







目录
escape()、urlencodeComponent()、urlencode() 区别 :
javascript 中 escape,encodeURI 区别?
编码历史
参照链接: https://blog.csdn.net/longwen_zhi/article/details/79704687
ASCII编码
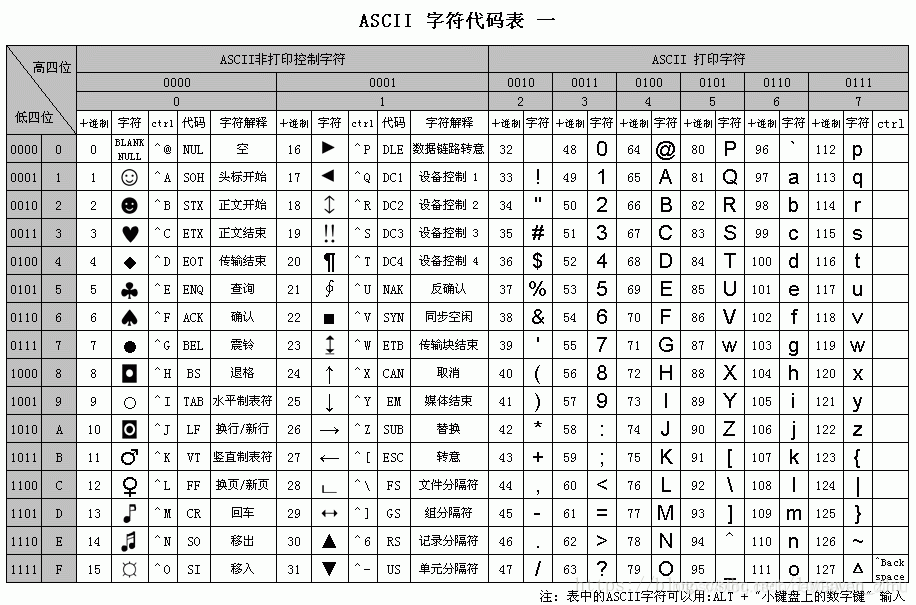
最开始美国编写的编码,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统
一个字节 8位二进制(其中使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。)
【ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),
如控制符 :LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;
如通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;
ASCII值为8、9、10 、13 分别转换为退格、制表、换行、回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
】
GBK 编码
GB2312
后来中国用计算机,但ASCII编码不支持中文。咋办,中国自己搞了一个 GB2312。但只能标识大约7000个汉子
两个字节 16位二进制(当字符小于127位时,与ASCII的字符相同,但当两个大于127的字符连接在一起时,就代表一个汉字)
GBK
中国汉子多,还有繁体字,7000个不够,咱办,在GB2312上继续扩展,重新定义规则,同时新增了近20000个新的汉字(包 括繁体字)和符号。
两个字节 16位二进制 (不在要求低字节一定是127之后的编码,只要第一个字节是大于127,就固定表示这是一个汉字的 开始,不管后面跟的是不是扩展字符集里的内容)
GB18030
又叫“DBCS”,又有问题了,中国有56个民族,所以,我们再次对编码规则进行了扩展,又加了近几千个少数民族的字符
Unicode编码
因为世界国家很多,每个国家都定义一套自己的编码标准,结果相互之间谁也不懂谁的编码,就无法进行很好的沟通交流,所以及时的出现了一个组织ISO决定定义一套编码方案来解决所有国家的编码问题。这个新的编码方案就叫做Unicode。
Unicode不是一个新的编码规则,是一套字符集(为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)),可以将Unicode理解为一本世界编码的字典。
( ISO规定:每个字符必须使用两个字节,即用16位二进制来表示所有的字符,对于ASCII编码表里的字符,保持其编码不变,只是将长度扩展到了16位,其他国家的字符全部统一重新编码。由于传输ASCII表里的字符时,实际上可以只用一个字节就可以表示,所以,这种编码方案在传输数据比较浪费带宽,存储数据比较浪费硬盘。)
UTF-8编码
由于Unicode比较浪费网络带宽和硬盘,因此为了解决这个问题,就在Unicode的基础上,定义了一套编码规则(将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)),
这个新的编码规则就是UTF-8,采用1-4个字符进行传输和存储数据。 utf-8中一个汉字是3个字节
UTF-8和Unicode与GBK的关系:
utf-8-------- decode(解码)----->>Unicode类型<<-------decode(解码)----- gbk
utf-8<<--------encode(编码)----->>Unicode类型<<-------encode(编码)----->>gbk
ACCII字符代码表

URL传特殊字符
参考链接:https://m.jb51.net/article/45777.htm
eg: http://localhost:8080/test.jsp?a=&123&b=+123
描述:地址栏 js传输特殊字符, eg: 上面的a=&123、b=+123字符当做参数传输,不用想肯定出错
原因: js后自动解析特殊字符,如+号为连接符,解析为空格,&为变量连接符,服务器端接受数据时&以后的数据不显示等等 (eg:+ 在js传递的时候,会理解为是连接字符用的,到了后台就将+号自动变为空格了,所以后台的字符串和前台生成 的已经不一样了)
解决:
1、将字符放到form表单中,然后用js提交form表单到服务器。(系统自动处理了,包括解决中文乱码问题)
2、将字符中的特殊字符替换成十六进制的字符, http://localhost:8080/test.jsp?a=%26123&b=%2B123
eg: str = str.replace(/\+/g,"%2B"); 将+号替换为十六进制 的 %2B
一些特殊字符与十六进制的对应关系:
| + | 空格 | / | ? | % | & | = | # | [ | ] |
| %2B | %20 | %2F | %3F | %25 | %26 | &3D | %23 | %5b | %5d |
3、最简单的一种,使用encodeURIComponent()函数。
该方法不会对 ASCII 字母和数字进行编码,也不会对这些 ASCII 标点符号进行编码: - _ . ! ~ * ' ( ) 。
其他字符(比如 :;/?:@&=+$,# 这些用于分隔 URI 组件的标点符号),都是由一个或多个十六进制的转义序列替换的。
http://localhost:8080/test.jsp?a=&123&b=+123
-
URL传中文
(参照链接:https://www.cnblogs.com/glory-jzx/archive/2013/06/14/3135580.html)
escape()、urlencodeComponent()、urlencode() 区别 :
js对文字进行编码涉及3个函数:escape, encodeURI, encodeURIComponent
相应3个解码函数:unescape, decodeURI, decodeURIComponent
编码 解码 应用场景 说明 encodeURIComponent() decodeURIComponent() 传递参数时 最多使用的应为encodeURIComponent,它是将中文、韩文等特殊字符转换成utf-8格式的url编码,所以如果给后台传递参数需要使用encodeURIComponent时需要后台解码对utf-8支持(form中的编码方式和当前页面编码方式相同)
递参数时需要使用encodeURIComponent,这样组合的url才不会被#等特殊字符截断。
例如:
<script ">
document.write(
'<a href="http://passport.baidu.com/?logout&aid=7&u=+encodeURIComponent("http://cang.baidu.com/bruce42")+">退出< /a>');</script>
encodeURI() decodeURI() url跳转时 进行url跳转时可以整体使用encodeURI
例如:Location.href=encodeURI("http://cang.baidu.com/do/s?word=百度&ct=21");
escape() unescape() js使用数据时 js使用数据时可以使用escape
例如:搜藏中history纪录。
escape对0-255以外的unicode值进行编码时输出%u****格式,其它情况下escape,encodeURI,encodeURIComponent编码结果相同。
javascript 中 escape,encodeURI 区别?
escape() 方法:
所有空格、标点符号、重音字符,以及任何其他非ASCII字符都编码改为"%XX"的形式,xx是16进制数字所代表.
escape和unescape的编码和解码功能, escape返回16进制编码的一种ISO拉丁字符集. unescape的功能将具有特殊值的16进制编码转换为ASCII字符串
举例:
escape('!@#$%^&*(){}[]=:/;?+\'"'):
结果:%21@%23%24%25%5E%26*%28%29%7B%7D%5B%5D%3D%3A/%3B%3F+%27%22
encodeURI() 方法 :
Encodeuri方法返回一个编码后的URI. 因此,如果你将其结果用Decodeuri方法,原始的串会返回. Encodeuri的方法并不对以下字符编码:":"、"/"、"; "、"? ". 但可以使用 encodeuricomponent 的方法对这些字符进行encode.
encodes,一种 Uniform Resource Identifier (URI)(URI)逐一替换某些字符,描述为UTF-8编码的特点.
例如 : encodeURI('!@#$%^&*(){}[]=:/;?+\'"'):
结果:!@#$%25%5E&*()%7B%7D%5B%5D=:/;?+'%22
encodeURIComponent() 方法:
encodeuricomponent 方法返回一个编码的URI. 因此,如果你将decodeuricomponent,原来的串会返回. 由于所有文字encodesencodeuricomponent方法都会进行编码,所以要小心,如果存在路径等串例如: "/FOLDER1/FOLDER2/DEFAULT.HTML". 加密后并不会,如果作为一个网络服务器的请求将会失效. 使用这种方法Encodeuri当字符串超过一个以上URI组成.
encodes,一种 Uniform Resource Identifier (URI)(URI)逐一替换某些字符,描述为UTF-8编码的特点.
例子:最简单的方法就是看它们加密这些字符后生成的代码.
encodeURIComponent('!@#$%^&*(){}[]=:/;?+\'"'):
结果 !%40%23%24%25%5E%26*()%7B%7D%5B%5D%3D%3A%2F%3B%3F%2B'%22
什么时候适合用什么方法?
escape()
escape() 方法不会加密 + 在服务器端会被解析为空格以及在表单forms区域中的空格spaces.基于这样的缩减方式,你应该尽可能的避免使用这种方法,二选一的话,最好的经常使用 encodeURIComponent().
escape() 不会加密: @*/+
encodeURI()
使用encodeURI() 比 escape() 稍专业化,它是针对URIs编码的 .一个做为querystring的反面, 属于URL的一个部分.使用这种方法是当你需要将一个字符串转换为URIs资源标识以及需要某些字符保持非encode状态.请记住, 这个' 字符是不会进行编码的,因为它本身就包括在URIs里.
encodeURI()不会加密: !@#$&*()=:/;?+'
encodeURIComponent()
encodeURIComponent() 方法用在大多数cases中,当你需要对一个单独URIs部件进行编码,这种方法可以加密某些特殊用于的URIs的字符,因此大部分部件可以包含在里面. 记住, ' 字符本身就包括在URIs里,所以不会此方法不会对其进行编码.
encodeURIComponent() 不会加密: !*()'
另外
escape不编码字符有69个:*,+,-,.,/,@,_,0-9,a-z,A-Z
encodeURI不编码字符有82个:!,#,$,&,',(,),*,+,,,-,.,/,:,;,=,?,@,_,~,0-9,a-z,A-Z
encodeURIComponent不编码字符有71个:!, ',(,),*,-,.,_,~,0-9,a-z,A-Z
另外还有其他写的好的参照:
https://www.williamlong.info/archives/469.html
https://747017186.iteye.com/blog/2260623















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









