







flume的诞生背景
现在大数据、数据分析在企业中的应用越来越广泛,大数据的一个主要应用场景是对一些日志进行分析,比如公司的监控的系统,采集运行在服务器上的日志进行分析,用户行为数据分析是采集用户在各个应用上面的日志行为进行分析。总结来看,很多地方都会产生日志,比如操作系统,web server(Tomcat,nginx等),应用程序等。那么这些数据要分析的话,就得将他们收集到一起来处理,发挥他们的价值。那么问题来了,怎么收集这些数据呢?
首先,这些日志的数据量非常大,那么我们肯定优先考虑用hadoop集群,做分布式处理。但是这些日志并不是集中放在一个地方,比如nginx的日志,我们一般会有多台服务器来处理请求。那如果想把他们移动到hadoop集群上,我么你可以采用脚本,比如我们日志产生的目录是/var/log/accsess.log上,使用shell的cp把他们拷贝到hadoop集群机器上,然后使用hadoop的hdfs -put命令传到集群上。当然,这样做也是可以的。但是我们要考虑一个问题:怎么做监控?拷贝过程中,如果中间某一个机器宕机了,你怎么办,能不能监控。第二,cp的话,得指定一个时间间隔,比如每一分钟,每两分钟一次,这样时效性又不太好,第三,原始日志都是text文本格式的,如果把文本格式的数据通过网络传输,磁盘IO、网络IO开销较大,第四、容错和负载均衡怎么做。很明显,这些问题需要一个统一的工具来解决,那么flume就是用来解决数据收集的问题的,因此诞生。
flume简介
flume是一个Apache的顶级开源项目,主要用于数据移动,从A移动到B这样的一个框架。当然这样说只是更好理解。具体的内容我们可以参考官网的简介:
从这里,可以提取到几个关键词:
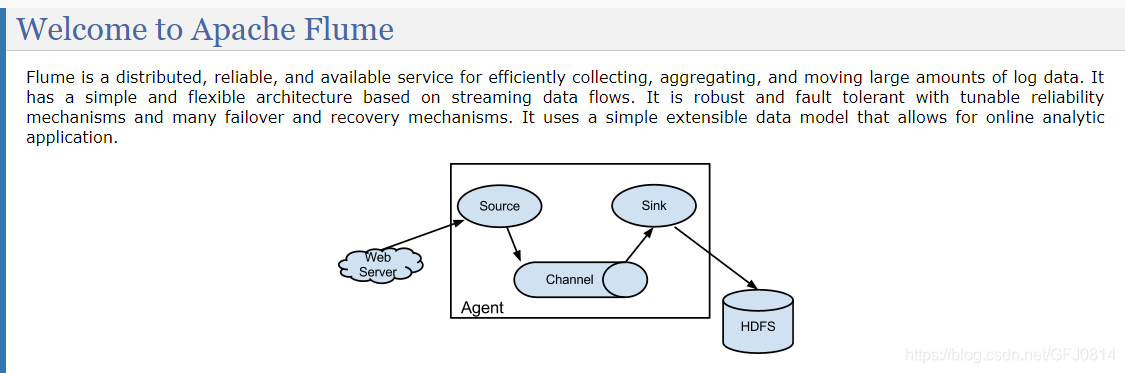
flume具有 collecting(收集), aggregating(聚合), and moving(移动)数据的功能
然后我们再来看它的架构:
一个flume实际上就是一个agent,这个agent又包含了三部分:
-
source:指定数据从哪里来(收集)
从官网的使用手册中,我们可以看到flume的source有很多种:

-
channel:数据暂存起来,用于将source中的数据传输到sink
-
sink:用于将收集到的数据转发送给下游,具体可以sink到地方包括,别的flume节点,HDFS上,输出到日志中logger

flume环境部署
-
下载flume
wget http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.0.tar.gz -
解压flume到用户目录下面的app目录下
tar -zvxf flume-ng-1.6.0-cdh5.7.0.tar.gz -C ~/app/ -
添加环境变量
编辑用户目录下的.bash_profile
添加:
export FLUME_HOME=/root/app/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
保存退出
source .bash_profile:刷新环境变量,使其生效
检测:
flume-ng version 输出flume的版本信息,代表安装成功

flume实战例子
flume的生产中的使用,实际上就是配置agent,写配置文件,指定source、channel、sink的相关配置,启动agent即可。以下举几个栗子增加体会。
- 实战案例一:从指定网络端口采集数据输出到控制台
配置内容:
#配置各个组件的名字(这个flume的配置是agent名字是a1,source是r1,channel是c1,sink是k1)
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#配置source
a1.sources.r1.type=netcat # 指定source的类型,
a1.sources.r1.bind=localhost # 指定采集的数据源网络ip
a1.sources.r1.port=44444 #指定端口
#配置sink
a1.sinks.k1.type=logger
#配置channel
a1.channels.c1.type=memory
#组装source,sink,channel成为一个agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
注意,在组装agent时候,source对应的channel用的是复数,sink对应的channel是单数,也就是说明:
一个source可以输出到多个channel
但是一个channel只能写入到一个sink
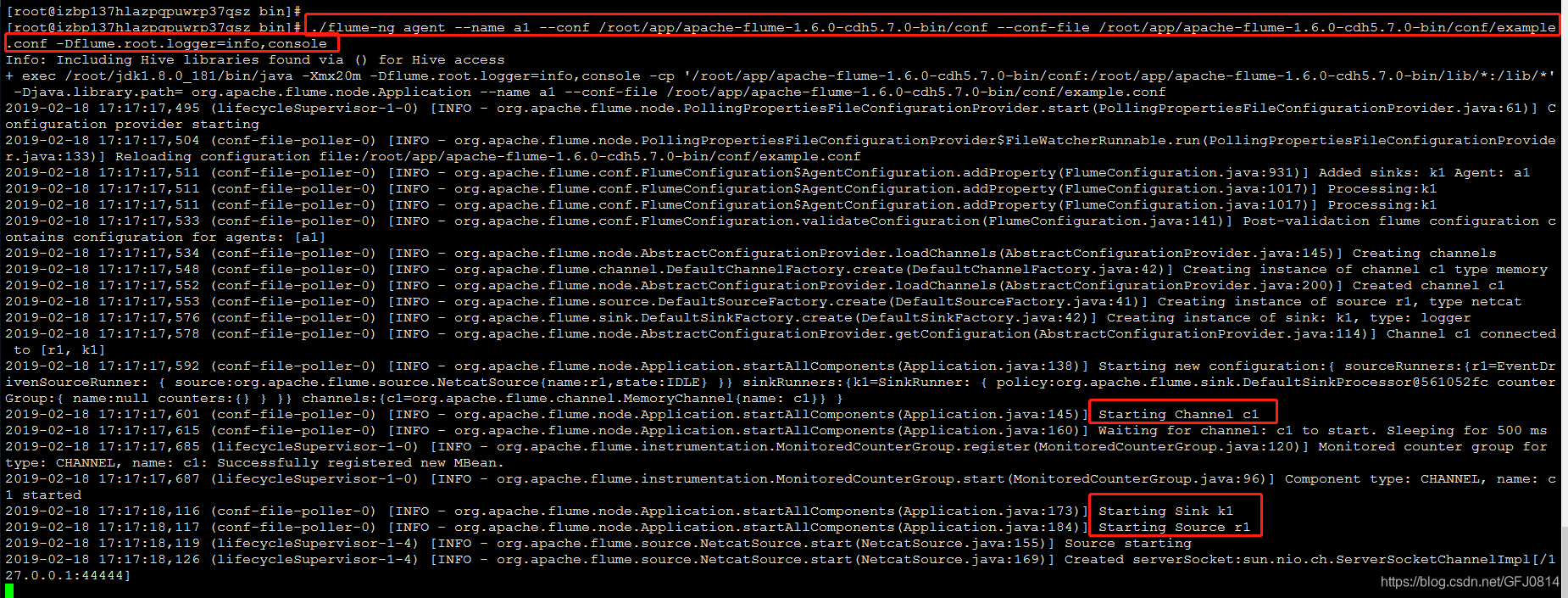
启动flume命令:

启动图示:从启动日志中可以看到channel、sink等组件依次被启动起来了
测试一下效果,我们用Telnet连接监听的localhost:44444,然后向其发送数据,如果输入的数据被sink到日志的控制台,那么就说明采集成功。上图说话:
步骤一:开启一个新窗口,发送测试数据
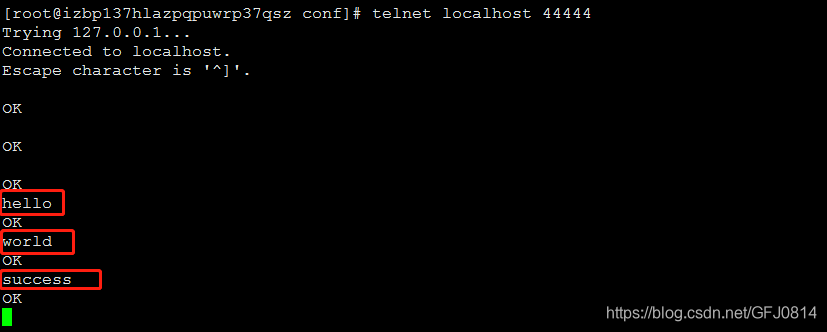
步骤二:在另外一个启动flume的窗口中,在控制台中可以看到已经接收到了数据:

我们可以看到,控制台中输出:
Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
那么这个event是什么呢?这个event是flume中数据传输的基本单元,一个event = 可选的header + 字节数组构成 。一般可以理解为,一个记录就是一个event。
- 实战案例二:监控一个文件,实时采集新增的数据到控制台
(1)将监控到的新增数据输出到控制台上,确定组件类型
首先我们要确定,我们要用哪种类型的source、channel、sink。这里的source因为和之前不一样,来自于监控文件的变化,对应的source,要选择exec source。因为还是输出到控制台,那么sink还是logger,channel继续用内存。
(2)具体配置怎么写?找官网
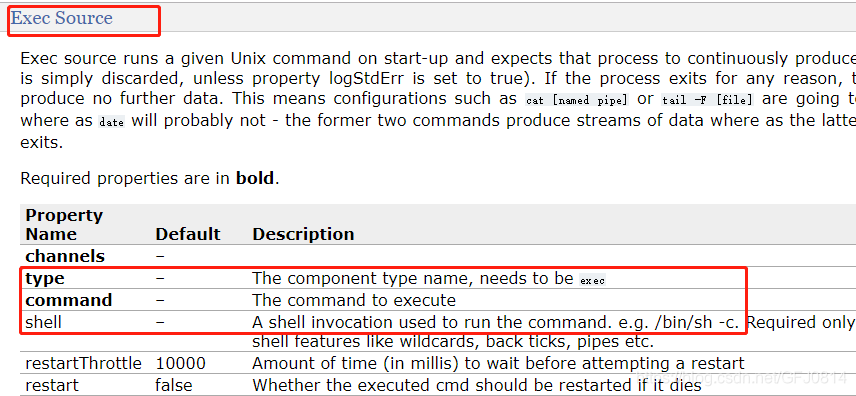
首先type必须设置为exec
监控的命令,因为监控的是文件实时新增数据,所以,监控tail -f 文件
再配置shell 为/bash/sh -c
(3)完整配置内容
#配置各个组件的名字
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#配置source
a1.sources.r1.type=exec
a1.sources.r1.command=tail -f /root/data/data.conf #创建了一个测试文件data.conf用于监控
a1.sources.r1.shell=/bin/sh -c
#配置sink
a1.sinks.k1.type=logger
#配置channel
a1.channels.c1.type=memory
#组装source,sink,channel成为一个agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
(4)测试效果
写入数据到文件
flume监控文件变动,将新增数据打印到控制台:

一般我们可以用于监控日志文件的数据变化,然后将其写入到HDFS,做离线处理,那么这个时候的sink就得选HDFS sink;或者我们将其写入kafka,做实时处理,那么这个时候的sink就选kafka sink。
- 将一台flume1上的文件变动数据传递到另外一台flume2上,打印在控制台上
(1)组件选型
avro sink:一般用于跨界点传输的sink ,指定sink到的机器ip和port
avro source:用于夸节点接收数据
所以技术选型:
源机器flume1: exec source + memory channel + avro sink
目标机器flume2: avro source + memory channel + logger sink
(2)写配置文件,因为这里有两个flume,那么就肯定是两个配置文件
配置读取监控数据并传递到另外一台flume2的flume1,
配置文件:exec-memory-avro.conf
#配置各个组件的名字
exec-memory-avro.sources = r1
exec-memory-avro.channels = c1
exec-memory-avro.sinks = k1
#配置source
exec-memory-avro.sources.r1.type=exec
exec-memory-avro.sources.r1.command=tail -f /root/data/data.conf
exec-memory-avro.sources.r1.shell=/bin/sh -c
#配置sink(这里是重点,配置目标机器的ip信息,并且type是avro)
exec-memory-avro.sinks.k1.type=avro
exec-memory-avro.sinks.k1.hostname=localhost
exec-memory-avro.sinks.k1.port=44444
#配置channel
exec-memory-avro.channels.c1.type=memory
#组装source,sink,channel成为一个agent
exec-memory-avro.sources.r1.channels=c1
exec-memory-avro.sinks.k1.channel=c1
配置接收flume1传来的数据并打印到控制台的flume2
配置文件:avro-memory-logger.conf
#配置各个组件的名字
avro-memory-logger.sources = r1
avro-memory-logger.channels = c1
avro-memory-logger.sinks = k1
#配置source(这里是重点,配置源机器的ip信息,并且type是avro)
avro-memory-logger.sources.r1.type=avro
avro-memory-logger.sources.r1.bind=localhost
avro-memory-logger.sources.r1.port=44444
#配置sink
avro-memory-logger.sinks.k1.type=logger
#配置channel
avro-memory-logger.channels.c1.type=memory
#组装source,sink,channel成为一个agent
avro-memory-logger.sources.r1.channels=c1
avro-memory-logger.sinks.k1.channel=c1
(3)启动flume
启动顺序:因为要把flume1的数据发到flume2,所以,要先启动flume2,才能保证flume1启动能连得上,不然会报连接不上的错误。
开启窗口一:启动接收数据的flume2:
./bin/flume-ng agent --name avro-memory-logger --conf /root/app/apache-flume-1.6.0-cdh5.7.0-bin/conf --conf-file /root/app/apache-flume-1.6.0-cdh5.7.0-bin/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
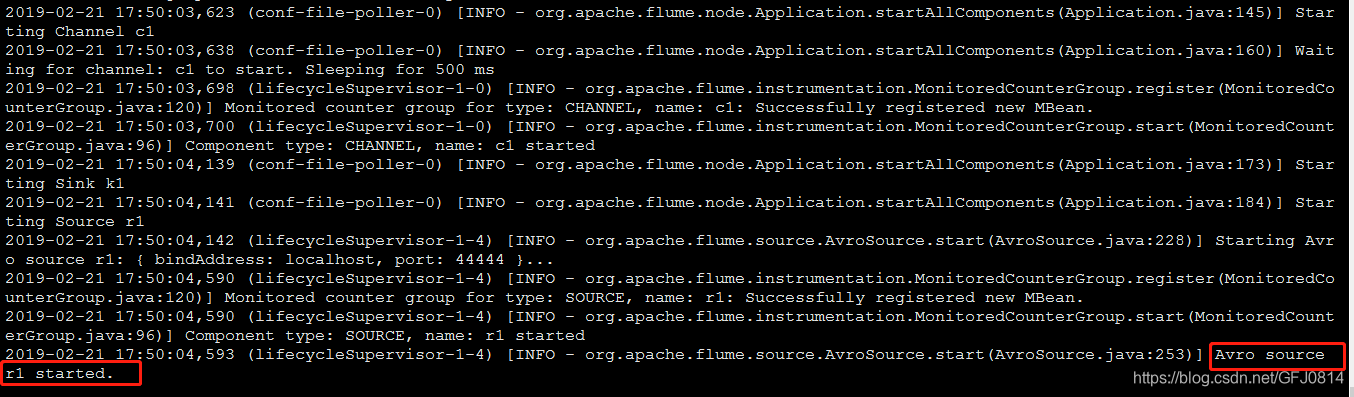
通过图中可以看见,avro source已经被成功启动了
开启窗口二:启动发送数据的flume1:
./bin/flume-ng agent --name exec-memory-avro --conf /root/app/apache-flume-1.6.0-cdh5.7.0-bin/conf --conf-file /root/app/apache-flume-1.6.0-cdh5.7.0-bin/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
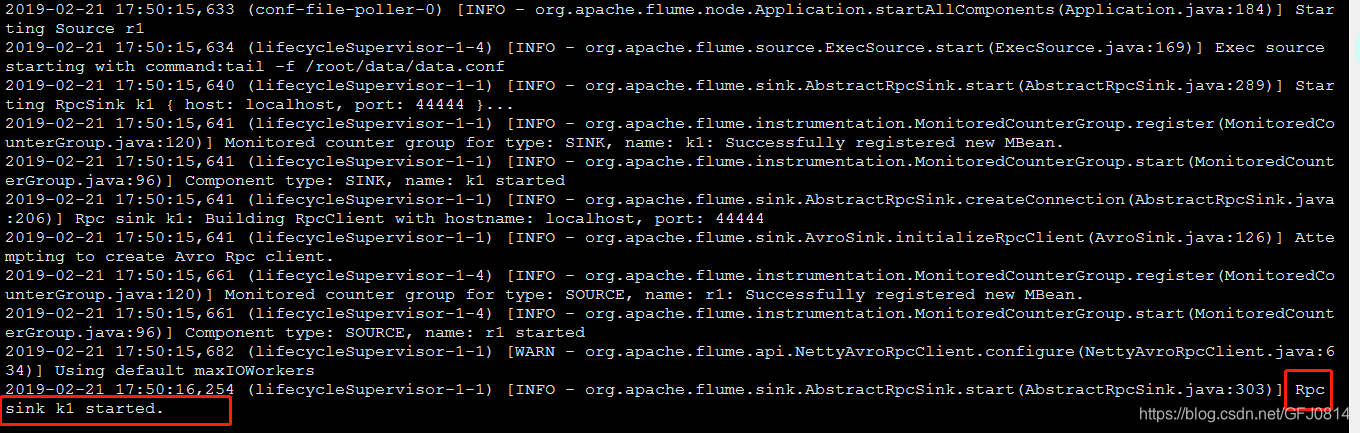
通过图中可以看见,avro sink已经被成功启动了
开启窗口三:向文件中写入数据,测试窗口一是否会有数据输出到控制台

我们可以看见,数据已经通过第一个flume收集到之后传递给第二个flume,打印出来了,完美~~

在操作中会发现,我们在写入数据之后,在控制台打印的时候会有一点延迟,这个是正常的,因为channel不会实时的将数据传输,他们会等待一小段时间或者等到一定的数据量之后再传输,提升传输效率。
结语
综上,就是本篇flume的入门到实战的全部内容了,讲解不是深入,但是感觉入门足够了。通过自己手动实现几个例子下来,对flume这个工具有感性的认识。在学习flume的过程中,感觉到了学会看官网文档很重要,这是一种很高效的学习方式,虽然刚开始有点难,有点害怕,但是生的单词并不多,多熟悉几遍就好了,慢慢啃,时间长了就不怕了。还有学习东西要坚持啊,已经很久没更新博客了,真是罪恶,后面要加快频次,提高博文质量了。好了,碎碎念了一波,不说了,准备下班了。














 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









