上下游调用形成服务之间的依赖。
强依赖: 服务A调用服务B,B服务出现故障时A服务也不可用
弱依赖: 服务A调用服务B,B服务出现故障时A服务仍然可用
2.强弱依赖作用
梳理强弱依赖主要是保障核心服务的稳定性 ,避免由于弱依赖服务故障对核心服务造成拖累。尽管我们在服务发布时也常常需要考虑服务之间的依赖,先发下游服务(服务提供者),再发上游服务(服务消费者)。
处理服务发布时的依赖关系,通常有以下几种方式:
通过发布计划,发布计划要求梳理服务发布之间的依赖关系
在功能设计时尽量避免服务之间的强依赖,如果无法避免,可以通过开关来处理
通过蓝绿发布等方式避免服务发布之间的依赖关系
二、治理强弱依赖措施
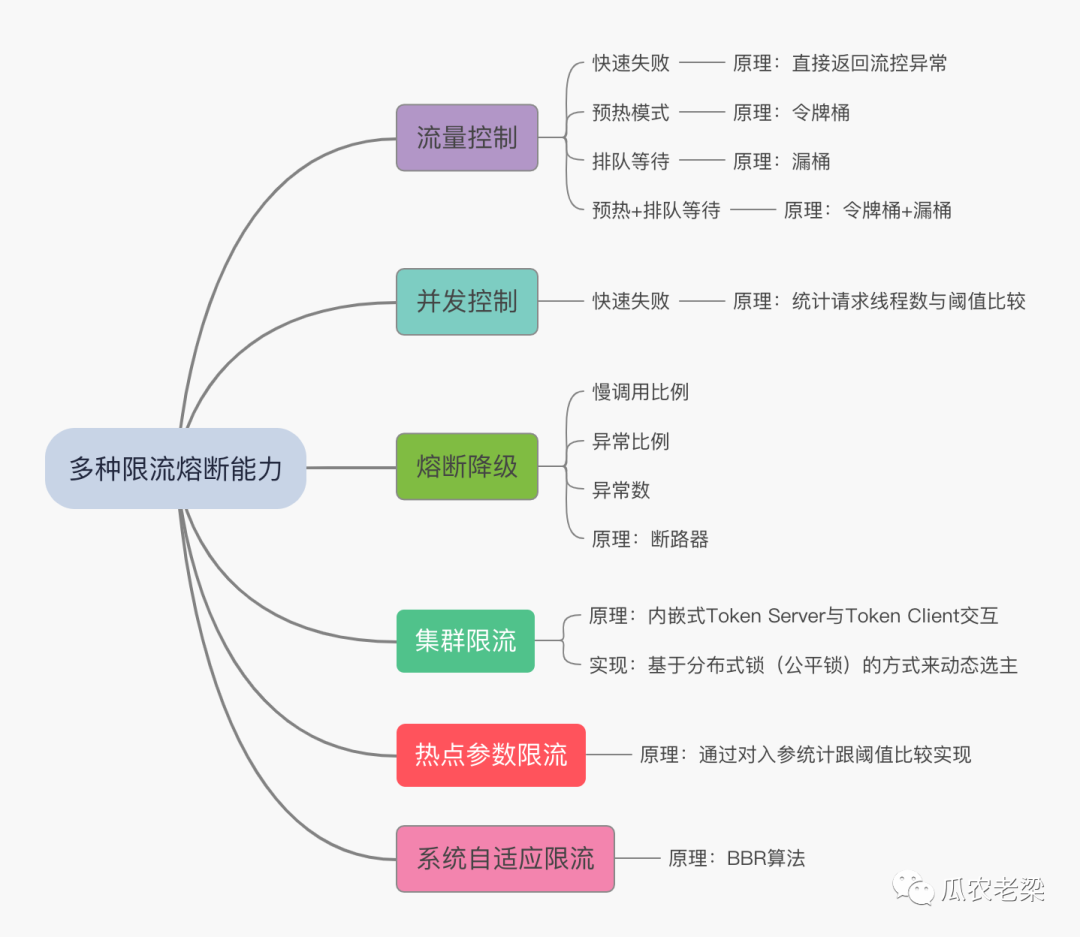
1.熔断限流措施
1.1 核心服务调用非核心服务
在非核心服务侧配置熔断降级,避免由于非核心服务产生慢调用拖垮核心服务。
常用的熔断维度有:慢调用比例、异常数比例、异常数
熔断实现通过断路器实现
1.2 非核心服务调用核心服务
通过核心服务配置限流,避免由于非核心服务流量过大对核心服务造成冲击
常用的限流措施:单机限流、集群限流、针对调用来源的限流
限流实现原理:令牌桶、漏桶
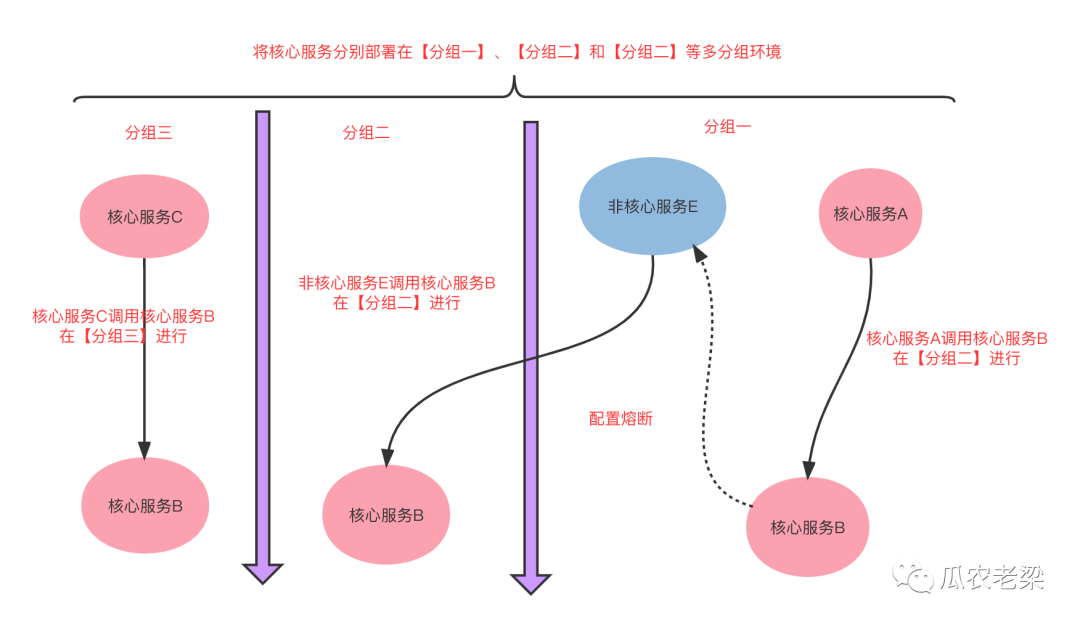
2.服务分组措施
如下图所示,将核心服务B部署在三个不同的分组中:
核心服务A调用核心服务B在分组一进行
核心服务B调用非核心服务E配置了熔断措施
非核心服务E调用核心服务B在分组二进行
核心服务C调用核心服务B在分组三进行
三、针对服务划分等级
1.强弱依赖前提
对服务的等级划分是强弱依赖的前提,否则我们将无法识别哪些是核心服务,哪些是非核心服务。针对强弱依赖的治理措施也就无法排上用场。
2.服务等级划分
在进行服务等级划分时,首先应该考虑划分的标准是什么?在考虑划分标准时须能够量化,避免模棱两可。发展故障时往往给用户带来影响、给公司带来资损。
发生故障时可以从受影响的用户数量、给公司造成资产损失两个维度进行划分。具体用户数量、资产损失多少,根据公司实际情况予以确定。
核心服务: 故障发生时造成公司较大资损(具体资损金额范围)或者用户大面积(受影响的用户数范围)无法使用,例如:交易支付服务。
重要服务: 故障发生不直接引起公司资损,不影响用户的整体体验,但是影响核心服务的排查效率和辅助决策能力,例如:监控告警服务。
辅助服务: 故障发生对用户使用情况和资产损失没有影响,例如:内部管理系统。
四、强弱依赖自动感知
1.强弱依赖人工梳理
通过走查服务代码核心逻辑,识别哪些链路接口是核心服务,哪些是非核心链路。针对这些非核心链路逻辑能够拆分到非核心服务中去。针对非核心链路可以配置降级措施。
2.故障演练自动感知
通过对依赖接口注入故障,判断对核心链路的影响,原理如下:
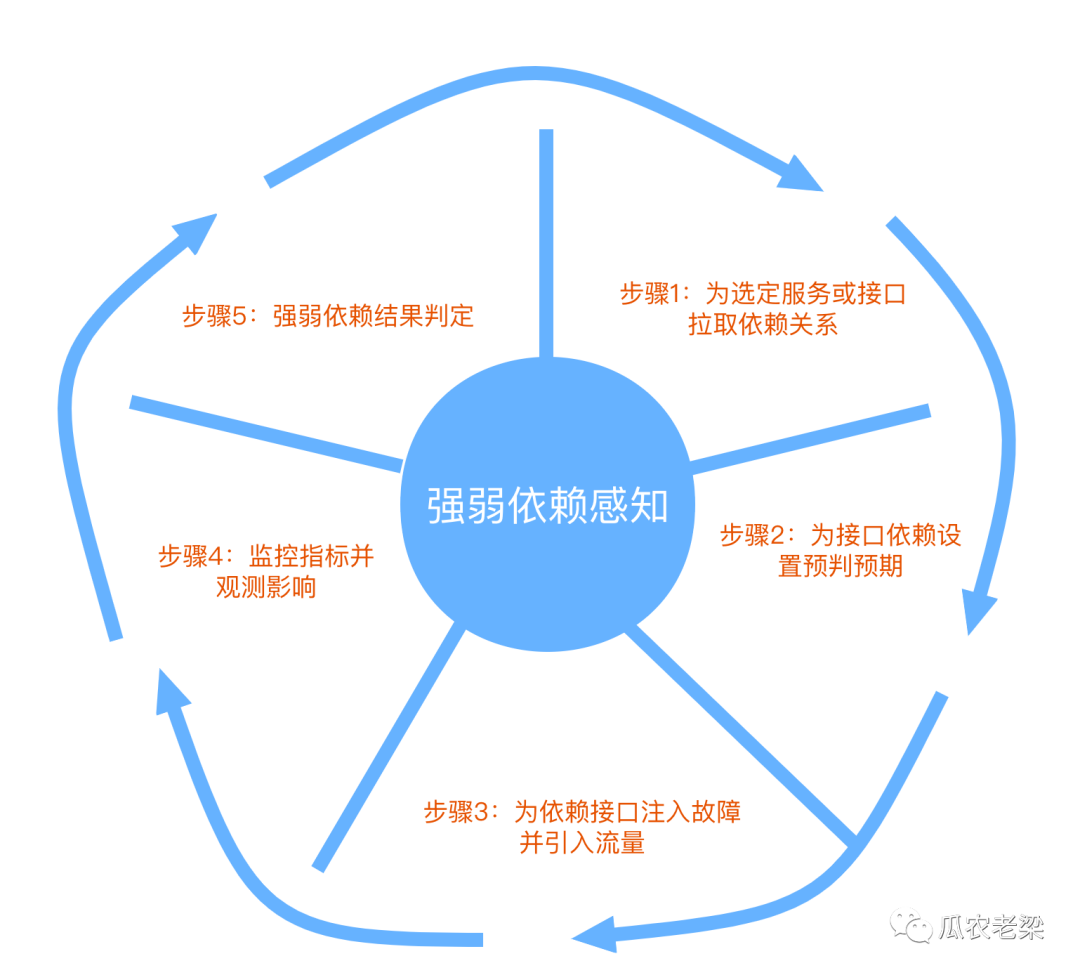
步骤1:为选定服务或接口拉取依赖关系
步骤2:为接口依赖设置预判预期
步骤3:为依赖接口注入故障并引入流量
步骤4:监控指标并观测影响
步骤5:强弱依赖结果判定


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









