









声明:代码的运行环境为Python3。Python3与Python2在一些细节上会有所不同,希望广大读者注意。本博客以代码为主,代码中会有详细的注释。相关文章将会发布在我的个人博客专栏《Python自然语言处理》,欢迎大家关注。
1、首先来看一个使用朴素贝叶斯分类器对性别进行分类鉴定的例子。
# 构造特征提取器
def gender_features(word): # 提取出字符串的最后一个字母
return {'last_letter': word[-1]}
names_set = ([(name, 'male') for name in names.words('male.txt')] +
[(name, 'female') for name in names.words('female.txt')]) # 获取语料库中人名的名称及性别
print(names_set[:10])
random.shuffle(names_set) # 随机打乱names_set中的名字
print(names_set[:10])
featuresets = [(gender_features(n), g) for (n, g) in names_set] # 选取特征集合
train_set, test_set = featuresets[500:], featuresets[:500] # 抽取训练数据和测试数据
classifier = nltk.NaiveBayesClassifier.train(train_set) # 朴素贝叶斯分类器
# 测试
classifier.classify(gender_features('Neo'))
classifier.classify(gender_features('Trinity'))查看测试结果:
'male'
'female'2、计算分类的正确率以及最有效的特征
# 分类正确率判断
print(nltk.classify.accuracy(classifier, test_set))
0.768
# 最有效的特征
classifier.show_most_informative_features(5) # 输出5个最有效的特征
Most Informative Features
last_letter = 'a' female : male = 40.2 : 1.0
last_letter = 'k' male : female = 30.8 : 1.0
last_letter = 'f' male : female = 16.6 : 1.0
last_letter = 'p' male : female = 11.9 : 1.0
last_letter = 'v' male : female = 9.8 : 1.0
3、当数据量很大时可以用如下方法进行数据集的划分。
# 大型数据时的数据集划分
from nltk.classify import apply_features
train_set = apply_features(gender_features, names_set[500:])
test_set = apply_features(gender_features, names_set[:500])4、贝叶斯公式及代码实现。
贝叶斯公式如下图所示:
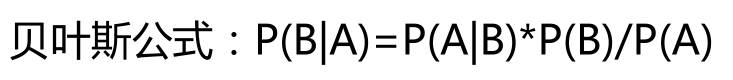
贝叶斯分类器为:

用代码的形式实现贝叶斯分类器:
# 手动计算贝叶斯分类器
# 计算P(特征|类别)
def f_c(data, fea, cla):
cfd = nltk.ConditionalFreqDist((classes, features) for (features, classes) in data)
return cfd[cla].freq(fea)
# 计算P(特征)
def p_feature(data, fea):
fd = nltk.FreqDist(fea for (fea, cla) in data)
return fd.freq(fea)
# 计算P(类别)
def p_class(data, cla):
fd = nltk.FreqDist(cla for (fea, cla) in data)
return fd.freq(cla)
# 计算P(类别│特征)
def res(data, fea, cla):
return f_c(data, fea, cla) * p_class(data, cla) / p_feature(data, fea)测试贝叶斯公式:
# 构造输入数据集
data = ([(name[-1], 'male') for name in names.words('male.txt')] +
[(name[-1], 'female') for name in names.words('female.txt')])
random.shuffle(data)
train, test = data[500:], data[:500]
# 计算Neo的为男性的概率
res(train, 'k', 'male')
res(train, 'a', 'female')测试结果为:
0.955223880597015
0.9829612220916567
5、选择正确的特征。
(1)过度拟合
# 过度拟合
def gender_features2(name):
features = {}
features["firstletter"] = name[0].lower()
features["lastletter"] = name[-1].lower()
for letter in 'abcdefghijklmnopqrstuvwxyz':
features["count(%s)" % letter] = name.lower().count(letter)
features["has(%s)" % letter] = (letter in name.lower())
return features
featuresets = [(gender_features2(n), g) for (n, g) in names_set]
train_set, test_set = featuresets[500:], featuresets[:500]
classifier = nltk.NaiveBayesClassifier.train(train_set)
print(nltk.classify.accuracy(classifier, test_set))结果:
0.76
(2)划分数据集,重新测试
# 数据划分为训练集、开发测试集、测试集
train_names = names_set[1500:]
devtest_names = names_set[500:1500]
test_names = names_set[:500]
# 重新训练模型
train_set = [(gender_features(n), g) for (n, g) in train_names]
devtest_set = [(gender_features(n), g) for (n, g) in devtest_names]
test_set = [(gender_features(n), g) for (n, g) in test_names]
classifier = nltk.NaiveBayesClassifier.train(train_set)
print(nltk.classify.accuracy(classifier, devtest_set))测试结果:
0.761
(3)将测试出错的元素打印出来
# 打印错误列表
errors = []
for (name, tag) in devtest_names:
guess = classifier.classify(gender_features(name))
if guess != tag:
errors.append((tag, guess, name))
for (tag, guess, name) in sorted(errors): # doctest: +ELLIPSIS +NORMALIZE_WHITESPACE
print('correct=%-8s guess=%-8s name=%-30s' % (tag, guess, name))结果:
correct=female guess=male name=Adelind
correct=female guess=male name=Aeriel
correct=female guess=male name=Aeriell
correct=female guess=male name=Ag
correct=female guess=male name=Aidan
correct=female guess=male name=Allsun
correct=female guess=male name=Anabel
correct=female guess=male name=Ardelis
correct=female guess=male name=Aryn
correct=female guess=male name=Betteann
correct=female guess=male name=Bill
correct=female guess=male name=Blondell
(4)重构特征,进行训练
# 重新构建特征
def gender_features(word):
return {'suffix1': word[-1:],
'suffix2': word[-2:]}
# 重新训练模型
train_set = [(gender_features(n), g) for (n, g) in train_names]
devtest_set = [(gender_features(n), g) for (n, g) in devtest_names]
classifier = nltk.NaiveBayesClassifier.train(train_set)
print(nltk.classify.accuracy(classifier, devtest_set))测试结果:
0.791
6、文档分类
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
# 文档分类特征提取器
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
word_features = all_words.most_common()[:2000]
def document_features(document):
document_words = set(document)
features = {}
for (word, freq) in word_features:
features['contains(%s)' % word] = (word in document_words)
return features
print(document_features(movie_reviews.words('pos/cv957_8737.txt')))
# 构造分类器
featuresets = [(document_features(d), c) for (d, c) in documents]
train_set, test_set = featuresets[100:], featuresets[:100]
classifier = nltk.NaiveBayesClassifier.train(train_set)
print(nltk.classify.accuracy(classifier, test_set))
print(classifier.show_most_informative_features(5))测试结果:
0.86
Most Informative Features
contains(outstanding) = True pos : neg = 10.4 : 1.0
contains(seagal) = True neg : pos = 8.7 : 1.0
contains(mulan) = True pos : neg = 8.1 : 1.0
contains(wonderfully) = True pos : neg = 6.3 : 1.0
contains(damon) = True pos : neg = 5.7 : 1.0
None
7、词性标注
# 词性标注
from nltk.corpus import brown
suffix_fdist = nltk.FreqDist()
for word in brown.words():
word = word.lower()
suffix_fdist[word[-1:]] += 1
suffix_fdist[word[-2:]] += 1
suffix_fdist[word[-3:]] += 1
common_suffixes = suffix_fdist.most_common()[:100]
print(common_suffixes)
# 定义特征提取器
def pos_features(word):
features = {}
for (suffix, freq) in common_suffixes:
features['endswith(%s)' % suffix] = word.lower().endswith(suffix)
return features
# 训练分类器
tagged_words = brown.tagged_words(categories='news')
featuresets = [(pos_features(n), g) for (n, g) in tagged_words]
size = int(len(featuresets) * 0.1)
train_set, test_set = featuresets[:1000], featuresets[2000:3000]
classifier = nltk.DecisionTreeClassifier.train(train_set)
print(nltk.classify.accuracy(classifier, test_set))
print(classifier.classify(pos_features('cats')))结果:
0.611
NNS
决策树输出:
# 决策树输出
print(classifier.pseudocode(depth=4))输出结果:
if endswith(he) == False:
if endswith(s) == False:
if endswith(.) == False:
if endswith(of) == False: return 'CD'
if endswith(of) == True: return 'IN'
if endswith(.) == True: return '.'
if endswith(s) == True:
if endswith(as) == False:
if endswith('s) == False: return 'NPS'
if endswith('s) == True: return 'NN$'
if endswith(as) == True:
if endswith(was) == False: return 'CS'
if endswith(was) == True: return 'BEDZ'
if endswith(he) == True:
if endswith(the) == False: return 'PPS'
if endswith(the) == True: return 'AT'
8、根据上下文构造特征提取器
# 根据上下文构造特征提取器
def pos_features(sentence, i):
features = {"suffix(1)": sentence[i][-1:],
"suffix(2)": sentence[i][-2:],
"suffix(3)": sentence[i][-3:]}
if i == 0:
features["prev-word"] = "<START>"
else:
features["prev-word"] = sentence[i - 1]
return features
pos_features(brown.sents()[0], 8)
tagged_sents = brown.tagged_sents(categories='news')
featuresets = []
for tagged_sent in tagged_sents:
untagged_sent = nltk.tag.untag(tagged_sent)
for i, (word, tag) in enumerate(tagged_sent):
featuresets.append((pos_features(untagged_sent, i), tag))
size = int(len(featuresets) * 0.1)
train_set, test_set = featuresets[size:], featuresets[:size]
classifier = nltk.NaiveBayesClassifier.train(train_set)
nltk.classify.accuracy(classifier, test_set)结果:
0.7891596220785678
9、序列分类
# 序列分类
# 定义特征提取器
def pos_features(sentence, i, history):
features = {"suffix(1)": sentence[i][-1:],
"suffix(2)": sentence[i][-2:],
"suffix(3)": sentence[i][-3:]}
if i == 0:
features["prev-word"] = "<START>"
features["prev-tag"] = "<START>"
else:
features["prev-word"] = sentence[i - 1]
features["prev-tag"] = history[i - 1]
return features
# 构建序列分类器
class ConsecutivePosTagger(nltk.TaggerI):
def __init__(self, train_sents):
train_set = []
for tagged_sent in train_sents:
untagged_sent = nltk.tag.untag(tagged_sent)
history = []
for i, (word, tag) in enumerate(tagged_sent):
featureset = pos_features(untagged_sent, i, history)
train_set.append((featureset, tag))
history.append(tag)
self.classifier = nltk.NaiveBayesClassifier.train(train_set)
def tag(self, sentence):
history = []
for i, word in enumerate(sentence):
featureset = pos_features(sentence, i, history)
tag = self.classifier.classify(featureset)
history.append(tag)
return zip(sentence, history)
tagged_sents = brown.tagged_sents(categories='news')
size = int(len(tagged_sents) * 0.1)
train_sents, test_sents = tagged_sents[size:], tagged_sents[:size]
tagger = ConsecutivePosTagger(train_sents)
print(tagger.evaluate(test_sents))结果:
0.7980528511821975
10、句子分割
# 句子分割
# 获取已分割的句子数据
sents = nltk.corpus.treebank_raw.sents()
tokens = []
boundaries = set()
offset = 0
for sent in nltk.corpus.treebank_raw.sents():
tokens.extend(sent)
offset += len(sent)
boundaries.add(offset - 1)
# 定义特征提取器
def punct_features(tokens, i):
return {'next-word-capitalized': tokens[i + 1][0].isupper(),
'prevword': tokens[i - 1].lower(),
'punct': tokens[i],
'prev-word-is-one-char': len(tokens[i - 1]) == 1}
# 定义标注
featuresets = [(punct_features(tokens, i), (i in boundaries))
for i in range(1, len(tokens) - 1)
if tokens[i] in '.?!']
# 构建分类器
size = int(len(featuresets) * 0.1)
train_set, test_set = featuresets[size:], featuresets[:size]
classifier = nltk.NaiveBayesClassifier.train(train_set)
nltk.classify.accuracy(classifier, test_set)结果:
0.936026936026936
基于分类的断句器:
# 基于分类的断句器
def segment_sentences(words):
start = 0
sents = []
for i, word in words:
if word in '.?!' and classifier.classify(words, i) == True:
sents.append(words[start:i + 1])
start = i + 1
if start < len(words):
sents.append(words[start:])11、识别对话行为类型
# 识别对话行为类型
posts = nltk.corpus.nps_chat.xml_posts()[:10000]
# 定义特征提取器
def dialogue_act_features(post):
features = {}
for word in nltk.word_tokenize(post):
features['contains(%s)' % word.lower()] = True
return features
# 训练分类器
featuresets = [(dialogue_act_features(post.text), post.get('class'))
for post in posts]
size = int(len(featuresets) * 0.1)
train_set, test_set = featuresets[size:], featuresets[:size]
classifier = nltk.NaiveBayesClassifier.train(train_set)
print(nltk.classify.accuracy(classifier, test_set))
结果:
0.668
12、评估
(1)准确度
####评估####
# 创建训练集与测试集
import random
from nltk.corpus import brown
tagged_sents = list(brown.tagged_sents(categories='news'))
random.shuffle(tagged_sents)
size = int(len(tagged_sents) * 0.1)
train_set, test_set = tagged_sents[size:], tagged_sents[:size]
# 使用同类型文件
file_ids = brown.fileids(categories='news')
size = int(len(file_ids) * 0.1)
train_set = brown.tagged_sents(file_ids[size:])
test_set = brown.tagged_sents(file_ids[:size])
# 使用不同类型文件
train_set = brown.tagged_sents(categories='news')
test_set = brown.tagged_sents(categories='fiction')
##准确度##
names_set = ([(name, 'male') for name in names.words('male.txt')] +
[(name, 'female') for name in names.words('female.txt')])
random.shuffle(names_set)
featuresets = [(gender_features(n), g) for (n, g) in names_set]
train_set, test_set = featuresets[500:], featuresets[:500]
classifier = nltk.NaiveBayesClassifier.train(train_set)
print('Accuracy: %4.2f' % nltk.classify.accuracy(classifier, test_set))结果:
Accuracy: 0.78
(2)精确度与召回率
##精准度与召回率##
from sklearn.metrics import classification_report
test_set_fea = [features for (features, gender) in test_set]
test_set_gen = [gender for (features, gender) in test_set]
pre = classifier.classify_many(test_set_fea)
print(classification_report(test_set_gen, pre))结果:
precision recall f1-score support
female 0.83 0.82 0.83 316
male 0.70 0.71 0.70 184
avg / total 0.78 0.78 0.78 500
(3)混淆矩阵
##混淆矩阵##
cm = nltk.ConfusionMatrix(test_set_gen, pre)
print(cm)结果:
| f |
| e |
| m m |
| a a |
| l l |
| e e |
-------+---------+
female |<260> 56 |
male | 54<130>|
-------+---------+
(row = reference; col = test)
(4)决策树中的熵和信息增益
# 熵和信息增益
import math
def entropy(labels):
freqdist = nltk.FreqDist(labels)
probs = [freqdist.freq(l) for l in nltk.FreqDist(labels)]
return -sum([p * math.log(p, 2) for p in probs])
print(entropy(['male', 'male', 'male', 'male']))
-0.0
print(entropy(['male', 'female', 'male', 'male']))
0.8112781244591328
print(entropy(['female', 'male', 'female', 'male']))
1.0
print(entropy(['female', 'female', 'male', 'female']))
0.8112781244591328
print(entropy(['female', 'female', 'female', 'female']))
-0.0
















 7223
7223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











