






论文地址:https://arxiv.org/pdf/1602.02830.pdf
代码:
Theano框架:https://github.com/MatthieuCourbariaux/BinaryNet
Torch框架:https://github.com/itayhubara/BinaryNet
主要内容
BNNs是在CNNs的基础上,将权重和激活值量化为1bit,即取值为+1和-1,这样前向传播时就能减少内存大小和访问,同时大部分的算术运算也转化成位运算,计算效率大大提高。作者还编写了一个二进制乘法的GPU内核,在MNIST上比普通的GPU快7倍,而且不损失任何精度。
权重、激活值和梯度的处理
作者提出两种二值化方法:
1.Deterministic(确定法)
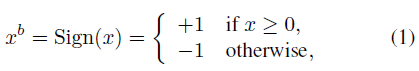
即直接使用符号函数。
2.Stochastic(随机法)
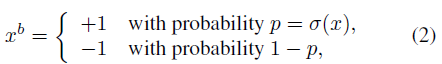
其中,
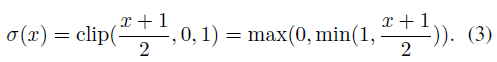
虽然随机法更加合理,但实现比较困难,需要硬件生成随机数,所以一般都是用确定法。
需要注意的是,梯度并未二值化。因为SGD的步长很小,而且梯度是累加的即带有一定的噪声,而噪声一般都服从正态分布,需要多次累加梯度来平均噪声。因此需要高精度的实数梯度。
BNN方法可以看作是Dropout的变形,区别在于Dropout是将一半的激活值置0,而BNN则是进一步将另一半置1。
二值化后还存在一个问题:sign函数是常数函数,导数为0,因此无法进行梯度传播。因此作者采用了STE的思路,用饱和STE的方法进行处理:
假设C为损失函数,有:
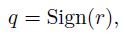

其中,
g
r
=
∂
C
∂
r
g_r=\frac{\partial C}{\partial r}
gr=∂r∂C,
g
q
=
∂
C
∂
q
g_q=\frac{\partial C}{\partial q}
gq=∂q∂C,而
1
∣
r
∣
≤
1
1_{|r| \leq 1}
1∣r∣≤1表示当
−
1
≤
r
≤
1
-1 \leq r \leq 1
−1≤r≤1时,梯度为1,否则梯度为0。可以看作用Htanh函数代替sign函数,即:
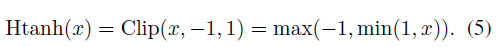
解决上面的问题后,给出如下训练算法:

优化技巧
Shift based Batch Normalization:主要用AP2(x)操作和移位操作代替乘法。AP2(x)是求与x的值最接近的2的次幂。具体如下:

Shift based AdaMax:

第一层:除了第一层输入,其他所有层的输入都是二元的,不过这影响不大。一方面,输入层相对于其他层通道更少(如rgb);另一方面,连续的输入转化成定点是很容易的。对于8bit输入,有:

前向传播时各层的计算方法如下:

该算法利用
±
1
\pm 1
±1乘法运算表的特点,用同或xnor代替乘法。
一些实验结果


Theano使用的是普通的BN层。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









