






代码随想录算法训练营第39天|贪心算法part05| 435. 无重叠区间、 763.划分字母区间、 56. 合并区间
435. 无重叠区间
自己做
思路:
这道题根射气球那道题很像,气球那道题是求不重叠的个数,从而得到需要的弓箭的数量
而这道题是移除最小数量的区间,使余下的区间不重叠,思路上差不多,但是就是做不对
我的错误在于:
先排序,通过比较右区间,如果重叠之间删除当前的结点,前一个结点的右区间还作为下次比较的右区间,但是直接删除造成了一个错误,其实应该比较两个结点的右区间,留下右区间小的,删除右区间大的,不一定必须删除后面的,我就直接删除后面的了,导致了最终的提交不通过。
代码:
python 正确代码如下
class Solution(object):
def eraseOverlapIntervals(self, intervals):
"""
:type intervals: List[List[int]]
:rtype: int
"""
# 移除最小数量的区间,是区间重合就需要删除
intervals = sorted(intervals, key=lambda x: x[0])
remove_count = 0
right = intervals[0][1]
for index in range(1, len(intervals)):
if intervals[index][0] - right < 0:# 有重叠之后,删除哪个呢?
right = min(intervals[index][1], right) # 这一步是为什么呢?为了下次比较是否有重叠时,不会出现重复删除区间的情况
remove_count += 1
else:
right = intervals[index][1]
return remove_count
代码随想录
这道题有很多种解法,记住上面讲的就得了
763. 划分字母区间
自己做:做不出来,想不到
代码随想录
思路:
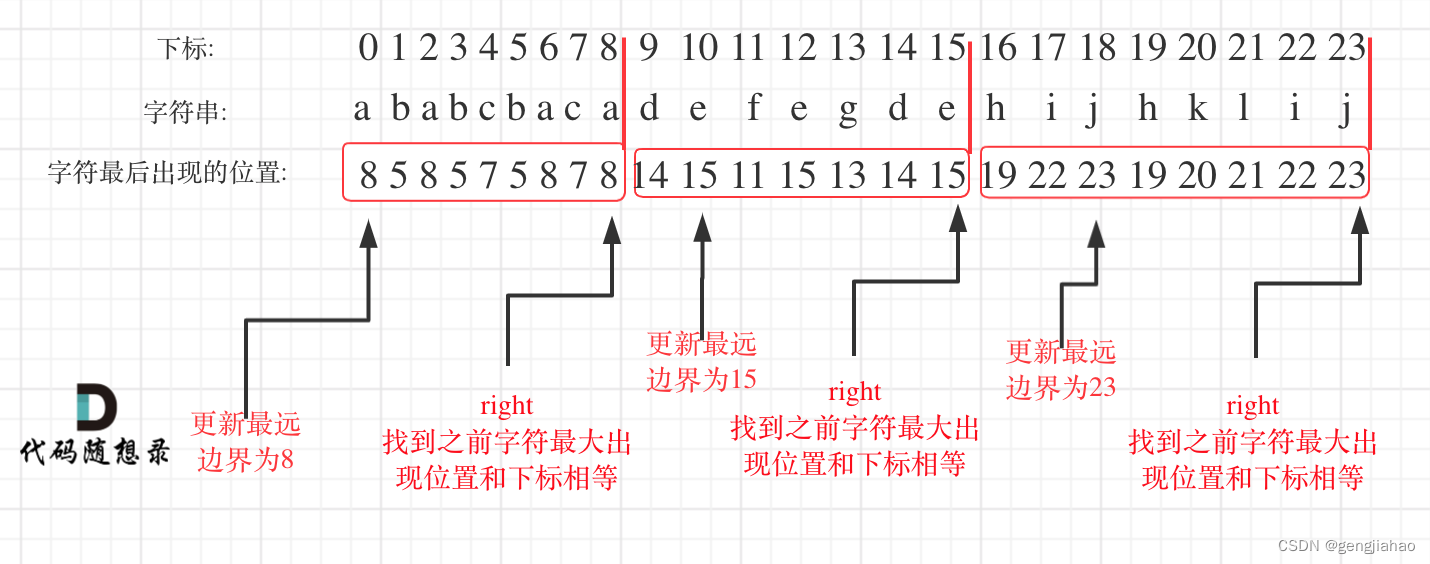
在遍历的过程中相当于是要找每一个字母的边界,如果找到之前遍历过的所有字母的最远边界,说明这个边界就是分割点了。此时前面出现过所有字母,最远也就到这个边界了。
可以分为如下两步:
-
统计每一个字符最后出现的位置
-
从头遍历字符,并更新字符的最远出现下标,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点
如图:
代码:
python
class Solution:
def partitionLabels(self, s: str) -> List[int]:
last_occurrence = {} # 存储每个字符最后出现的位置
for i, ch in enumerate(s):
last_occurrence[ch] = i
result = []
start = 0
end = 0
for i, ch in enumerate(s):
end = max(end, last_occurrence[ch]) # 找到当前字符出现的最远位置
if i == end: # 如果当前位置是最远位置,表示可以分割出一个区间
result.append(end - start + 1)
start = i + 1
return result
补充
这里提供一种与452.用最少数量的箭引爆气球 (opens new window)、435.无重叠区间 (opens new window)相同的思路。
统计字符串中所有字符的起始和结束位置,记录这些区间(实际上也就是435.无重叠区间 (opens new window)题目里的输入),将区间按左边界从小到大排序,找到边界将区间划分成组,互不重叠。找到的边界就是答案。
代码:
python
class Solution:
def countLabels(self, s):
# 初始化一个长度为26的区间列表,初始值为负无穷
hash = [[float('-inf'), float('-inf')] for _ in range(26)]
hash_filter = []
for i in range(len(s)):
if hash[ord(s[i]) - ord('a')][0] == float('-inf'):
hash[ord(s[i]) - ord('a')][0] = i
hash[ord(s[i]) - ord('a')][1] = i
for i in range(len(hash)):
if hash[i][0] != float('-inf'):
hash_filter.append(hash[i])
return hash_filter
def partitionLabels(self, s):
res = []
hash = self.countLabels(s)
hash.sort(key=lambda x: x[0]) # 按左边界从小到大排序
rightBoard = hash[0][1] # 记录最大右边界
leftBoard = 0
for i in range(1, len(hash)):
if hash[i][0] > rightBoard: # 出现分割点
res.append(rightBoard - leftBoard + 1)
leftBoard = hash[i][0]
rightBoard = max(rightBoard, hash[i][1])
res.append(rightBoard - leftBoard + 1) # 最右端
return res
56. 合并区间
自己做
思路:
先排序,只要有重叠的区间,就合并,每到不发生重叠的情况,就把之前的区间加入到结果列表中,然后重新初始化左右区间
代码:
python
class Solution(object):
def merge(self, intervals):
"""
:type intervals: List[List[int]]
:rtype: List[List[int]]
"""
intervals = sorted(intervals, key = lambda x: x[0])
result = []
left = intervals[0][0]
right = intervals[0][1]
for i in range(1, len(intervals)):
if intervals[i][0] <= right:
right = max(intervals[i][1], right)
else:
result.append([left, right])
left = intervals[i][0]
right = intervals[i][1]
result.append([left, right])
return result
代码随想录
思路:
本题的本质其实还是判断重叠区间问题。
大家如果认真做题的话,话发现和我们刚刚讲过的452. 用最少数量的箭引爆气球 (opens new window)和 435. 无重叠区间 (opens new window)都是一个套路。
这几道题都是判断区间重叠,区别就是判断区间重叠后的逻辑,本题是判断区间重贴后要进行区间合并。
所以一样的套路,先排序,让所有的相邻区间尽可能的重叠在一起,按左边界,或者右边界排序都可以,处理逻辑稍有不同。
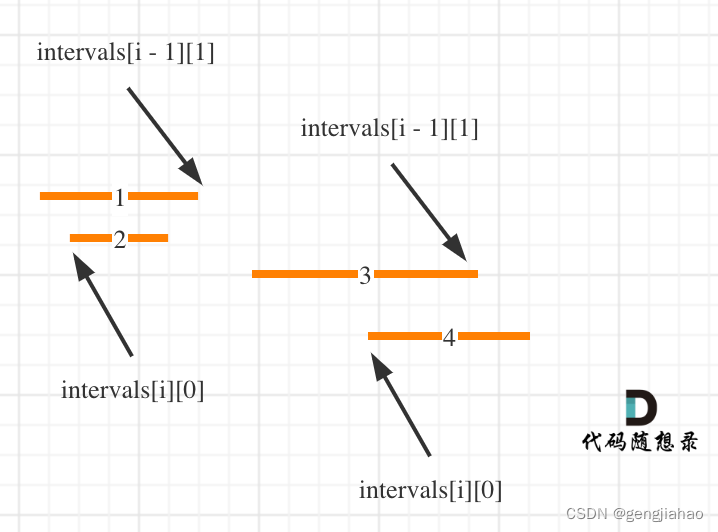
按照左边界从小到大排序之后,如果 intervals[i][0] <= intervals[i - 1][1] 即intervals[i]的左边界 <= intervals[i - 1]的右边界,则一定有重叠。(本题相邻区间也算重贴,所以是<=)
这么说有点抽象,看图:(注意图中区间都是按照左边界排序之后了)
知道如何判断重复之后,剩下的就是合并了,如何去模拟合并区间呢?
其实就是用合并区间后左边界和右边界,作为一个新的区间,加入到result数组里就可以了。如果没有合并就把原区间加入到result数组。
python
class Solution:
def merge(self, intervals):
result = []
if len(intervals) == 0:
return result # 区间集合为空直接返回
intervals.sort(key=lambda x: x[0]) # 按照区间的左边界进行排序
result.append(intervals[0]) # 第一个区间可以直接放入结果集中
for i in range(1, len(intervals)):
if result[-1][1] >= intervals[i][0]: # 发现重叠区间
# 合并区间,只需要更新结果集最后一个区间的右边界,因为根据排序,左边界已经是最小的
result[-1][1] = max(result[-1][1], intervals[i][1])
else:
result.append(intervals[i]) # 区间不重叠
return result















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









