







1. 思路分析
1.1 网页关系分析
上图红框内是第一页网址
第一页网址:https://movie.douban.com/top250?start=0
第二页网址:https://movie.douban.com/top250?start=25
…
第十页网址:https://movie.douban.com/top250?start=225
可以看出存在规律,实际就是每页展示25部电影。
1.2 页面内容定位
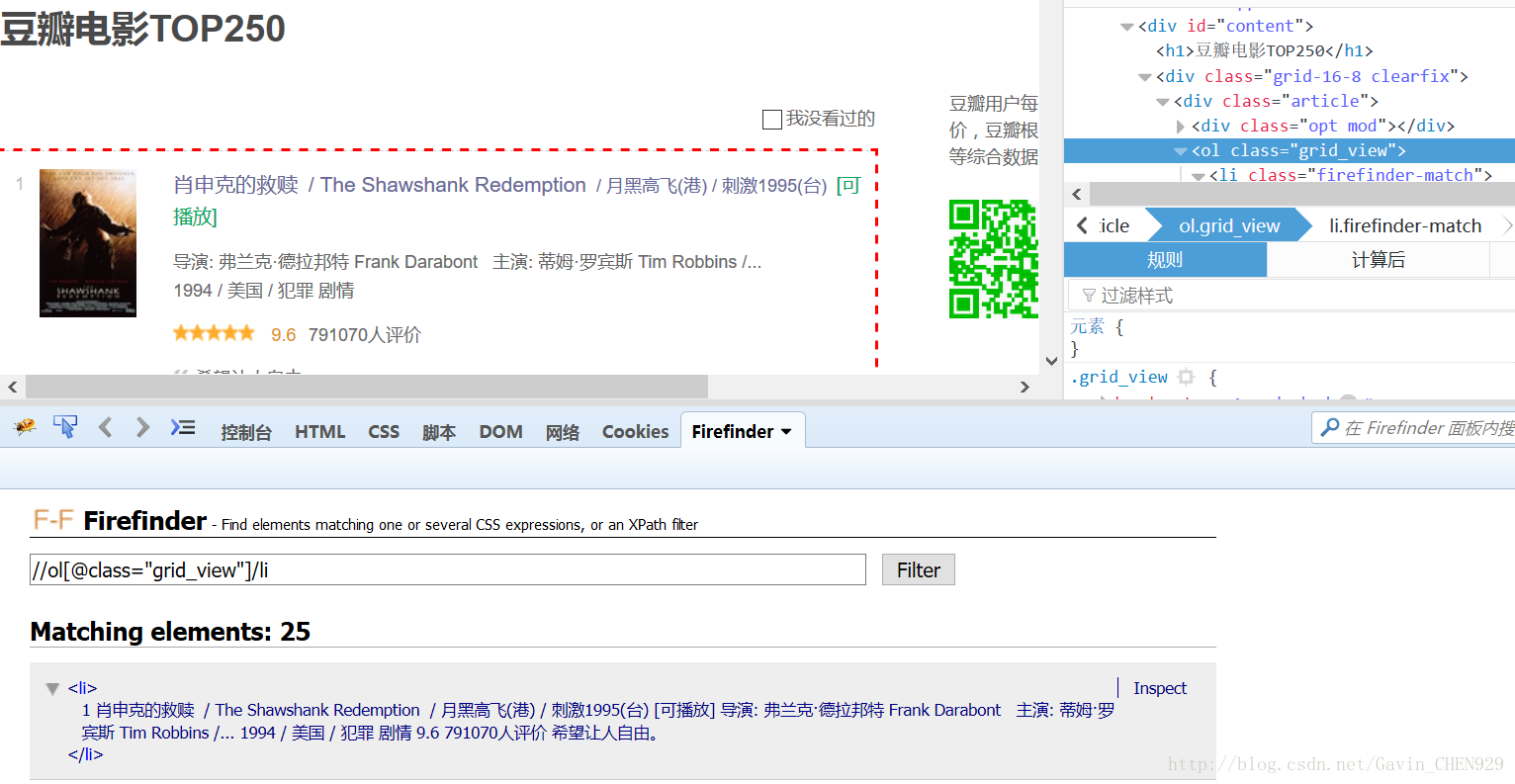
由于使用scrapy框架,可用Xpath表达式定位元素。
推荐可以使用Firefox的Firefinder插件结合Xpath,快速的定位到想要提取的元素。
2. 创建项目编写爬虫
创建一个项目目录douban
scrapy startproject douban进入douban目录创建爬虫film
scrapy genspider -t basic film movie.douban.comitems.py代码如下
import scrapy
class DoubanItem(scrapy.Item):
rank = scrapy.Field()
title = scrapy.Field()
dr = scrapy.Field()
act = scrapy.Field()
ty = scrapy.Field()
yr = scrapy.Field()
con = scrapy.Field()
des = scrapy.Field()
score = scrapy.Field()
link = scrapy.Field()
peo = scrapy.Field()film.py代码如下
import scrapy
from douban.items import DoubanItem
from scrapy.http import Request
class MovieSpider(scrapy.Spider):
"""
爬取豆瓣排名前250的电影信息,包括:
rank排名
title片名
dr导演
act演员
ty类型
score得分
peo评价人数
yr上映时间
con国家
link豆瓣链接
"""
name = "movie"
allowed_domains = ["movie.douban.com"]
start_urls = ['http://movie.douban.com/']
def parse(self, response):
for i in range(10):
url = "https://movie.douban.com/top250?start=%s" % str(i*25)
yield Request(url=url, callback=self.film_detail)
def film_detail(self, response):
item = DoubanItem()
rank = response.xpath('//ol[@class="grid_view"]/li/div/div/em/text()').extract()
namelst = response.xpath('//ol[@class="grid_view"]/li//div[@class="info"]//a//span[@class="title"][1]//text()').extract()
score = response.xpath('//ol[@class="grid_view"]/li//div[@class="star"]//span[2]//text()').extract()
peo = response.xpath('//ol[@class="grid_view"]/li//div[@class="star"]//span[4]//text()').extract()
link = response.xpath('//ol[@class="grid_view"]/li/div/div/a/@href').extract()
lsts = response.xpath('//ol[@class="grid_view"]/li//div[@class="bd"]//p[1]/text()').extract()
lsts = [lst.strip() for lst in lsts]
dr_act = lsts[::2] # 提取奇数项
yr_con_ty = lsts[1::2] # 提取偶数项
dr_act = [d.split('\xa0\xa0\xa0') for d in dr_act]
dr = [dr[0] for dr in dr_act]
act = [act[1] for act in dr_act]
yr_con_ty = [d.split('\xa0/\xa0') for d in yr_con_ty]
yr = [yr[0] for yr in yr_con_ty]
con = [con[1] for con in yr_con_ty]
ty = [ty[2] for ty in yr_con_ty]
for i in range(len(rank)):
item['rank'] = rank[i]
item['title'] = namelst[i]
item['score'] = score[i]
item['link'] = link[i]
item['dr'] = dr[i]
item['act'] = act[i]
item['yr'] = yr[i]
item['con'] = con[i]
item['ty'] = ty[i]
item['peo'] = peo[i]
yield itempipelines.py代码如下
import pymysql.cursors
class DoubanPipeline(object):
"""
将数据写进本地csv文件和mysql数据库
"""
def __init__(self):
self.conn = pymysql.connect(host='127.0.0.1',
user='root',
password='123456',
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)
cur = self.conn.cursor()
cur.execute("create database douban")
cur.execute("use douban")
cur.execute("create table film(id INT PRIMARY KEY AUTO_INCREMENT, rank INT, title VARCHAR(200), score FLOAT , link VARCHAR(50), dr VARCHAR(200), act VARCHAR(200), yr VARCHAR(200), con VARCHAR(200), ty VARCHAR(200), peo VARCHAR(50))")
def process_item(self, item, spider):
rank = item['rank']
title = item['title']
score = item['score']
peo = item['peo']
link = item['link']
dr = item['dr']
act = item['act']
yr = item['yr']
con = item['con']
ty = item['ty']
with open('film.csv', 'a+', encoding='utf-8') as f:
f.write(rank+',')
f.write(title+',')
f.write(score+',')
f.write(dr+',')
f.write(act+',')
f.write(yr+',')
f.write(con+',')
f.write(ty+',')
f.write(peo + ',')
f.write(link + '\n')
try:
cur = self.conn.cursor()
sql = "insert into film(rank, title, score, peo, link, dr, act, yr, con, ty)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
cur.execute(sql, (rank, title, score, peo, link, dr, act, yr, con, ty))
self.conn.commit()
return item
except Exception as err:
print(err)
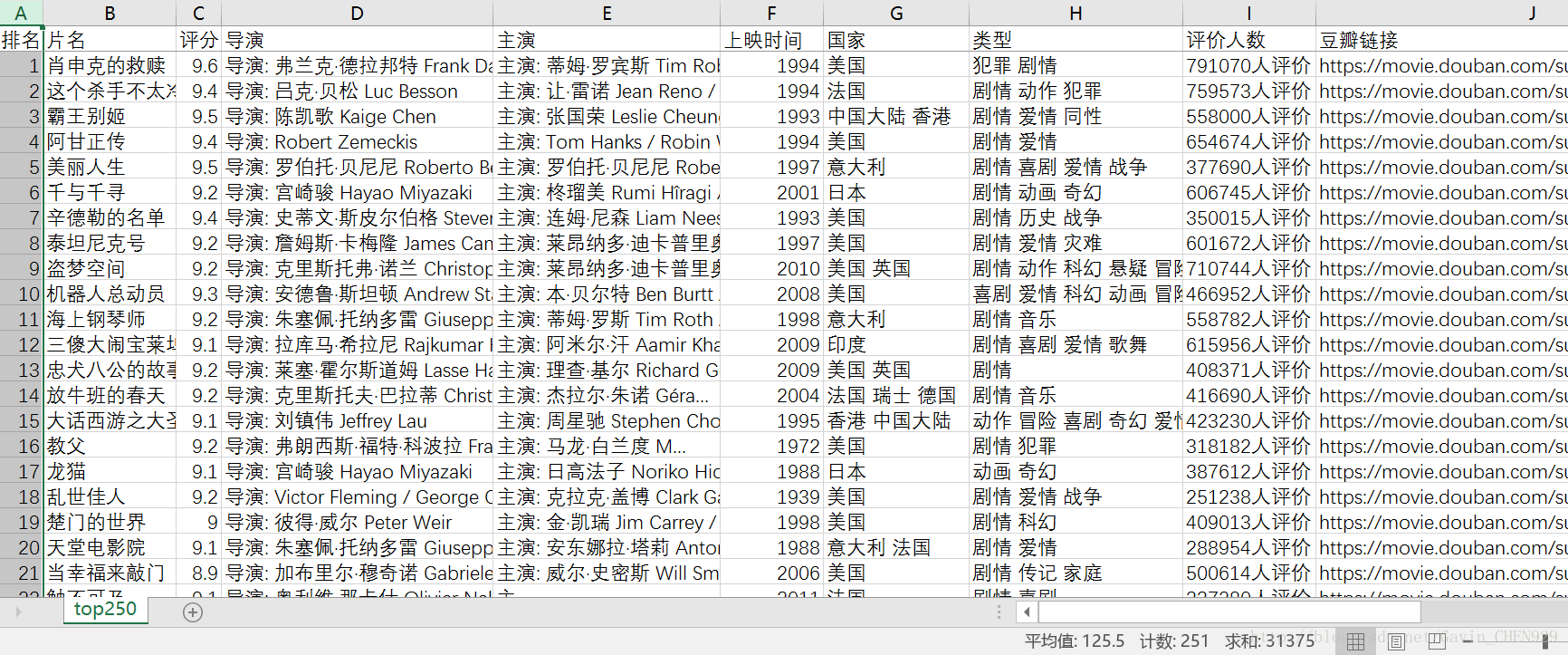
print(rank, title)3. 爬取结果
本地csv文件
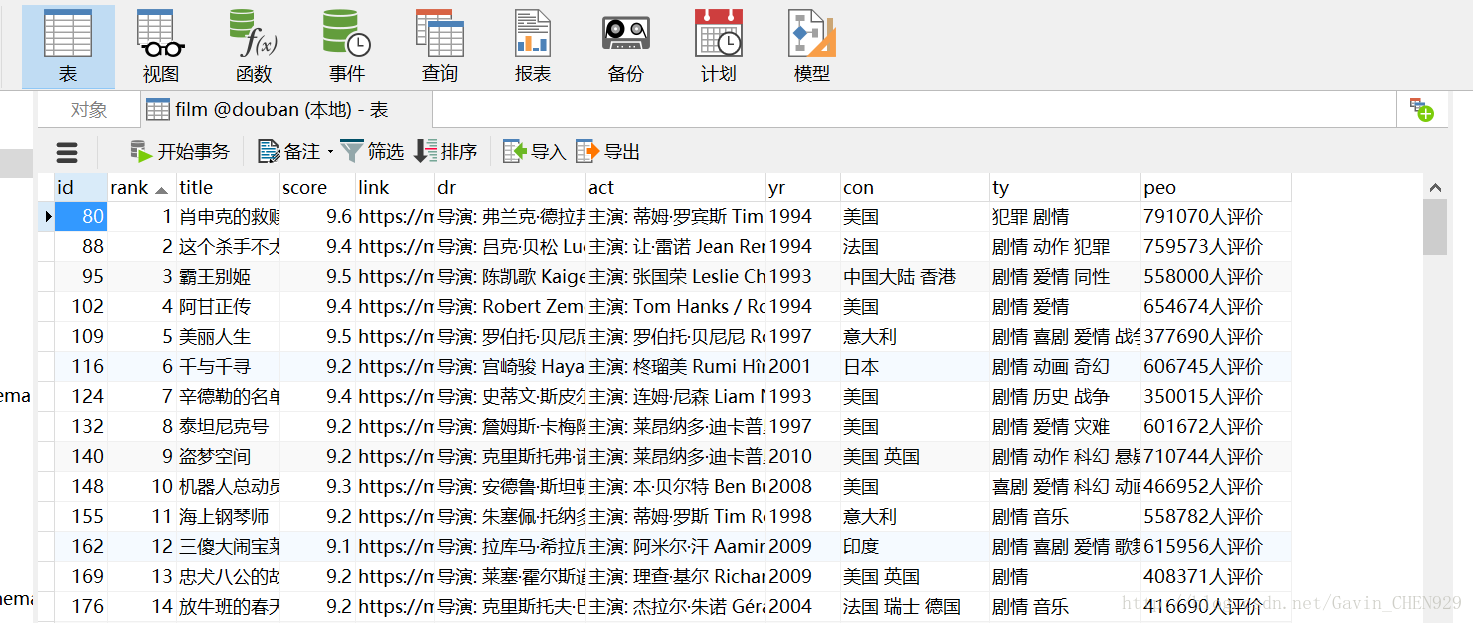
MySQL数据库














 9688
9688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









