







 本文深入探讨了多种网络编程模型,包括UDP与TCP的传输特点、多线程/多进程模型的应用场景、线程池/进程池模型的优势及限制、基于I/O复用的事件循环模型的实现方式以及listener-Worker服务器模型的不同变种。针对每种模型的特点、优缺点进行了详细解析。
本文深入探讨了多种网络编程模型,包括UDP与TCP的传输特点、多线程/多进程模型的应用场景、线程池/进程池模型的优势及限制、基于I/O复用的事件循环模型的实现方式以及listener-Worker服务器模型的不同变种。针对每种模型的特点、优缺点进行了详细解析。
1 一问一答CS架构
1.1 C-S UDP传输模型

问题:UDP是廉价的不可靠服务,不保证传输质量和结果。因而UDP一般较多应用于内网等简单的网络环境,而不是互联网复杂的网络环境。
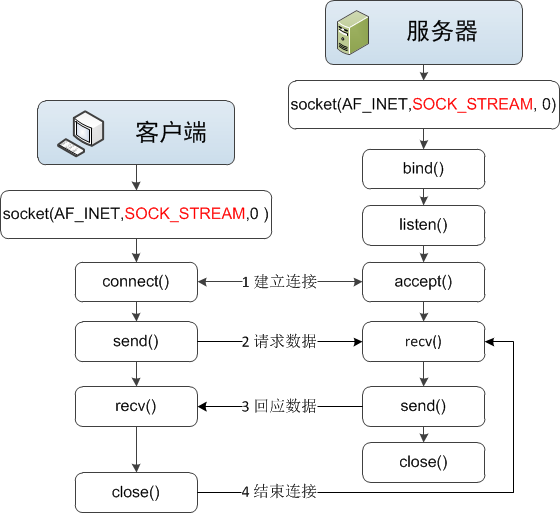
问题:TCP方式传输提供了UDP所无法提供的可靠传输服务。但是这里服务器以while(1)方式accept,必须顺序处理客户端请求,完全没有并发量。如果在处理一个客户请求的时候出现第二个客户请求,客户2将被丢弃。
2 多线程/多进程模型
2.1 fork模型
/*************************************************************************
> File Name: echoser.c
> Author: Simba
> Mail: dameng34@163.com
> Created Time: Fri 01 Mar 2013 06:15:27 PM CST
************************************************************************/
#include<stdio.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<unistd.h>
#include<stdlib.h>
#include<errno.h>
#include<arpa/inet.h>
#include<netinet/in.h>
#include<string.h>
#include<signal.h>
#define ERR_EXIT(m) \
do { \
perror(m); \
exit(EXIT_FAILURE); \
} while (0)
void do_service(int);
int main(void)
{
signal(SIGCHLD, SIG_IGN);
int listenfd; //被动套接字(文件描述符),即只可以accept, 监听套接字
if ((listenfd = socket(PF_INET, SOCK_STREAM, IPPROTO_TCP)) < 0)
//listenfd = socket(AF_INET, SOCK_STREAM, 0)
ERR_EXIT("socket error");
struct sockaddr_in servaddr;
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(5188);
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
/* servaddr.sin_addr.s_addr = inet_addr("127.0.0.1"); */
/* inet_aton("127.0.0.1", &servaddr.sin_addr); */
//允许重复使用本地地址和套接字绑定
int on = 1;
if (setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on)) < 0)
ERR_EXIT("setsockopt error");
if (bind(listenfd, (struct sockaddr *)&servaddr, sizeof(servaddr)) < 0)
ERR_EXIT("bind error");
if (listen(listenfd, SOMAXCONN) < 0) //listen应在socket和bind之后,而在accept之前
ERR_EXIT("listen error");
struct sockaddr_in peeraddr; //传出参数
socklen_t peerlen = sizeof(peeraddr); //传入传出参数,必须有初始值
int conn; // 已连接套接字(变为主动套接字,即可以主动connect)
pid_t pid;
while (1)
{
if ((conn = accept(listenfd, (struct sockaddr *)&peeraddr, &peerlen)) < 0) //3次握手完成的序列
ERR_EXIT("accept error");
printf("recv connect ip=%s port=%d\n", inet_ntoa(peeraddr.sin_addr),
ntohs(peeraddr.sin_port));
pid = fork();
if (pid == -1)
{
ERR_EXIT("fork error");
}
else if (pid == 0)
{
// 子进程
close(listenfd);
do_service(conn);
exit(EXIT_SUCCESS);
}
else if (pid>0)
{
close(conn); //父进程
}
}
close(listenfd);
return 0;
}
void do_service(int conn)
{
char recvbuf[1024];
while (1)
{
memset(recvbuf, 0, sizeof(recvbuf));
int ret = read(conn, recvbuf, sizeof(recvbuf));
if (ret == 0) //客户端关闭了
{
printf("client close\n");
break;
}
else if (ret == -1)
ERR_EXIT("read error");
fputs(recvbuf, stdout);
write(conn, recvbuf, ret);
}
}signal(SIGCHLD, handler);
.....................
void handler(int sig)
{
/* wait(NULL); //只能等待第一个退出的子进程 */
while (waitpid(-1, NULL, WNOHANG) > 0)
;
}signal(SIGCHLD, handler);
.....................
void handler(int sig)
{
/* wait(NULL); //只能等待第一个退出的子进程 */
while(wait(NULL)>0)
;
}
原理:
这里的核心逻辑是while(1){ fork() },然后通过子进程来处理每个新连接的读写请求。
问题:
如果要同时响应成百上千路的连接请求,则无论多线程还是多进程都会严重占据系统资源,降低系统对外界响应效率,而线程与进程本身也更容易进入假死状态。创建和销毁进程或线程的开销。
3 线程池/进程池模型
3.1 进程池模型
原理:
“线程池”旨在减少创建和销毁线程的频率,其维持一定合理数量的线程,并让空闲的线程重新承担新的执行任务。“连接池”维持连接的缓存池,尽量重用已有的连接、减少创建和关闭连接的频率。
问题:
“线程池”和“连接池”技术也只是在一定程度上缓解了频繁调用 IO 接口带来的资源占用。而且,所谓“池”始终有其上限,当请求大大超过上限时,“池”构成的系统对外界的响应并不比没有池的时候效果好多少。所以使用“池”必须考虑其面临的响应规模,并根据响应规模调整“池”的大小。
4 基于I/O复用的事件循环模型
4.1 select模型
server.c
#include <sys/types.h>
#include <sys/socket.h>
#include <stdio.h>
#include <sys/un.h>
#include <sys/time.h>
#include <sys/ioctl.h>
#include <unistd.h>
#include <netinet/in.h>
int main()
{
int rcd ;
struct sockaddr_un server_sockaddr ;
int backlog ;
ushort ci ;
int watch_fd_list[3] ;
fd_set catch_fd_set ;
fd_set watchset ;
int new_cli_fd ;
int maxfd;
int socklen,server_len;
struct sockaddr_un cli_sockaddr ;
struct {
char module_id ; /* Module ID */
int cli_sock_fd ; /* Socket ID */
} cli_info_t[2] ;
for (ci=0;ci<=1;ci++)
cli_info_t[ci].cli_sock_fd=-1;
for (ci=0;ci<=2;ci++)
watch_fd_list[ci]=-1;
int server_sockfd,client_sockfd;
server_sockfd = socket( AF_UNIX, SOCK_STREAM, 0 ) ;
server_sockaddr.sun_family = AF_UNIX ;
// server_sockaddr.sin_addr.s_addr=htonl(INADDR_ANY);
// server_sockaddr.sin_port=htons(9734);
strcpy( server_sockaddr.sun_path, "server_socket" ) ;
server_len=sizeof(server_sockaddr);
rcd = bind( server_sockfd, ( struct sockaddr * )&server_sockaddr, server_len ) ;
backlog = 5 ;
rcd = listen( server_sockfd, backlog ) ;
printf("SERVER::Server is waitting on socket=%d \n",server_sockfd);
watch_fd_list[0]=server_sockfd;
FD_ZERO( &watchset ) ;
FD_SET( server_sockfd, &watchset ) ;
maxfd=watch_fd_list[0];
while (1){
char ch;
int fd;
int nread;
catch_fd_set=watchset;
rcd = select( maxfd+1, &catch_fd_set, NULL, NULL, (struct timeval *)0 ) ;
if ( rcd < 0 ) {
printf("SERVER::Server 5 \n");
exit(1);
}
if ( FD_ISSET( server_sockfd, &catch_fd_set ) ) {
socklen = sizeof( cli_sockaddr ) ;
new_cli_fd = accept( server_sockfd, ( struct sockaddr * )&( cli_sockaddr ), &socklen ) ;
printf(" SERVER::open communication with Client %s on socket %d\n", cli_sockaddr.sun_path,new_cli_fd);
for (ci=1;ci<=2;ci++){
if(watch_fd_list[ci] != -1) continue;
else{
watch_fd_list[ci] = new_cli_fd;
break;
}
}
FD_SET(new_cli_fd , &watchset ) ;
if ( maxfd < new_cli_fd ) {
maxfd = new_cli_fd ;
}
for ( ci=0;ci<=1;ci++){
if(cli_info_t[ci].cli_sock_fd == -1) {
cli_info_t[ci].module_id=cli_sockaddr.sun_path[0];
cli_info_t[ci].cli_sock_fd=new_cli_fd;
break;
}
}
continue;
}
for ( ci = 1; ci<=2 ; ci++ ) {
int dst_fd = -1 ;
char dst_module_id;
char src_module_id;
int i;
if (watch_fd_list[ ci ]==-1) continue;
if ( !FD_ISSET( watch_fd_list[ ci ], &catch_fd_set ) ) {
continue ;
}
ioctl(watch_fd_list[ ci ],FIONREAD,&nread);
if (nread==0){
continue;
}
read( watch_fd_list[ ci ], &dst_module_id, 1 ) ;
for (i=0;i<=1;i++){
if(cli_info_t[i].module_id == dst_module_id)
dst_fd= cli_info_t[i].cli_sock_fd;
if(cli_info_t[i].cli_sock_fd == watch_fd_list[ ci ])
src_module_id= cli_info_t[i].module_id;
}
read( watch_fd_list[ ci ], &ch, 1 ) ;
printf("SERVER::char=%c to Client %c on socket%d\n",ch, dst_module_id,dst_fd);
write(dst_fd,&src_module_id, 1 ) ;
write(dst_fd,&ch, 1 ) ;
}
}
}client.c
#include <sys/types.h>
#include <sys/socket.h>
#include <stdio.h>
#include <sys/un.h>
#include <unistd.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int main(){
int client_sockfd;
int len;
struct sockaddr_un server_sockaddr,cli_sockaddr;
int result;
char dst_module_id='B';
char ch='1';
char src_module_id;
client_sockfd= socket(AF_UNIX,SOCK_STREAM,0);
// memset( &cli_sockaddr, 0, sizeof( cli_sockaddr) ) ;
cli_sockaddr.sun_family = AF_UNIX ;
strcpy( cli_sockaddr.sun_path, "A" ) ;
bind( client_sockfd, ( struct sockaddr * )&cli_sockaddr, sizeof( cli_sockaddr ) ) ;
server_sockaddr.sun_family=AF_UNIX;
// server_sockaddr.sin_addr.s_addr=htonl(INADDR_ANY);
// server_sockaddr.sin_port=htons(9734);
strcpy( server_sockaddr.sun_path, "server_socket" ) ;
len=sizeof(server_sockaddr);
result = connect(client_sockfd,( struct sockaddr * )&server_sockaddr,len);
if (result <0){
printf("ClientA::error on connecting \n");
// exit(1);
}
printf("ClientA::succeed in connecting with server\n");
sleep(10);
write(client_sockfd,&dst_module_id,1);
write(client_sockfd,&ch,1);
read (client_sockfd,&src_module_id,1);
read (client_sockfd,&ch,1);
printf("ClientA::char from Client %c =%c\n", src_module_id,ch);
close (client_sockfd);
} 原理:
使用 select() 接口同时从多个客户端接收数据的过程;由于 select() 接口可以同时对多个句柄进行读状态、写状态和错误状态的探测,所以可以很容易构建为多个客户端提供独立问答服务的服务器系统。
select-默认支持64个fd,最高支持1024个fd。
问题:
select在检索活动连接的时候是线性检测的,当连接数特别大的时候效率就低了
4.2 epoll模型
epoll比select支持更多,而且epoll的效率更高
5,listener-Worker服务器模型
5.1 模型1
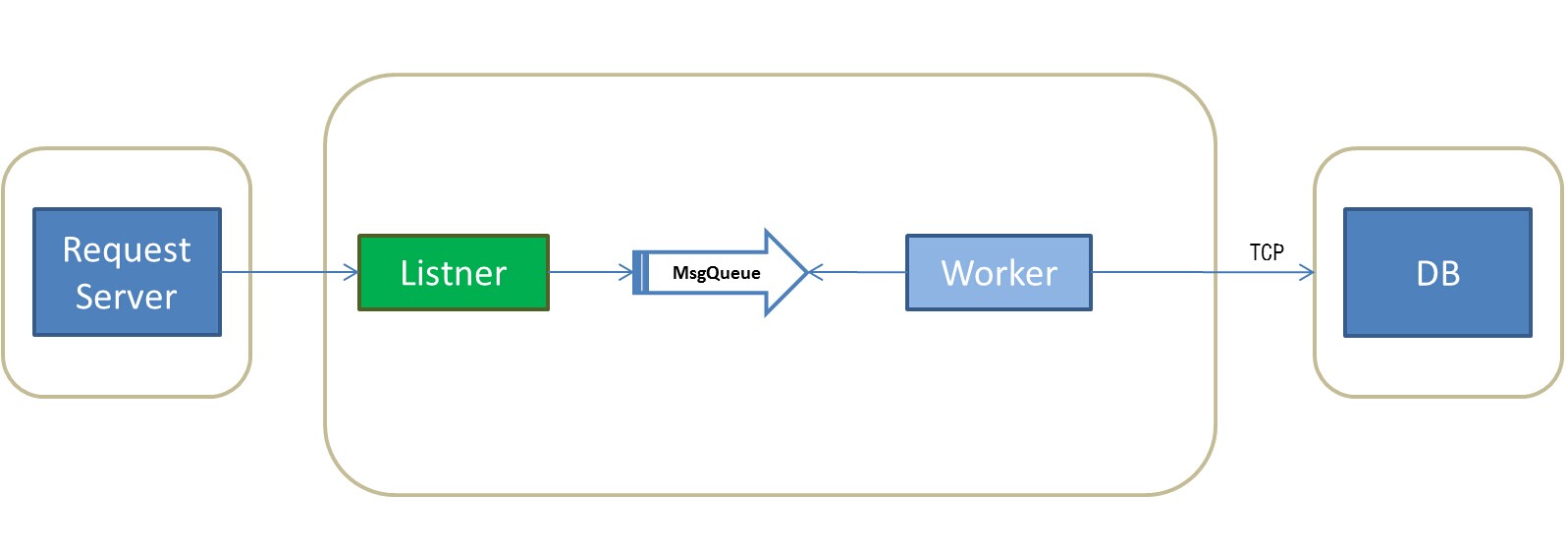
原理:
使用一个listener进程专门来处理外面的请求。使用一个MsgQueue来实现Listner与Worker之间的通信。使用一个TCP链接来处理与DB之间的数据请求问题。优点在于解耦合,左边生产者,右边消费者,能够应对大量请求的情况。
瓶颈:
xxx
5.2 模型2
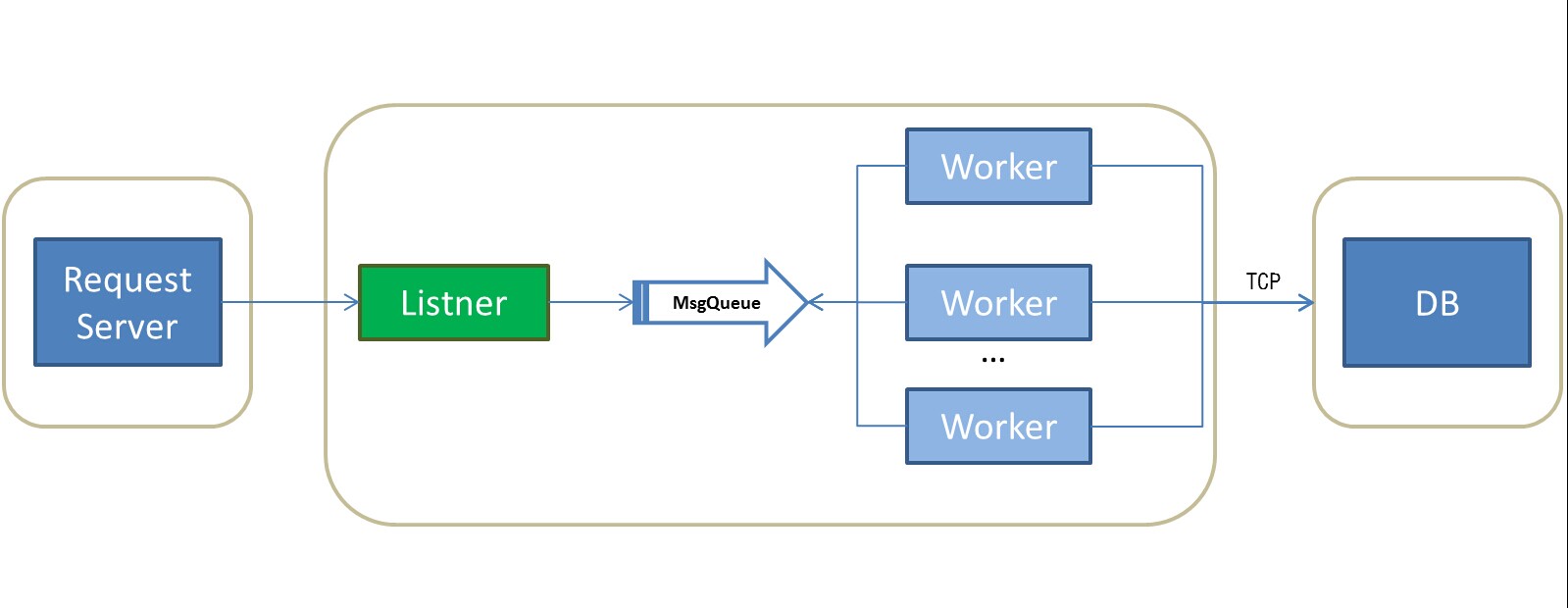
原理:
使用MsgQueue模型,一个进程写,多个进程读。有多个worker运行,每个worker空闲时会从MsgQueue获取请求。注意worker的数量应和cpu或核数一致。但是msgQ是用锁来解决竞争的,所以msgQ的锁会成为瓶颈。
问题:
当worker数量增加后,多个worker会争用MsgQueue。由于MsgQueue的锁机制导致了性能下降。此为其瓶颈。
5.3 模型3
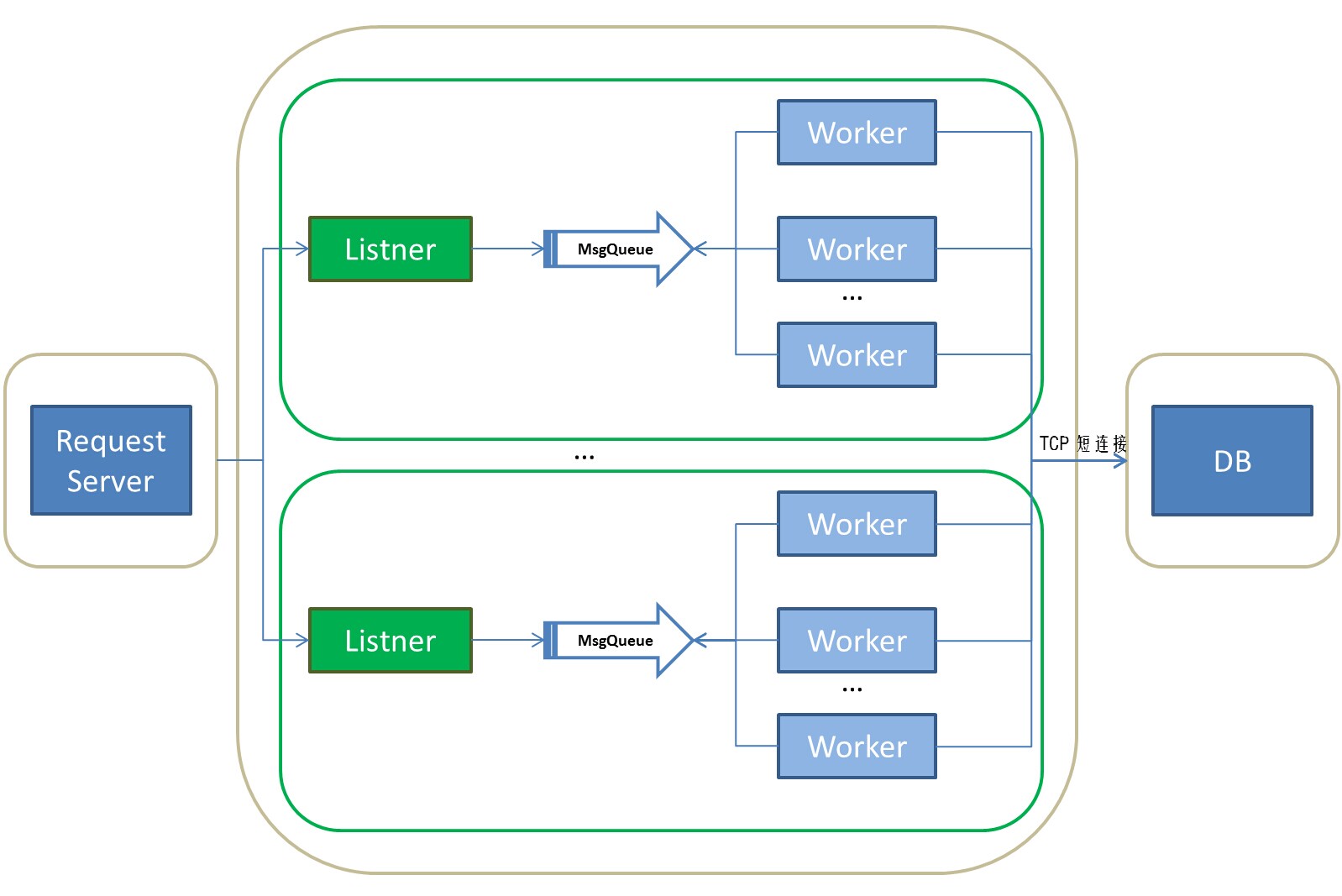
原理:
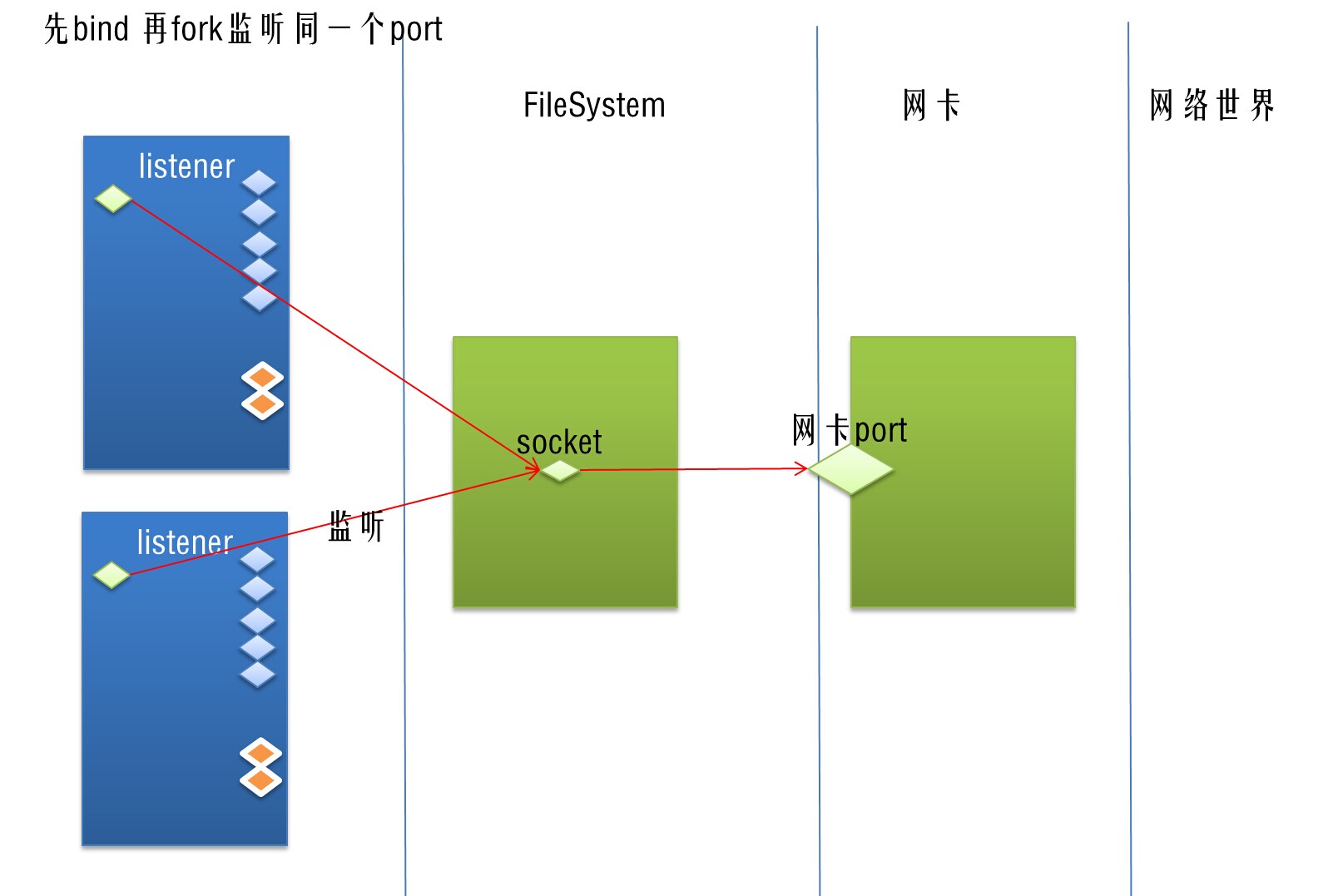
复用多套Listener和Worker体系可以有效解决MsgQueue的锁机制导致的争用数据问题。同时,多个listener监听同一个端口。
瓶颈:
问题1,如果多worker频繁建立TCP短链接。那么worker在这里充当client角色,DB充当Server角色。一次TCP短链接由worker发起,并且由worker close。每次worker会选用一个动态端口,并基于该端口生成一个socket fd来进行链接。server上fd频繁进入TIME_WAIT状态从而导致达到可用端口数量上限。从而出现丢包。
TIME_WAIT的存活时间被定义为2个MSL(Maximum Segment Lifetime,报文最大存活时间),MSL随着实现不同,数值也有变化,Berkeley标准中MSL是30s,所以一般TIME_WAIT是一分钟。2个MSL,能有效确保TCP双工连接终止,并且让老连接的数据包从网络上消失,避免与新的连接包混淆。
默认配置,端口数为2.8w,以一分钟计算,当每秒请求量超过2.8w/60=470时,就可能存在端口溢出情况,最后没有可用的端口建立连接,从而产生大量丢包。(查看Linux内核选用端口范围:cat /proc/sys/net/ipv4/ip_local_port_range)
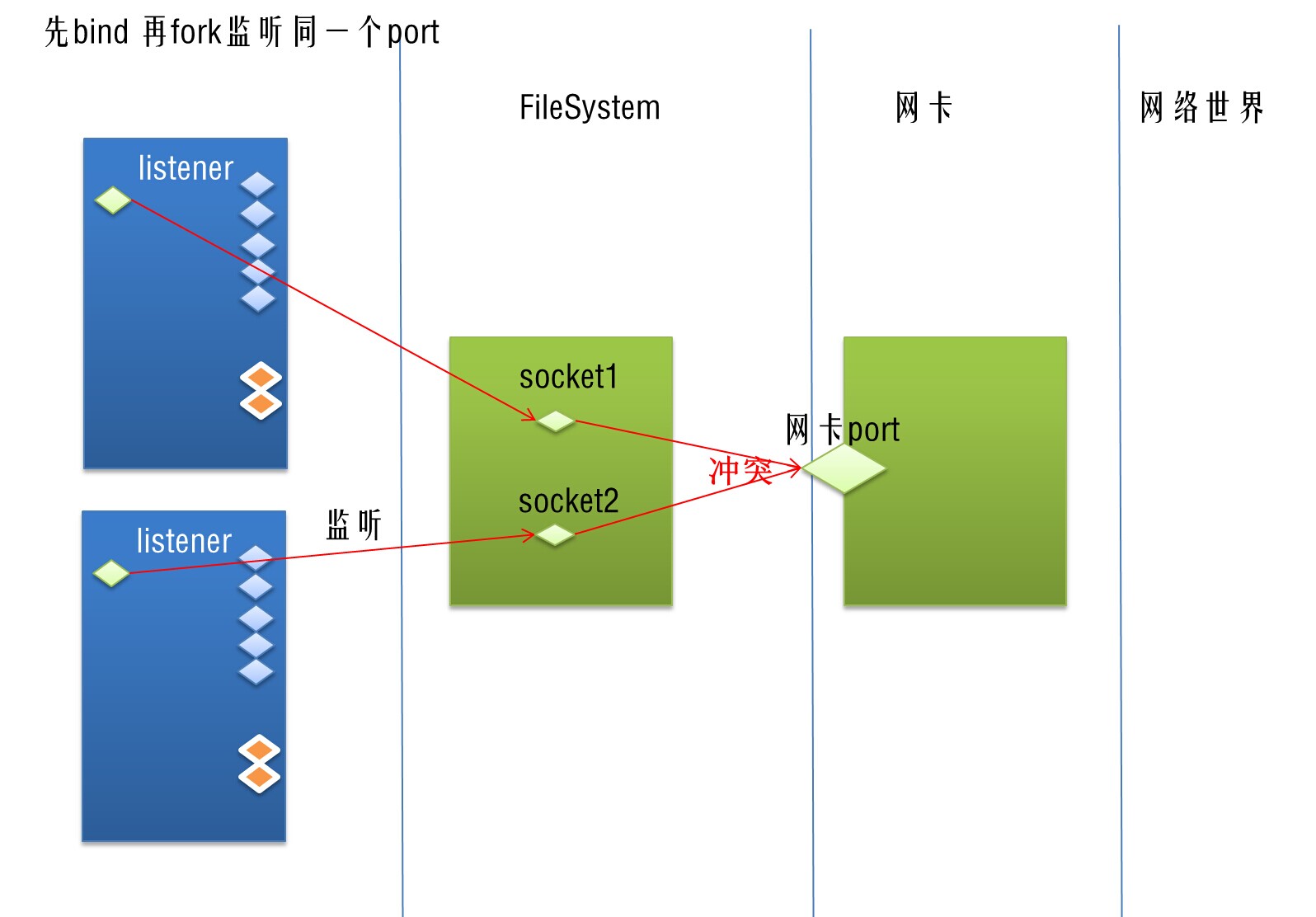
问题2,这里多个listener监听一个对外port。
1 如果使用accept循环,会有竞争。
2 如果使用epoll(指的是每个listener自己用epoll管理自己的fd队列,但是因为本质上是监听同一个端口,所以会同时被触发到),会有惊群。常见使用epoll方式来将监听该port的对应的socket fd加入到epoll池中。但是依靠epoll来实现该机制会导致惊群问题。
(现在新的linux版本已经解决epoll监听端口时的惊群问题)
另,nginx使用锁机制解决竞争或者惊群问题。
5.4 模型4
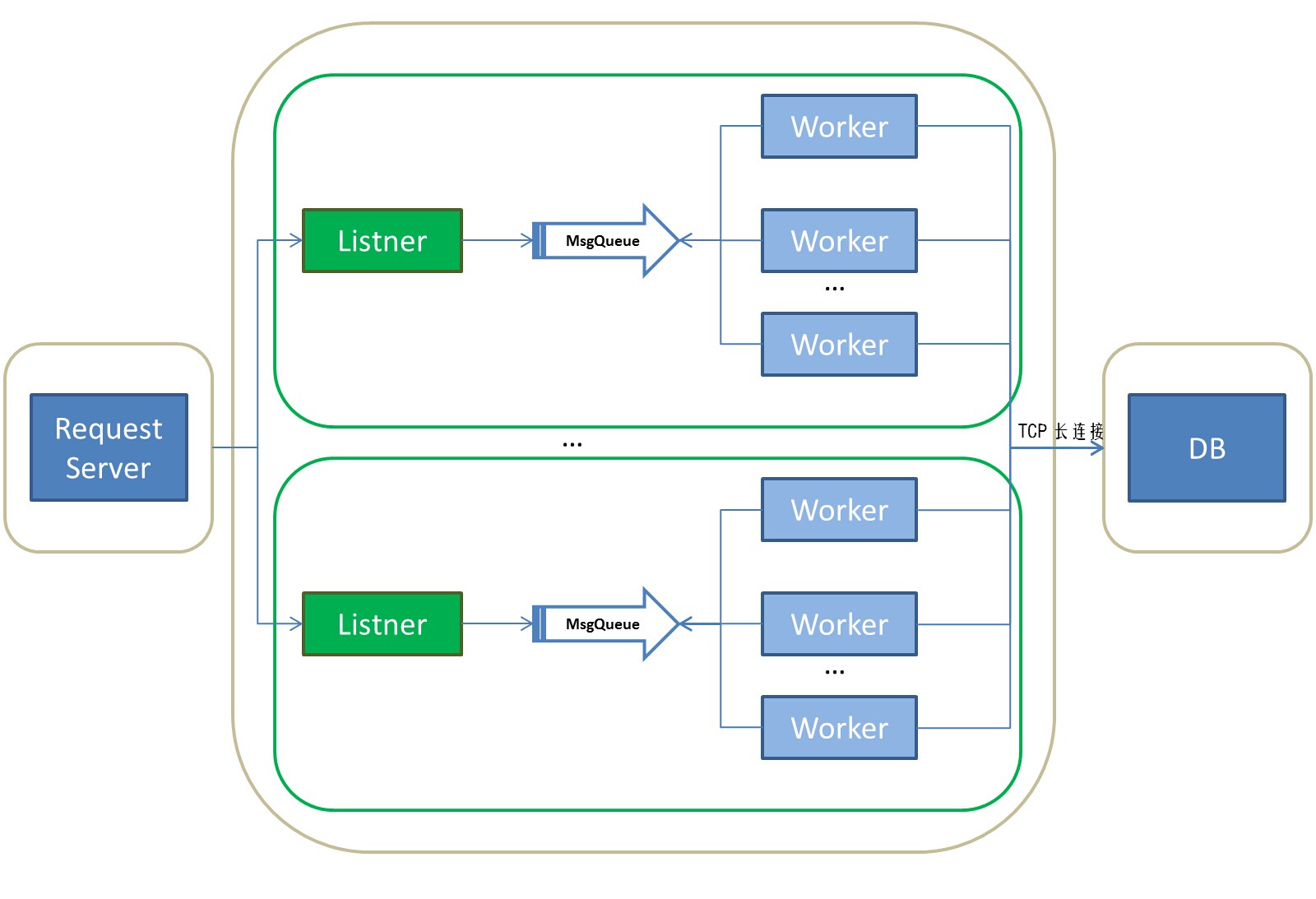
原理:
长连接替换是一种思路,与之而来的则是容灾需求以及心跳的维护等附加管理需求。
问题:
xxx
5.5 模型5
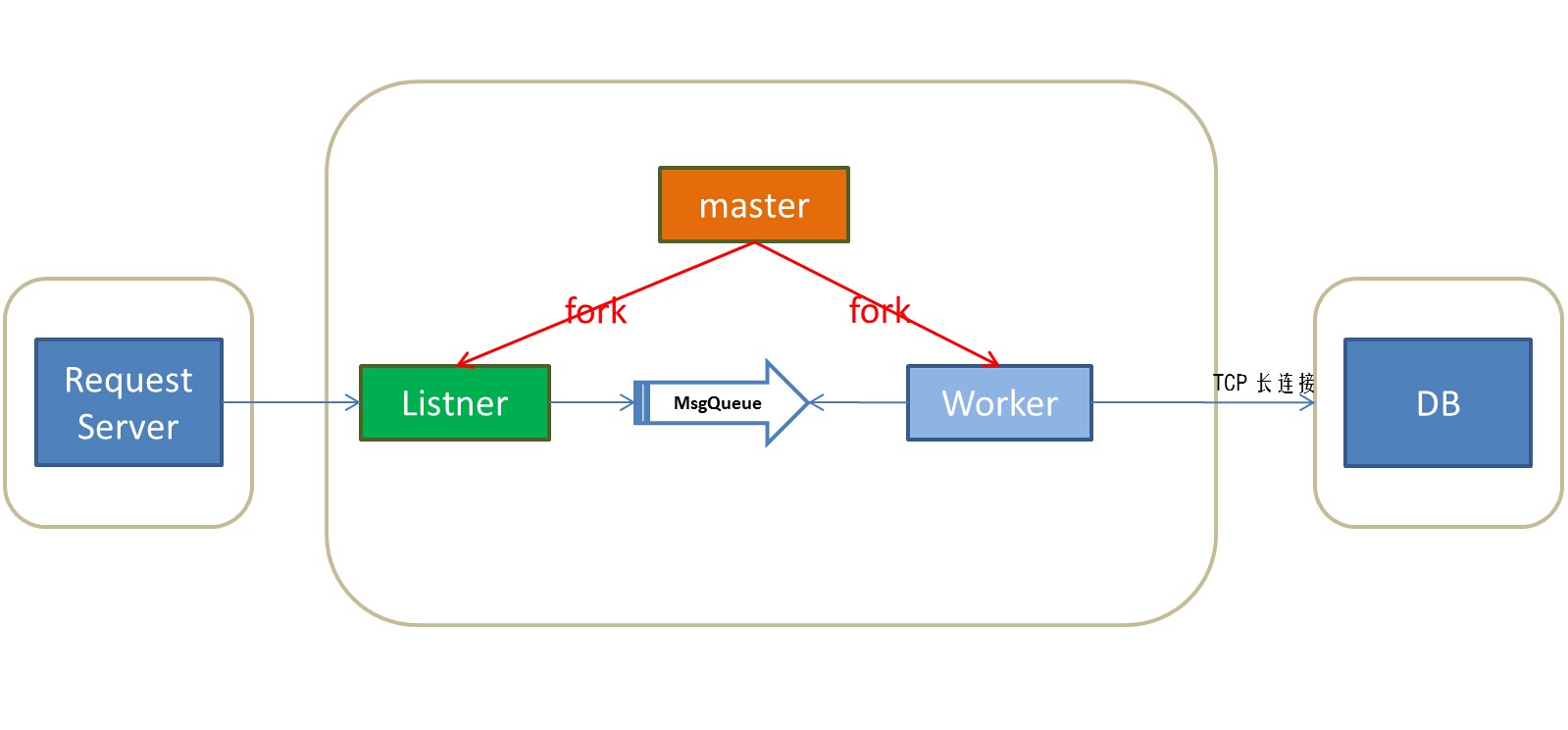
master可以负责子进程的健康状况,因为子进程挂掉了,会发送sigchild信号给父进程。
5.5 模型5
5.6 模型6
6 相关问题
6.1,TIME_WAIT问题
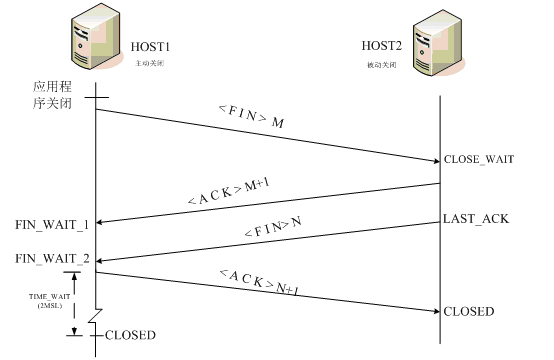
6.1.1 什么是MSL?
MSL(最大分段生存期)指明TCP报文在Internet上最长生存时间,每个具体的TCP实现都必须选择一个确定的MSL值。RFC 1122建议是2分钟。
TIME_WAIT 状态最大保持时间是2 * MSL,也就是1-4分钟。
6.1.2 为什么需要TIME_WAIT?
第一:我们没有任何机制保证最后的一个ACK能够正常送达
第二:网络上仍然有可能有残余的数据包(wandering duplicates,或老的重复数据包),我们也必须能够正常处理。
假设最后一个ACK丢失了,服务器会重发它发送的最后一个FIN,所以客户端必须维持一个状态信息,以便能够重发ACK;如果不维持这种状态,客户端在接收到FIN后将会响应一个RST,服务器端接收到RST后会认为这是一个错误。如果TCP协议能够正常完成必要的操作而终止双方的数据流传输,就必须完全正确的传输四次握手的四个节,不能有任何的丢失。这就是为什么socket在关闭后,仍然处于 TIME_WAIT状态,因为他要等待以便重发ACK。
如果目前连接的通信双方都已经调用了close(),假定双方都到达CLOSED状态,而没有TIME_WAIT状态时,就会出现如下的情况。现在有一个新的连接被建立起来,使用的IP地址与端口与先前的完全相同,后建立的连接又称作是原先连接的一个化身。还假定原先的连接中有数据报残存于网络之中,这样新的连接收到的数据报中有可能是先前连接的数据报。为了防止这一点,TCP不允许从处于TIME_WAIT状态的socket建立一个连接。处于TIME_WAIT状态的socket在等待两倍的MSL时间以后(之所以是两倍的MSL,是由于MSL是一个数据报在网络中单向发出到认定丢失的时间,一个数据报有可能在发送图中或是其响应过程中成为残余数据报,确认一个数据报及其响应的丢弃的需要两倍的MSL),将会转变为CLOSED状态。这就意味着,一个成功建立的连接,必然使得先前网络中残余的数据报都丢失了。
TIME_WAIT导致一个后果就是在 这个2MSL的时间内,该地址上的链接(客户端地址、端口和服务器端的地址、端口)不能被使用。比如我们在建立一个链接后关闭链接然后迅速重启链接,那么 就会出现端口不可用的情况。
根据TCP协议,主动发起关闭的一方,会进入TIME_WAIT状态,持续2*MSL(Max Segment Lifetime),缺省为240秒。值得一说的是,对于基于TCP的HTTP协议,关闭TCP连接的是Server端,这样,Server端会进入TIME_WAIT状态,可想而知,对于访问量大的Web Server,会存在大量的TIME_WAIT状态,假如server一秒钟接收1000个请求,那么就会积压240*1000=240,000个TIME_WAIT的记录,维护这些状态给Server带来负担。当然现代操作系统都会用快速的查找算法来管理这些TIME_WAIT,所以对于新的TCP连接请求,判断是否hit中一个TIME_WAIT不会太费时间,但是有这么多状态要维护总是不好。
6.1.3 假如Server端主动关闭链接
如HTTP(TCP):Server主动关闭链接
listenfd = socket();
...
while(1){
acceptfd =accept();
}Server维护TIME_WAIT队列=监听公共端口的进程数目*每个进程可以打开的fd数目=n*1024
6.1.4 假如Client端主动关闭链接
Client维护的TIME_WAIT队列=可用端口数量=3977
6.2,fork与监听端口问题
6.3 TCP短连接和长连接区别
6.4 TCP粘包问题
6.5 惊群问题


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









