







- 需要一个Linux系统,可以采用虚拟机,也可以租用云主机
- 安装JDK环境
在命令行输入javac,看是否已经有JAVA环境,没有则继续按照提示安装JDK环境,安装完JDK之后,在命令行输入 vim /etc/profile ,进行设置环境变量。
javac验证时候有JAVA环境:
配置环境变量:配置的变量包含JAVA_HOME、CLASSPATH、PATH,按照自己的安装目录进行配置
配置完成后输入以下命令让其生效


如何配置Hadoop?
首先安装hadoop
下载hadoop ,命令如下:
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz




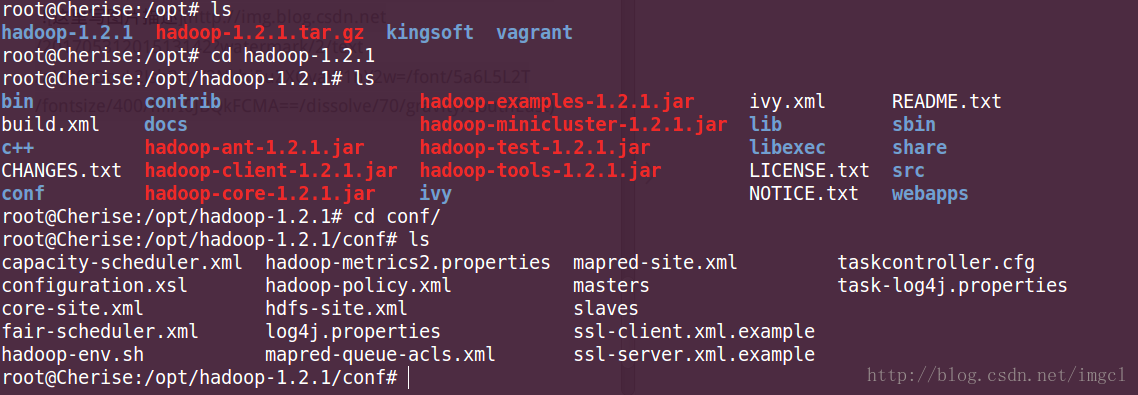
conf里面需要配置的文件有(下图中红色框起来的):

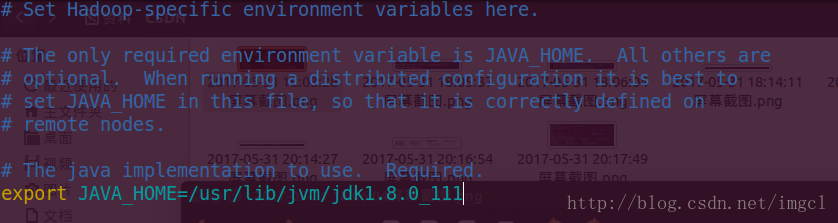
第一个修改hadoop-env.sh中的配置
vim hadoop-env.sh 进入文件配置JAVA_HOME 变量 和之前配置JAVA环境的JAVA_HOME路径是一样的,如果不知道JAVA_HOME的路径,可以通过echo $JAVA_HOME来查看路径
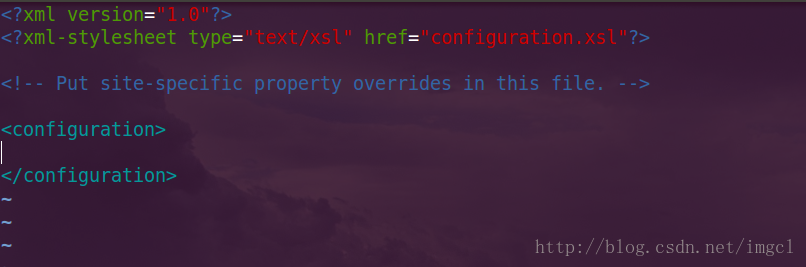
接下来配置其他是三个XML文件,第一个看core-site.xml,打开之后它是一个空的配置文件,如下图:
配置后的(注意:下图中的localhost为自己本机的名字比如我的就是:Cherise):
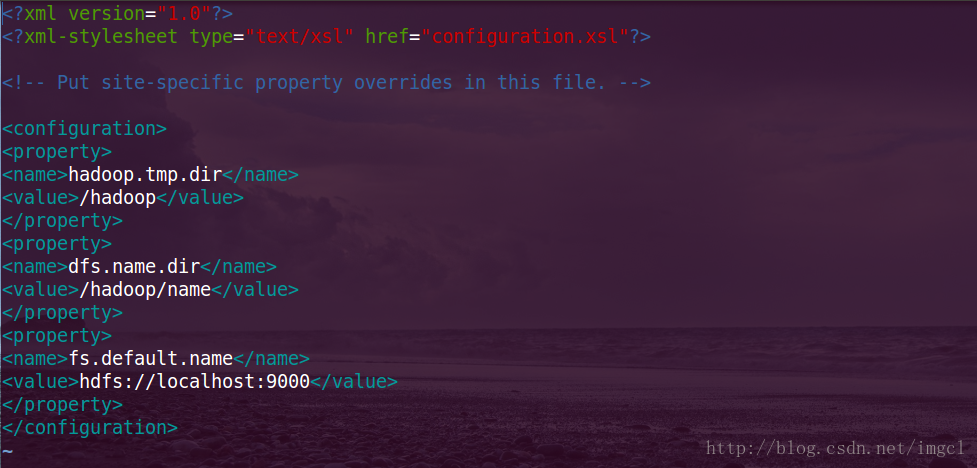
<name>hadoop.tmp.dir</name>
<value>/hadoop</value> //配置Hadoop的临时工作目录
</property>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value> //dfs.name.dir的目录在/hadoop/name下
</property>
<property>
<name>fs.default.name</name>//文件系统的DataNode该如何访问
<value>hdfs://localhost:9000</value>//用这个方式访问(本机)
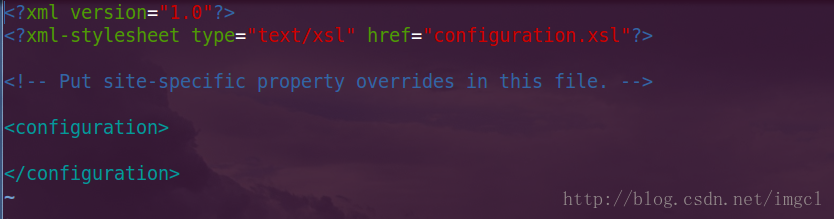
</property>再来看vim hdfs-site.xml 配置文件,配置前的(它也是一个空的配置文件,同样也需要一些属行需要配置):
配置后的:
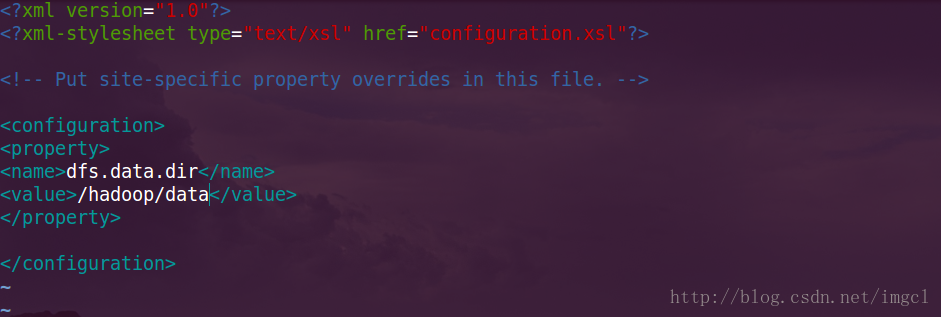
<property>
<name>dfs.data.dir</name>//文件系统的数据
<value>/hadoop/data</value>//放在这个目录下
</property>
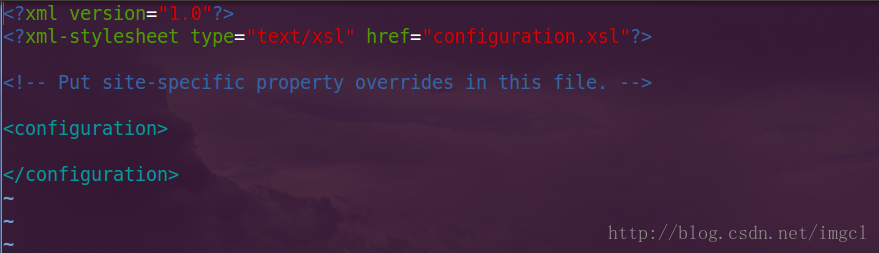
最后看第三个配置文件: mapred-site.xml ,用命令vim mapred-site.xml 进入文件,配置前的:
配置后的(注意:下图中的localhost为自己本机的名字比如我的就是:Cherise):
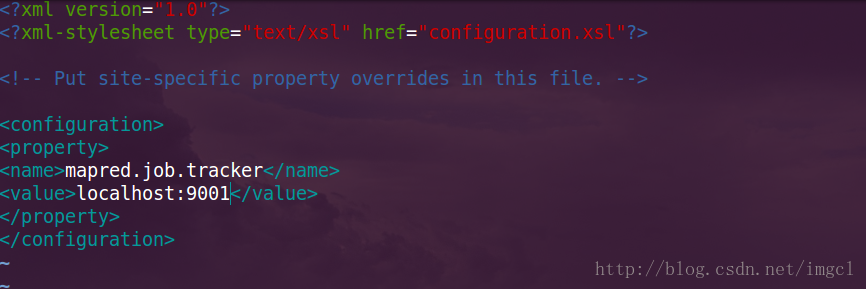
<property>
<name>mapred.job.tracker</name>//任务调度器该如何访问
<value>localhost:9001</value>//这样访问本机:端口号
</property>
到此,配置文件已经配置完毕!
然后我们还要告诉系统Hadoop安装到哪了
命令 vim /etc/profile
在配置环境变量的地方加上 HADOOP_HOME的路径配置,以及在PATH中加上$HADOOP_HOME/bin: 如下图所示:

温馨提示:保存之后记得生效,命令为:source /etc/profile
然后用hadoop命令看是否能找到Hadoop这个执行程序,也就是说看配置好着没有:
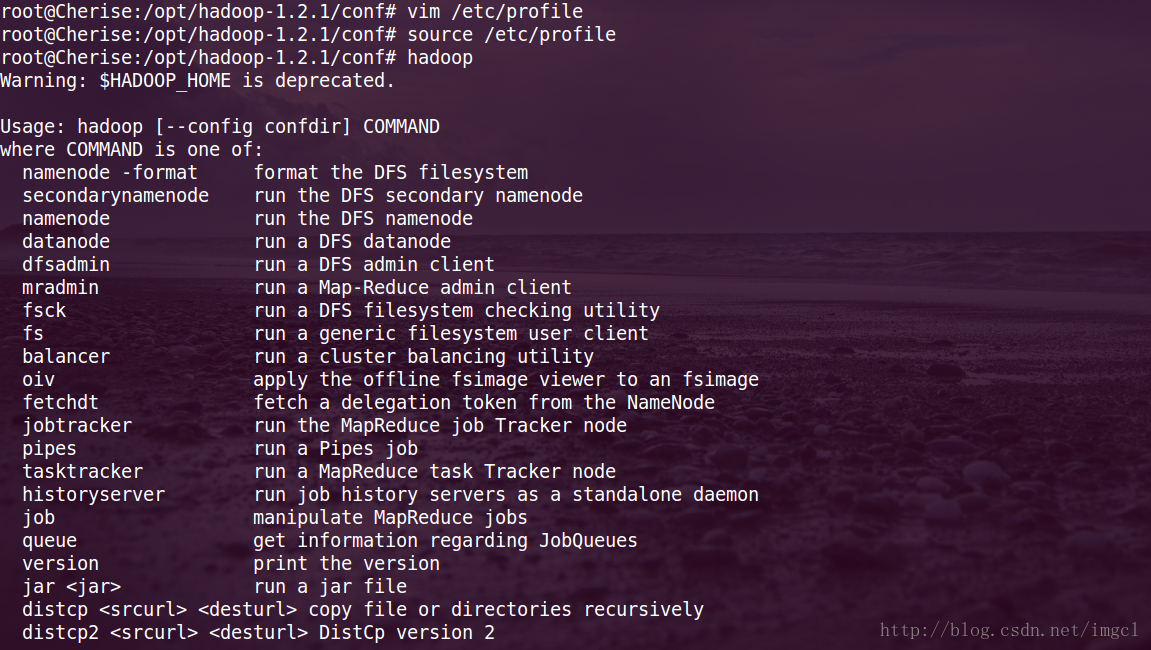
其实这个Hadoop的可执行程序在哪呢?如下图:

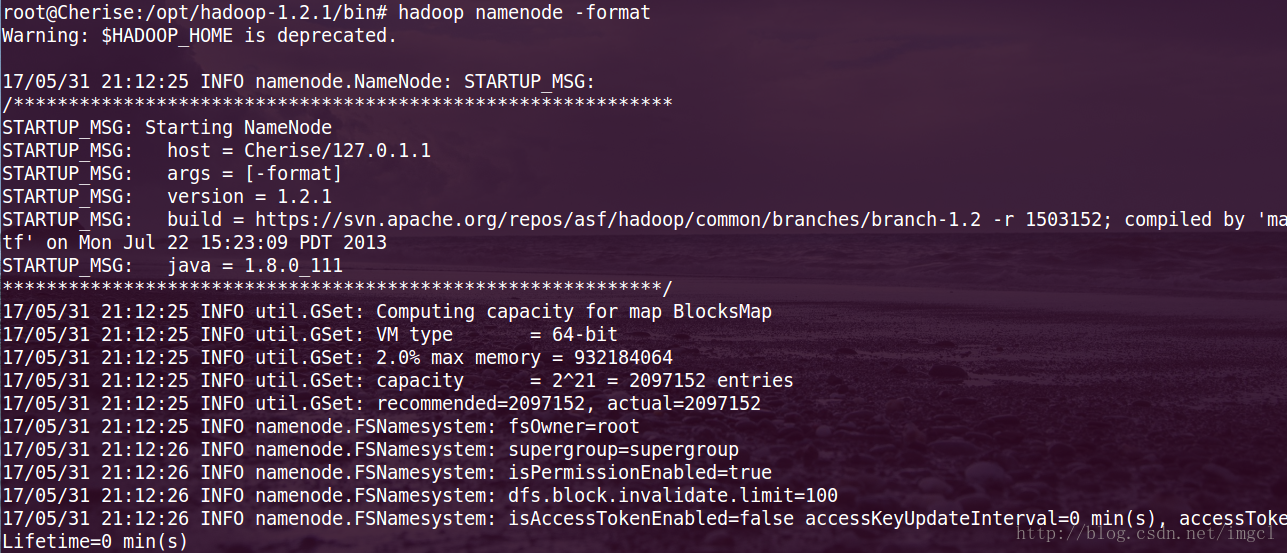
我们在执行之前需要对namenode先进行格式化操作,命令:hadoop namenode -format
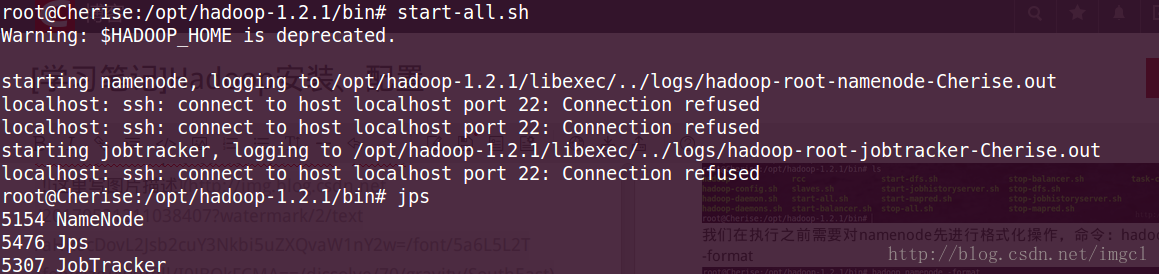
然后在任何地方都可以启动 start-all.sh 然后用jps 来查看Hadoop运行是否正常 ,如下图(如果有以下进程(红色框中的那6个进程)在运行则运行Hadoop运行正常):

看看Hadoop下面有什么文件系统

安装到此结束!
华丽分割线
安装小结
- 在linux下安装JDK,并设置环境变量 ,安装命令:apt-get install openjdk-7-jdk
- 在 /etc/profile中设置环境变量
- 下载Hadoop,并设置Hadoop的环境变量
修改4个配置文件。
a):修改hadoop-env.sh ,设置JAVA_HOME;
b):3个xml文件(都在hadoop-1.2.1目录下的conf目录下):
第一个:core-site.xml(设置属性 hadoop.tmp.dir、dfs.name.dir、fs.default.name)
第二个:hdfs-site.xml(设置属性 dfs.data.dir)
第三个:mapred-site.xml(设置属性 mapred.job.tracker)格式化 hadoop namenode -format
- 启动start-all.sh
- 用jps命令查看 hadoop是否安装成功














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









