






高级SQL LINQ特性
8.1 处理并发变化
当我们设计一个单用户系统的时候,开发人员不需要担心一个用户的修改对其它用户的影响。但是单用户系统的情况很少。如果系统要支持多用户,我们就需要负责处理两个用户同时改变同一记录会引发的问题。一般情况下,有两种策略来处理这种问题:悲观并发性:同一个时间内,只允许一个用户修改记录。乐观并发性:允许多个用户同时修改记录。在乐观并发性的情况下,设计人员需要决定要保留第一个用户的修改还是使用最后一次修改,或者合并多个修改。每个策略都有自己的优点和缺点。
8.1.1 悲观并发性
在.NET之前,许多程序维护着一些打开的数据库连接。在这种系统中,用户从数据库中获取一条记录并对该记录加锁来防止其它用户进行修改。这种锁称为悲观并发性。小的windows程序使用这种方法很少遇到问题。然而,如果用户急剧增加,那么这种处理方法将会使系统陷于停滞状态。在Web时代无状态结构的程序面前,悲观并发性已经不能适应用户的需求。
8.1.2 乐观并发性
由于在无连接的条件下遇到的问题,人们使用了乐观并发性模型,该模型允许用户在自己的数据拷贝上进行修改。当需要保存修改的时候,程序会检查原始值是否已被改变。如果没有改变,那么该记录将被保存。如果记录值已经改变,那么程序需要知道是否应该继续保存,或者放弃修改或者是合并修改。
如果没有并发性检查,那么发送到数据库的SQL语句应该遵循这样的语法:UPDATE TABLE SET [field = value] WHERE [Id = value]。如果加入乐观并发性检查,将会附加一个检查并发的WHERE子句。列表8.1在Book表上进行了乐观并发性检查。
列表8.1 使用乐观并发性对Book表进行更新
UPDATE dbo.Book SET
Title = @NewTitle,
Subject = @NewSubject,
Publisher = @NewPublisher,
PubDate = @NewPubDate,
Price = @NewPrice,
PageCount = @NewPageCount,
Isbn = @NewIsbn,
Summary = @NewSummary,
Notes = @NewNotes
WHERE ID = @ID
AND Title = @OldTitle
AND Subject = @OldSubject
AND Publisher = @OldPublisher
AND PubDate = @PubDate
AND Price = @Price
AND PageCount = @PageCount
AND Isbn = @OldIsbn
AND Summary = @OldSummary
AND Notes = @OldNotes
RETURN @@RowCount
如果以上代码返回0,那么标识数据库的原始值已经被修改,就需要提示用户,让其进行合适的处理。现在,这种并发检查已经内置在SQL LINQ中了。配置类使其进行乐观并发性检查非常的简单。实际上,通过建立表和列的映射,我们已经设置了乐观并发性。当调用SubmitChanges的时候。DataContext将会自动实现乐观并发性。为了阐明更新时产生的SQL语句,考虑以下示例:获取最贵的书籍并对其打折10%的处理。(列表8.2)
列表8.2 SQL LINQ处理并发的默认实现
Ch8DataContext context = new Ch8DataContext()
Book mostExpensiveBook =
(from book in context.Books
orderby book.Price descending
select book).First();
decimal discount = .1M;
mostExpensiveBook.Price -= mostExpensiveBook.Price * discount;
context.SubmitChanges();
这将会产生如下的SQL语句:
UPDATE [dbo].[Book] SET [Price] = @p8
FROM [dbo].[Book]
WHERE ([Title] = @p0) AND ([Subject] = @p1) AND ([Publisher] = @p2)
AND ([PubDate] = @p3) AND ([Price] = @p4) AND ([PageCount] = @p5) AND ([Isbn] = @p6) AND ([Summary] IS NULL) AND ([Notes] IS NULL) AND ([ID] = @p7)
当调用DataContext.SubmitChanges方法的时候,Update语句将被发送到服务器。如果受到影响的行数为零,那么DataContext将会意识到原来的记录被其它用户修改了。此时程序将会抛出一个ChangeConflictException。在这种情况下,为了实现乐观并发性,参数的多少可能会降低程序的性能。在这种情况下,我们需要改善我们的映射,标识那些必须进行检查的列和一些不需要检查的列。通过设置UpdateCheck属性可以做到这点。默认情况下,UpdateCheck总是设置为Always,这表示SQL LINQ总是对此列进行检查。我们可以将其设置为只有在值改变的时候才检查(WhenChanged),或者从不检查(Never)。
如果我们要利用UpdateCheck属性的强大威力,并且有能力修改数据库设计,我们可以为每个表添加一个RowVersion或者一个TimeStamp列。当记录值改变的时候,数据库会自动更新该记录的RowVersion值。并发性检查只需要对RowVersion列和ID列上进行检查,其它的列可以全部设置为UpdateCheck=Never。在第7章我们使用了这种方法。列表8.3阐述了修改后的Author类,使用TimeStamp列来进行并发检查。
Listing 8.3 使用TimeStamp 列进行乐观并发检查
Ch8DataContext context = new Ch8DataContext();
Author authorToChange = (context.Authors).First();
authorToChange.FirstName = "Jim";
authorToChange.LastName = "Wooley";
context.SubmitChanges();
产生的SQL如下:
UPDATE [dbo].[Author]
SET [LastName] = @p2, [FirstName] = @p3
FROM [dbo].[Author]
WHERE ([ID] = @p0) AND ([TimeStamp] = @p1)
SELECT [t1].[TimeStamp]
FROM [dbo].[Author] AS [t1]
WHERE ((@@ROWCOUNT) > 0) AND ([t1].[ID] = @p4)
除了使用timestamp列外,还有很多处理并发的模型。第一个选择就是简单忽略任何并发变化而总是更新记录,允许接受最后的更新。在这种情况下,需要设置所有的属性的UpdateCheck值为Never。除非你能确保并发性不是问题,否则不要使用这种解决方案。在大多数情况下,都应当通知用户发生了冲突,并提供一些选择进行继续处理。
在有些情况下,允许用户修改同一个表的不同的列是可行的。例如,在一个大表中,也许需要用不同的对象管理不同列的集合,在这种情况下,将UpdateCheck设置为WhenChanged是一个很好的解决方案。目前为止,我们已经能够检测到更新冲突了,接下来要做的就是处理这些冲突。
8.1.3 处理并发性异常
当我们使用Always或者WhenChanged进行UpdateCheck的时候,不可避免的要产生更新冲突,这种情况下,DataContext将会抛出一个ChangeConflictException异常。所以我们需要将更新代码包装在一个异常处理模块中。
一旦异常被抛出,有很多选项用来解决这个问题。DataContext不仅能发现那些冲突的对象,而且还能检测那些属性值发生了变化。它为我们提供了每个属性的原始值,变化的值和数据库中的值。我们需要指定RefreshMode来决定需要保留哪些值。列表8.4显示了如何保留我们对数据的改变。
列表8.4 使用KeepChanges解决变化冲突
try
{
context.SubmitChanges(ConflictMode.ContinueOnConflict);
}
catch (ChangeConflictException)
{
context.ChangeConflicts.ResolveAll(RefreshMode.KeepChanges);
context.SubmitChanges();
}
如果我们使用KeepChanges选项,就不需要检查变化的值,我们断定我们的值是正确的。这种“最后就是胜者”的方法可能具有潜在的危险性。那些我们没有更新的列值将会被数据库的现有值取代。如果将RefreshMode设置为KeepCurrentValues,那么我们程序中对象的值将会全部覆盖数据库中的值,这种情况更加危险,因为其它的用户的修改将会完全丢失(原著的讲述有误)。为了安全起见,应该获取其它用户所作的修改,并放弃自己的修改,然后让用户决定如何处理这种冲突。使用
如果业务上有需要,我们可以进行变化的合并。将RefreshMode设置为KeepCurrentValues可以做到这点。使用RefreshMode.OverwriteCurrentValues可以做到这点,这种情况下,将不会有SQL提交到数据库。
当使用DataContext.SubmitChanges方法提交变化的时候,你可能想把能够提交的没有冲突的改变一次提交,而后一次性处理那些冲突的改变。也有可能想在首次遇到冲突的情况就停止继续提交。使用ConflictMode参数可以实现这种选择,ContinueOnConflict选项对应前者,而FailOnFirstConflict选项对应后者。列表8.5显示了一次性提交所有不冲突记录,然后处理那些冲突的记录,放弃当前修改而使用数据库的值。
列表8.5 使用用户的值替换数据库的值
try
{
context.SubmitChanges(ConflictMode.ContinueOnConflict);
}
catch (ChangeConflictException)
{
context.ChangeConflicts.ResolveAll(RefreshMode.OverwriteCurrentValues);
}
然而这种处理方法仍有缺点, 用户不能及时获知其它用户的修改。所以不能及时作出处理的决定,一种好的解决方案是展示给用户那些引发冲突的字段的各个值。列表8.6阐述了如何使用DataContext.ChangeConflicts集合做到这些。
列表8.6 显示冲突细节
try
{
context.SubmitChanges(ConflictMode.ContinueOnConflict);
}
catch (ChangeConflictException)
{
var exceptionDetail =
from conflict in context.ChangeConflicts
from member in conflict.MemberConflicts
select new
{
TableName = context.GetTableName(conflict.Object),
MemberName = member.Member.Name,
CurrentValue = member.CurrentValue.ToString(),
DatabaseValue = member.DatabaseValue.ToString(),
OriginalValue = member.OriginalValue.ToString()
};
ObjectDumper.Write(exceptionDetail);
}
ChangeConflicts的每个元素都包含一个对象引发的冲突信息。而此对象又包含一个MemberConflicts集合,该集合中的每个元素又包含每一个成员的冲突信息,包括CurrentValue, DatabaseValue,和OriginalValue等。一旦我们获取了这些信息,就可以合适的展示给用户。图8.1展示了用户更新价格时引发的冲突信息。
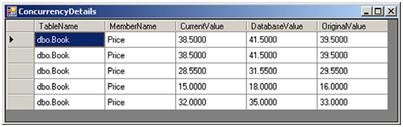
图 8.1 显示并发冲突信息
在设计一个多用户系统的时候,我们需要考虑如何处理并发性。在大多数情况下,不是是否抛出一个ChangeConflictException异常的事情,而是何时和如何处理ChangeConflictException异常。可以使用以上的处理方法,也可以撤销整个事务。这就是我们下面要讲述的。
8.1.4 使用事务解决冲突
如果需要更新的记录集合必须要一次性提交,而不能只提交一部分。那么前面讲述的处理方法就会不能工作。因此我们需要事务来处理这种情况。
SQL LINQ提供了三种管理事务的方式。第一种情况是使用ContinueOnConflict.FailOnFirstConflict参数来获得事务支持,让SubmitChanges方法在执行过程中出现冲突的时候,那么已经提交的变化就会自动撤销。
如果我们要手动维护一个事务,DataContext同样有能力完成这些,使用DataContext维护的数据库连接可以BeginTransaction。列表8.7阐述了这种管理事务的用法。
列表 8.7 使用DataContext管理事务
try
{
context.Connection.Open();
context.Transaction = context.Connection.BeginTransaction();
context.SubmitChanges(ConflictMode.ContinueOnConflict);
context.Transaction.Commit();
}
catch (ChangeConflictException)
{
context.Transaction.Rollback();
}
使用DataContext直接管理事务的方法不能扩展到多连接或者多DataContext对象上。作为第三种选择,.NET 2.0 Framework d的System.Transactions.TransactionScope类被设计用来实现跨越连接的事务。使用之前,需要添加System.Transactions库的引用。
TransactionScope的实例将会自动根据跨越连接的数量来扩展事务。如果事务在一个数据库调用内,那么它将使用简单的数据库事务,如果事务跨越了多个连接,那么它会自动将事务升级为企业级事务。此外TransactionScope不需要我们显式的开始或者回滚。所有要做的就是需要对其调用Complete。列表8.8阐述了如何使用TransactionScope。
列表8.8 使用TransactionScope 对象管理事务
using (System.Transactions.TransactionScope scope =new System.Transactions.TransactionScope())
{
context.SubmitChanges(ConflictMode.ContinueOnConflict);
scope.Complete();
}
不像其它的事务处理机制,我们不需要将代码包装到try catch块中,使用TransactionScope的时候,事务会在调用Complete的时候自动提交。如果在调用SubmitChanges方法的时候发生了异常,那么Compete方法将被跳过。我们不需要显式回滚事务。真正让人感到兴奋的是,TransactionScope对象将会根据给定的上下文自动升级,所以,对于单个数据源还是多个不同类型的数据源,代码是相同的。因为这种灵活性和可扩展性,使用TransactionScope将是处理事务的首选方法。
8.2 高级数据库特性
8.2.1 直接执行SQL: 从SQL查询返回对象
虽然LINQ为我们展示了访问数据的革命性的强大能力,但是基于对象的查询需要预先编译。当我们需要一种更灵活的模型的时候,需要直接执行SQL语句而不是预先编译。同样使用DataContext对象,就可以完成这种工作,只需要把SQL语句直接传递给DataContext.ExecuteQuery方法就可以了。如列表8.9所示:
列表8.9 执行动态SQL语句
string searchName;
string sql = @"Select ID, LastName, FirstName, WebSite, TimeStamp " +
"From dbo.Author Where LastName = '" + searchName + "'";
IEnumerable<Author> authors = context.ExecuteQuery<Author>(sql);
这些代码比标准的ADO.NET代码少了很多。当我们使用ExecuteQuery方法的时候,不用担心数据的来源。重要的是SQL中选择的列名称需要与映射信息中设定的相同。因为整个查询都是弱类型,所以需要小心验证用户提供的值以防止SQL注入攻击和其它问题。为了避免这种情况,可以使用ExecuteQuery 方法的一个类似String.Format方法的重载来构造SQL查询。这种情况下,提供的值将会以参数的形式出现。列表8.10扩展了前面的示例,DataContext对象将查询转换为一个参数化查询。由此可以阻止恶意用户的注入攻击。
列表8.10 使用参数化的动态SQL查询
string searchName = "Good' OR ''='";
Ch8DataContext context = new Ch8DataContext();
string sql =@"Select ID, LastName, FirstName, WebSite, TimeStamp " +
"From dbo.Author Where LastName = {0}";
ObjectDumper.Write(context.ExecuteQuery<Author>(sql, SearchName));
查看产生的SQL,可以看到查询已经被参数化,从而防止了注入攻击。
Select ID, LastName, FirstName, WebSite, TimeStamp
From dbo.Author
Where LastName = @p0
8.2.2 使用存储过程
虽然标准的SQL LINQ提供了很好的CRUD操作,但是往往业务需求要求你必须使用存储过程。使用存储过程的原因一般都是为了解决安全,性能,审计和额外的功能。在有些情况下,参数化查询从安全性和性能上降低了使用存储过程的必要性,从性能方面来看,参数查询的执行计划被计算一次,然后缓存起来,就像存储过程一样。从安全角度来看,参数化查询同样消除了可能的SQL注入攻击。不过SQL LINQ需要表级别上的权限,对于有些DBA来说,他们可能不太情愿。而使用存储过程可以让DBA控制数据访问和定制索引模式。然而如果使用存储过程,那么我们就需要分别创建CRUD SQL语句,而且不能限制更新的列数。虽然如此,如果需要使用存储过程,SQL LINQ还是为我们提供了便利。
使用存储过程读取数据
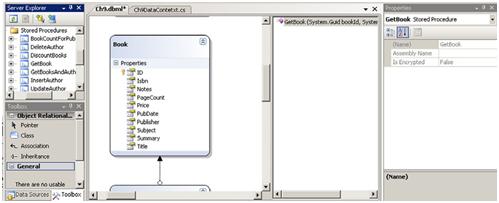
以从数据库查询book信息为例,为了阐述存储过程能作的额外的操作,我们将在AuditTracking表中添加一条审计信息。该名为GetBook的存储过程接受BookId和当前用户名为参数,返回指定Id的Book信息。为了添加一个存储过程的包装,打开包含Book类SQL LINQ设计器,在服务管理器中展开存储过程节点。从服务管理器中拖动GetBook节点到设计器中。结果如图8.2所示。
图 8.2 在SQL LINQ设计器中添加GetBook存储过程
SQL LINQ会将存储过程作为一个方法进行调用。如列表8.11所示。
列表8.11 使用一个返回结果的存储过程
Guid bookId = new Guid("0737c167-e3d9-4a46-9247-2d0101ab18d1");
Ch8DataContext context = new Ch8DataContext();
IEnumerable<Book> query = context.GetBook(bookId,
System.Threading.Thread.CurrentPrincipal.Identity.Name);
注意到存储过程方法返回的结果是IEnumerable<T>而不是IQueryable<T>类型。接下来,让我们看一下自动产生的代码是如何使用DataContext调用一个存储过程的。查看后置代码文件,可以看到代码如列表8.12所示。
列表8.12 产生调用GetBook 存储过程的代码
[Function(Name="dbo.GetBook")
public ISingleResult<Book> GetBook(
[Parameter(Name="BookId", DbType="UniqueIdentifier")] System.Nullable<System.Guid> bookId,[Parameter(Name="UserName", DbType="NVarChar(50)")] string userName)
{
IExecuteResult result = this.ExecuteMethodCall( this,
((MethodInfo)(MethodInfo.GetCurrentMethod())),
bookId,
userName);
return ((ISingleResult<Book>)(result.ReturnValue));
}
实现调用存储过程的代理方法,不仅需要我们导入System.Data.Linq命名空间,还需要导入System.Data.Linq.Mapping和System.Reflection命名空间。对于GetBook方法,它调用了GetBook存储过程,并传递一个BookId参数及当前用户名。该方法将会返回一个ISingleResult<Book>类型的对象,ISingleResult并不返回单个对象,而是一个对象列表,如果我们的存储过程返回了多个结果集,那么我们需要使用IMultipleResult类型。
为了将我们的方法映射到存储过程上,我们需要指定一系列属性,第一个为应用在方法GetBook上的Function属性,他又一个Name参数指定映射的存储过程名称。接下来,我们需要指定方法的参数和存储过程参数之间的映射关系。通过使用System.Data.Linq.Mapping.Parameter属性建立映射关系,一旦映射建立完毕,我们就可以进行方法调用了。
为了调用一个存储过程,DataContext包含了一个名称ExecuteMethodCall的方法。我们可以通过使用这个方法返回结果集,标量值或者处理其它的语句。因为我们已经创建了一个从DataContext继承的类,我们可以在类中直接调用此方法。
ExecuteMethodCall方法需要三个参数,第一个是调用此方法的DataContext的实例,第二个是调用它的方法的MethodInfo对象。使用反射,通过MethodInfo.GetCurrentMethod()可以得到当前正在执行的方法的实例。最后一个参数是一个参数数组,这些就是存储过程需要的参数。数组中的参数必须和存储过程中参数一一对应。如果它们不匹配,将会引发一个运行时异常。图8.3显示ExecuteMethodCall返回的接口。
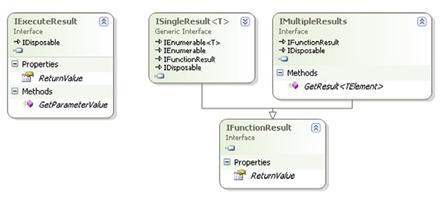
图 8.3 ExecuteMethodCall返回结果实现的接口
IExecuteResult暴露了一个Object类型的ReturnValue属性和可以访问参数值的接口。如果存储过程返回了一个强类型对象列表。我将会强制转换ReturnValue为ISingleResult<T>类型。如果存储过程返回了多个结果,还可以将ReturnValue转换为IMultipleResults类型,之后可以通过泛型的GetResult<TElement>方法访问每个结果。
通过存储过程返回数据不只局限于表和结果集。还可以只返回一个标量值。列表8.13阐述了如何访问BookCountForPublisher存储过程返回的指定的publisher的book数量。
列表8.13 返回标量值
[Function(Name="dbo.BookCountForPublisher")]
public int BookCountForPublisher(
[Parameter(Name="PublisherId", DbType="UniqueIdentifier")]
System.Nullable<System.Guid> publisherId)
{
IExecuteResult result = this.ExecuteMethodCall(this,
((MethodInfo)(MethodInfo.GetCurrentMethod())), publisherId);
return ((int)(result.ReturnValue));
}
使用存储过程更新数据
如果使用存储过程更新数据是必须的,那么不用担心,SQL LINQ让一切变得简单。不过我们从此失去了只更新那些变化的列的能力。此外我们需要自己写代码处理并发冲突。让我们看看如何使用存储过程更新Author信息。
列表8.15显示了更新Author表的存储过程定义。为了阐述存储过程额外的能力,我们不只更新了Author表,而且在AuditTracking表插入了一条记录用于审计。
列表8.15 更新Author表的存储过程
CREATE PROCEDURE [dbo].[UpdateAuthor]
@ID UniqueIdentifier output,
@LastName varchar(50),
@FirstName varchar(50),
@WebSite varchar(200),
@UserName varchar(50),
@TimeStamp timestamp
AS
DECLARE @RecordsUpdated int
UPDATE dbo.Author
SET LastName=@LastName, FirstName=@FirstName, WebSite=@WebSite
WHERE ID=@ID AND
[TimeStamp]=@TimeStamp
SELECT @RecordsUpdated=@@RowCount
IF @RecordsUpdated = 1
INSERT INTO dbo.AuditTracking
(TableName, UserName, AccessDate) VALUES ('Author', @UserName, GetDate())
END
RETURN @RecordsUpdated
存储过程中需要注意的一点是:一旦更新完成,那么应该立刻获取改变的行数,否则@@RowCount返回的结果可能并不可靠。
下面,我们创建了一个方法来使用这个存储过程(如列表8.16)。
列表 8.16 使用LINQ调用用来更新的存储过程
[Function(Name="dbo.UpdateAuthor")]
public int AuthorUpdate(
[Parameter(Name="ID")] Guid iD,
[Parameter(Name="LastName")] string lastName,
[Parameter(Name="FirstName")] string firstName,
[Parameter(Name="WebSite")] string webSite,
[Parameter(Name="UserName")] string userName,
[Parameter(Name="TimeStamp")] byte[] timeStamp)
{
if (userName == null)
{
userName=Thread.CurrentPrincipal.Identity.Name;
}
IExecuteResult result = this.ExecuteMethodCall(this,
((MethodInfo)(MethodInfo.GetCurrentMethod())),
iD, lastName, firstName, webSite, userName, timeStamp);
iD = (Guid)(result.GetParameterValue(0));
int RowsAffected = ((int)(result.ReturnValue));
if (RowsAffected==0)
{
throw new ChangeConflictException();
}
return RowsAffected;
}
对于更新数据,和选择数据的调用方式基本相同。下面的代码展示了如何调用由设计器产生的方法。如列表8.17所示。
列表8.17 调用UpdateT(T instance) 方法
private void UpdateAuthor(Author instance)
{
this.UpdateAuthor(instance.ID, instance.LastName, instance.FirstName,
instance.WebSite, null, instance.TimeStamp);
}
到目前为止,我们阐述了如何手动编写使用存储过程的代码。在多数情况下,使用设计器产生调用存储过程的代码将会更加简单。在图8.4中,再次显示了Visual Studio设计器。这次,请注意四个面板:服务器管理器,方法面板的两面,属性窗口。为了从存储过程产生一个方法,只需要简单的拖拽存储过程到方法面板中,就会自动产生方法签名。
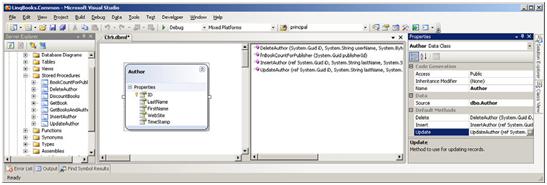
图8.4 使用设计器产生调用存储过程的方法
一旦添加了存储过程,我们可以配置自定义的Insert, Update和Delete方法,选择Author类并查看属性窗口。每个自定义存储过程方法就会出现,如果我们选择Update属性,然后点击按钮,就会打开如图8.5的设计器。
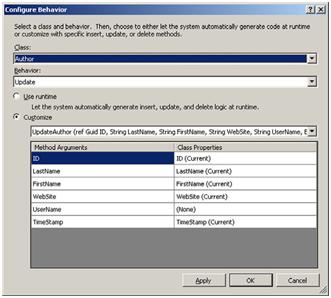
图8.5 关联存储过程与CRUD操作
默认情况下,Insert, Update和Delete方法的行为都被设置为Runtime。当其设置为Runtime的时候,DataContext将会自动产生Insert, Update和Delete方法。为了改变这种特性,选择Customize选项来定义你需要改变的行为。首先选择要定制的方法,然后选择定义的存储过程。一旦选择了存储过程,那么就可以进行方法参数的定制。如果想要进行额外的检查,如上例,需要把UserName参数的对应的属性设置为None,然后点击确定按钮。需要注意的是,如果我们需要对实现进行改变,就需要在partial类中做到这点,而不要在desinger.cs中去修改, 因为任何对designer.cs文件的改变都将被设计器中的其它修改覆盖。
8.2.3 使用自定义函数
许多数据-中心的应用程序只使用存储过程过程来进行数据访问。有一种可能比存储过程更易于使用的方法是用户自定义函数。两个主要的用户自定义函数类型是标量和表值函数。标量函数返回单个值,这种函数对于快速查找业务非常方便。表值函数与存储过程类似,但是用户自定义函数中可以添加额外的功能。此外,用户自定义函数的结果可以方便的被多个服务器端查询重用。
为了学习如何使用用户自定义函数,让我们复习一下列表8.13所示存储过程。它返回了指定出版社的书籍数量。接着我们创建了一个名为fnBookCountForPublisher的实现同样功能的自定义函数。如列表8.18所示:
列表8.18 用户自定义标量函数
CREATE FUNCTION dbo.fnBookCountForPublisher
(@PublisherId UniqueIdentifier ) RETURNS int
AS
BEGIN
DECLARE @BookCount int
SELECT @BookCount = count(*) FROM dbo.Book
WHERE dbo.Book.Publisher=@PublisherId
Return @BookCount
END
使用SQL LINQ调用用户自定义函数的方法与存储过程的调用类似。将用户自定义函数从服务器管理器中拖入SQL LINQ设计器,然后保存,就可以看到设计器自动生成的代码,如列表8.19所示:
列表8.19 设计器生成的包装自定义函数的代码
[Function(Name = "dbo.fnBookCountForPublisher", IsComposable = true)]
public int? fnBookCountForPublisher1(
[Parameter(Name = "PublisherId")] Guid? publisherId)
{
return (int?)(this.ExecuteMethodCall( this,
((MethodInfo)(MethodInfo.GetCurrentMethod())), publisherId).ReturnValue);
}
由此可以看到,使用自定义函数和存储过程的唯一区别就是使用了IsComposable属性,将其设置为true,表示映射到一个自定义函数。设置为false,将其映射到一个存储过程。列表8.20的代码使用了自定义函数,整个查询都在服务端执行。
列表8.20 在查询中使用自定义函数
var query =
from publisher in context.GetTable<Publisher>()
select new
{
publisher.Name,
BookCount = context.fnBookCountForPublisher(publisher.ID)
};
下面是发送到服务器的的SQL查询:
SELECT Name, CONVERT(Int, dbo.fnBookCountForPublisher(ID)) AS value
FROM Publisher AS t0
使用自定义函数返回表同样很简单,示例函数根据指定出版社ID返回了它所属的Book信息。包装该自定义函数的代码如列表8.21所示:
列表8.21 包装用户自定义表函数
[Function(Name = "dbo.fnGetPublishersBooks", IsComposable = true)]
public IQueryable<Book> fnGetPublishersBooks(
[Parameter(Name = "Publisher", DbType = "UniqueIdentifier")] System.Nullable<System.Guid> publisher)
{
return this.CreateMethodCallQuery<Book>(this,
((MethodInfo)(MethodInfo.GetCurrentMethod())), publisher);
}
在本示例中,我们使用了返回IQueryable接口的CreateMethodCallQuery方法,这允许我们继续组合查询。列表8.22阐述了如何使用该用户自定义函数。
列表8.22 使用用户自定义函数
Guid publisherId = new Guid("855cb02e-dc29-473d-9f40-6c3405043fa3");
var query1 =
from book in context.fnGetPublishersBooks(publisherId)
select new
{
book.Title,
OtherBookCount = context.fnBookCountForPublisher(book.Publisher) - 1
};
该查询对应的SQL语句如下:
SELECT Title, CONVERT(Int, dbo.fnBookCountForPublisher(Publisher)) - @p1 AS value
FROM dbo.fnGetPublishersBooks(@p0) AS t0
至此,我们已经学习了许多SQL LINQ的高级特性,下面让我们对象视角观察SQL LINQ的一些特性。
8.3改进业务层
当工作于业务层的时候,我们会集中关注性能,可维护性和代码重用。本节中,就让我们看看SQL LINQ提供了那些我们可以利用的功能来提高我们的业务层设计。
8.3.1 编译的查询
只要加入了一个复杂的层,那么性能就会降低。在系统的性能和可维护性上做决定就像是鱼与熊掌。LINQ也不例外。在转换LINQ查询语法上需要额外的时间。这些时间花费在反射映射数据,解析查询到表达式树和构造SQL语句上。如果一个LINQ查询被重复使用,那么可以对查询进行一次分析,然后保存进行多次使用。为了定义一个可重用的查询,可以使用CompiledQuery.Compile方法。在数据上下文中,我们推荐使用静态字段和非静态方法。这个方法返回一个泛型函数定义。列表8.23阐述了如何创建一个预编译的查询,该查询用来返回那些高价格的书籍,通过传递一个最低价格来决定什么样的书籍才算是高价的。除了价格值之外,整个查询结果将会被预编译。此后只需要指定DataContext实例和参数值,查询即将被执行。
列表 8.23 预编译查询
public static Func<CustomContext, decimal, IQueryable<Book>>
ExpensiveBooks = CompiledQuery.Compile(
(Ch8DataContext context, decimal minimumPrice) =>
from book in context.Books
where book.Price >= minimumPrice select book);
public IQueryable<Book>
GetExpensiveBooks(decimal minimumPrice)
{
return ExpensiveBooks(this, minimumPrice);
}
列表8.23包含了两个新成员,首先ExpensiveBooks是一个静态字段,它包含了预编译的查询定义。第二个方作为封装ExpensiveBooks调用的帮助方法。通过使用System.Data.Linq.CompiledQuery. Compile方法并提供一个定义查询的lambda表达式。它会预编译查询。又因为我们使用了静态字段,所以在我们的AppDomain中查询将会只编译一次。之后再次进行查询,将不会消耗额外的转换开销。
如果你对使用预编译查询不是那么确定,请阅读Rico Mariani发表的文章:http://blogs.msdn.com/ricom/archive/2007/06/22/dlinq-linq-to-sql-performance-part-1.aspx. 他展示了使用预编译查询时的性能是不使用时的两倍,而且是使用DataReader时的93%。因为LINQ还在不断改进,所以,它还将提供更好的性能。
下面将会更多的讨论可维护性和重用的问题。因为通常情况下,获取一点性能的代价是极大的降低了程序的可维护性。
8.3.2 利用Partial 类定义业务逻辑
使用面向对象的编程实践需要利用基本的对象结构,然后对其进行功能扩展。在.NET 2.0时,主要的方法就是使用从基类继承的方法。使用partial类,我们可以使用单独的文件分离功能集合,然后让编译器把它们编译为一个类。Partial类在处理自动产生的代码的时候非常有用。默认情况下,通过代码自动产生的工具(设计器和SqlMetal)产生的代码都是partial类。结果,我们可以利用代码自动产生工具的同时,又可以在单独的类文件中进行业务逻辑定义。列表8.24显示了为Author类添加功能的代码,利用了partial关键字的功能。
列表8.24 使用partial 为类添加功能
public partial class Author
{
public string FormattedName
{
get
{
return this.FirstName + ' ' + this.LastName;
}
}
}
使用这种方法能够让我们避免工具自动产生的代码对我们产生的影响。Partial类还可以用来实现接口,如列表8.26所示:
列表8.26 在partial类中实现IDataErrorInfo 接口
partial class Publisher : System.ComponentModel.IDataErrorInfo
{
private string CheckRules(string columnName)
{
//See the download samples for the implementation
//All rules are ok, return an empty string return string.Empty;
}
#region IDataErrorInfo Members
public string Error
{
get { return CheckRules("Name") + CheckRules("WebSite"); }
}
public string this[string columnName]
{
get { return CheckRules(columnName); }
}
#endregion
}
Partial类引入了一种将方法分离到不同文件中的方法。
如果我们需要在自动产生的代码中选择性的调用一个方法,.NET 2.0之前,我们没有任何办法。不过C# 3.0 和VB 9.0引入了一种叫做partial方法的新特性,允许我们在一个方法中选择性的调用其它方法。
8.3.3 使用partial方法
当我们对业务实体进行处理的时候,往往需要提供额外的业务操作。在C# 3.0 和VB 9.0以前,我们可能创建一个抽象类并允许我们的类进行重写。如果在SQL LINQ中使用这种模型,将会出现很多问题,C# 3.0 和VB 9.0引入了partial方法。使用partial方法,我们可以在自动产生的代码中插入方法存根。如果我们在业务代码中实现了该方法,那么编译器将会添加这个功能,如果我们没有实现这个方法,那么编译器将会移除这个方法。列表8.27显示了一些SQL LINQ设计器和SqlMetal插入到我们类中的一些partial方法以及我们如何使用这些方法的一些代码。
列表8.27 partial方法的定义和使用
[Table(Name="dbo.Publisher")]
public partial class Publisher : INotifyPropertyChanging, INotifyPropertyChanged
{
#region Extensibility Method Definitions
partial void OnCreated();
partial void OnNameChanging(string value);
partial void OnNameChanged();
#endregion
public Publisher()
{
this._Books = new EntitySet<Book>(
new Action<Book>(this.attach_Books),
new Action<Book>(this.detach_Books));
OnCreated();
}
[Column(Storage="_Name", DbType="VarChar(50) NOT NULL", CanBeNull=false)]
public string Name
{
get
{
return this._Name;
}
set
{
if ((this._Name != value))
{
this.OnNameChanging(value);
this.SendPropertyChanging();
this._Name = value;
this.SendPropertyChanged("Name");
this.OnNameChanged();
}
}
}
在SQL LINQ自动产生的代码中,你会发现大量的方法存根,这些方法允许你注入额外的功能。在本示例中,如果我们需要初始化一些我们的属性,可以按如下方法实现OnCreated方法:
partial void OnCreated()
{
this.ID = Guid.NewGuid();
this.Name = string.Empty();
this.WebSite = string.Empty();
}
如果实现了OnCreated方法,我们可以确保实例化对象时赋予了对象正确的值。如果需要,可以使用PropertyChanging和PropertyChanged事件来实现更复杂的业务逻辑。说到属性变化,自动代码中包含了两个partial方法的存根,每个属性在变化前后都会调用它们。这可以让我们在用户输入变化的时候进行变化跟踪以及应用其它业务逻辑。
记住,如果我们没有实现partial方法,它们并不会让我们编译后的业务对象变的复杂。Partial方法很有用,但是有时候我们需要实现一个多态的模型,还好,SQL LINQ同样提供了处理这种业务的方法。
8.3.4 使用对象继承
在本节示例中,我们只有一个user对象,它包含用户名和ID。如果我们需要特化很多不同功能的用户。例如:我们可以给Author和Publisher特定的权限,以便他们可以编辑那些属于他们的信息,其它用户的权限需要更多的限制。为了将用户与角色相关联,我们为User表添加了两列用来指示用户的类型。如果两列信息都为空,那么他就是普通用户,否则该用户可能是Author,或者是Publisher。图8.7展示了修改后的用户表。
图8.7 修改后的用户表
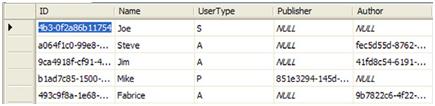
在我们的新表中,我们添加了三列。后面的两列包含着Publisher和Author表的主键。UserType标识着用户类型。在本例中,如果类型是A,表示用户就是Author,P表示Publisher,S表示标准用户。接下来,该如何将该表的数据映射到我们的业务对象中呢?因为我们有三个用户类型,所以有三个用户类来表示不同的用户种类。标准用户类为UserBase,因为这个类是其它两个类的基类。其它两个用户类是AuthorUser和PublisherUser,它们都从UserBase类继承。图8.8显示了整个对象结构。
图 8.8 带有继承关系的SQL LINQ设计器
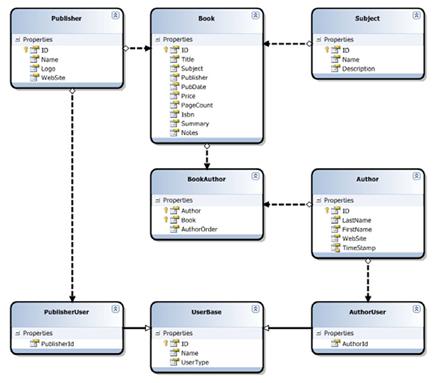
通过SQL LINQ设计器可以构建整个对象结构,在设计器中,通过拖拽添加Publisher, Book, BookAuthor, 和Author类。为了添加User类,将User表拖拽到设计器中,因为我们的UserBase类不需要包含类型定义字段,所以将Author和Publisher属性从用户类中删除。接着从属性窗口中将User类的名称修改为UserBase。
一旦UserBase类配置好了后,就需要定义另外两个用户类。从工具栏中拖动两个新类到设计器中。将它们分别命名为PublisherUser和AuthorUser。在右键菜单提供的功能中,为PublisherUser类添加一个名为PublisherId的属性,并将其源设置为Author列。同时为AuthorUser也添加一个名为AuthorId的属性,将其源设置为Author列。定义好类之后,从工具箱中选择“继承”工具,将PublisherUser和UserBase类相关联。对AuthorUser也做相同的操作。
我们的继承模型已经基本完成。接下来还需要标识什么样的行数据映射到哪个类上。例如,如果我们加载了一条UserType为A的用户数据,那么我们应该得到一个AuthorUser类的实例。为了做到这点,需要加强映射信息。下面就让我们通过使用设计器做到这些。
为了指定映射,选择PublisherUser和UserBase之间的继承箭头,打开属性窗口。属性窗口有四个值:基类识别器, 派生类识别器, 识别器属性和默认继承。首先设置识别器属性,它标识哪个基类的属性用来指示实例化目标对象的类型。UserBase类中维护了一个UserType属性,现在要做的就是将它设置为识别器属性。基类识别器用来指示UserType中哪个值用来实例化UserBase类型。在我们的示例中,为其设置为S,标识一个标准用户。下一个属性是派生类识别器,将其设置为P。如果一个值没有类型可以对应,那么此时应该使用默认继承属性,将其设置为UserBase类,这样在UserType的值没有匹配的时候,就将实例化一个UserBase类。对于AuthorUser类,做以上同样的操作。
一旦完成设置,并保存。就可以查看设计器产生的代码。如下:
[InheritanceMapping(Code="S", Type=typeof(UserBase), IsDefault=true)]
[InheritanceMapping(Code="A", Type=typeof(AuthorUser))]
[InheritanceMapping(Code="P", Type=typeof(PublisherUser))]
[Table(Name="dbo.[User]")]
Public partial class UserBase
{
//Implementation code omitted
}
运行时依赖这些属性(或者XML映射文件)来指示需要加载那些对象。除了需要设置继承映射属性以外,还需要设置另外一个属性,这个属性就是UserType属性。注意到:IsDiscriminator参数被设置为true。
[Column(Storage="_UserType", IsDiscriminator=true)]
public char UserType
当我们获取记录的时候,SQL LINQ将会检查由IsDiscriminator属性修饰的属性。然后将该字段的值与映射信息中的值进行比较,来决定实例化哪种类型的实例。
在我们使用这种继承映射之前,让我们用设计器建立更多的关系。使用设计器在Publisher和Author类之间建立关联,这会让我们在对象之间进行导航,即使数据库的对应表之间没有外键关联。结果如图8.4。完成设计后,列表8.28阐述了如何使用这些继承。
列表8.28 使用SQL LINQ继承
var query =
from user in context.UserBases select user.Name;
var authors =
from user in context.UserBases where user is AuthorUser
select user.Name;
var publishers =
from user in context.UserBases.OfType<PublisherUser>()
select user.Name;
在第一个示例中,我们选择了所有的用户,没有使用继承结构。下面是SQL LINQ产生的SQL代码:
SELECT [t0].[Name]
FROM [dbo].[User] AS [t0]
在第二个查询中,我们通过类型约束了返回的记录。只获取那些AuthorUser对象(where the UserType=A)。最后一个示例演示了另一种过滤的方法,使用了OfType方法来获取那些匹配Publisher类型的的对象。因为我们只获取了用户名称,所以两个示例返回了同样的的SQL:
SELECT [t0].[Name]
FROM [dbo].[User] AS [t0] WHERE [t0].[UserType] = @p0
需要记住的一点是,如果你有一个列用来标识几个派生类,而不是全部派生类,那么就需要在数据库中将此列标识为Nullable。否则更新那些没有实现这些属性的对象将会抛出一个异常,因为此对象没有存储这个属性值。
目前为止,我们只是简单了解了SQL LINQ提供的继承映射的能力。只要数据被限制在单个表上,那么是SQL LINQ实现继承还是相对简单一些。基类上用于映射继承信息的属性和设置识别器列是所有我们要做的事情。不过SQL LINQ的继承模型有很多弱点。首先,运行时需要基类上的映射信息,业务对象可能会对基类映射的实现有所限制,因为继承层次中的每个对象可能来自不同的表。
SQL LINQ继承模型的第二个弱点是基于这样的事实,一个类的映射信息不能跨越多个表。一个实体的数据分布在多个表中的情况并不少见。从数据库设计视角,这是合理的, 但是从对象视角看,这些分布在多个表中的信息最好能够集中到一个对象中。例如:地址信息往往会被从一些表中分离出来单独存储。如果能够让Author对象包含地址属性,而不是包含一个地址对象,就不能把地址信息从Author表中分离出来,因为SQL LINQ不支持一个表映射到两个类,或者一个类映射到两个表。这时我们就需要SQL LINQ之外的一个框架ADO.NET Entity Framework,它为我们提供了更多高级的映射功能。
8.4 LINQ to Entities简介
在多数情况下,SQL LINQ都是用来进行CRUD操作的。但是有时我们需要更复杂的实体映射操作,这时候一对一的表和对象映射就不能满足我们的需求了。特别是那些拥有复杂的数据库结构,进行过性能优化的并带有数据库视图的数据库。如图8.9所示。在本例中,添加了一个用来存储地址的新表。可以使用它存储任何表中的相关地址。在图8.9中,我们使用Address表存储了Author和Publisher的地址信息。
注意:我们不会争论这种设计是好是坏,这只是一个示例,使不使用这种设计由你决定
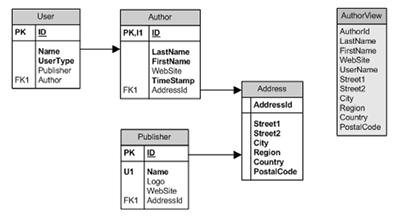
图 8.9 添加共享的地址表
本例中,我们把地址信息正规化到一个单独的表中,然而,我们的业务实体需要合并Author和Address信息到一个类中。如果我们想要查看这种平面视图,我们可以简单的创建一个服务器视图。这个视图将会把如何合并表的业务逻辑分离出来。
问题是,一旦使用了视图,那么就丢失了进行更新的元数据。1976年, Peter Chen博士创建了实体-关系模型。其中,他在物理模型(数据库)和逻辑模型(对象)中插入了一层概念模型。从某些方面来说,概念模型跟那个用来合并多个表的视图类似。不过,它跟视图有很大不同。首先,实体数据模型(EDM)包含了所有元数据的信息。这些信息包含了数据的来源和去向,所以可以使用代码实现更新操作。在语言组进行LINQ设计的时候,微软数据组在为那些更复杂的数据结构实现一个概念模型。他们把这种技术称作ADO.NET Entity Framework (EF)。EF使用XML映射文件隔离了逻辑模型和物理模型。 (如图8.10).
图 8.10 实体框架的层次
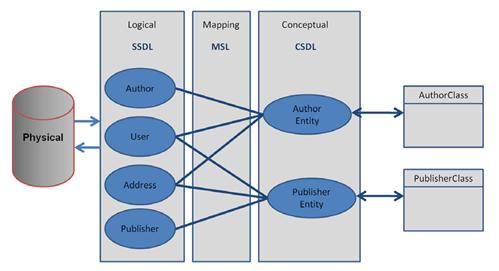
在EF中,物理数据库模型一一映射到一个逻辑模型中,一个表映射到一个逻辑层实体。逻辑层实体使用基于XML的存储模式定义语言(SSDL)来定义。这种映射跟我们在SQL LINQ中的定义类似。EF与 SQL LINQ不同的是,它使用另一个XML文件把逻辑模型映射到一个概念模型,它使用了映射模式语言(MSL)。概念模型使用另一个XML文件来定义,使用的语言是概念模式定义语言(CSDL)。之后这些概念实体可以转换到强类型的对象。
建立了EDM之后,我们可以使用基于字符串的实体SQL来查询数据。此外,我们的LINQ知识可以通过LINQ to Entities应用到EDM中。因为EDM表示应用程序和数据库之间的一个真正抽象,所以我们可以通过修改数据库和EDM映射文件来重建数据存储而不用重新编译我们的应用程序。
EF建立在已经存在的ADO提供者模型上,所以EF可以工作在所有ADO支持的数据源上,而像SQL LINQ只能支持SQL Server,如果你等不及让LINQ支持其它类型的数据库,那么你可以考虑使用EF建立你的数据访问层。在本书编写的时候,EF被安排在发布了LINQ之后发布。基于这样的安排,我们不能对其进行完整的讲解。关于EF的更多信息,请参阅:http://msdn2.microsoft.com/en-us/data/aa937723.aspx。
8.5摘要
SQL LINQ提供了处理关系数据库和应用程序之间的交互的问题。我们不用再编写那些繁杂的ADO.NET数据访问代码。因为我们设置了用于映射的元数据,所以可以让框架来管理实体生命周期。图8.11总结了典型的实体对象生命周期。
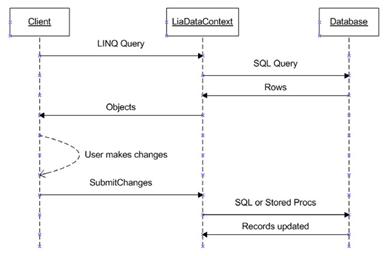
图8.11 SQL LINQ时序图















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









