







更多优质内容,请关注公众号:智驾机器人技术前线
1.论文信息
-
论文标题:TranSplat: Generalizable 3D Gaussian Splatting from Sparse Multi-View Images with Transformers
-
作者:Chuanrui Zhang1∗, Yingshuang Zou1∗, Zhuoling Li, Minmin Yi, Haoqian Wang1†
-
作者单位:清华大学,香港大学,E-surfing Vision Technology Co., Ltd
-
论文链接:https://arxiv.org/abs/2408.13770
-
项目地址:https://xingyoujun.github.io/transplat/#todo
2.摘要
与之前的3D重建方法如NeRF相比,最新的通用3D高斯溅射(G-3DGS)方法即使在稀疏视图设置中也展现出了令人印象深刻的效率。然而,现有G-3DGS方法的有前景的重建性能在很大程度上依赖于准确的多视图特征匹配,这相当具有挑战性。特别是对于在不同视图之间有许多不重叠区域并且包含许多相似区域的场景,现有方法的匹配性能较差,重建精度有限。为了解决这个问题,我们开发了一种策略,利用预测的深度置信图来指导准确的局部特征匹配。此外,我们提出利用现有的单目深度估计模型的知识作为先验,以提高视图之间不重叠区域的深度估计精度。结合所提出的策略,我们提出了一种名为TranSplat的新型G-3DGS方法,该方法在RealEstate10K和ACID基准测试中均取得了最佳性能,同时保持了竞争速度,并展现出强大的跨数据集泛化能力。
3.主要贡献
-
提出利用深度置信图来增强不同视图之间的匹配,并相应地显著提高在纹理不足或重复模式区域的重建精度;
-
提出了一种策略,将单目深度估计器的先验编码到高斯参数的预测中,确保即使在不重叠的区域也能精确估计3D高斯中心;
-
衍生的方法TranSplat在两个大规模基准测试中取得了最佳结果,并展现出强大的跨数据集泛化能力。
4.核心思想与方法
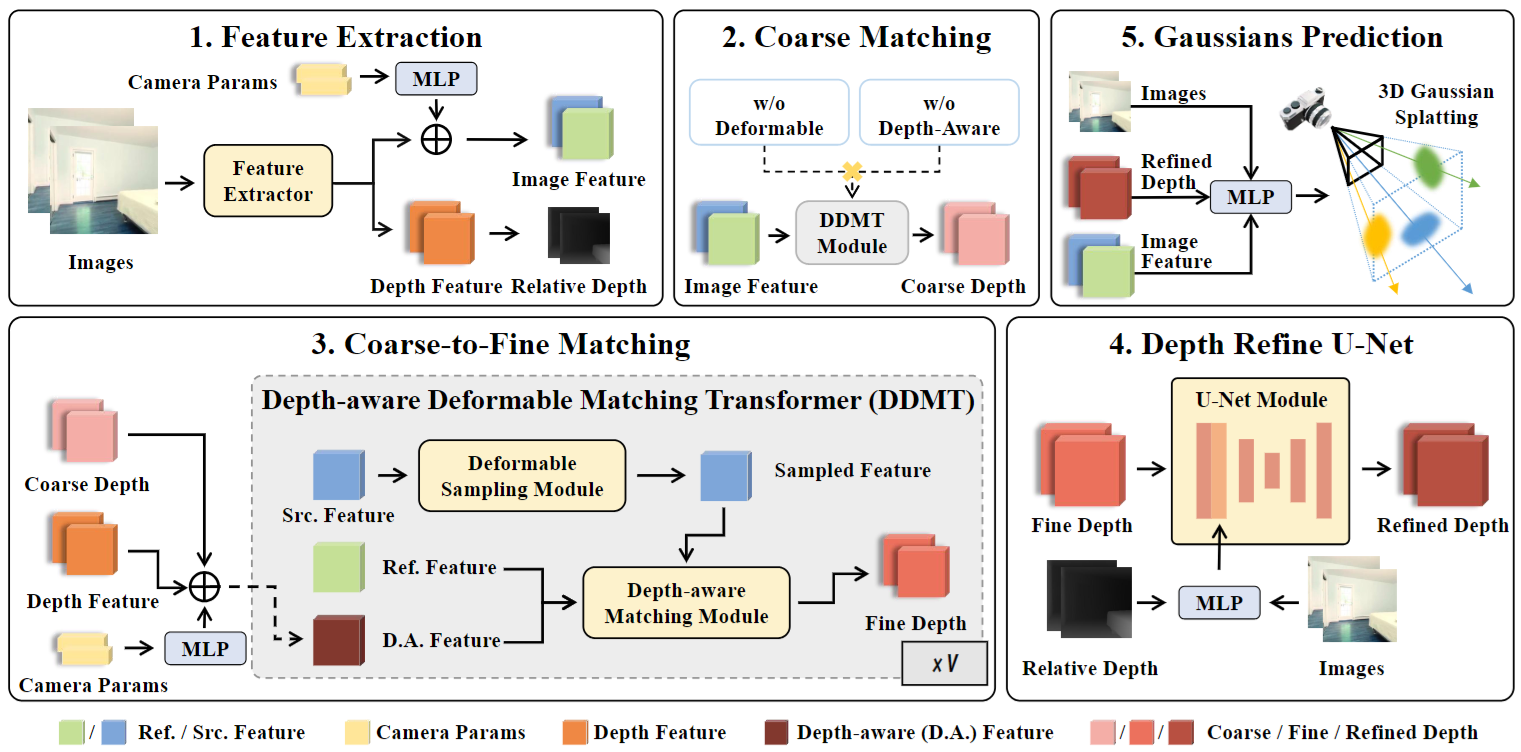
算法框架
本文的方法以多视图图像为输入,首先提取图像特征和单目深度先验。接下来,使用从粗到细的匹配阶段来获得每个视图的几何一致的深度分布。具体来说,使用我们提出的深度感知可变形匹配变换器模块计算多视图特征相似性。然后,使用深度细化U-Net进一步细化深度预测。最后,预测像素级的3D高斯参数以渲染新视图。
5.实验仿真验证

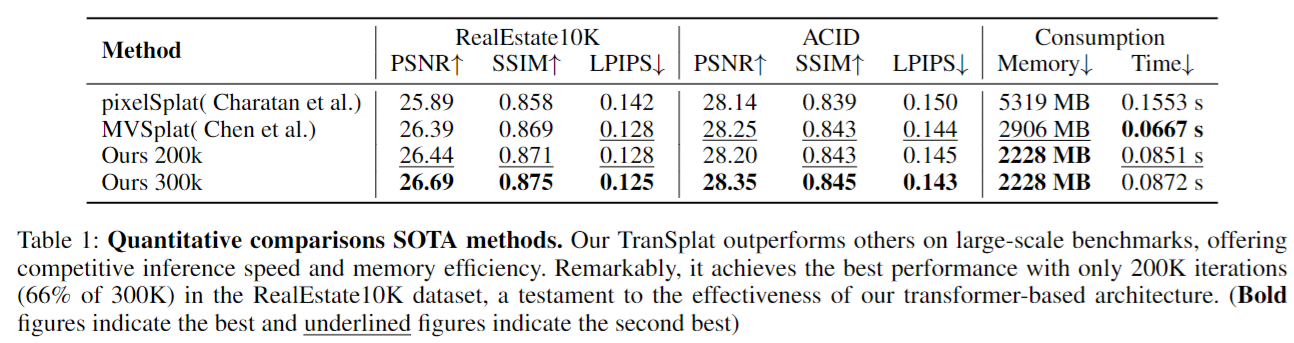
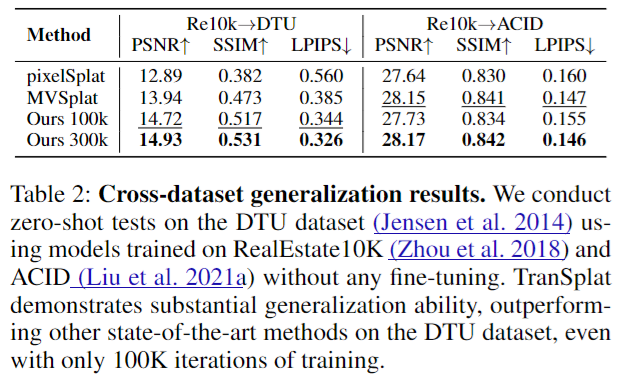
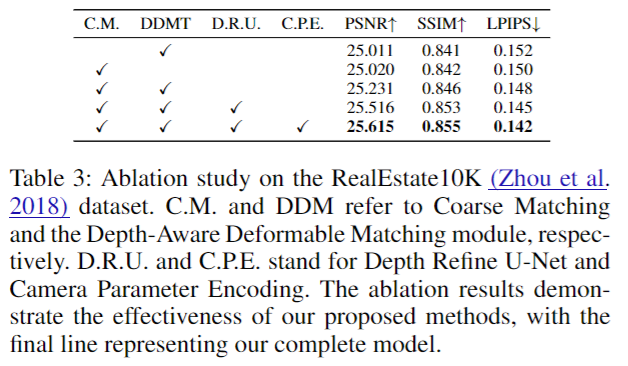
6.总结&局限
在这项工作中,我们介绍了TranSplat,这是一种新颖的、可泛化的稀疏视图场景重建网络,它采用了基于变换器的架构。配备多视图输入,我们的方法预测一组3D基元高斯来表示场景。为了解决由相似区域引起的错误匹配,我们提出了深度感知变形匹配变换器,它增强了对准确深度分布的关注。为了改进非重叠区域的3D高斯,我们设计了深度细化模块,该模块使用单目深度先验优化深度图。我们的方法在两个大规模场景级重建基准测试中实现了最先进的性能,并展示了优越的跨数据集泛化能力。
局限性:我们按像素预测3D高斯基元,这可能导致物体侧面的点数较少,旋转物体时可能造成间隙。探索生成更有意义的3D高斯以表示物体侧面的方法将是有趣的。

本文仅做学术分享,如有侵权,请联系删文!
更多优质内容,请关注公众号:智驾机器人技术前线
















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









