







Summary
我们使用了libpmem,libpmemobj,pmemkv,以及memkind来实现几乎相同的功能,把持久内存当成页缓存,所不同的是memkind是易失的。您可以把这些代码在您的持久内存的服务器上编译并运行,从而深入的了解持久内存编程的方法和需要注意的地方,因为应用的功能和性能完全取决于你对持久内存的理解和编程的方法。所有的这些代码在github中也可以找到:https://github.com/guoanwu/pmem_program/tree/master/cbs_req .
现在我们就这几种实现的异同,从代码量、性能、实现的难度、还有空间的额外开销等方面来比较这些解决方案,如表 1所示:就这个场景而言,我我们可以推荐使用libpmem或者libpmemblk。
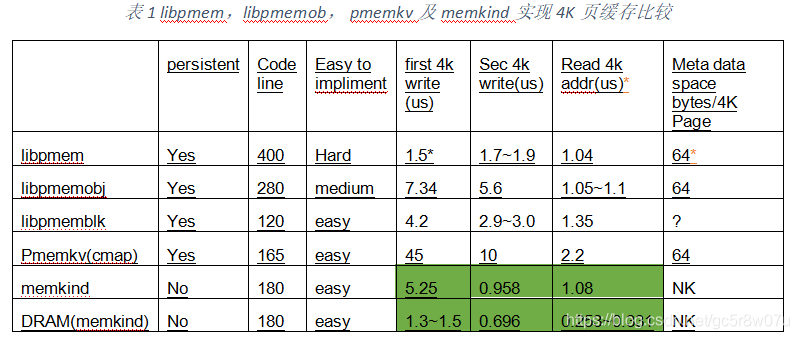
- libpmem meta data 64 bytes is for the cache optimization. In ICX+BPS, can change back to 8 bytes overhead.
*read will real copy the 4k page from PMEM to DRAM.
Accelerate the WAL
根据客户的反馈,有客户需要加速WAL的写入,当然通过持久内存可以非常快的加速log的写入,在Intel的官网上面可以看到一些相关的测试: https://software.intel.com/content/www/us/en/develop/articles/optimizing-write-ahead-logging-with-intel-optane-persistent-memory.html; 客户很多的WAL的log大小基本是在100个字节左右,必须完全落盘,如果使用SSD,由于每次刷盘都需要至少一页的大小,所以存在严重的写放大的问题, 写的实际有效的带宽非常小。而由于持久内存是自己可访问的,没有写放大的问题,可以非常充分的利用所有的持久内存的带宽。
但是有些客户的WAL log的量非常大,没有办法完全写入持久内存中,所以想使用持久内存来加速整个log的写入,来使用大概有下面的一些需求:
1.Log的大小一般可能就100字节左右,每个log都必须保证持久化,也就是写入SSD时候必须每次保证刷新。SSD每次都需要写入4K页面,所以存在严重的写放大的问题。
2.可以使用持久内存来作为一个持久化buffer,在背后将log写入SSD。
3.不能出现任何脏的数据。
4.在断电的情况下,最多丢弃一条最后正在写入的记录。
我们完成了一个POC在github上可以找到我们代码:https://github.com/guoanwu/pmem_program/blob/master/wal_accel,其中的实现主要是使用了持久内存作为一个ring buffer,在写入持久内存的同时,写入SSD(不刷新,利用page cache),在一段时间后,使用背后的线程将SSD的数据刷新,并更新持久内存buffer中的消费地址。恢复数据时,将SSD的数据加上持久内存中保留的部分数据拼在一起就是完整的数据。同时我们实现了系统调用的截获,使用PRELOAD就可以不需要更改原来的代码,而有直接加速的作用。
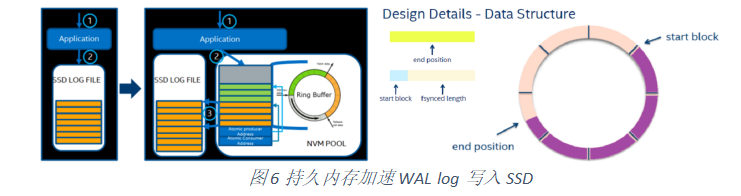
我们通过示例 6来测试WAL的写入性能。
示例 6 WAL log写入测试
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <time.h>
#include <string.h>
uint64_t ntime_since(const struct timespec *s, const struct timespec *e)
{
int64_t sec, nsec;
sec = e->tv_sec - s->tv_sec;
nsec = e->tv_nsec - s->tv_nsec;
if (sec > 0 && nsec < 0) {
sec--;
nsec += 1000000000LL;
}
/*
* time warp bug on some kernels?
*/
if (sec < 0 || (sec == 0 && nsec < 0))
return 0;
return nsec + (sec * 1000000000LL);
}
#define LOG_NUM 10000
unsigned char * logs[LOG_NUM];
const unsigned char allChar[63]="0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
void generateString(unsigned char* dest,const unsigned int len)
{
unsigned int cnt,randNo;
srand((unsigned int)time(NULL));
for(cnt=0;cnt<len;cnt++)
{
randNo=rand()%62;
*dest=allChar[randNo];
dest++;
}
*dest='\0';
}
//generate LOG_NUM logs with different size from 50~250
void gen_log()
{
int i,size;
unsigned char * dest;
srand((unsigned int)time(NULL));
//generate logs
for(i=0;i<LOG_NUM;i++)
{
size=rand()%(250-50+1)+50; //50~250 bytes.
dest=(unsigned char *)malloc(size+1);
generateString(dest, size);
logs[i]=dest;
}
}
int main()
{
int fd, size;
char *buffer;
struct timespec start, end;
int i=100;
int j;
gen_log();
//write log, we must append write
fd = open("/mnt/nvme0/wal.log", O_WRONLY|O_CREAT|O_APPEND);
clock_gettime(CLOCK_REALTIME, &start);
//1M log write into the log
while(i--) {
for(j=0;j<LOG_NUM;j++)
{
write(fd,logs[j],strlen((const char *)logs[j]));
fdatasync(fd); //in the normal code, we need to fdatasync and with the wal accellerate, we need to use the AOFGUARD_DISABLE_SYNC=yes to ignore this sync; the data sync is called in the write
}
}
clock_gettime(CLOCK_REALTIME, &end);
printf("the durating for 1m logs=%ld\n",ntime_since(&start,&end));
//fd: the file is closed
close(fd);
//read progress:since when open the log again, it will copy the data in the pmem to the NVMe, so the O_RDWR must be used.
fd = open("/mnt/nvme0/wal.log", O_RDWR);
struct stat stat;
fstat(fd,&stat);
printf("fd=%d,filesize=%ld read the log from the head with the size 300 \n",fd,stat.st_size);
//lseek(fd, 0, SEEK_SET);
buffer=malloc(300);
size = read(fd, buffer, 300); //read data to a buffer
printf("size=%d, buffer=%s, bufferlen=%ld\n",size, buffer, strlen(buffer));
close(fd);
free(buffer);
}
编译后我们测试可以发现用持久内存加速WAL,性能有很大的提升。但是这里的测试数据只是一个参考,不同的配置有不同的数据 。
















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









