






上一篇学习完 SQL 语句在 Server 层流转的过程,这一篇我们学习 MySQL 语句执行流程中存储引擎层的部分,本篇学习使用的存储引擎是 InnoDB
MySQL InnoDB 存储引擎层架构
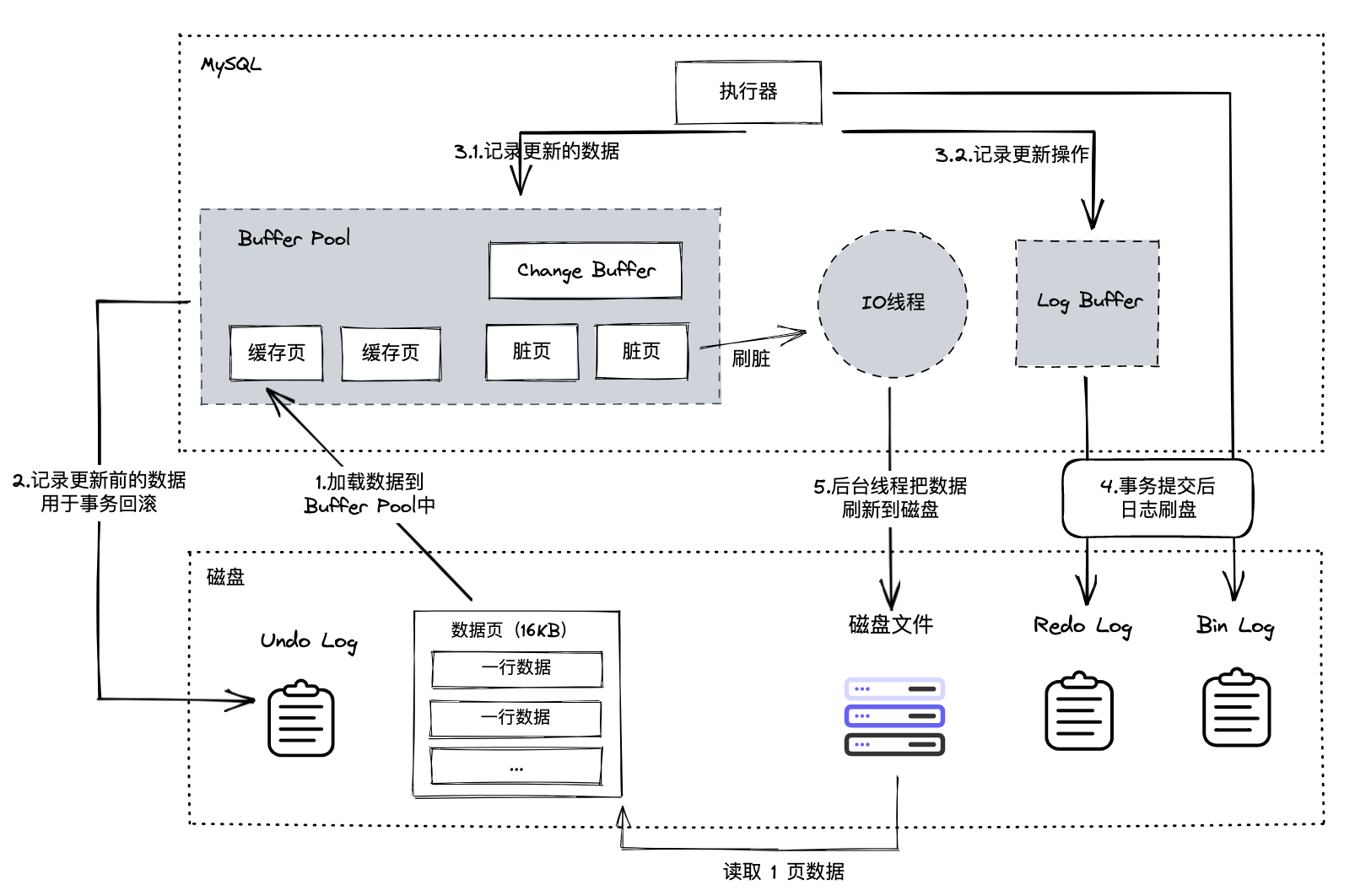
MySQL SQL 语句在 InnoDB 存储引擎层中的流转大概如上图,从行为角度分可以细分成读与写两类行为,下面针对这两个行为做分析
直接读写磁盘
在 MySQL 中,存储引擎负责数据存储、数据读取、数据更新,但是数据实际上存在磁盘中。因此无论是哪一款存储引擎,当客户端需要对数据进行修改时,都需要先把数据从磁盘中加载到内存中,数据操作完成后,把内存中的数据再写回到磁盘中。
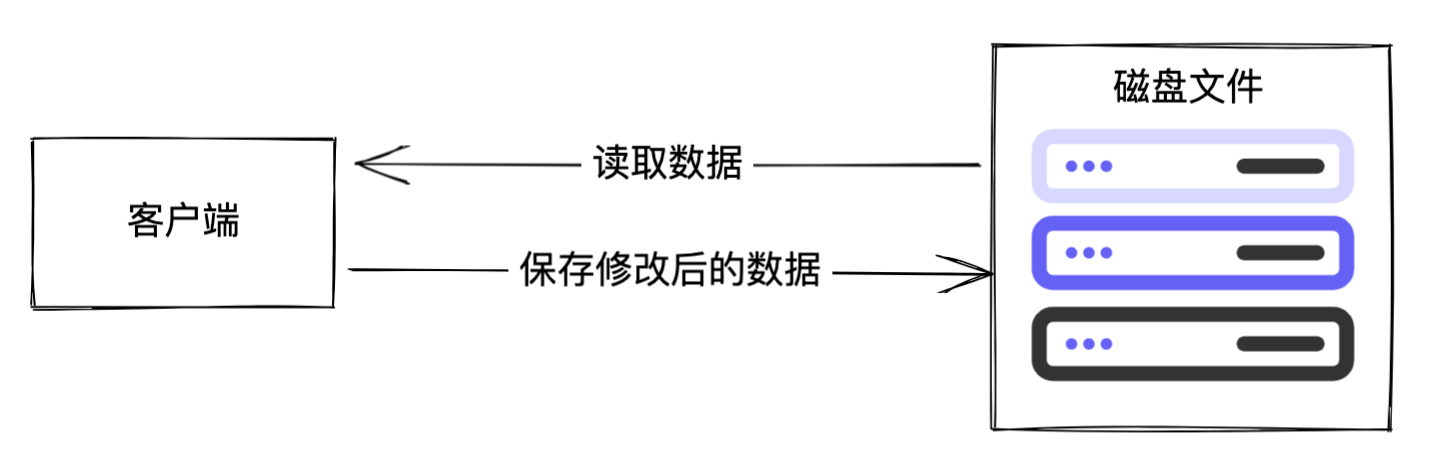
显然这种做法是不太合理的,多个更新操作都直接操作磁盘,由于磁盘 IO 效率不高,导致性能低下。
Buffer Pool
直接操作磁盘文件效率不高这么简单的问题我们能想到,MySQL 的设计者自然也考虑到了。所以在客户端与磁盘文件中间设计了一个 Buffer Pool ,专门用于更新数据使用的缓冲池,毕竟操作内存的效率还是要比操作磁盘更高。
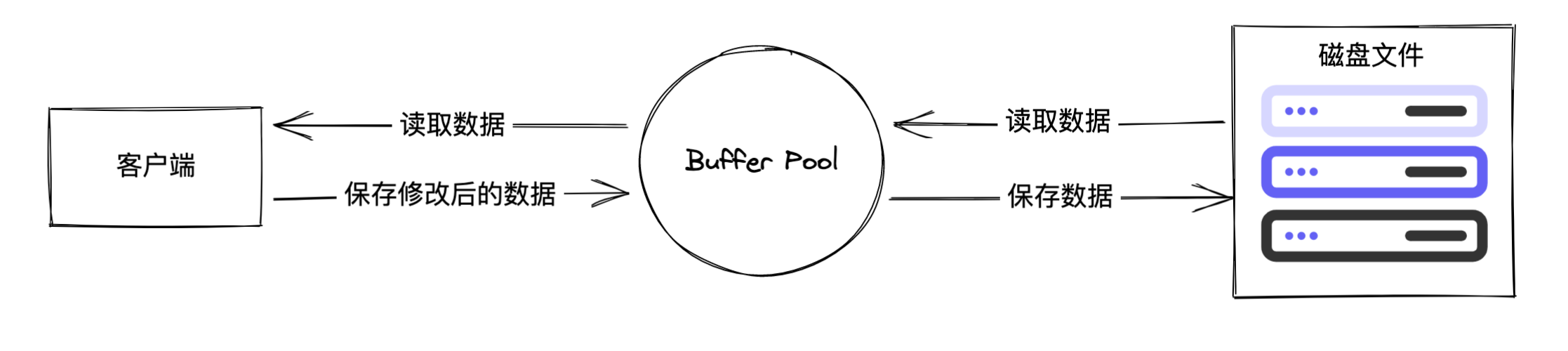
读取数据:如果数据存在 Buffer Pool,则直接从 Buffer Pool 中读取;如果不存在,则从磁盘读取数据,再写入到 Buffer Pool 中。
写入数据:数据先写入 Buffer Pool,然后根据配置的持久化策略,把数据写入到磁盘文件中。
这种做法尽可能地避免了客户端直接和磁盘进行 IO,Buffer Pool 的加入提升了读写性能。
缓存预读机制
Buffer Pool 的加入的确能有效提升读写效率,但是我们还需要考虑一个问题:每次从磁盘中读取多少数据到 Buffer Pool 中?对于一次客户端的更新操作,可能只需要读取少量字节的数据,每次客户端需要多少字节就从磁盘中读取多少字节,这显然不合理,因为磁盘 IO 效率低,特别是磁盘的随机读做操。
根据局部性原理,往往一块需要使用的数据,它附近位置的数据可能也会马上被用到,所以缓存需要一个预读机制,一次性读取多一点数据到 Buffer Pool 中,在数据交互时,可以尽量减少磁盘 IO 的次数,使用到了一个空间换时间的思想。
我们后面讨论的基础都建立在使用 InnoDB 存储引擎上。
InnoDB 中数据的最小单位是页,一页数据的大小是 16 KB,所以从磁盘文件中读取数据写入 Buffer Pool 中也是以页为单位。缓存中的页会对应一份元数据,这个元数据包含数据页的编号,数据页在 Buffer Pool 中的地址等信息。
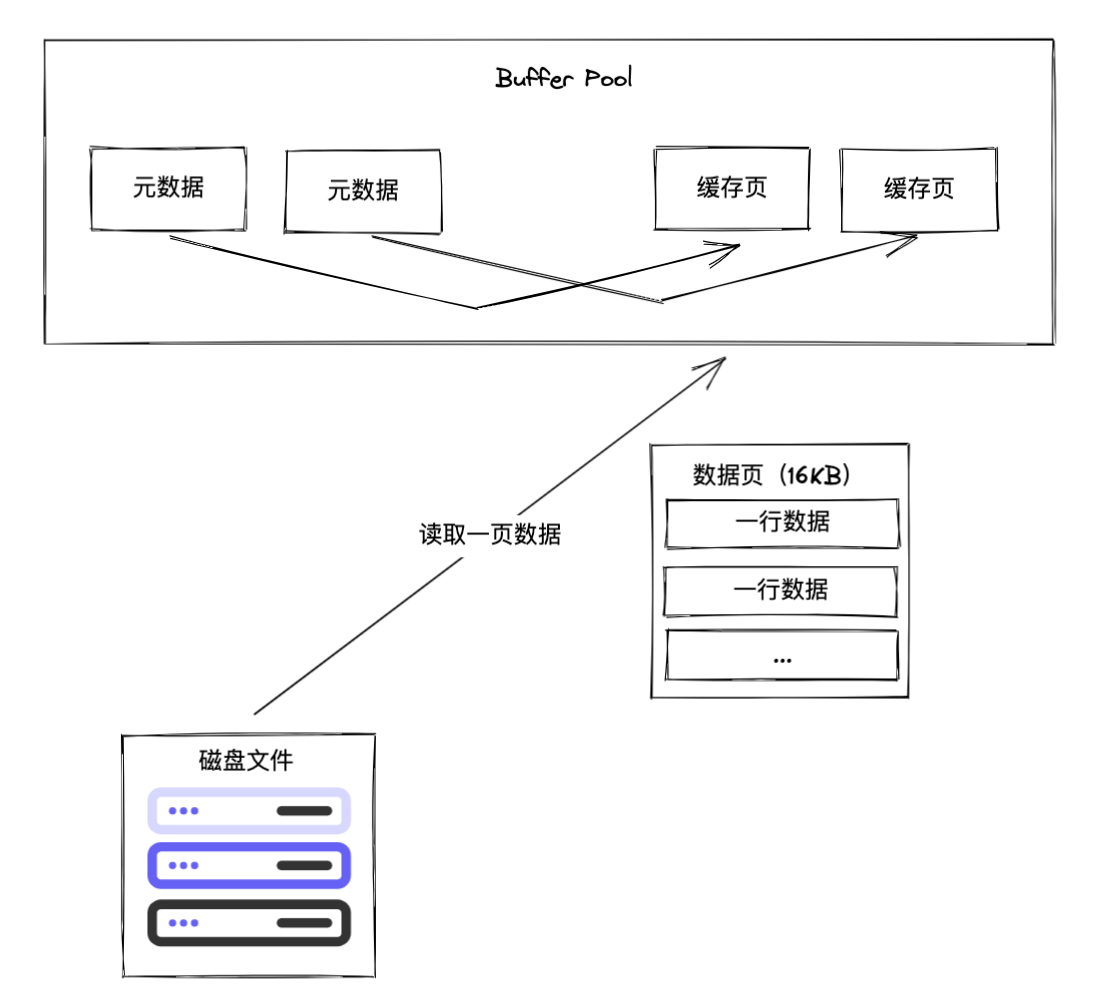
其中 InnoDB 使用两种预读算法来提升 IO 的效率:线性预读和随机预读。介绍这两种预读算法前,我们先了解一下 InnoDB 数据存储的逻辑结构图
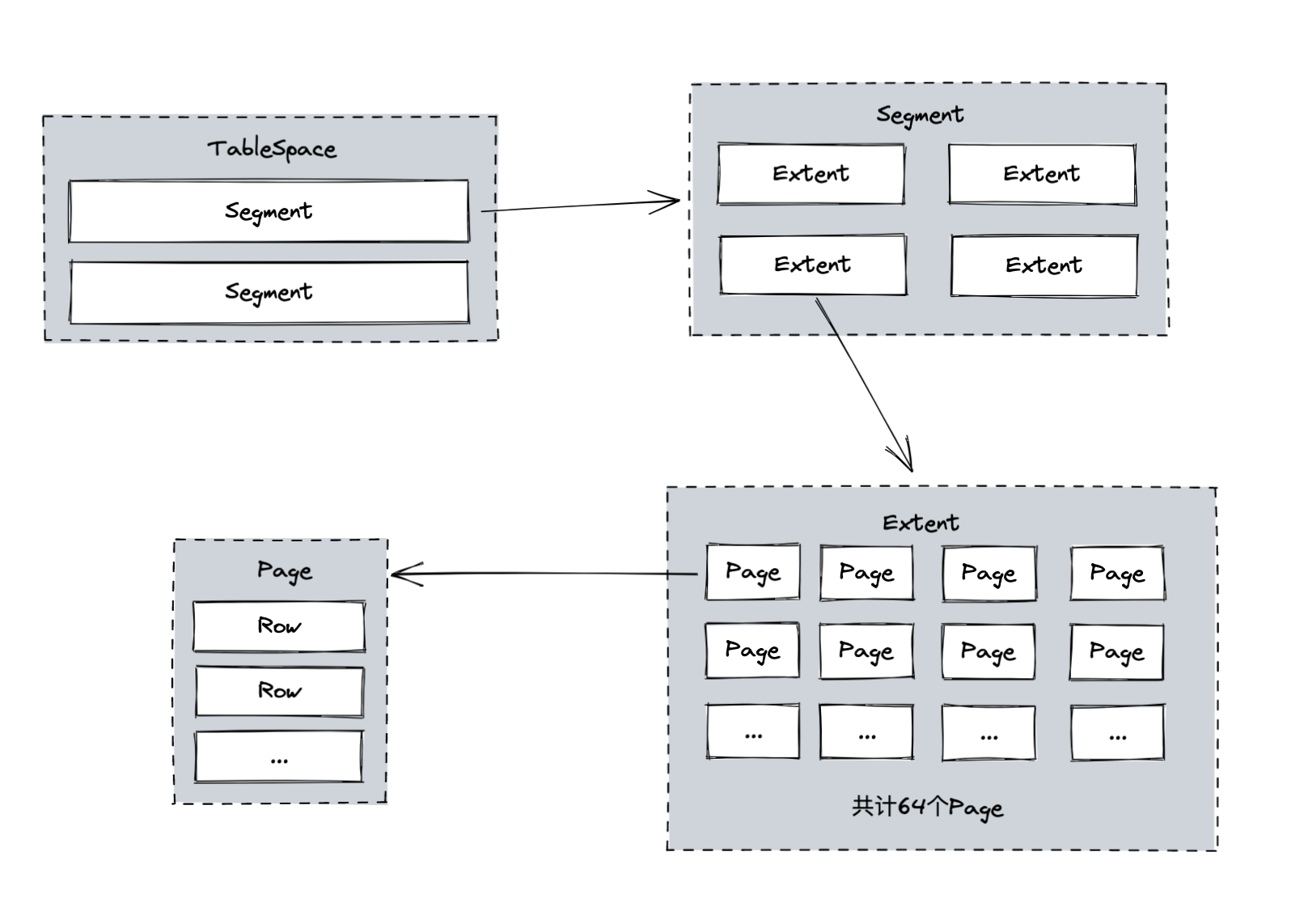
我们重点关注 Extent 和 Page,一个 Extent 包含了 64 个 Page,Page 是 InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。
线性预读
当我们读取一个 Extent 中的 Page 的数量达到了 innodb_read_ahead_threshold (默认56)个时,提前加载下一个 Extent 的数据到 Buffer Pool 中。方便后面数据访问时可以直接访问 Buffer Pool,不需要再访问磁盘。
随机预读
当 Buffer Pool 中缓存的 Page 的数量达到了 13 个时( innodb_random_read_ahead 参数控制此行为是否开启),提前把当前正在读取的 Extent 中剩下的所有 Page 读取到 Buffer Pool 中。方便访问后面的 Page 时可以直接访问 Buffer Pool。
缓存管理
有了预读机制后,我们的缓存池的作用得到了进一步的发挥,通过减少数据交互时的磁盘 IO 次数,达到提升数据操作性能的目的。此时我们同样需要考虑一个问题,Buffer Pool 默认大小是 128 M,虽然我们可以通过修改配置来增大这个空间,但是 Buffer Pool 的空间总是有限的,缓存池空间大小总是有限制的,如果缓存页中加载了非常多的数据导致缓存池耗尽了怎么处理呢?
链表
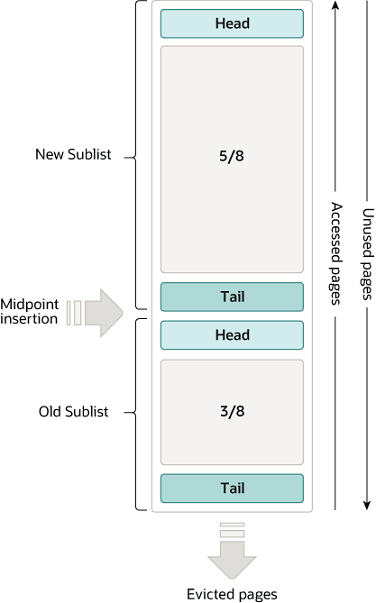
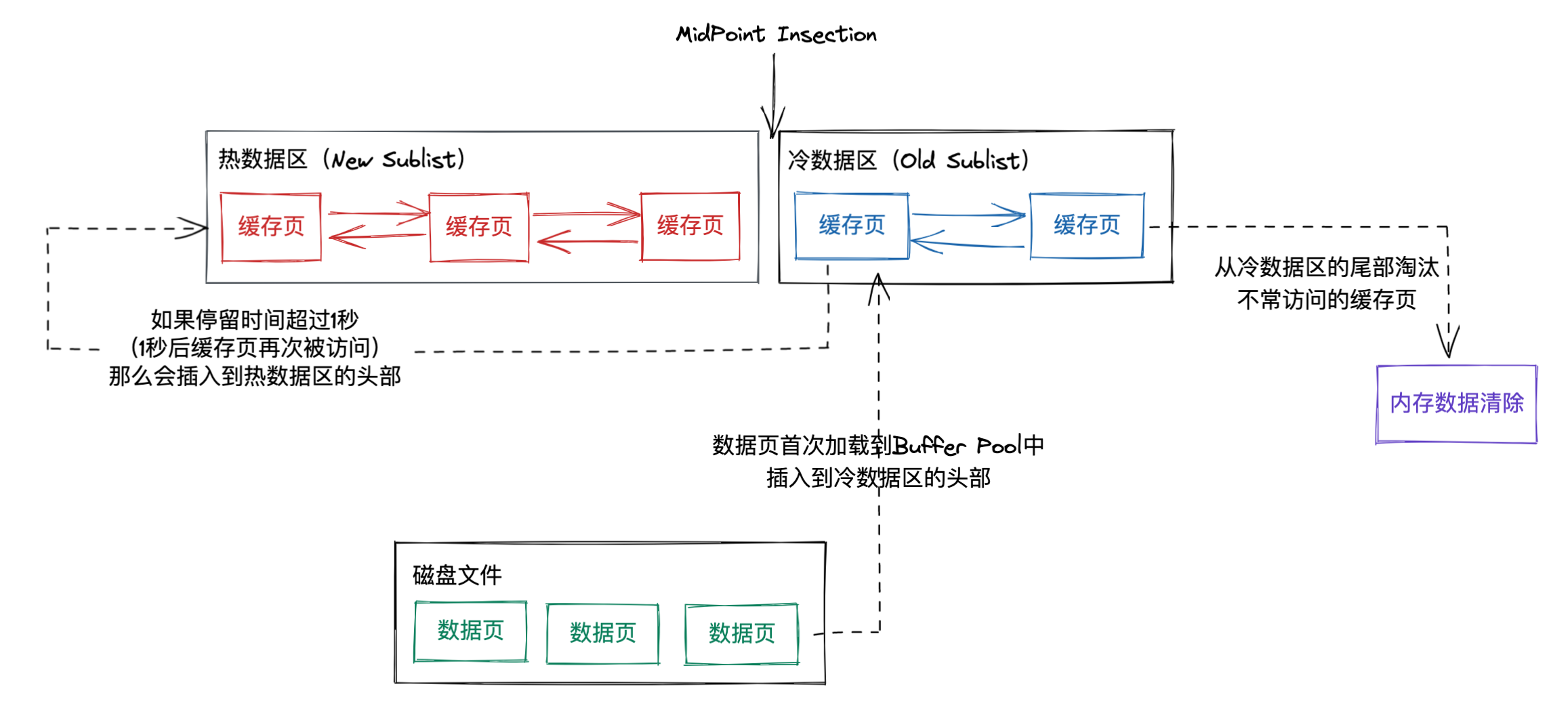
InnoDB 使用的是一种 LRU 的变体算法将缓冲池作为一个链表进行管理,当需要对 Buffer Pool 进行内存淘汰时,最近最少使用的缓存页将会被清除。使用 midpoint 把数据划分为冷数据区和热数据区。New Sublist:热数据区;Old Sublist:冷数据区。
无论是预读还是普通读取,所有数据页读取到 Buffer Pool 中时,都使用头插法插入到冷数据区中,更早的数据往 Tail 方向挪动。当冷数据区中的数据被访问,那么这份数据会移动到热数据区中,没有被访问到的数据会转移到冷数据区中,当实现内存淘汰时,会把冷数据区中 Tail 部分的数据淘汰掉。读取到 Buffer Pool 的数据页先放在冷数据区,避免了预读机制的存在导致热数据区的数据被冲掉。
默认热数据区和冷数据区大小比例是 5:3,通过参数 innodb_old_blocks_pct 来控制。冷数据区的占比越小,会使得冷数据区没有被访问的数据的淘汰速度更快,在生产环境中,内存足够大时,会尽量把这个数值调低,尽量避免热数据被淘汰。
热数据转移规则
假设我们现在执行了一条不带索引不带 limit 的查询语句
select * from account;
由于这条语句没有使用索引,所以会进行全表扫描,但是这种查询很多时候都是短时间内只访问一 次,但是后面基本上都不会用到的。
假设这些数据被访问一次就导致它从冷数据区转移到热数据区中,热数据区中的热点数据被转移到冷数据区中,当发生内存淘汰时,位于冷数据区中的“原来的热点数据”就被清除出内存,导致 Buffer Pool 中全是一些低频访问的冷数据,这大大降低了缓存的命中率,无法充分发挥缓存的作用。
这种情况很常见,同时 InnoDB 的设计者也考虑到了这个问题,所以 InnoDB 定义了冷数据转移到热数据的规则:如果这个数据页在 LRU 链表中冷数据区存在的时间超过了 1 秒,就把它移动到热数据区,这个时间可以通过参数 innodb_old_blocks_time 来进行控制。
因为通过预读机制和全表扫描加载到冷数据区中的数据,通常在 1 秒内会加载并且完成对他们的访问,它们会放在冷数据区等待清空,不会有太多机会进入热数据区;如果 1 秒后还有其他操作对它进行了访问,那说明确实有多个场景要对他进行操作,才会放入到热数据区的头部。
所以 Buffer Pool 中的 LRU 算法整体原理是这样的:
至此,MySQL 更新数据中读取部分介绍完毕
Buffer Pool 的数据刷盘
上面从 Buffer Pool 的由来到预读机制再到内存淘汰,其实侧重点是从磁盘中读取数据加载到内存中,基本上解决了大部分其中的问题;接下来我们看一下操作完读取出来的数据后,Buffer Pool 是如何把这些更新后的数据写入到磁盘文件中的。
当内存中的数据和磁盘中的数据不一致时,我们称内存中的数据为脏数据;把内存中的数据写入到磁盘中的这个过程我们称为刷脏。从这方面也能看出,内存和磁盘,可靠的其实是磁盘数据。
刷脏触发
MySQL 在以下场景会触发刷脏动作
-
当 redo log 写满了,先停止所有更新操作,将 checkpoint 向前推进,推进那部分日志的脏页更新到磁盘
-
系统内存不够,需要将一部分数据页淘汰,如果是干净页就直接淘汰;如果是脏页就需要全部同步到磁盘
-
MySQL 正常关闭 之前,由于不能导致内存中的数据丢失,在正常关闭前也会把脏页更新到磁盘中
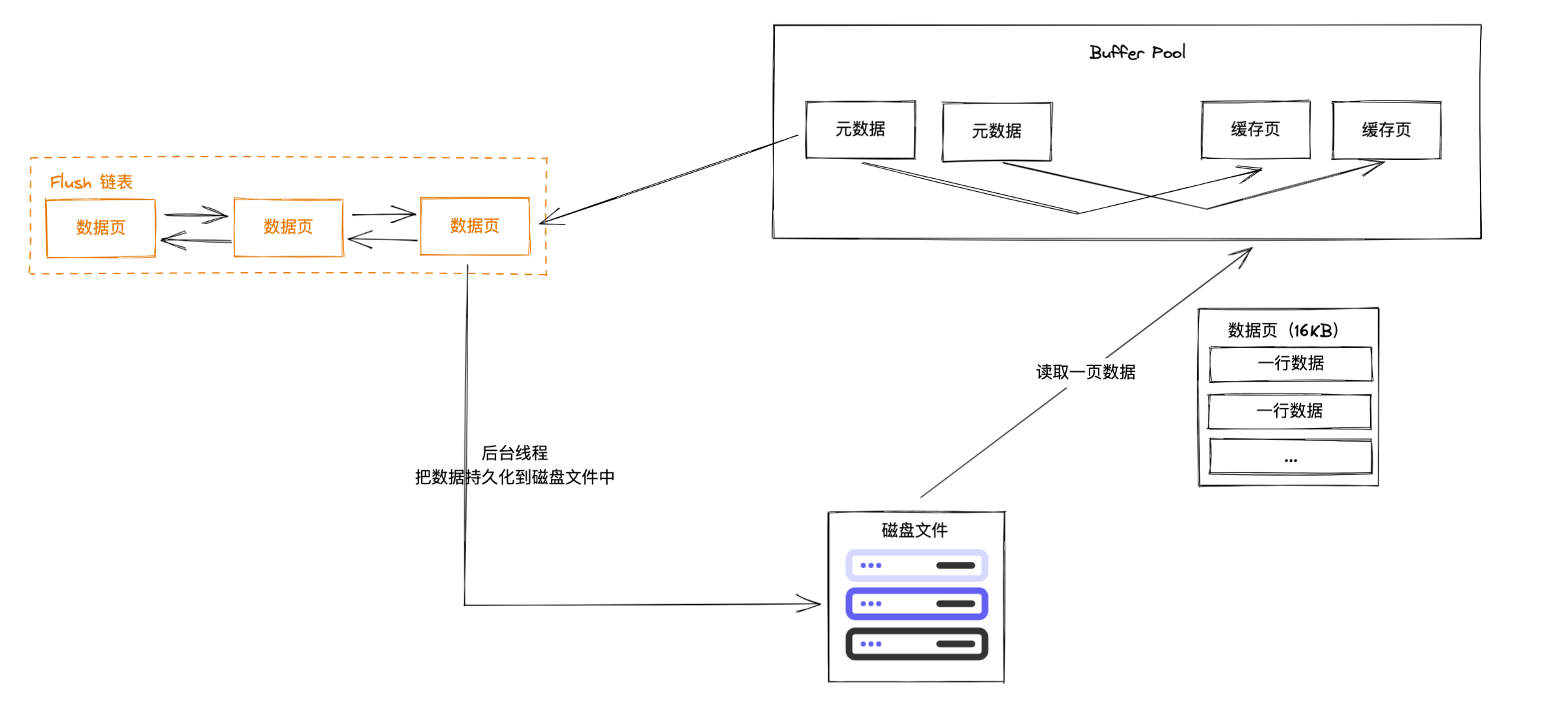
Flush 链表
Buffer Pool 中需要更新到磁盘中的数据是修改过的数据,Buffer Pool 中存在着预读机制加载进来的数据,全部更新同步一遍显然不合理,所以 Buffer Pool 使用了 Flush 链表来记录修改过的数据。
Flush 链表中记录着修改过的数据页,后台线程会按配置的策略把数据进行持久化到磁盘中。
Change Buffer
Buffer Pool 中还有一块区域叫 Change Buffer,主要的作用也是提高读写效率,在更新数据时可以把更新的值缓存下来,先不进行数据更新,减少磁盘 IO 次数
原理
当需要更新一个数据页时
- 如果这个数据页已经缓存在 Buffer Pool 中,那么直接对这个缓存页进行修改
- 如果这个数据页不在 Buffer Pool 中,不需要再去磁盘中读取数据页而产生随机读磁盘 IO,直接把需要修改成的值缓存到 Change Buffer 这一块区域中。等待下次需要访问这个数据页 / 预读机制把这个数据页加载到 Buffer Pool 中时,进行 merge (合并)操作
Change Buffer 触发 merge 的情况
- 访问这个数据页
- 后台 IO 线程定时把 Change Buffer merge 到磁盘中
- Buffer Pool 空间不足时,为了保证热数据区的数据,把修改 merge 了腾出空间
- 数据库正常关闭
Change Buffer 规则
如果本次操作操作了唯一索引,那么这个操作就不能使用 Change Buffer 了,因为需要保证数据的唯一性,需要把数据都读到内存中进行比对看看是否违反了唯一索引的约束,如果把数据都已经读入到内存中了,那么 Change Buffer 自然也就没有意义了,所以唯一索引的更新不能使用 Change Buffer
其他情况下都可以正常使用 Change Buffer 来提升效率
Redo Log
上面介绍了 Buffer Pool 如何存储改动的数据,后续数据的持久化是由一个异步的线程来完成,因此这里会存在一个问题,当数据页记录到 Flush 链表后,在后台线程进行持久化前,如果数据库奔溃了,这些内存中的数据就无法完成持久化了。(因为 InnoDB 的事务操作是需要保证持久性的)
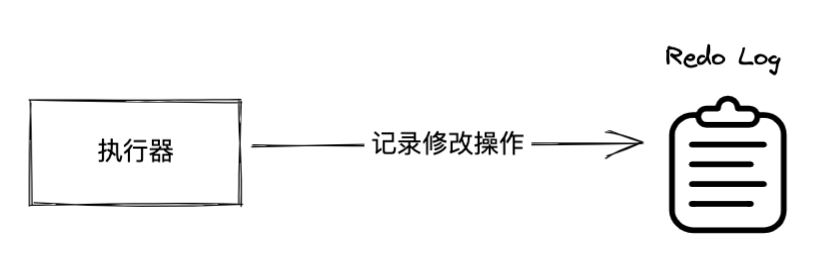
所以 Buffer Pool 为了避免这个问题,把这些数据的修改都先记录到了 Redo Log 这个日志文件中。一旦数据库崩溃,内存中的数据还没及时刷到磁盘中,数据库在启动时就会去读取 Redo Log 中之前做过的未保存的操作,重新执行一遍,从而实现数据恢复,这就是事务持久性的保障机制。
Log Buffer
从 Buffer Pool 的诞生可以看出,直接读写磁盘文件的效率是很低的,所以设计中往往会在中间加入一个缓存,Log Buffer 就是这个角色,它里面保存了需要写入数据库的修改内容,默认大小 16M,通过参数 innodb_log_buffer_size 来控制。

由于 Redo Log 记录的是 DML 操作,而不是数据页,因此空间足够的 Log Buffer 可以容纳大事务中的多个 DML 操作,并把这些操作合并,可以使得最终刷到日志文件中的数据量减少,同时也可以减少刷盘次数,减少磁盘 IO,从而提升性能。
另外 Redo Log 的写入方式是顺序写,比随机写的效率更高,所以 Redo Log 使用了顺序写 + Log Buffer 这两个手段来提升效率。
Log Buffer 刷盘机制
刷盘,写入日志文件这个操作其实用户线程是没办法完全实现的,是需要调用操作系统内核方法帮助我们实现,所以 Log Buffer 刷盘其实是有 3 步走
- 事务提交时修改操作写入内存中的 Log Buffer
- Log Buffer 中的数据写入 Redo Log 在操作系统中的文件系统缓存(Page Cache)
- 文件系统缓存刷盘(fsync),完成磁盘写入
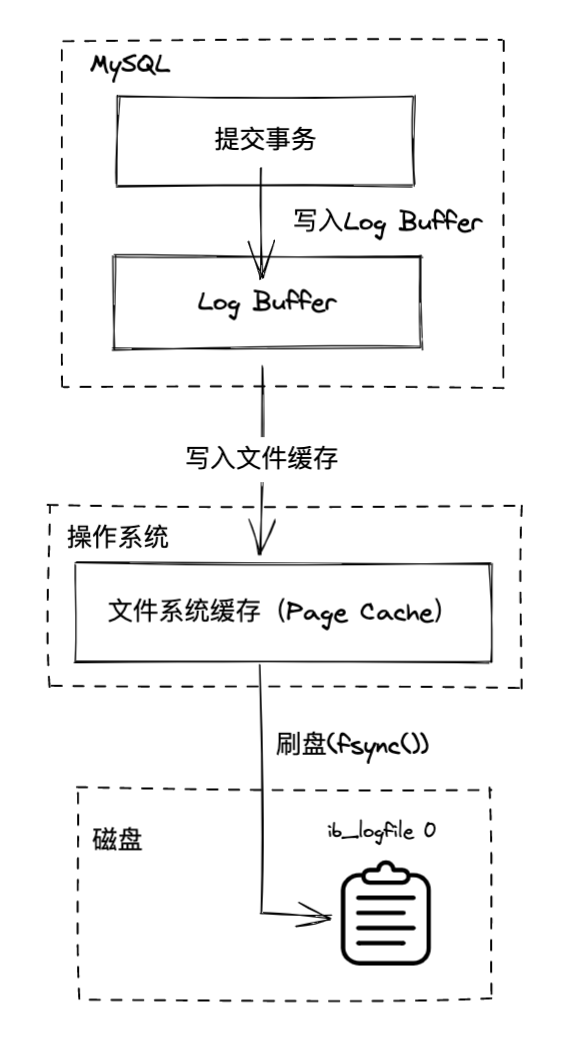
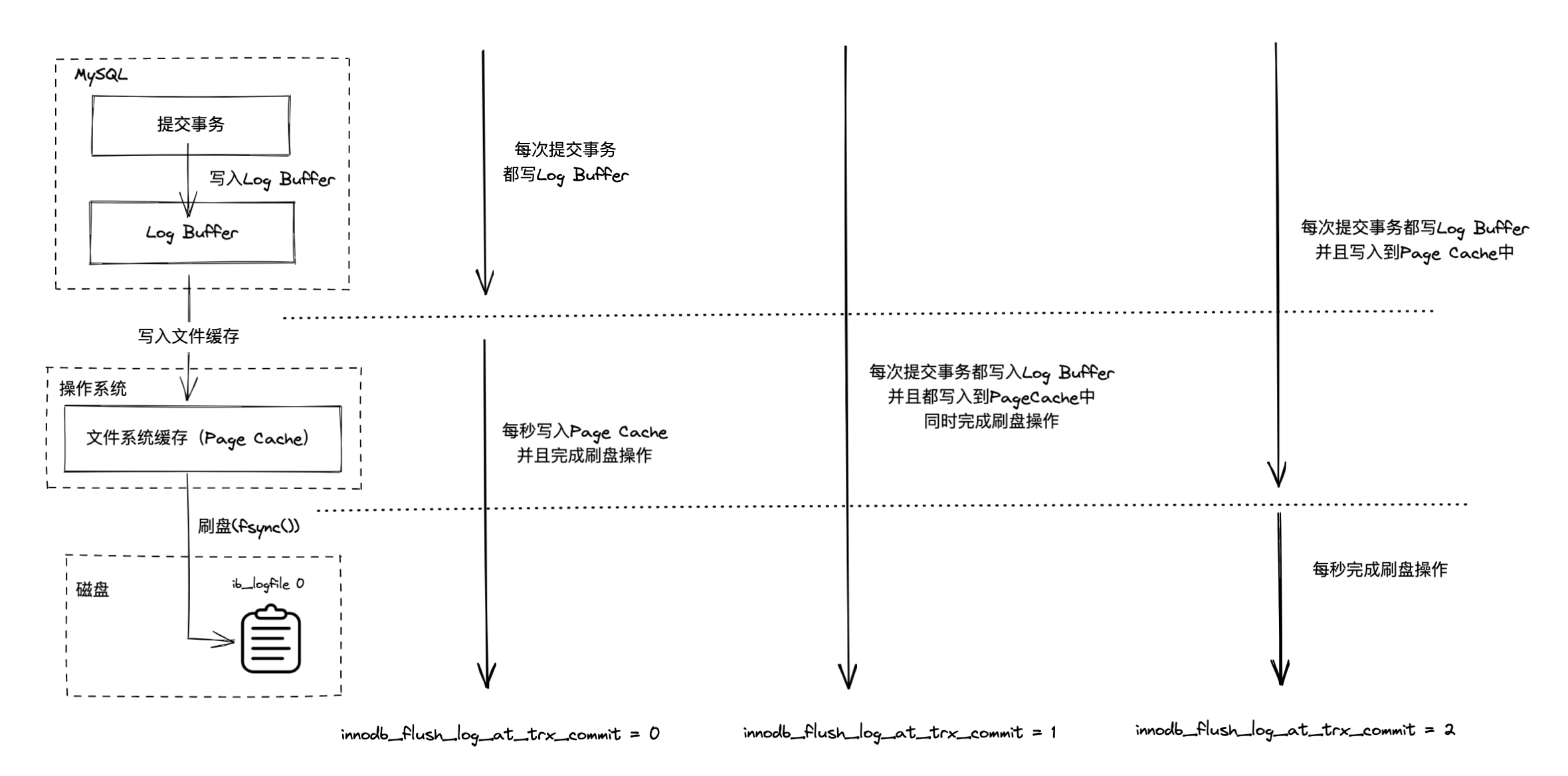
所以 Log Buffer 刷盘机制会围绕这 3 步的开展,MySQL 提供了一个参数 innodb_flush_log_at_trx_commit 来根据不同的场景来设置不同的值来满足需求。
- 0:每次提交事务时把修改操作写入到 Log Buffer 中,后台线程每秒一次把 Log Buffer 的内容写入到 Redo Log 中,同时也完成刷盘。这个策略的性能是最佳的,因为主线程的操作都是操作内存中的数据,但是如果 MySQL 出现崩溃,会存在 1 秒的数据丢失。
- 1:每次提交事务时既把修改操作写入到 Log Buffer 中,又把 Log Buffer 中的内容写入到 Redo Log 中同时完成刷盘。这是 MySQL 的默认刷盘策略,这种策略能保证内存硬盘数据的一致性,但是牺牲了部分性能。
- 2:每次提交事务时把修改操作写入到 Log Buffer 中,同时把 Log Buffer 中的内容写入到 Redo Log 中,但是先不进行刷盘,而是等待后台线程每秒执行一次刷盘操作。这种策略,如果操作系统出现崩溃,也可能会存在 1 秒的数据丢失。
三种策略的示意图:
Binlog
前面已经介绍过 Binlog 是 MySQL Server 层自己维护的一份二进制日志,主要的功能是主从同步与数据恢复,另外如果开启了 Binlog 的话,在事务提交时需要保证 Redo Log 和 Binlog 同时成功写入
Redo Log 和 Binlog 双写保证
前面提到 Binlog 有主从复制和数据恢复的功能,所以在数据更新时也要把操作记录到 Binlog 上,当事务提交时就需要同时写入 Redo Log 和 Binlog,Redo Log 保证了主库的数据恢复,Binlog 保证了从库的数据同步,任何一份日志写入失败都有数据不一致的风险,如何保证这两份日志都成功写入呢?
为了解决这个问题,InnoDB 设计了更新语句两阶段提交,采用的模式类似于分布式事务中 2PC 解决方案,遵循 XA 协议
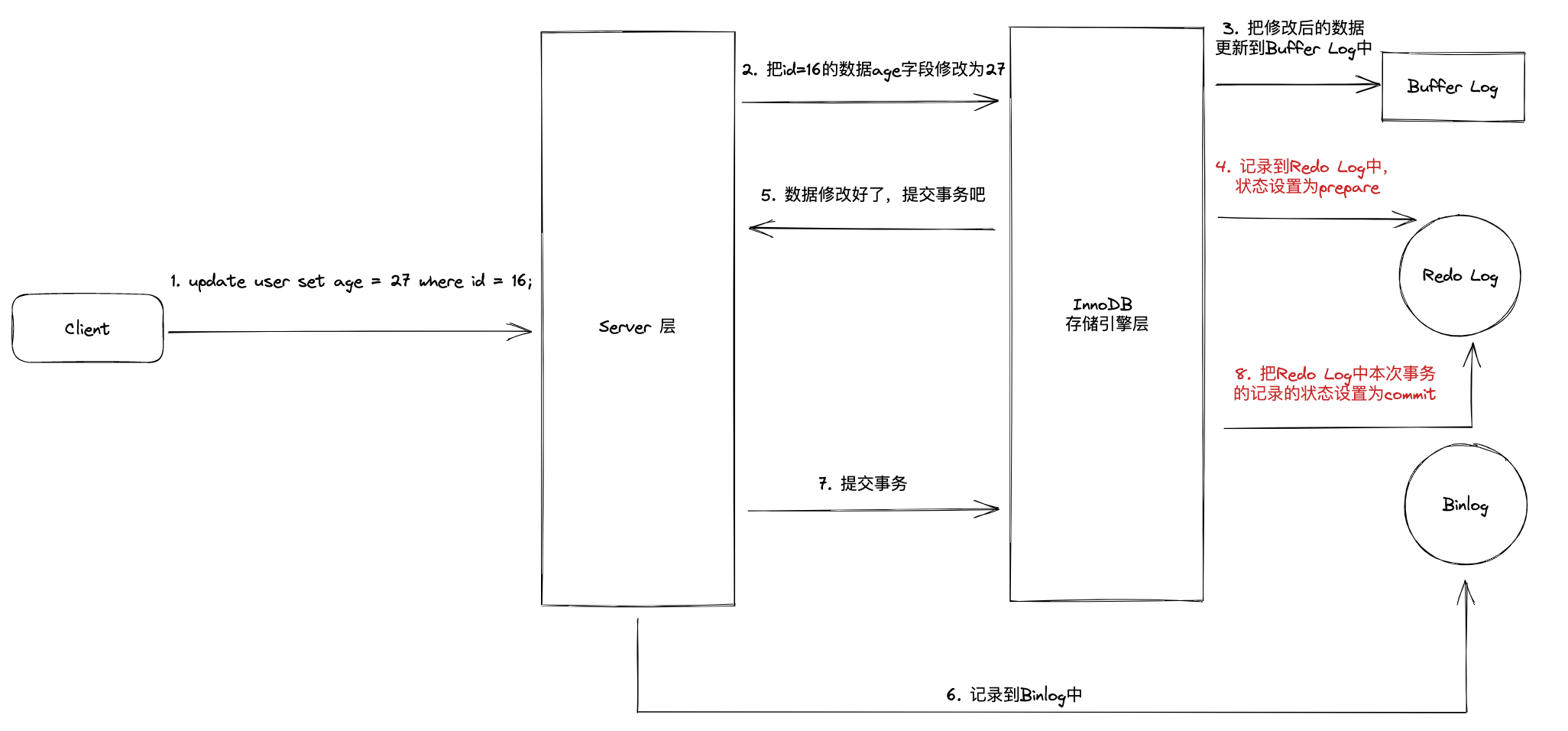
两阶段提交的核心流程:
- prepare 阶段:写入 Redo Log 并把状态设置为 prepare
- commit 阶段:写入 Binlog 并把 Redo Log 的状态设置为 commit
在整个流程中,Binlog 充当了事务协调者的角色,通知 InnoDB 执行 commit、rollback 指令,当第 6 步写入 Binlog 时写入失败,commit 阶段中事务就不会提交,此时 Redo Log 中 prepare 状态的数据就会被回滚
当 MySQL 根据 Redo Log 进行崩溃恢复时:
- 如果数据在 Redo Log 和 Binlog 都存在,那么这个事务需要进行提交
- 如果数据只在 Redo Log 中而不在 Binlog 中,说明第二段提交没有成功,这个事务是需要回滚的
至此,MySQL 更新数据中写入部分介绍完毕
总结
MySQL 更新语句执行流程比查询语句执行流程更为复杂,因为需要同时考虑读取、写入两个部分:
- 读取方面
- 考虑到直接随机磁盘 IO 效率低下,MySQL 在中间加入了一个 Buffer Pool
- 考虑到减少主线程时间的磁盘 IO 次数,MySQL 加入了预读机制,预读机制基于 Page 和 Extent 结构又分为线性预读与随机预读
- 考虑到预读机制带来的内存空间压力,MySQL 使用了内存淘汰算法,定义了冷热数据区的一系列规则
- 写入方面
- 考虑到尽可能减少写入、同步的数据,MySQL 使用了 Flush 链表来记录修改过的数据页,脏页会在特定的时候进行刷脏
- 考虑尽可能降低每次更新时磁盘读取数据的次数,MySQL 在 Buffer Pool 中开辟了一块 Change Buffer 区域,暂时缓存修改的数值缓存下来,等待数据页进入 Buffer Pool 时进行 merge 操作
- 考虑到数据崩溃会导致破坏 InnoDB 的持久性,MySQL 使用了 Redo Log 来记录修改操作,以便崩溃恢复
- 考虑到直接写磁盘文件效率低下,MySQL 又引入了一个缓存 Log Buffer 提升操作效率
- 最后围绕记录修改操作的全过程,提供了三种不同的 Log Buffer 刷盘策略
如果这篇文章对你有帮助,请给我一个免费的大拇哥👍
我的个人知识库 GitHub 地址:https://github.com/gelald/javrin 请给我 star 支持一下,谢谢~















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









