







1、模拟headers
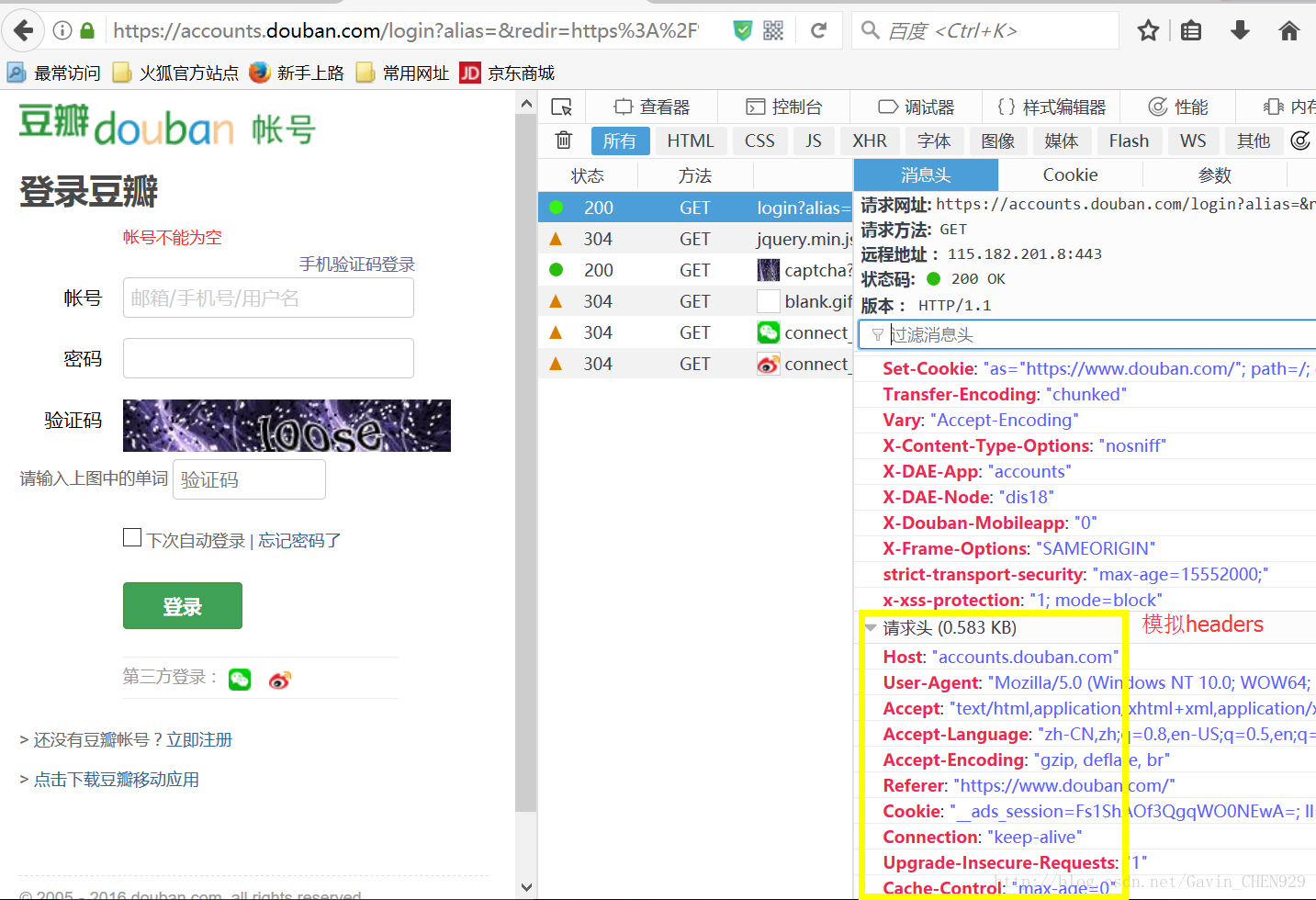
2、登陆豆瓣,查看并构造表单
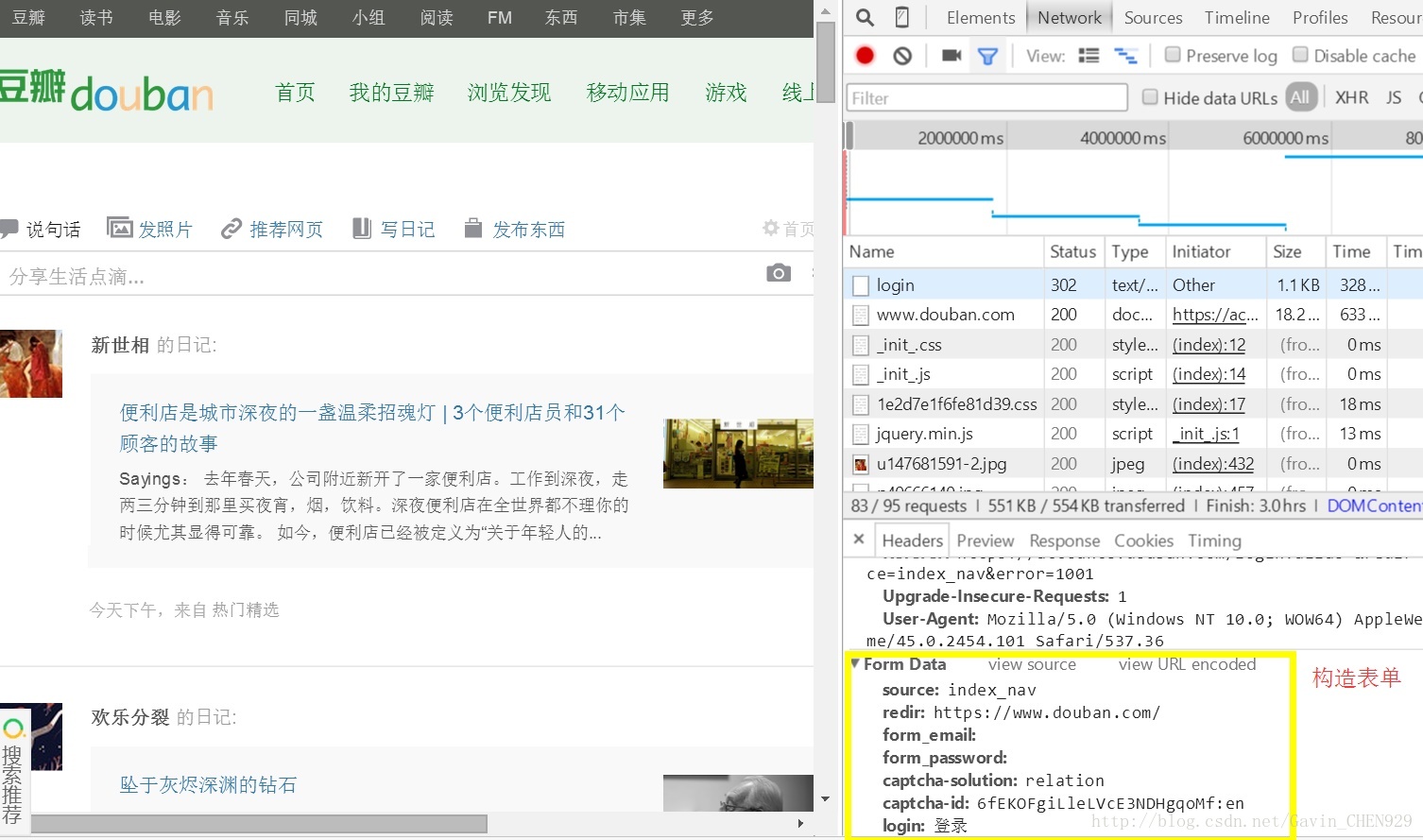
两种实现方式,一种普通,一种使用session
import requests
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
login_url = 'https://accounts.douban.com/login' # 登陆网址
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Host':'accounts.douban.com',
'Referce':'https://www.douban.com/',
} # 模拟headers
# s = requests.session() # 创建session
# s.headers.update(headers) # 之后会都会带上headers
res = requests.get(login_url, headers=headers)
# res = s.get(login_url) # 不用再模拟headers
res.encoding = 'utf-8'
print(res.status_code)
soup = BeautifulSoup(res.text, 'lxml')
captcha = soup.find_all('div', class_='item item-captcha')
captcha_id = captcha[0].find_all('input')
captcha_id = captcha_id[1]['value'] # 得到captcha-id
if len(captcha): # 如果存在验证码
captcha_url = captcha[0].div.img['src'] # 得到验证码图片地址
urlretrieve(captcha_url, 'd:/captcha.jpg')
captcha_solution = input('Please input captcha:\n')
form_data = {
'source':'index_nav',
'redir':'https://www.douban.com/',
'form_email':'',
'form_password':'',
'captcha-solution':captcha_solution,
'captcha-id':captcha_id,
} # 构造表单
else:
form_data = {
'source':'index_nav',
'redir':'https://www.douban.com/',
'form_email':'',
'form_password':'',
}
res_login = requests.post(login_url, headers=headers, data=form_data)
# res_login = s.post(login_url, data=form_data)
res_login.encoding = 'utf-8'
print(res.status_code)
soup = BeautifulSoup(res_login.text, 'lxml')
print(soup)














 1851
1851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









