






查询关系数据
当在讨论查询技术的时候,我们理所当然的要关注数据库。在这一部分,我们将继续学习LINQ的核心框架结构,这次要关注的是关系数据。只需要很小的改动,我们就可以使用LINQ查询可以与SQL Server家族的数据进行协同工作,从而消除那些重复的数据库访问代码。通过改变内在的数据源,同样的LINQ查询可以立刻使用在数据库上。此外,SQL LINQ还可以对SQL Server的数据库进行更新以及访问存储过程和自定义函数。第六章显示SQL LINQ和Object LINQ的区别。第七章深入研究了SQL LINQ的内部结构。第八章揭示了SQL LINQ提供的更高级的数据库访问能力。
初识SQL LINQ
到目前为止,我们一直都是在处理在内存中的数据。为了查询这些数据,我们需要一个实现IEnumerable<T>接口的对象来遍历数据。它不能处理持久化的数据。如SQL Server一样的关系数据库。
本章中,我们要使用SQL LINQ来处理查询和类关联而不是用ADO.NET。作为开始,我们使用了一个示例,该示例列出了价格小于$30的book,并按照它们的主题分组。这需要我们合并两个集合(Books 和Subjects)的信息列表6.1显示了这个问题的解决方案。
列表 6.1 使用Object LINQ查询Subjects和Books
IEnumerable<Book> books = Book.GetBooks();
IEnumerable<Subject> subjects = Subject.GetSubjects();
var query =
from subject in subjects
join book in books
on subject.SubjectId equals book.SubjectId
where book.Price < 30
orderby subject.Description, book.Title
select new
{
subject.Description,
book.Title,
book.Price
};
在这个示例中,我们填充book和subject集合,然后进行查询。我们达到了目标,但并不是很有效。下面是我们需要传给数据库的SQL查询。
SELECT ID, Isbn, Notes, PageCount, Price, PubDate, Publisher, Subject, Summary, Title
FROM Book
SELECT ID, Name, Description
FROM Subject
因为过滤,投影和排序都是在客户端上做的,我们需要在处理之前获取所有的数据。结果,我们需要获取那些我们不需要的记录。此外,我们不能利用数据库索引的强大性能。这意味着我们给网络和处理器增加了压力。更糟糕的是,我们需要写所有的数据访问代码,这些代码有很多重复且容易出错。SQL LINQ帮了我们的大忙。它解决我们上述提到的所有问题。最后,我们获得得将是下面得数据库查询。
SELECT t0.Description, t1.Title, t1.Price
FROM Subject AS t0 INNER JOIN
Book AS t1 ON t0.ID = t1.Subject
WHERE (t1.Price < @p0)
ORDER BY t0.Description, t1.Title
令人感到惊奇得是,我们可以不用改动或者添加一行代码就可以做到这点。我们的业务对象上的变化允许我们消除那些更新记录的代码。
下面的三章,我们将深入探讨SQL LINQ。在本章中,我们将会探讨学习SQL LINQ的使用以及如何提高性能并且减少代码。第七章中,我们将会深入SQL LINQ的底层,探讨它的框架结构和它的魔力所在。第八章将会探讨SQL LINQ的更多高级课题。
6.1 开始使用SQL LINQ
在本章的示例中,我们要查找价格低于$30的书籍并按照主题分组。如列表6.2所示:
列表 6.2 选择book对象
IEnumerable<Book> books = Book.GetBooks();
var query = from book in books
where book.Price < 30 orderby book.Title
select new
{
book.Title, book.Price
};
现在,我们仍然需要从数据库中获取所有数据到客户端。SQL语句如下:
SELECT ID, Isbn, Notes, PageCount, Price, PubDate, Publisher, Subject, Summary, Title
FROM Book
而实际上,最有效的SQL语句应该如下面的一样:
SELECT Title, Price
FROM Book AS t0
WHERE (Price < @p0)
ORDER BY Title
要做到这种改变,我们查询需要修改吗?不需要!所有要做的就是修改我们的Book类并且改变访问方式。首先,让我们看看对于Book对象需要作出什么改变。
图 6.1 比较Book表和Book类
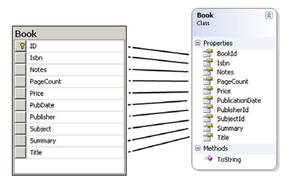
首先,我们在表和目标对象之间进行1-1映射。稍后,我们会将表和对应的Subject对象相关联,由此可以看出如何处理数据库中的外键关系。但是现在,我们将会集中关注单个表。首先让我们看看Book类的代码,如列表 6.3
列表 6.3 Book类定义
public class Book
{
public Guid BookId { get; set; }
public String Isbn { get; set; }
public String Notes { get; set; }
public Int32 PageCount { get; set; }
public Decimal Price { get; set; }
public DateTime PublicationDate { get; set; }
public String Summary { get; set; }
public String Title { get; set; }
public Guid SubjectId { get; set; }
public Guid PublisherId { get; set; }
}
我们只使用了公共属性,从而使类看上去相当清爽。接下来,我们需要一种方法来使用数据库中的数据对我们的对象进行填充。通过建立对象和数据表及列的映射关系可以做到这一点。
6.1.1设置对象映射
要使用SQL LINQ,首先要添加System.Data.Linq程序集的应用,该程序及包含在.NET 3.5中。然后添加下面的命名空间,这个命名空间使包含可以让我们建立映射关系的类。
using System.Data.Linq.Mapping;
在多数情况下,我们需要在一个类中标识两个方面:要关联到什么表上和那些列上。映射到book表也许是最简单的映射了。在这种情况下,我们的数据库有一个名为Book的表。与之对应的是名为Book的类。为了声明映射,需要添加一个Table属性到类声明上,如下:
[Table]
public class Book {…}
如果需要更详细一点,可以使用Name参数指明源表的名称,如下:
[Table(Name="dbo.Book")]
public class Book {…}
现在,我们将类映射到表上了,还需要指定类属性和列的映射信息。通过Column属性类可以做到这点。添加一个Column属性需要映射列信息类属性上。例如,将Title属性映射到Title列上。如下:
[Column]
public String Title { get; set; }
上面使用的是直接映射。我们可以指定更详细的映射信息,如要映射列的名称。如下所示的用法,使用Name参数可以做到列名称与类属性名称不必相同。
[Column(Name="PubDate")]
public DateTime PublicationDate { get; set; }
我们需要为每个对象标识它们的主键。在我们的示例中,BookId属性需要标识。使用IsPrimaryKey参数来标识这个映射。为了管理对象标识,SQL LINQ需要指定至少一个属性作为主键。
[Column(Name=”ID”, IsPrimaryKey=true)]
public Guid BookId { get; set; }
我们使用同样的方法为类中所有的属性声明映射信息,结果如列表 6.4所示。
列表 6.4 建立了映射的Book类
using System.Data.Linq;
[Table]
public class Book
{
[Column(Name="ID", IsPrimaryKey=true)]
public Guid BookId { get; set; }
[Column]
public String Isbn { get; set; }
[Column(CanBeNull=true)]
public String Notes { get; set; }
[Column]
public Int32 PageCount { get; set; }
[Column]
public Decimal Price { get; set; }
[Column(CanBeNull=true)]
public String Summary { get; set; }
[Column(Name="PubDate")]
public DateTime PublicationDate { get; set; }
[Column]
public String Title { get; set; }
[Column(Name="Subject")]
public Guid SubjectId { get; set; }
[Column(Name="Publisher")]
public Guid PublisherId { get; set; }
}
添加这些额外的映射信息使得我们可以避免编写例如Create, Read, Update和Delete方法。做了上述的映射后,还需要建立到数据库的连接,DataContext可以完成我们的任务,它在System.Data.Linq命名空间中。下面就可以开始进行数据查询了。
6.1.2 设置DataContext
图6.2中显示的DataContext是SQL LINQ的心脏,它处理了几乎所有的工作任务。首要的任务就是它管理了所有到数据库的连接。我们可以通过连接字符串来构建DataContext。DataContext将会为我们管理打开的和关闭的连接。我们不需要关心连接的滥用。
图 6.2 DataContext提供的服务
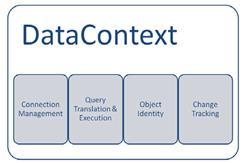
首要要创建一个DataContext的实例,它需要一个连接字符串参数。。
DataContext dataContext = new DataContext(liaConnectionString);
DataContext处理我们映射,将用数据库的数据填充到一个对象集合中。该对象集合是一个泛型集合:Table<>。为了从DataContext中获取book对象集合,需要调用dataContext.GetTable<Book>():
DataContext dataContext = new DataContext(liaConnectionString);
Table<Book> books = dataContext.GetTable<Book>();
没有SQL LINQ时,我们使用List<Book>来保存泛型对象列表。而使用LINQ,就需要使用Table<Book>。由此带来的好处就是我们不再编码获取源数据,还可以更加动态的访问和操作数据。还将允许我们在进行数据库请求之前处理查询。下面就让我们看看使用SQL LINQ如何做到这些吧。
6.2 使用SQL LINQ读取数据
我们要做的第一件事就是从数据库中选择数据。一种方式就是使用GetTable方法。这个泛型的Table类实现了IQueryable<T>接口,它扩展了IEnumerable<T>。所以我们可以自由使用任何来自Object LINQ的查询操作符。下面就使用一个简单的查询从数据库获取我们刚刚重构过的Book对象。如列表6.5.
列表 6.5 使用SQL LINQ获取book数据
DataContext dataContext = new DataContext(liaConnectionString);
IQueryable<Book> query = from book in dataContext.GetTable<Book>()
select book;
在本例中,我们没有写任何关于ADO.NET的代码。但是我们获取了所有的数据,而没有对其进行任何过滤。
在我们学习SQL LINQ特性的时候,有时需要针对数据库来检查我们的代码。此时,结果查询将会令你感到惊奇。我们有多种方法可以查询发送到数据库的查询。使用SQL Server Profiler工具或者将DataContext的Log属性附加到一个输出流上,如下:
dataContext.Log = Console.Out;
启用了日志功能,发送到数据库的任何SQL语句都被发送到输出流上。如果附加到控制台流上,那么sql语句就会显示在控制台窗口上,在Windows程序中,sql语句将被发送到Output 窗口中。接下来,我们会频繁使用log功能以观察在LINQ的背后发生了什么。
还有一种方法,微软有一个查询可视化工具可以附加在Visual Studio 2008中,该工具的代码和安装包可以从http://weblogs.asp.net/scottgu/archive/2007/07/31/linq-to-sql-debug-visualizer.aspx下载。一旦安装了此工具,我们就可进行调试,然后将鼠标停留在查询变量上,可以看到如图6.3所示场景。
点击放大镜,就是显示如图6.4所示窗口,允许访问将要发送到数据库的完整的SQL语句。可视化器还可以允许我们在数据表格中查看结果并且手动编辑产生的SQL语句。
图6.3 在调试时使用SQL LINQ查询可视化器查看相关信息

图 6.4 SQL LINQ查询可视化查看窗口
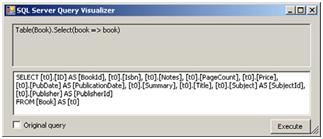
同样可以使用编程的方法来访问这些信息,利用DataContext.GetCommand方法:
Console.Writeline(dataContext.GetCommand(query).CommandText);
这个command并不会在执行时被使用, 但是它会显示被处理的语句。当你慢慢熟悉SQL LINQ后,可以选择一种你最喜欢的技术。不管你选择了哪种,都有必要查看一下要被执行的sql语句,以避免你不希望的情况发生。
上一个示例中,我们学会了如何使用映射,但是却不知道如何获取部分数据,因为SQL LINQ建立在查询表达式之上,所以我们可以只获取那些我所需要的结果。因此如果我们要得到一个标题列表,就可以使用列表6.6所示查询。
列表 6.6 获取book 标题列表
DataContext dataContext = new DataContext(liaConnectionString);
dataContext.Log = Console.Out;
IEnumerable<String> query =
from book in dataContext.GetTable<Book>()
select book.Title;
因为使用了dataContext.Log,所以可以在输出窗口中看见如下查询。
SELECT [t0].[Title] FROM [Book] AS [t0]
查看这个SQL语句,可以看到所发生的变化,为了达到只获取书籍标题和价格的要求,可以使用如下查询,如列表6.7。
列表 6.7 映射到匿名类型
var query = from book in dataContext.GetTable<Book>()
select new
{
book.Title, book.Price
};
对应的SQL语句如下所示:
SELECT [t0].[Title], [t0].[Price] FROM [Book] AS [t0]
再次运行示例,看看SQL代码在何时显示在窗口中?时我们调用dataContext.GetTable<Book>()方法的时候还是声明query对象的时候?都不是,直到我们访问数据的时候,才真正的产生SQL语句。查询变量包含了如何访问数据的定义,而不是数据本身。查询被延迟到第一次使用数据时执行。我们将在6.6节中详细讨论这点。
接下来,我们要为查询添加分页功能,如下:
列表 6.8 添加分页功能
DataContext dataContext = new DataContext(liaConnectionString);
dataContext.Log = Console.Out;
var books = dataContext.GetTable<Book>();
var query = from book in books select new
{
book.Title,
book.Price
};
var pagedTitles = query.Skip(2);
var titlesToShow = pagedTitles.Take(2);
ObjectDumper.Write(titlesToShow);
发送到数据的SQL语句如下:
SELECT TOP 2 [t1].[Title], [t1].[Price]
FROM
( SELECT ROW_NUMBER() OVER (ORDER BY [t0].[Title], [t0].[Price])
AS [ROW_NUMBER],[t0].[Title], [t0].[Price]
FROM [Book] AS [t0]
) AS [t1]
WHERE [t1].[ROW_NUMBER] > @p0
针对特定的数据库进行查询优化是可能的,上面的SQL语句是针对SQL Server 2005产生的,如果我们使用SQL Server 2000,就会产生不同的SQL语句。因为ROW_NUMBER()选项是特定于SQL Server 2005的。
由此可以看出,SQL LINQ能够从LINQ查询产生与之相对的SQL语句,并能针对数据源的类型进行调整。下面我们将会学习更多SQL LINQ特性。
6.3 优化查询
到目前为止,我们都是在关注如何从表中获取数据,可以看出SQL LINQ要优于ADO.NET,因为我们不再需要写那些重复的数据访问代码了。
关系数据库提供了管理和访问数据的特殊能力。通过使用索引和查询执行计划,数据库可以比没有索引的情况下提供更快的访问速度。此外,通过在服务器上处理查询,通过网络传输的信息就会减少。减少网络传输量是很重要的事情,因为网络管道是数据-中心的程序的最大瓶颈。SQL LINQ能够利用这一点。
6.3.1过滤
SQL LINQ支持大量的过滤功能。示例中,我们要查找那些低于30美元的书籍,就可以使用列表 6.10所示代码:
列表 6.10 根据范围过滤
var books = dataContext.GetTable<Book>();
var query = from book in books where book.Price < 30
select book;
查看产生的SQL,结果跟我们想的一样。
SELECT [t0].[Title]
FROM [dbo].[Book] AS [t0] WHERE [t0].[Price] < @p0
在SQL LINQ中,查询被转换为对数据库的参数化查询,结果返回了符合要求的数据,并且解决了一些其它的问题,如转换后的查询能够阻止SQL注入攻击。之前,要阻止这样的攻击,最简单的方法是使用存储过程。使用参数化查询的另一个好处是可以利用SQL Server的查询计划缓存。通过重用那些只有输入参数值变化的查询,SQL Server可以决定合适的执行计划并对其缓存以继续使用。在后续查询执行的时候,服务器将会使用缓存而不是重新计算表达式。
许多SQL关键字在.NET Framework中没有直接对应的关键字。在许多情况下,对应的功能总是存在,只有有可能,LINQ就能转换到合适的SQL查询上。
考虑SQL中LIKE查询,LIKE查询通过模式匹配来查询记录。与之相对,String类型有三个方法与之对应-StartsWith, EndsWith和 Contains。SQL LINQ设计用这三个方法与SQL中的LIKE表达式对应,产生对应的LIKE查询。
对了查找标题包含”on”的book,我们使用如列表6.11的查询。
列表 6.11 使用映射的CLR方法
var books = dataContext.GetTable<Book>();
var query = from book in books
where book.Title.Contains("on")
select book.Title;
转换后的SQL表达式如下:
SELECT [t0].[Title]
FROM [dbo].[Book] AS [t0] WHERE [t0].[Title] LIKE @p0
-- @p0: Input NVarChar (Size = 4) NOT NULL [%on%]
注意Contains方法已经被转为为包含%通配符的参数值,这是针对SQL Server的转换方式。并不是所有的CLR函数都可以被转换到数据库的等价物。考虑如下查询:
var query =
from book in books
where book.PubDate >= DateTime.Parse("1/1/2007") 成功转换
select book.PubDate.Value.ToString("MM/dd/yyyy"); 无法转换
在本示例中,转换提供者可以转换DateTime.Parse方法并插入一个特定数据库的日期展示。不能转换在select子句中的ToString方法来格式化数据。识别所有支持和不支持的表达式是不可能的,而且,转换支持是依赖于特定的提供者。当你不确定一个方法是否被支持的时候,就需要测试一下是不是真的是如你所想。
在许多情况下,过滤都能如期工作。有时需要做点工作查找合适的方法。这里不能覆盖所有的映射。但是应该尽量让过滤操作在服务器端执行而不是在客户端执行。这样才能最大化利用带宽和数据库索引的优点。
目前为止,在不需写ADO.NET代码的情况下,我们获取了合适的数据。下面还需要修改查询,添加排序和分组的功能。
6.3.2 排序和分组
与Object LINQ没有区别,添加了排序功能的SQL LINQ语句如列表 6.12所示:
列表 6.12 使用SQL LINQ进行排序
var books = dataContext.GetTable<Book>();
var query = from book in books
where book.Price < 30
orderby book.Title
select book.Title;
产生的SQL语句如下所示:
SELECT [t0].[Title] FROM [Book] AS [t0]
WHERE [t0].[Price] < @p0
ORDER BY [t0].[Title]
如果要对结果进行降序排序。可以使用descending查询表达式。同样,如果相对多个列进行排序,只需要对字段用逗号隔开,如标准的SQL表达式一样做就可以了。
通常,除了排序结果,还需要对结果进行分组。如列表6.13,我们对book列表按照主题进行分组。
列表 6.13 分组和排序
var query =
from book in dataContext.GetTable<Book>()
group book by book.SubjectId into groupedBooks
orderby groupedBooks.Key
select new
{
SubjectId = groupedBooks.Key,
Books = groupedBooks
};
foreach (var groupedBook in query)
{
Console.WriteLine("Subject: {0}", groupedBook.SubjectId);
foreach (Book item in groupedBook.Books)
{
Console.WriteLine("Book: {0}", item.Title);
}
}
产生的SQL语句如下:
SELECT [t1].[SubjectId] AS [Key]
FROM (
SELECT [t0].[Subject] AS [SubjectId]
FROM [dbo].[Book] AS [t0] GROUP BY [t0].[Subject]
) AS [t1]
ORDER BY [t1].[SubjectId]
实现了分组,对分组结果进行聚合就变得简单了。
6.3.3聚合
SQL LINQ支持所有IEnumerable<T>上的扩展聚合方法。因此,我们可以获取每种分类的Book数量。如列表6.14:
列表 6.14 在结果中包含聚合
Table<Book> books = dataContext.GetTable<Book>();
var query = from book in books
group book by book.SubjectId into groupedBooks select new
{
groupedBooks.Key,
BookCount = groupedBooks.Count()
};
对应的SQL语句如下:
SELECT COUNT(*) AS [BookCount], [t0].[Subject] AS [SubjectId] FROM [Book] AS [t0]
GROUP BY [t0].[Subject]
列表6.15显示了更复杂的用法:
列表 6.15 使用多个聚合
Table<Book> books = dataContext.GetTable<Book>();
var query =
from book in books
group book by book.SubjectId into groupedBooks
select new
{
groupedBooks.Key,
TotalPrice = groupedBooks.Sum(b => b.Price),
LowPrice = groupedBooks.Min(b => b.Price),
HighPrice = groupedBooks.Max(b => b.Price),
AveragePrice = groupedBooks.Average(b => b.Price)
};
再一次,这些操作符都被转换为对应的SQL聚合方法。
到目前为止,我们只是针对单个表进行操作,下面要讲如何使用SQL LINQ实现连接操作。
6.3.4连接
在本示例中,我们使用Subject表连接Books表。这样就可以显示主题名称了。SQL LINQ提供了两种连接方法。一种是使用where子句,类似于ANSI-82 标准的SQL语法。如列表6.16所示:
列表 6.16 连接Books 和Subjects
var subjects = dataContext.GetTable<Subject>();
var books = dataContext.GetTable<Book>();
var query =
from subject in subjects
from book in books
where subject.SubjectId == book.SubjectId
select new { subject.Name, book.Title, book.Price };
15年前,ANSI-92标准取代了ANSI-82标准。所以使用ANSI-82的语法也许会不大合适。幸运的是,LINQ同样提供了ANSI-92标准的语法。如列表 6.17所示。
列表 6.17 使用Join 关键字进行连接
var query =
from subject in subjects
join book in books
on subject.SubjectId equals book.SubjectId
select new { subject.Name, book.Title, book.Price };
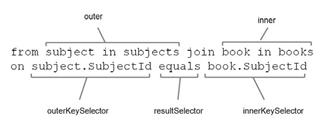
了解LINQ join子句中源和目的对象的顺序是很重要的。不像数据库理解SQL那么宽松,LINQ是严格的。因为查询表达式被转换为方法。改变了表的顺序而没有改变字段的顺序就会发生编译时错误。下面是System.Enumerable.Join扩展方法的定义。
public static IEnumerable<TResult> Join<TOuter, TInner, TKey, TResult>
(this IEnumerable<TOuter> outer,
IEnumerable<TInner> inner,
Func<TOuter, TKey> outerKeySelector,
Func<TInner, TKey> innerKeySelector,
Func<TOuter, TInner, TResult> resultSelector)
可以看到,第一个参数和第三个参数对应,第二个和第四个参数对应。图6.5显示了示例中参数的对应关系。
图 6.5 join子句与操作符之间的映射关系
(我觉得本图有误)
目前的连接操作都是内连接。下面看一下如何实现外连接。
为了得到所有主题,而不管该主题下是否有书籍存在。用ANSI-92 SQL表达式表达如下:
SELECT Subject.Name, Book.Title
FROM Subject LEFT OUTER JOIN
Book ON Subject.ID = Book.Subject
为了使用LINQ做到这点,DefaultIfEmpty()方法帮我们做到这点。如列表 6.18所示:
列表 6.18 类似outer join
var query =
from subject in Subjects
join book in books
on subject.SubjectId equals book.SubjectId into joinedBooks
from joinedBook in joinedBooks.DefaultIfEmpty()
select new
{
subject.Name,
joinedBook.Title,
joinedBook.Price
};
本例中,我们使用一个名为joinedBooks的临时变量保留了book和subject连接后的结果。如果主题并不包含一个book,使用DefaultIfEmpty方法将会返回一个默认值。最后我们得到了完整的查询代码,如列表6.19所示:
列表 6.19 使用SQL LINQ重写原来的示例
DataContext dataContext = new DataContext(liaConnectionString);
Table<Subject> subjects = dataContext.GetTable<Subject>();
Table<Book> books = dataContext.GetTable<Book>();
var query = from subject in subjects
join book in books
on subject.SubjectId equals book.SubjectId
where book.Price < 30
orderby subject.Name
select new
{
subject.Name,
joinedBook.Title,
joinedBook.Price
};
与列表 6.1相比,唯一变化的就是数据源。LINQ查询完全相同。但是看一下产生的SQL语句,现在我们只获取了我们想要的数据。此外,我们在服务器上执行了排序,连接和过滤。下面是SQL LINQ查询产生的完整的SQL查询:
SELECT t0.Name, t1.Title, t1.Price
FROM Subject AS t0 INNER JOIN
Book AS t1 ON t0.ID = t1.Subject
WHERE (t1.Price < @p0) ORDER BY t0.Name
6.4 学会使用对象树
在对象和关系数据库的阻抗错配中,对象可以包含其它对象的集合,而数据库则包含可以关联的表。读取一个subject然后显示它所关联的book可不是那么简单。我们需要详细的告诉数据库连接两个表并返回结果。
在面向对象的世界里,我们获取了一个对象的实例,如Subject。从这个Subject对象上,我们可以钻取属于该Subject的book。还可以再通过book钻取它的Authors或者其它任何暴露的属性。幸运的是SQL LINQ提供了一种简单方法让我们在对象之间进行导航。
返回到Subject类定义,可以看到,我们需要一个能够访问属于该Subject的Book的方法。而且,最好能够实现懒惰加载(用到时加载)。例如Subject有一个Books属性。列表 6.20显示了如何通过泛型System.Data.Linq.EntitySet<Book>暴露Books对象集合。在示例中,再次使用了自动完成属性以保持代码简洁。
列表 6.20 映射对象关联
using System.Data.Linq.Mapping;
{
[Table]
public class Subject
{
[Column(IsPrimaryKey = true, Name = "ID")]
public Guid SubjectId { get; set; }
[Column]
public String Description { get; set; }
[Column]
public String Name { get; set; }
[Association(OtherKey="SubjectId")]
public EntitySet<Book> Books { get; set; }
}
}
就像表和列的映射一样,我们需要告诉LINQ对象是如何关联的。使用Association属性可以做到这点。为了建立有效的Association,需要标识Book类型是如何关联到Subject上的。通过指定Books属性指定了需要关联的两个类型。Book对象包含一个SubjectId属性,已经映射到数据库的Subject列上。因此对于包含Books属性的Subject类。我们指定了Book类标识Subject对象的键SubjectId,这个键就是OtherKey。
现在我们指定两个对象之间的关系,就可以像列表 6.21一样,很容易的访问属于一个Subject的所有Book对象了。
列表 6.21 遍历对象树
foreach (Subject subject in dataContext.GetTable<Subject>())
{
Console.WriteLine(subject.Name);
foreach (Book book in subject.Books)
{
Console.WriteLine("…{0}", book.Title);
}
}
当我们运行这个查询的时候,结果与外连接相同。
为了对结果过滤,可能需要附加一些扩展方法:Any和All。Any方法只返回那些有对应Book的主题。列表6.22显示了Any的用法。
列表 6.22 使用Any达到与使用inner join相同的结果
var query = from subject in Subjects
where subject.Books.Any()
select subject;
同样返回不关联任何Book对象的主题也很简单,如下:
var query = from subject in Subjects
where !subject.Books.Any()
select subject;
还可以对关联主题的Book进行其它查询,如列表 6.23所示,显示了关联Book的价格都小于30美元的主题。
列表 6.23 使用All来过滤子对象
var query = from subject in Subjects
where subject.Books.All(b => b.Price < 30)
select subject;
通过更自然的对象层次来展示数据允许我们工作在一个熟悉的编程方式上。通过基本的业务需求建立对象依赖,这让我们保持了业务规则的完整,而不需要把精力浪费在关系数据存储上。
如有必要,还可以使用层次语法进行查询,如列表 6.24所示:
列表 6.24 使用对象层次查询
Table<Subject> subjects = dataContext.GetTable<Subject>();
var query = from subject in subjects
orderby subject.Name
select new
{
subject.Name,
Books = from book in subject.Books
where book.Price < 30
select new { book.Title, book.Price }
};
6.5数据在何时载入,这与我有关吗?
数据何时从数据库中获取?SQL LINQ使用了一种叫做延迟执行的技术。使用延迟执行,只有在请求时,结果才会被载入内存。只要注意一下SQL语句被产生的时间,就会发现定义查询的时候不会产生SQL。只有当我们请求每条记录的时候才会产生。等到需要的时候才进行访问,我们将它叫做懒惰加载。
6.5.1懒惰加载
懒惰执行为我们带来了性能优势。然而在某些情况下,可能有意外的情况发生。考虑列表 6.25的代码,它显示了所有的主题对象。
列表 6.25 懒惰加载子对象
DataContext dataContext = new DataContext(liaConnectionString);
dataContext.Log = Console.Out;
var subjects = dataContext.GetTable<Subject>();
ObjectDumper.Write(subjects);
上面的代码只是列出了subject,并没有获取book。只在需要的时候获取Book对象,使我们可以节约带宽,减少内存消耗以及减少数据库操作。
通过修改ObjectDumper调用可以扩展这个示例。ObjectDumper.Write的一个重载指示显示子对象的级别。如下所示,我们指定显示Subject下的一层对象。
ObjectDumper.Write(Subjects, 1);
要注意的一点是,只有使用的时候才会为每个subject获取记录。当不需要显示所有子对象时候,我们是懒惰执行的受益者。但是现在,在每次访问subject的book对象的时候,都要对数据库进行一次查询。列表 6.26显示了改变了ObjectDumper.Write调用后的示例的输出。
列表 6.26 懒惰执行加载子元素的输出结果
SELECT [t0].[ID], [t0].[Description], [t0].[Name] FROM [Subject] AS [t0]
SubjectId=a0e2a5d7-88c6-4dfe-a416-10eadb978b0b
Description=null
Name=Software development
Books=...
SELECT [t0].[ID] AS [BookId], [t0].[Isbn], [t0].[Notes],
[t0].[PageCount], [t0].[Price], [t0].[PubDate] AS [PublicationDate],
[t0].[Summary], [t0].[Title], [t0].[Subject] AS [SubjectId],
[t0].[Publisher] AS [PublisherId]
FROM [dbo].[Book] AS [t0]
WHERE [t0].[Subject] = @p0
-- @p0: Input UniqueIdentifier (Size = 0; Prec = 0; Scale = 0) NOT NULL [a0e2a5d7-88c6-4dfe-a416-10eadb978b0b]
Books: BookId=b1c7670c-fdf5-45e5-8f06-3b7994b6a346
Isbn=0-222-77777-2
Notes=null
PageCount=256
Price=35.5000
PublicationDate=4/1/2007
Summary=null Title=C# on Rails
SubjectId=a0e2a5d7-88c6-4dfe-a416-10eadb978b0b
Subject={ }
PublisherId=855cb02e-dc29-473d-9f40-6c3405043fa3
Books: BookId=4f3b0ac1-3746-4067-a810-79a9ce02a7bf
Isbn=0-000-77777-2
Notes=null
PageCount=101
Price=25.5500
PublicationDate=11/10/2004
Summary=null Title=Funny Stories
SubjectId=a0e2a5d7-88c6-4dfe-a416-10eadb978b0b
Subject={ }
PublisherId=4ab0856e-51f3-4b67-9355-8b11510119ba
SELECT [t0].[ID] AS [BookId], [t0].[Isbn],
[t0].[Notes], [t0].[PageCount], [t0].[Price],
[t0].[PubDate] AS [PublicationDate], [t0].[Summary], [t0].[Title],
[t0].[Subject] AS [SubjectId], [t0].[Publisher] AS [PublisherId]
FROM [dbo].[Book] AS [t0]
WHERE [t0].[Subject] = @p0
-- @p0: Input UniqueIdentifier (Size = 0; Prec = 0; Scale = 0) NOT NULL [92f10ca6-7970-473d-9a25-1ff6cab8f682]
Books: BookId=09017e35-ca66-40b8-80a4-ba5253716e33
Isbn=2-444-77777-2
Notes=null
PageCount=50
Price=29.0000
PublicationDate=2/18/1973
Summary=null
Title=Bonjour mon Amour
SubjectId=92f10ca6-7970-473d-9a25-1ff6cab8f682
Subject={ }
PublisherId=4ab0856e-51f3-4b67-9355-8b11510119ba
本例中,我们获取了所有的subject,然后对其进行迭代,并访问了它包含的书籍。可以看到每一次循环,就会发送一次SQL查询到数据库。如果我们确实要全部用到这些book对象,那么懒惰执行可能要给我们带来不能容忍的恶果了。有改变这种情形的方法吗?
6.5.2立刻载入
如果我们要多次访问结果,可以使用ToList, ToDictionary, ToLookup, 或ToArray一次获取。因此,可以改变示例中的代码,使其一次获取所有的subjects 然后对其进行重用。
var subjects = dataContext.GetTable<Subject>().ToList<Subject>();
通过显示要求需要获取所有结果,我们强迫SQL LINQ立即获取所有结果,而不是多次对数据库进行访问。简单的使用ToList仍然不能帮助我们消除对子对象的懒惰加载。幸运的是,SQL LINQ支持使用DataContext做到这点。
通过使用列表6.27中使用的DataLoadOptions类型,就可以提前保持(并不获取)结果集,只要声明的对象被使用的时候,同时也会获取关联的子对象。
列表 6.27 使用DataLoadOptions 优化对象加载
DataLoadOptions options = new DataLoadOptions();
options.LoadWith<Subject>(subject => subject.Books);
dataContext.LoadOptions = options;
在本例中,我们创建了一个名为options的DataLoadOptions对象。DataLoadOptions对象的主要功能是通过指定对象类型指示同时加载子对象。因为我们是要在加载Subject的时候同时加载Book集合,所以需要通知options需要LoadWith<Subject>并且传递一个一个方法。通过这个lambda表达式,我们指定“给定一个subject,加载Books EntitySet”。接下来要做的就是将options赋予data context对象。使用了options,再次运行示例,就产生了如下的SQL:
SELECT [t0].[ID], [t0].[Description], [t0].[Name],[t1].[ID] AS [BookId], [t1].[Isbn], [t1].[Notes], [t1].[PageCount], [t1].[Price], [t1].[PubDate] AS [PublicationDate], [t1].[Summary],[t1].[Title], [t1].[Subject] AS [SubjectId], [t1].[Publisher] AS [PublisherId],
( SELECT COUNT(*)
FROM [dbo].[Book] AS [t2]
WHERE [t2].[Subject] = [t0].[ID]
) AS [count]
FROM [Subject] AS [t0]
LEFT OUTER JOIN [dbo].[Book] AS [t1] ON [t1].[Subject] = [t0].[ID]
ORDER BY [t0].[ID], [t1].[ID]
通过指定DataLoadOptions,避免了针对数据库的多次子查询。如果已经知道必需要访问这些子对象,那么使用这个功能会使你的程序反应灵敏。
注意到DataContext.LoadOptions在一个实例上只能设置一次,一旦设置完成,就不能再改变。DataLoadOptions提供了对结果的更强大的控制能力,但是需要小心使用。
简单的指定DataLoadOptions,在对结果进行两次迭代的情况下,并不能消除多次获取。为了完全消除多次获取,需要合并DataLoadOptions和ToList方法。这样,就可以保证只对数据库进行一次访问。
使用连接,SQL LINQ有了钻取数据的能力。这样就使得我们可以做一次映射后,把精力集中到业务需求上来。有时需要检查底层发生的数据库操作,以保证没有意外的情况发生。
6.6 更新数据
如果仅限于获取数据,那么SQL LINQ的功能可能不会好于一个报表工具。不过,更新数据和获取数据一样简单。只要我们有一个DataContext对象,就可以使用Table对象上的添加,修改和删除方法。DataContext将会跟踪这些变化,并且使用一次方法调用完成对数据库的更新。
示例中,需要对那些高价格的书籍进行一个折扣优惠活动。在这种情况下,我们获取了高价格的书籍-价格超过$30,然后对所有book的价格减$5,最后通过调用DataContext. SubmitChanges保存修改到数据库中。如列表6.28所示:
列表 6.28 更新数据到数据库
DataContext dataContext = new DataContext(liaConnectionString);
var ExpensiveBooks =
from b in dataContext.GetTable<Book>()
where b.Price>30
select b;
foreach (Book b in ExpensiveBooks)
{
b.Price -= 5;
}
dataContext.SubmitChanges();
提交到数据库的SQl如下所示:
UPDATE [Book]
SET [Price] = @p8
WHERE ([ID] = @p0) AND ([Isbn] = @p1) AND ([Notes] IS NULL) AND
([PageCount] = @p2) AND ([Price] = @p3) AND ([PubDate] = @p4) AND
([Summary] IS NULL) AND ([Title] = @p5) AND ([Subject] = @p6) AND
([Publisher] = @p7)
这段SQL看上去有些多余的地方。前两行已经完成了更新操作。余下的部分对并发冲突进行了检查。关于并发冲突,我们会在第八章讲述。但是重要的一点是,我们只对价格进行了更新,而不是所有列。这正是我们想要的。
知道了如何读取和更新数据,现在,让我们看一下如何做到CRUD的另外两个操作:创建和删除。通常,我们通过IList的Add和Remove方法进行集合对象的添加和删除操作。这些操作都是即时的。LINQ预发布版继续使用了这些特性,然而,用户也许会感到困惑, 因为在提交命令到数据库之前,后续的查询都不会感知到这些被创建和删除的数据。所以微软改变了方法的名称,通过InsertOnSubmit和DeleteOnSubmit这两个方法来保持语义的准确性。
使用SQL LINQ创建一个新项就像调用在table对象上调用InsertOnSubmit方法那么简单。对于删除操作,就是简单调用DeleteOnSubmit方法。列表 6.29添加一个新的Book到数据库中,随后又将其删除。
列表 6.29 从表中添加和删除项
DataContext dataContext = new DataContext(liaConnectionString);
Table<Book> books = dataContext.GetTable<Book>();
Book newBook = new Book();
newBook.Price = 40;
newBook.PublicationDate = System.DateTime.Today;
newBook.Title = "Linq In Action";
newBook.PublisherId = new Guid("4ab0856e-51f3-4b67-9355-8b11510119ba");
newBook.SubjectId = new Guid("a0e2a5d7-88c6-4dfe-a416-10eadb978b0b");
books.InsertOnSubmit(newBook);
dataContext.SubmitChanges();
books.DeleteOnSubmit(newBook);
dataContext.SubmitChanges();
如果检查产生的SQL代码,将会发现添加一条记录就是一个简单的INSERT INTO语句。删除一条记录要比DELETE FROM语句稍微复杂一些。多于的那些SQL代码是为了处理并发性问题。使用这些基本的对象方法,我们可以执行所有标准的CRUD方法。DataContext跟踪所有改变并自动产生SQL来完成请求的操作。
6.7 摘要
本章中,我们阐述了如何实现对象关系映射。一旦建立了映射关系,就可以执行所有的标准查询和扩展方法。在以前ADO.NET中,我们必须手动编写那些数据访问代码。但是使用SQL LINQ,一旦映射建立,我们就可以忽略那些数据库交互的细节。从而可以将注意力集中到业务层面上,而不是实现细节上。
此外SQL LINQ继承了Object LINQ的能力,它可以对结果进行预处理。同时利用了索引等数据库提供的数据处理能力。我们建议您花些时间来实践一下本章的那些示例。加深对SQL LINQ的理解。
在下一章中,我们会深入探讨SQL LINQ的特性和一些工具。了解SQL LINQ的一些更高级的特性。















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









