







Fork/Join的概念
Fork/Join框架是 Java 7提供的一个用于并行执行任务的框架,是把一个大任务分割为若干子任务,最终汇总每个子任务结果得到大任务结果的框架。其中Fork用于将任务分割成子任务,Join用于将子任务合并并汇总结果。而且在各线程计算时采用工作窃取算法。
所谓工作窃取算法,是指某个线程从其他队列里窃取任务来执行。通俗易懂的话来说就是,我干完了活一有空闲,发现你有一堆活要干,我就帮你干一点。其优点是,充分利用了线程并行计算,减少了线程间的竞争;缺点是在某些情况下仍然存在竞争,而且对系统资源消耗比较大。
Fork/Join框架设计
步骤一:分割任务 首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务仍然很大,所以仍然需要不停的切割,直到分割出的子任务足够小。有一种动态规划中的分而治之的思想。
步骤二:执行任务合并结果 分割的子任务分别放在双端队列里,然后几个启动线程分别成双端队列中获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列中拿数据,然后合并这些数据。Fork/Join使用两个类来完成以上工作:
- ForkJoinTask:首先创建一个ForkJoin任务,它提供在任务中执行fork()和join()操作的机制。通常不直接继承ForkJoinTask类,而是用其抽象子类RecursiveAction(用于没有返回结果的任务)、RecursiveTask(用于返回结果的任务)。
- ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来提交启动执行。
ForkJoin实例一(只做一次垂直切割)
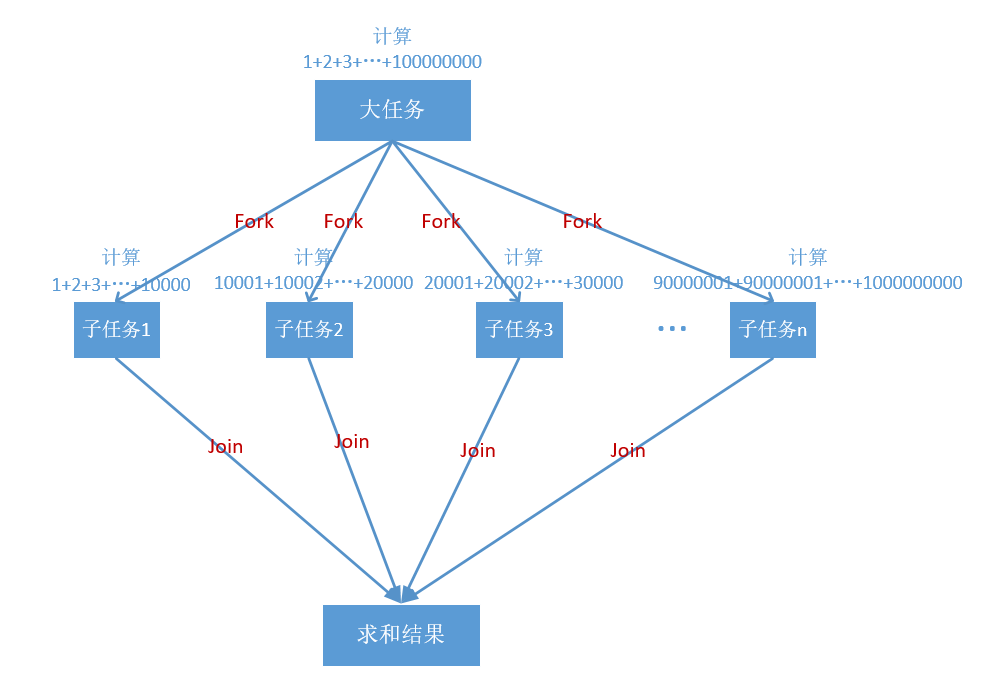
这里只将任务进行一次垂直切割,Fork分割成n个子任务,然后各自计算,最后Join汇总结果。
代码实现:
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
public class CountTask extends RecursiveTask<Long>{
private static final long THRESHOLD = 10000;//阈值,以一次计算10000的区间分割
private long start;
private long end;
public CountTask(long start,long end){
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
boolean canCompute = end-start<=THRESHOLD;
if(canCompute){
for(long i = start;i<=end;i++){
sum += i;
}
}else{
List<CountTask> tasklist = new ArrayList<>();
for(long i=start;i<=end;i=i+THRESHOLD+1){//按区间分割成n个子任务
CountTask task=null;
if(i+THRESHOLD<=end){
task = new CountTask(i,i+THRESHOLD);
}else{
task = new CountTask(i,end);
}
tasklist.add(task);
}
for(CountTask task:tasklist){//分割成n个子任务
task.fork();
}
for(CountTask task:tasklist){//等待子任务完成,合并n个子任务结果
sum+=task.join();
}
}
return sum;
}
public static void countCompute(long start,long end){
long t1 = System.currentTimeMillis();
long sum = 0;
for(long i=start;i<=end;i++){
sum+= i;
}
System.out.println("串行计算耗时:"+(System.currentTimeMillis()-t1)+",result="+sum);
}
public static void main(String[] args){
ForkJoinPool forkJoinPool = new ForkJoinPool();
Scanner sc = new Scanner(System.in);
while(sc.hasNextLong()){
long start = sc.nextLong();
long end = sc.nextLong();
long t1 = System.currentTimeMillis();
CountTask task = new CountTask(start,end);
Future<Long> result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
System.out.println("Fork/Join耗时:"+(System.currentTimeMillis()-t1));
countCompute(start,end);
}
}
}
运行结果

从结果可以看出,1+2+…+n,n为千万之前,并行和串行相当,但是千万之后并行的效率就远大于串行了。
ForkJoin实例一(子任务继续递归切割)
采用二分法,如果子任务还是很大,继续切割,直到任务大小不大于阈值。
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
public class CountTask extends RecursiveTask<Long>{
private static final long THRESHOLD = 10000;//阈值
private long start;
private long end;
public CountTask(long start,long end){
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
boolean canCompute = end-start<=THRESHOLD;
if(canCompute){
for(long i = start;i<=end;i++){
sum += i;
}
}else{
long middle = (start+end)/2;
CountTask leftTask = new CountTask(start,middle);
CountTask rightTask = new CountTask(middle+1,end);
leftTask.fork();
rightTask.fork();
sum+=leftTask.join();
sum+=rightTask.join();
}
return sum;
}
public static void countCompute(long start,long end){
long t1 = System.currentTimeMillis();
long sum = 0;
for(long i=start;i<=end;i++){
sum+= i;
}
System.out.println("串行计算耗时:"+(System.currentTimeMillis()-t1)+",result="+sum);
}
public static void main(String[] args){
ForkJoinPool forkJoinPool = new ForkJoinPool();
Scanner sc = new Scanner(System.in);
while(sc.hasNextLong()){
long start = sc.nextLong();
long end = sc.nextLong();
long t1 = System.currentTimeMillis();
CountTask task = new CountTask(start,end);
Future<Long> result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
System.out.println("Fork/Join耗时:"+(System.currentTimeMillis()-t1));
countCompute(start,end);
}
}
}该实例,运行数据较大时,效率还是比较慢,当我n输入千万左右开始就不要几秒才能出结果。然而这只是一个思路,这个可以用于归并排序,或者快排的Fork/Join实现。有兴趣的人,可以自己构思去写。
结论
Fork/Join是一个非常实用的并发框架,特别是用于将大任务的分解,能充分利用系统的CPU,以更高的效率完成一个大任务。说句题外话,某一定程度有点和hadoop的mapreduce单机版很类似。















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









