







一,我是如何使用Python抓取网页的
我知道Python有一个爬虫框架scrapy,但是目前还没有学习,并且也没有什么很棘手的的问题需要去使用一个爬虫框架,所以我就用Python自带的urllib,将目标网页爬下来,然后用正则过滤出自己需要的内容。
二,效率问题
上面的方法简单,真的是上手即用,但是问题是效率问题,如果一个网页一个网页的抓,显然带宽无法达到最高,浪费了大部分带宽,这时候大部分人都会想到,多线程啊!
对,但是我们大部分人又都会写出下面的代码
# 总任务数有500个
while i < 500:
thirdList = []
# 每次开50个进程跑,这50个完了再开下一次50个线程
for x in range(50):
t = threading.Thread(target = loop)
t.start()
thirdList.append(t)
for t in thirdList:
t.join()这样做确实效率会提升一大截,因为毕竟是多线程了嘛,以前一个一个,现在50个50个的,肯定会提高效率,这种方式具体的网络占用情况见下面:
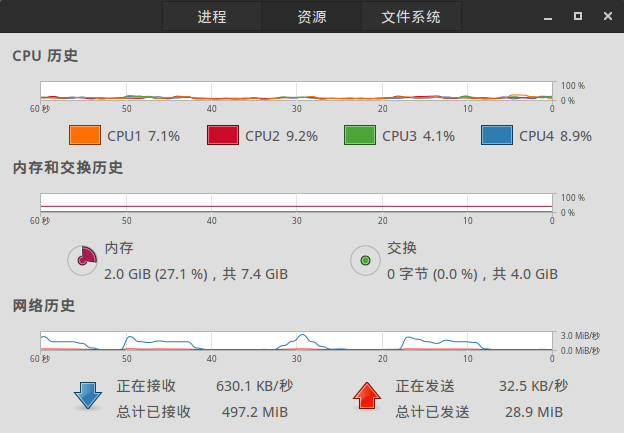
我们注意到,网络占用是一段一段的,突然变高又突然降低,这很容易理解,开始50个一起工作,肯定网络占用大,然后任务一个一个都完成了,网络占用肯定就又低了,等下一次50个来了,网络占用又变高了。
这就是我们想要的吗?肯定不是,我们需要的是一个能稳定占用宽带资源的程序,所以就有了线程池的应用。
三,简易“线程池”
思想是这样的,我们需要有一个机制,可以限制线程的个数,一个线程工作完成了,新的线程进来,并且如果某个线程工作超时,就自动退出(抓取大量网页,少一些是可以允许的)。
要解决的问题又两个:
(1)如何限制线程个数
(2)如何实现超时自动退出
(1)如何限制线程个数
我的办法很简单,就是计数,全局变量用来记录已经启动的线程的个数,然后,这个线程退出之前必须将线程数减一,这样,就可以控制线程个数
(2)如何实现超时退出
这个问题在我这个爬虫上很简单,超时就是网络连接超时,这个时间是可以设置的,就是下面这一句:
# 设置超时时间
socket.setdefaulttimeout(10)在线程中try-except检测:
try:
request = urllib.urlopen(pageUrl)
# 任何异常都退出,包括了超时异常
except Exception, e:
# 减少一个线程
thirdCount -= 1
return就是这样,很容易一个“线程池”实现了,下面是使用这种方法的效果:
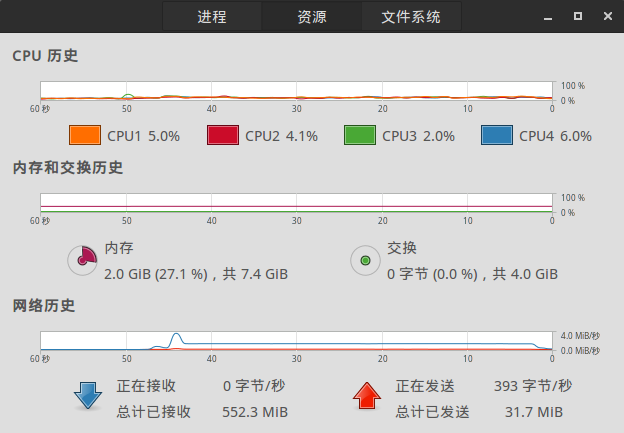
抓取过程中,网络都是被100%利用了的。
代码在这















 112
112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









