







在微信公众号“dotNET跨平台”中看到文章《使用IronOCR识别图片文字》(参考文献1),主要介绍Ocr工具IronOCR,后者是基于C#开发的、从图片和PDF文档中识别及读取文本的工具库。本文基于参考文献测试IronOCR的基本用法。
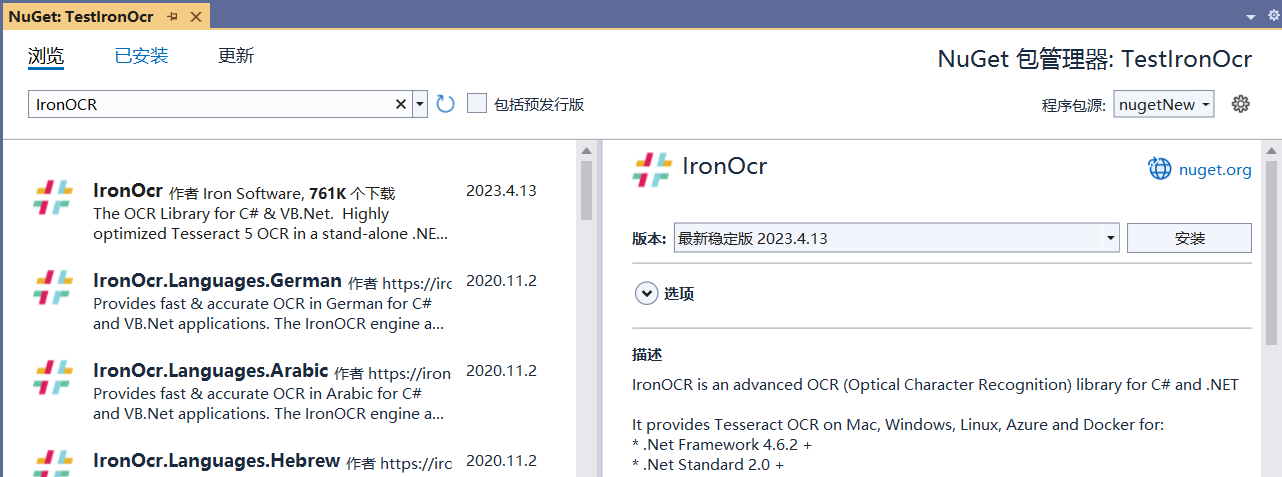
之前测试过采用PaddleOCRSharp识别车牌及图片中的文字,基于上次的程序界面,在项目中添加IronOCR的NuGet包,如下图所示:
参考文献1中的示例代码很简单,如下所示。测试过程中发现的问题是AutoOcr这个类在IronOCR中已经找不到了,在IronOCR官网的帮助文档中也找不到该类。
var Ocr = new AutoOcr();
var Image = new Bitmap(@"C:\path\to\image.png");
var Result = Ocr.Read(Image);
Console.WriteLine(Result.Text);
从IronOCR的NuGet包说明中找到项目url(参考文献5),其首页包含最新的、也最简单的程序用法,如下所示:
using IronOcr;
var ocr = new IronTesseract();
using (var input = new OcrInput())
{
input.AddImage("attachment.png");
OcrResult result = ocr.Read(input);
string text = result.Text;
}
基于上述示例,编写代码识别车牌图片及纯文本图片,示例代码及测试图片如下所示,但是要么结果为空,要么就是一堆乱码。
var Ocr = new IronTesseract();
using (var input = new OcrInput(imagePath))
{ var Result = Ocr.Read(input);
txtOcrResult.Text = Result.Text;
}

接着翻IronOCR的帮助文档,入门文章的开头也有示例代码,但比上面的代码多了一句,即指定识别的语言。于是将代码修改为指定识别图片中的中文文本(代码如下),但是运行程序时会报下图所示错误:
var Ocr = new IronTesseract();
Ocr.Language = OcrLanguage.ChineseSimplifiedBest;
using (var input = new OcrInput(imagePath))
{
var Result = Ocr.Read(input);
txtOcrResult.Text = Result.Text;
}
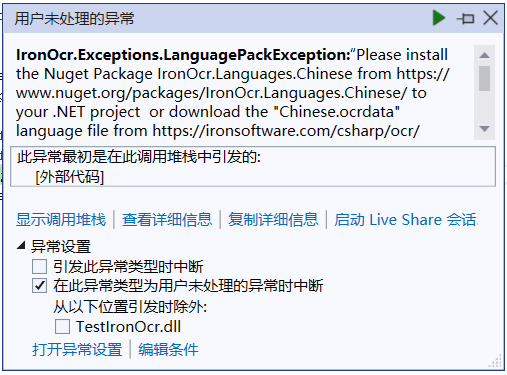
看报错信息应该是缺少语言包,同时在帮助文本中也找到一段话,大致意思是说虽然IronOCR支持125种语言,但安装NuGet包时仅带了英语的语言包,如果需要识别其它语言的图片,需要安装对应语言的NuGet包。于是搜索并安装IronOCR中文语言包,注意,安装时请安装IronOcr.Languages.Chinese包,安装IronOcr.Languages.ChineseSimplified的话运行程序依然会报错。

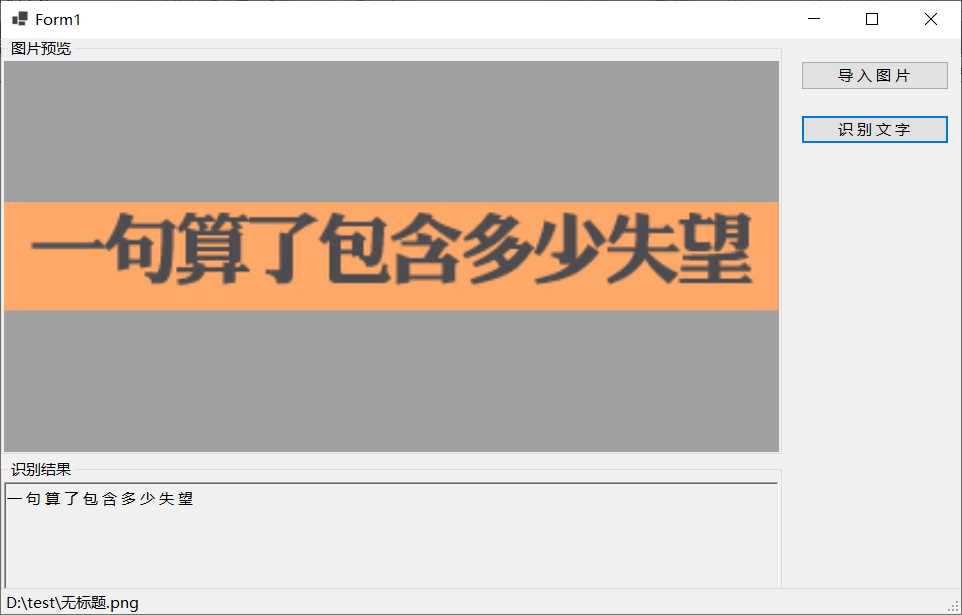
 再运行程序,即可识别文本,测试截图如下图所示,但是识别车牌还是结果为空。IronOCR的配置很多,本文仅是根据示例走通了最简单的用法,后续还会继续学习IronOCR的更详细的用法。
再运行程序,即可识别文本,测试截图如下图所示,但是识别车牌还是结果为空。IronOCR的配置很多,本文仅是根据示例走通了最简单的用法,后续还会继续学习IronOCR的更详细的用法。

参考文献:
[1]https://blog.csdn.net/sD7O95O/article/details/130023008?spm=1001.2014.3001.5502
[2]https://blog.csdn.net/qq_35264464/article/details/80438581
[3]https://blog.51cto.com/shanyou/3271156
[4]https://ironsoftware.com/csharp/ocr/docs/?utm_source=nuget&utm_medium=organic&utm_campaign=readme&utm_content=crossplatformbanner
[5]https://ironsoftware.com/csharp/ocr/

















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









