






前言
相较于上一周的Coursera课程——神经网络与深度学习-CSDN博客,这次的课程明显专业性强了很多,涉及到了很多概念,主要讲解的是我们实际在训练自己神经网络的时候,需要考虑哪些因素以及背后的原理。
实践过程
1.数据集的划分
训练集:用于模型的训练,参数在训练集上产生
验证集:用于模型选择和超参数调优,还可以防止过拟合
测试集:验证最后的效果
一般比例为6:2:2,但当数据量过于庞大的时候,就没有必要选择大数量的验证集和测试集,例如可以1000000、10000、10000。
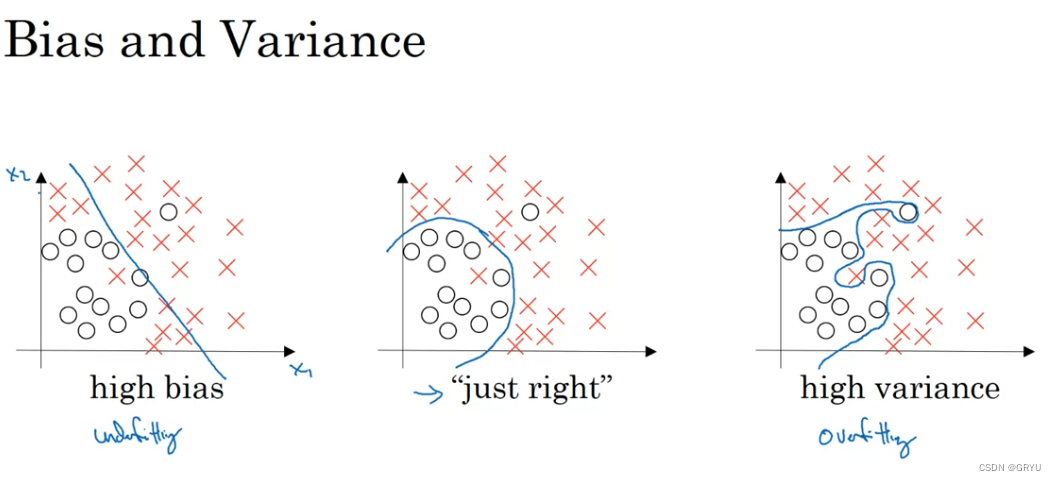
2.偏差和方差
机器学习中的偏差-方差权衡(bias-variance tradeoff)是指模型的复杂度与其在不同数据集上的表现之间的关系。偏差(bias)是指模型对真实关系的近似能力,方差(variance)是指模型对数据变化的敏感性。简单模型(如线性回归)可能有较高的偏差和较低的方差,而复杂模型(如高阶多项式回归)可能有较低的偏差和较高的方差。过拟合的模型通常是偏差低但方差高的。
3.正则化
为了解决高方差的问题,我们通常采取正则化的方式。模型可能在训练集上面表现得很好,但实际上发生了过拟合,对新数据上表现不佳,所以我们要加入一些惩罚项,来提高他的抗噪能力。
正则化:通过添加惩罚项来限制模型的复杂度,以防止过拟合并提高模型的泛化能力。

为什么正则化能够防止过拟合?
由偏差和方差图我们可以看出来,过拟合产生的原因是最后得到的模型过于复杂了。当我们加入惩罚项,其实就是相当于每个参数乘以一个小于1的数,Lambda越大参数就越小,我们假设一个极端的情况,Lambda大到很多参数都变成了0,其在神经网络中不起作用,就相当于我们的网络变成了一个浅层的网络,因而可以防止过拟合。
我们可以根据上述分析发现,过拟合的本质是让模型没有那么复杂,保留在一个适中的复杂程度,因此衍生出一些其他的正则化方法:
Drop out正则化:随机丢掉一些网络中的节点,也可以起到简化网络的作用。(在梯度检测的过程中不要进行这一步骤)
Early Stopping :一般我们在开始的时候习惯把参数w设置为接近于0的数,早一些停止参数拟合的过程可以让w没有那么大
4.归一化

对数据不同尺度的特征进行归一化,可以避免梯度下降学习过程中的反复震荡,避免因为特征尺度不同而导致某些特征对于训练造成较大的影响
5.梯度消失/爆炸
为什么会出现梯度消失/爆炸?
当训练一个层数非常多的神经网络的时候,由于损失函数的导数是随着层数的增加指数级的增加或减少,因此会出现这种情况。
怎么解决?
在每一层的权重乘以1/n(随着激活函数的不同,这个常用值会不同)
6.梯度检查
我们怎么确定自己的反向传播代码是否正确,需要运用到梯度检查,本质上是梯度逼近(和求导数的过程差不多,对前后进行微小扰动𝜀, 计算[f(𝜃+𝜀)-f(𝜃-𝜀)]/(2𝜃) )
算法优化
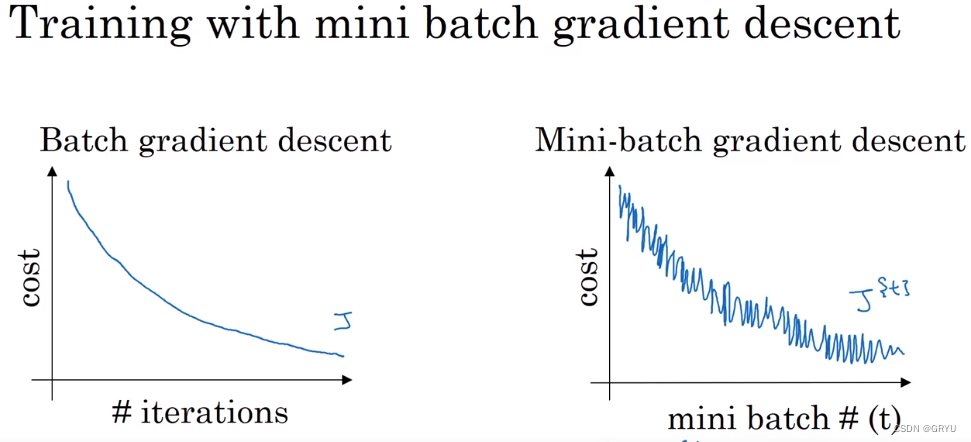
1.小批量(mini-batch)梯度下降
传统的学习每进行一个轮次,都需要处理大量的数据,这样我们迭代一次所需要的时间会很长,小批量梯度下降法相当于把一个大的数据分为很多小的子集,每一个轮次学习一个子集,这样当遍历一遍所有的数据时候,传统学习只走了1步梯度下降,而小批量的方法可能已经走了5000步了,下图是他们成本函数的走向。
批量大小影响到收敛的速度和能否找到全局最小值,一般选择64-512。
2.指数加权平均数
![]()
越接近当前时刻的数据对于数值的影响越大,而1/(1-β)代表的是多少次之后之前的数据影响为1/e。
3.带动量的梯度下降
在完成一次反向传播后,利用导数更新参数值W和b的时候,采用指数加权平均数来更新每次的导数值。
v_dW=beta*v_dW+(1-beta)*dW
v_db=beta*v_db+(1-beta)*db
为什么叫带动量的梯度下降?

我们在梯度下降的过程中,可以将其分解为上下振动的噪声和向着最小值前进,在使用指数加权平均数的过程中,震荡的噪声被平均掉了,而前进的方向不变,像一个小球从碗的边缘加速向下到底部。
4.RMSprop 均方根传递(Root Mean Square prop)
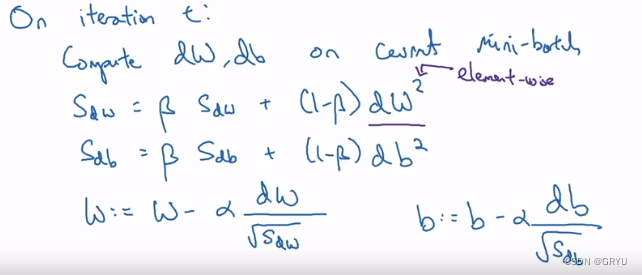
这里的dw是逐元素平方
根据w和b的性质,Sdw是一个较小的数,Sdb是一个较大的数,这样也可以保证减慢b方向的学习
也就是垂直方向,同时加速或至少不减慢水平方向的学习。
如果S_dW的平方根非常接近0 为了确保数值稳定性,要给分母加上一个非常非常小的epsilon,
10的-8次方是一个合理的默认值。
5.亚当优化算法
本质上是结合了动量梯度下降和RMSprop 均方根传递


6.学习率衰减
随着轮次的进行,学习率不断减小,这样可以避免在最小值附近陷入反复震荡的情况。
7.本地最优化问题
我们经常会担心这样一个问题,会不会得到的不是全局最优解而是局部最优解。但事实上这种情况是极其少的,因为在多维空间这种情况更像是一个马鞍形,我们称这个为停滞区(Plateaus) :导数长时间接近于零的一段区域 。你会花费很长的时间,缓慢地在停滞区里找到离开的那个点。

超参调整
1.超参调整
(1)超参重要度排序
学习率最重要
其次批次大小和隐藏单元数量
最后是网络层数和学习速率衰减
其他参数一般取默认值

(2)超参组合
随机取样,同时可以在效果好的区域集中取样

(3)超参尺度
选取适当的尺度研究超参,例如对数尺度
(4)模型训练方式
熊猫与鱼子酱:可以建立一个模型,每隔一段时间去看它的学习曲线,或是损失函数,或是误差,调整一下参数看效果;也可以同时跑多个模型,比较其效果。
2.SoftMax

逻辑回归其实算是一种特殊的SoftMax分类器
总结
系统性的学习一下深度学习的过程还是挺有收获的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









