







【CVPR2024】CricaVPR: Cross-image Correlation-aware Representation Learning for Visual Place Recognition
这个论文提出了一种具有跨图像相关性的鲁棒全局表示方法用于视觉位置识别(VPR,Visual Place Recognition )任务,命名为 CricaVPR。主要有两个创新点:
- 使用自注意力机制来关联 batch 中多幅具有不同条件或视角的图像
- 引入了一种多尺度卷积增强策略,它通过融合多尺度局部信息来改进预训练的视觉基础模型
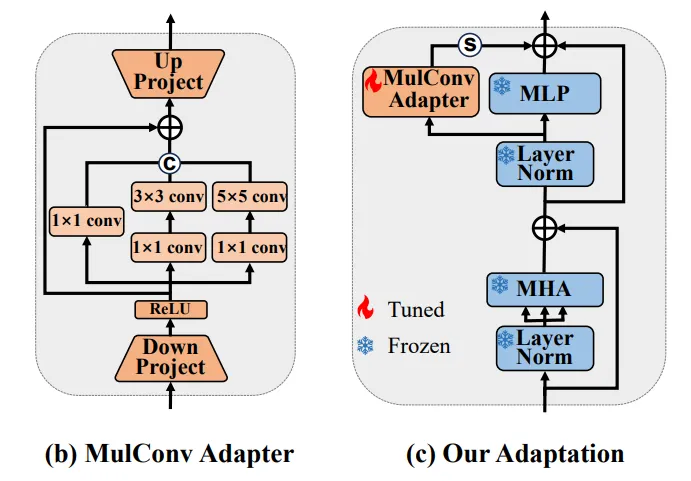
第二个创新点: multi-scale convolution-enhanced adaptation 比较容易理解,作者使用多尺度卷积来微调DINO,如下图所示,这里不过多介绍。
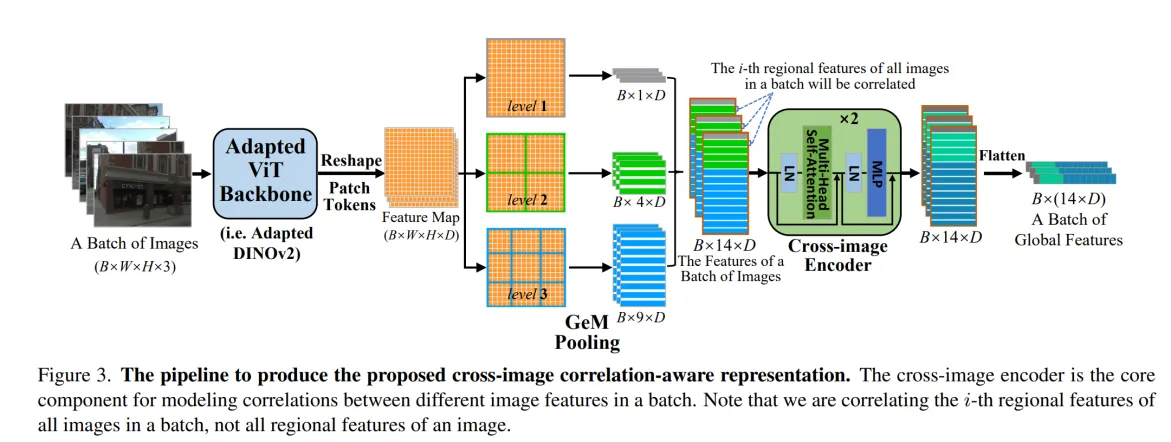
论文技术框架如下图所示,主要的跨尺度的图像编码器。需要注意的是,该方法是在关联一个 batch 所有图像第i个区域的特征,而不是单个图像的所有区域特征。可以这么理解,以前的 attention 是考虑 token 和 token 之间的相似性,这里作者考虑的是 图像与图像之间的关联。图里可能体现的不是特别清楚,得阅读作者的源代码了。
 实验部分可以参考作者论文,这里不过多介绍。
实验部分可以参考作者论文,这里不过多介绍。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









