







在日常开发中,我们经常会遇到MySQL查询变慢的问题——明明逻辑没问题,数据量也不算特别大,但SQL执行就是“磨磨蹭蹭”。此时,MySQL执行计划(Explain) 就是我们排查问题的“手术刀”:它能清晰展示MySQL优化器对SQL的执行思路,比如是否使用索引、扫描多少行数据、是否需要临时表等,帮我们精准定位性能瓶颈,写出更高效的SQL。
今天,我们就从基础用法到进阶实战,全面拆解MySQL执行计划,让你彻底掌握这个核心优化工具。
一、Explain入门:是什么?怎么用?
1. 什么是Explain?
Explain是MySQL提供的内置工具,通过在SQL语句前添加EXPLAIN关键字,就能获取MySQL优化器对该SQL的执行计划预估——它不会实际执行SQL,但会告诉我们:
- SQL是否使用了索引?用了哪个索引?
- 表之间的连接方式是什么?
- 预估需要扫描多少行数据?
- 是否需要排序或临时表?
这些信息是优化SQL的核心依据,也是排查慢查询的第一步。
2. 基本用法
用法极其简单:在需要分析的SQL前直接加EXPLAIN即可。例如:
-- 分析“查询t1表中b=100”的执行计划
EXPLAIN SELECT * FROM t1 WHERE b=100;
执行后,MySQL会返回一张包含多个字段的结果表,每个字段都对应执行计划的关键信息。接下来,我们先搭建测试环境,再逐个拆解这些字段。
二、实战准备:搭建测试环境
为了让执行计划的分析更直观,我们先创建两张测试表(t1和t2),并插入模拟数据。以下是完整的建表和数据插入语句,可直接复制执行:
-- 1. 创建数据库
CREATE DATABASE martin;
USE martin;
-- 2. 创建t1表(含主键和普通索引)
DROP TABLE IF EXISTS t1;
CREATE TABLE `t1` (
`id` int NOT NULL AUTO_INCREMENT,
`a` int DEFAULT NULL,
`b` int DEFAULT NULL,
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间',
PRIMARY KEY (`id`), -- 主键索引
KEY `idx_a` (`a`), -- 普通索引a
KEY `idx_b` (`b`) -- 普通索引b
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 3. 用存储过程插入1000条测试数据
DROP PROCEDURE IF EXISTS insert_t1;
DELIMITER ;;
CREATE PROCEDURE insert_t1()
BEGIN
DECLARE i int;
SET i=1;
WHILE(i<=1000) DO
INSERT INTO t1(a,b) VALUES(i, i);
SET i=i+1;
END WHILE;
END;;
DELIMITER ;
CALL insert_t1();
-- 4. 复制t1表为t2(结构和数据完全一致)
DROP TABLE IF EXISTS t2;
CREATE TABLE t2 LIKE t1;
INSERT INTO t2 SELECT * FROM t1;
环境搭建完成后,我们就可以基于这两张表分析执行计划了。
三、核心解析:Explain结果的关键字段
执行EXPLAIN SELECT * FROM t1 WHERE b=100;后,会得到类似如下的结果(不同MySQL版本格式可能略有差异,但核心字段一致):

其中,加粗的字段是需要重点关注的核心项,我们逐个拆解:
| 列名 | 解释 |
|---|---|
| id | 查询编号 |
| select_type | 查询类型:显示本行是简单还是复杂查询 |
| table | 涉及到的表 |
| partitions | 匹配的分区:查询将匹配记录所在的分区。仅当使用 partition 关键字时才显示该列。对于非分区表,该值为 NULL。 |
| type | 本次查询的表连接类型 |
| possible_keys | 可能选择的索引 |
| key | 实际选择的索引 |
| key_len | 被选择的索引长度:一般用于判断联合索引有多少列被选择了 |
| ref | 与索引比较的列 |
| rows | 预计需要扫描的行数,对 InnoDB 来说,这个值是估值,并不一定准确 |
| filtered | 按条件筛选的行的百分比 |
| Extra | 附加信息 |
1. select_type:查询类型
表示当前查询是简单查询还是复杂查询(如子查询、联合查询),常见值如下:
| select_type值 | 解释 |
|---|---|
| SIMPLE | 简单查询(无关联、无子查询),最常见的类型 |
| PRIMARY | 复杂查询中最外层的查询(如子查询的外层、联合查询的第一个查询) |
| UNION | 联合查询中第二个及以后的查询(如A UNION B中的B) |
| SUBQUERY | 子查询中第一个查询(如SELECT * FROM t1 WHERE id=(SELECT id FROM t2 where a=1)) |
| DERIVED | 派生表查询(如SELECT * FROM (SELECT distinct id FROM t1) AS temp中的子查询) |
| MATERIALIZED | 被物化的子查询(MySQL会将子查询结果存储为临时表,避免重复计算) |
重点:大部分日常查询都是SIMPLE类型,复杂查询(如SUBQUERY、UNION)需要关注是否有性能损耗(如重复计算)。
2. type:表连接/扫描类型(性能核心!)
type字段直接反映了查询的性能优劣,它表示MySQL如何扫描表中的数据,从优到劣的排序如下(越靠上性能越好,日常优化至少要保证达到range级别,避免ALL):
| type值 | 解释 | 适用场景 |
|---|---|---|
| system | 表中只有1行数据(仅MyISAM/Memory引擎支持),最优情况(几乎遇不到) | 极小表的查询 |
| const | 基于主键/唯一索引的等值查询,最多返回1行数据,性能极佳 | WHERE id=1(id是主键) |
| eq_ref | 关联查询中,被关联表基于主键/唯一索引扫描(每行只匹配1条) | t1 JOIN t2 ON t1.id=t2.id(t2.id是主键) |
| ref | 基于普通索引的等值查询,可能返回多行(但性能仍较好) | WHERE b=100(b有普通索引idx_b) |
| range | 基于索引的范围查询(如>、<、BETWEEN、IN) | WHERE a BETWEEN 100 AND 200 |
| index | 全索引扫描(扫描所有索引节点,但不扫描表数据),性能较差 | 查询字段都在索引中,但无过滤条件 |
| ALL | 全表扫描(扫描表中所有数据),性能最差,必须避免! | WHERE create_time='2024-01-01'(无索引) |
实战建议:如果type是ALL(全表扫描),优先检查是否能加索引;如果是range,确认是否能用等值查询优化(如IN改等值)。
3. key & possible_keys:实际使用/可能使用的索引
possible_keys:MySQL优化器认为当前查询可能适用的索引(可能有多个,也可能为NULL);key:MySQL优化器实际选择使用的索引(如果为NULL,说明没走索引)。
关键结论:
- 如果
possible_keys有值但key为NULL,说明索引失效(如索引列用了函数、类型不匹配等); - 如果
possible_keys和key都为NULL,说明没有合适的索引,需要考虑新增索引。
4. key_len:索引长度
表示当前查询中,MySQL实际使用的索引的字节长度,主要用于判断:
- 联合索引是否被完全利用(如联合索引
idx_a_b(a,b),若key_len包含a和b的长度,说明联合索引被完全使用); - 索引列是否允许NULL(允许NULL会多1字节)。
常见字段类型的key_len计算方式(以UTF8编码为例):
| 列类型 | KEY_LEN | 备注 |
|---|---|---|
| int | key_len = 4+1 | int 为 4 bytes,允许为 NULL,加 1 byte |
| int not null | key_len = 4 | 不允许为 NULL |
| bigint | key_len=8+1 | bigint 为 8 bytes,允许为 NULL 加 1 byte |
| bigint not null | key_len=8 | bigint 为 8 bytes |
| char(30) utf8 | key_len=30*3+1 | char(n)为: n * 3,允许为 NULL 加 1 byte |
| char(30) not null utf8 | key_len=30*3 | 不允许为 NULL |
| varchar(30) not null utf8 | key_len=30*3+2 | utf8 每个字符为 3 bytes,变长数据类型,加 2 bytes |
| varchar(30) utf8 | key_len=30*3+2+1 | utf8 每个字符为 3 bytes,允许为 NULL,加 1 byte,变长数据类型,加 2 bytes |
| datetime | key_len=8+1 (MySQL 5.6.4之前的版本); key_len=5+1(MySQL 5.6.4及之后的版本) | 允许为 NULL,加 1 byte |
实战用法:若联合索引idx_a_b(a,b)的key_len仅包含a的长度(如5),说明b列未被利用,需检查查询条件是否包含b。
5. rows:预估扫描行数
MySQL优化器预估的、当前查询需要扫描的行数(InnoDB引擎下是估值,不一定完全准确,但可作为参考)。
核心逻辑:rows越小,查询性能越好。如果rows远大于实际数据量,可能是MySQL统计信息过时,需执行ANALYZE TABLE 表名更新统计信息。
6. Extra:附加信息(性能问题的“预警灯”)
Extra字段包含MySQL执行SQL时的额外信息,很多时候是性能问题的直接信号,常见值如下:
| Extra值 | 解释 | 性能影响 | 例子 |
|---|---|---|---|
| Using index | 使用覆盖索引(查询字段都在索引中,无需回表查数据),性能优秀 | 正面(推荐) | explain select a from t1 where a=111; |
| Using filesort | 无法用索引排序,需在内存/磁盘中做外部排序,性能差 | 负面(需优化) | explain select * from t1 order by create_time; |
| Using temporary | 需要创建临时表存储中间结果(如无索引的GROUP BY),性能差 | 负面(需优化) | explain select * from t1 group by create_time; |
| Using where | 需用WHERE条件过滤数据(正常情况,非性能问题) | 中性 | explain select * from t1 where create_time='2019-06-18 14:38:24'; |
| Impossible WHERE | WHERE条件恒为false(如WHERE 1<0),无数据返回 | 中性 | explain select * from t1 where 1<0; |
| Using join buffer | 关联查询中,被驱动表无索引,需用缓冲区暂存数据,性能差 | 负面(需优化) | explain select * from t1 straight_join t2 on (t1.create_time=t2.create_time); |
实战案例:
- 若出现
Using filesort:检查排序字段是否有索引(如ORDER BY create_time需加idx_create_time); - 若出现
Using temporary:检查GROUP BY的字段是否有索引(如GROUP BY a需加idx_a)。
四、对比实验:有无索引对执行计划的影响
光说不练假把式,我们通过“有无索引”的对比,直观感受索引对执行计划的影响:
实验1:有索引的情况(b字段有idx_b索引)
执行:
EXPLAIN SELECT * FROM t1 WHERE b=100;
关键结果:
type=ref(普通索引等值查询,性能好);key=idx_b(实际走了索引);rows=1(仅扫描1行)。

实验2:无索引的情况(删除b字段的idx_b索引)
先删除索引:
ALTER TABLE t1 DROP INDEX idx_b;
再执行同样的查询:
EXPLAIN SELECT * FROM t1 WHERE b=100;
关键结果:
type=ALL(全表扫描,性能差);key=NULL(没走索引);rows=1000(预估扫描所有1000行数据)。
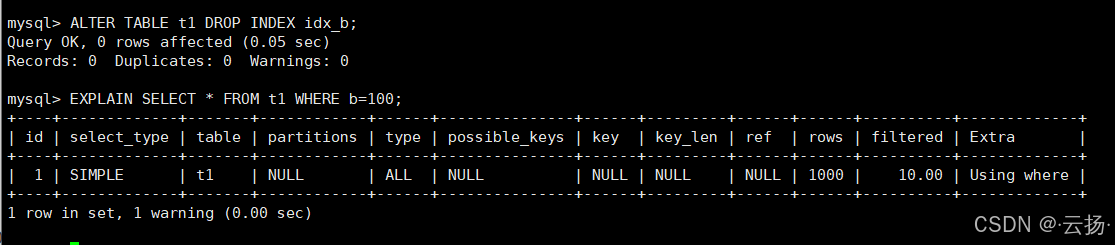
结论:索引能直接将type从ALL(全表)优化为ref(索引),扫描行数从1000降到1,性能提升显著。
五、特殊场景:分区表与实时执行计划
除了常规查询,Explain还能应对一些特殊场景,比如分区表和线上实时慢查询。
1. 分区表的执行计划
如果表是分区表(如按时间分区的销售表),Explain会显示partitions字段,告诉我们查询命中了哪些分区(避免全分区扫描)。
示例:创建分区表并分析执行计划
-- 1. 创建按年份分区的销售表
CREATE TABLE sales (
sale_id INT,
sale_date DATE,
amount DECIMAL(10, 2)
) PARTITION BY RANGE (YEAR(sale_date)) (
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN MAXVALUE
);
-- 2. 插入测试数据
INSERT INTO sales (sale_id, sale_date, amount)
VALUES
(1, '2022-01-01', 100.50),
(4, '2023-04-10', 300.20),
(8, '2024-09-17', 320.90);
-- 3. 分析查询2024年数据的执行计划
EXPLAIN SELECT * FROM sales WHERE sale_date='2024-09-17';
结果中partitions字段会显示p2024,说明仅扫描2024年的分区,避免了全分区扫描。

2. 实时分析正在执行的SQL
线上遇到慢查询时,我们可以用EXPLAIN FOR CONNECTION分析正在执行的SQL的执行计划,无需等待SQL执行完成。
步骤:
-
模拟慢查询:
SELECT *,sleep(100) FROM t1 LIMIT 1; -
用
show processlist查看当前连接的SQL:SHOW PROCESSLIST;会得到类似如下结果,记录目标SQL的
Id(如108):

-
分析该连接的执行计划:
EXPLAIN FOR CONNECTION 108; -- 12是上一步的Id
这样就能实时定位正在执行的慢查询的性能瓶颈(如是否走索引、是否全表扫描)。

六、MySQL 8.0新特性:更强大的执行计划
MySQL 8.0对Explain做了增强,新增了树状执行计划和EXPLAIN ANALYZE,让分析更精准。
1. 树状执行计划(FORMAT=TREE)
用FORMAT=TREE可以以树状结构展示执行计划,更直观地看到查询的逻辑流程,还能显示预估成本:
EXPLAIN FORMAT=TREE SELECT * FROM t1 WHERE a=100;
结果示例:
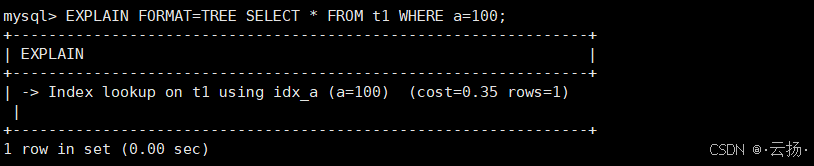
cost=0.35:预估执行成本(数值越小越好);rows=1:预估扫描行数。
2. EXPLAIN ANALYZE:实际执行并返回真实性能数据
EXPLAIN ANALYZE会实际执行SQL(注意:避免在生产环境执行写操作!),并返回真实的执行时间、扫描行数、循环次数等数据,比预估更精准:
EXPLAIN ANALYZE SELECT * FROM t1 WHERE a=100;
结果示例:

actual time=0.069..0.071:实际执行时间(毫秒),前值是获取第一行的时间,后值是获取所有行的时间;loops=1:循环次数(避免多次循环导致的性能损耗)。
适用场景:测试环境中精准优化SQL,确认优化后的实际性能提升。
七、总结:Explain优化SQL的核心流程
掌握了Explain后,优化SQL的流程就很清晰了:
- 执行EXPLAIN:获取执行计划;
- 看type:是否为
ALL(全表)或index(全索引),若是则优先加索引; - 看key:是否为NULL(没走索引),若是则检查索引失效原因;
- 看Extra:是否有
Using filesort/Using temporary,若是则优化排序/GROUP BY字段的索引; - 验证优化:加索引或修改SQL后,再用EXPLAIN(或8.0的EXPLAIN ANALYZE)验证性能是否提升。
最后记住:Explain不是“一次性工具”,而是日常开发中需要频繁使用的“SQL体检仪”——多分析、多对比,才能写出高性能的MySQL查询。

















 869
869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









