








整体架构
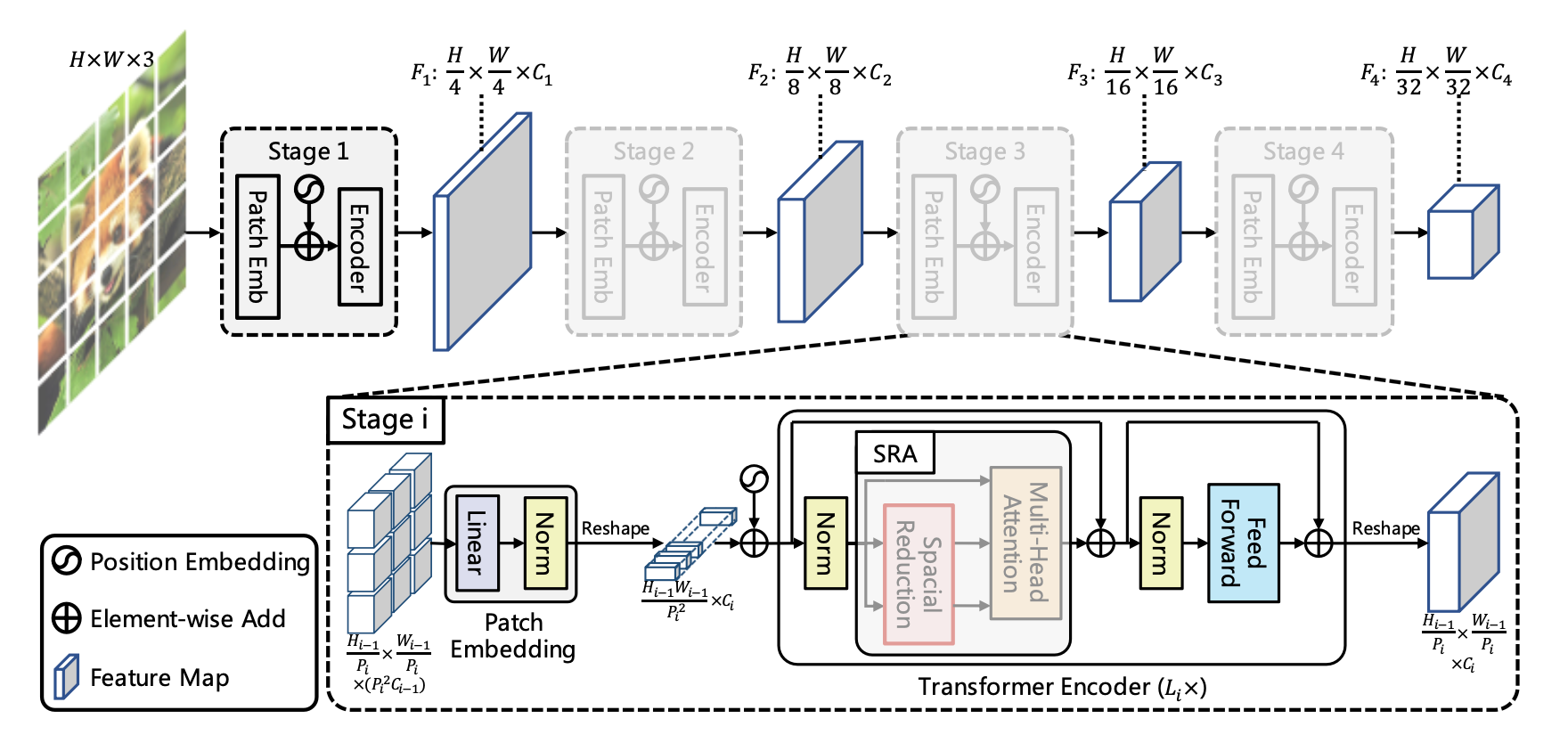
整个“金字塔”架构分为4个stage,每个stage内的基础结构是相似的,即:
- Patch Embedding:目的在于将信息分块,降低单张图的图片大小,但会增加数据的深度
- Transformer Encoder:目的在于计算图片的attention value,由于深度变大了,计算复杂度会变大,所以在这里作者使用了Special Reduction来减小计算复杂度
具体模块
Patch Embedding
Patch Embedding部分与ViT中对与图片的分块操作是一样的,即:
- 将原图切成总数为 p i × p i p_i\times p_i pi×pi的patches
具体操作:
使用卷积操作, k e r n a l _ s i z e = H p i , s t r i d e = H p i \mathrm{kernal\_size}=\frac{H}{p_i},\mathrm{stride}=\frac{H}{p_i} kernal_size=piH,stride=piH
- 将每个patch内的数据拉平,然后进行LayerNorm,此时每个patch内的数据大小为 H i − 1 W i − 1 p i 2 × C i \frac{H_{i-1}W_{i-1}}{p_i^2}\times C_i pi2Hi−1Wi−1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









