









AWK介绍
AWK是贝尔实验室1977年搞出来的为Unix/Linux提供样式扫描与处理工具,非常擅长处理结构化数据和生成表单。与sed 和grep 很相似,但功能却超过
两者,之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的Family Name的首字符。要学AWK,就得提一
提AWK的一本相当经典的书《The AWK Programming Language》。关于perl,python,AWK, sed 之间的比较可以参考这个解答。
AWK基本结构
awk程序由三部分组成,分别为:
初始化(处理输入前做的准备,放在BEGIN块中),数据处理(处理输入数据),收尾处理(处理输入完成后要进行的处理,放到END块中)。
其中,在“数据处理”过程中,指令被写成一系列模式/动作过程,模式是用于测试输入行的规则,以确定是否将应用于这些输入行。
awk有三种调用方式:awk 命令行,使用-f 选项调用awk 程序,利用命令解释器调用awk 程序。
AWK语法
AWK的命令形式如下:
awk [ -F re] [parameter...] ['prog'] [-f progfile] [in_file...]
(1) -F re:允许awk 更改其字段分隔符。默认情况下将制表符和空格都看作字段分隔符(多个空格仍然作为一个分隔符),但是可以将分隔符从空格改
为任何其它字符,就是使用参数-F 如:awk -F : ‘{print $2}’ abc.txt
(2) parameter:该参数帮助为不同的变量赋值。
(3) ‘prog’:awk 的程序语句段。这个语句段必须用单引号:’ 和 ’括起,以防被shell 解释。这个程序语句段的标准形式为:’pattern {action}’
其中pattern 参数可以是egrep 正则表达式中的任何一个,它可以使用语法/re/再加上一些样式匹配技巧构成。与sed 类似,你也可以使用”,”分开两样式
以选择某个范围。action 参数总是被大括号包围,它由一系列awk 语句组成,各语句之间用”;”分隔。awk 解释它们,并在pattern 给定的样式匹配的记
录上执行其操作。你可以省略pattern 和action 之一,但不能两者同时省略,当省略pattern 时没有样式匹配,表示对所有行(记录)均执行操作,省略
action时执行缺省的操作——在标准输出上显示。
总结来说 模式(pattern)可以是以下任意一个:
(a)/正则表达式/:使用通配符的扩展集。
(b)关系表达式:可以用下面运算符表中的关系运算符进行操作,可以是字符串或数字的比较,如$2>%1选择第二个字段比第一个字段长的行。
(c)模式匹配表达式:用运算符~(匹配)和~!(不匹配)。
(d)模式,模式:指定一个行的范围。该语法不能包括BEGIN和END模式。
(e)BEGIN:让用户指定在第一条输入记录被处理之前所发生的动作,通常可在这里设置全局变量。
(f)END:让用户在最后一条输入记录被读取之后发生的动作。
操作(action)由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大括号内。主要有四部份:
(a)变量或数组赋值
(b)输出命令
(c)内置函数
(d)控制流命令
(4) -f progfile:允许awk 调用并执行progfile 指定有程序文件。progfile 是一个文本文件,它必须符合awk 的语法。
(5) in_file:awk的输入文件,awk 允许对多个输入文件进行处理。值得注意的是awk 不修改输入文件。如果未指定输入文件,awk 将接受标准输入,
并将结果显示在标准输出上。
AWK的 记录与字段
awk将每一行作为一条记录,将每条记录按分割条件进行分割后的一域叫字段。整条记录表示为$0, 第一个字段$1,第二个字段$2……
AWK 举例
通过上面的理论介绍 感觉还是没法 看到AWK的真正威力,下面举例说明AWK的使用方法。
测试文件的数据(文件名为test.txt)如下:
对应的字段分别为:
序号 姓名 性别 地址 月薪
1 Daniel M China 12000
2 Jack M USA 8000
3 Eva F UK 9000
4 Wang M China 7000 1,awk的内置变量使用
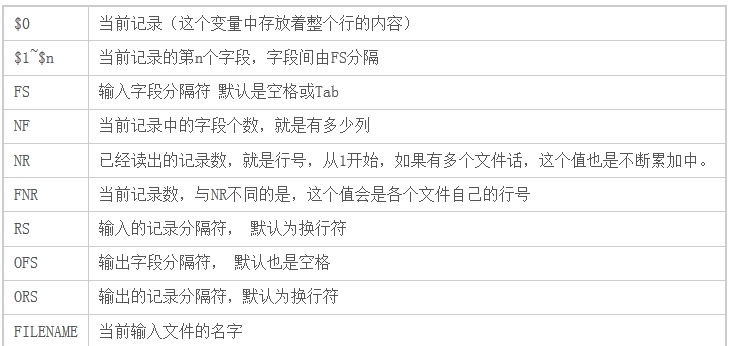
awk中有两类内置的变量,一类用户可根据需要改变,主要有:FS:输入数据的字段分割符,RS:输入数据的记录分隔符,OFS:输输出数据的字段分割符,
ORS:输出数据的记录分隔符;另一类是系统自动改变的,如:NF:当前记录的字段个数,NR:当前记录编号等。
比如我们想打印测试文件中的用户名及其所在行号, 命令为:awk '{print NR,$2}' OFS="," test.txt
执行结果为:
1,Daniel
2,Jack
3,Eva
4,Wang
这个输出字段分隔符为"," 并且 输出行号 NR。
2,pattern/action模式举例
awk程序部分采用了pattern/action模式,即,针对匹配pattern的数据,使用action逻辑进行处理。
比如输出性别为男性的成员名 及其 序号 命令为: awk '$3 ~ /M/ {print $1,$2}' OFS="," test.txt
执行结果为:
1,Daniel
2,Jack
4,Wang
其实 ~ 表示模式开始。/ /中是模式。这就是一个正则表达式的匹配。
也可以通过模式取反来达到上面的效果 命令如: awk '$3 !~ /F/ {print $1,$2}' OFS="," test.txt
再如 显示出序号大于3的记录,命令如:awk '$1>3 {print $1,$2}' OFS="," test.txt
执行结果为:
4,Wang
3,BEGIN和 END
awk中BEGIN和END,提供BEGIN和END的作用是给程序赋予初始状态和在程序结束之后执行一些扫尾的工作。任何在BEGIN之后列出的
操作(在{}内)将在Unix awk开始扫描输入之前执行,而END之后列出的操作将在扫描完全部的输入之后执行。因此,通常使用BEGIN来显
示变量和预置(初始化)变量,使用END来输出最终结果。
例如统计测试文件中所有人的月薪和 命令为: awk 'BEGIN {print "ALL ";sum=0} {sum=sum+$5} END {printf "sum is:%d\n", sum}' test.txt
结果为:
ALL
sum is:36000
4,条件语句
awk中的条件语句与C相似,但它有更好地支持,包括 if, if/else语句。
如输出若有男性及姓名 命令为: awk '{if( $3 !~ /F/ ) {print $1,$2}}' OFS="," test.txt
5,循环语句
循环语句与C很相似,包括do…while,for,continue/break,while等
如输出第一行 每个字段占一行 命令为:awk 'NR==1 { i = 1; while ( i <= NF ) { print $i; i++}}' test.txt
结果为:
1
Daniel
M
China
12000
6,数组
awk中的数组的下标可以是数字和字母,称为关联数组。用变量作为数组下标。
如统计测试文件中男女个数 并输出 命令为:awk '{a[$3]++;} END {for (i in a) print i "," a[i];}' test.txt
结果为:
F,1
M,3
数组a中的下标是测试文件中的第三列 即 性别,其初始 a[$3] 从0开始计数自增。在END模块中,for循环被用于循环整个数组,
打印那些存储在数组中的值。
7,内建函数
(a), 字符串函数
sub函数, 将test.txt中的Eva换成Emely并输出:awk '{sub(/Eva/,"Emely");print}' test.txt
gsub函数 作用如sub,但它在整个文档中进行匹配。如:awk '{gsub(/Eva/,"Emely");print}' test.txt
(b),index函数
作用:找到第2个字符串在第1个字符串的位置。从1开始,0表示不匹配
如 输出e在第二个字段(即名字)中出现的位置 命令为:awk '{print index($2, "e")}' test.txt
(c),length函数
作用:返回记录的字符数。
如 输出各行 名字长度 命令为:awk '{print length($2)}' test.txt
(d),substr函数
作用:截取字符串
如 截取第二个字段(即名字)中从第二个字符开始的3个字符。 awk '{print substr($2, 2,3)}' test.txt
结果为:
ani
ack
va
ang
(e),match函数
作用:match函数返回在字符串中符合正则表达式的起始位置,如果找不到指定的正则表达式则返回0。
match函数会设置内建变量RSTART为字符串中子字符串的开始位置,RLENGTH为到子字符串末尾的字符个数。substr可利于这些变量来截取字符串。
如 打印以连续小写字符结尾的开始位置及RSTART和RLENGTH变量的值 命令为:
awk '{start=match($2, /[a-z]+$/);print start,RSTART, RLENGTH }' test.txt
结果为:
2 2 5
2 2 3
2 2 2
2 2 3
(f),toupper和tolower
作用:大小写转换
如 将第二个字段字符 转换为小写输出 命令为:awk '{print tolower($2)}' test.txt
(g),split函数
作用:按一个字符串分割成一个数组
如: awk '{split("9:56:00",time,":"); print time[2]}' // 结果为 56
再如 把字符串 a:b:c 根据:拆分为多行,命令如下:
echo "a:b:c" | awk '{n=split($0,a,":");i=1;while(i<=n) print a[i++]}'
输出:
a
b
c
另例:
(h),awk允许自定义函数,语法是:function name(parameter-list) {statements;}
如:
Function insert(STRING, POS, INS) {
before_tmp = substr(STRING, 1, POS)
after_tmp = substr(STRING, POS + 1)
return before_tmp INS after_tmp
}
调用方法:print insert($1, 4, “XX”)
此外还有内建时间、数学函数 在此不 敷述了 可以 google下。
8,输入、输出和源文件
AWK 工具可以从文件中读取其输入,正如在此之前所有示例所做的那样,它也可以从其他命令的输出中获取输入。
例如, 输出字段1和字段2:cat test.txt | awk '{print $1,$2}'
awk可使用shell的重定向符进行重定向输出。
例如 输入行号和第一个字段,到file.txt中:awk '{print NR,$2 >"file.txt"}' test.txt
9,排序与排重
awk可以结合 sort, uniq命令实现 排序和排重。
sort 经常与 uniq 命令一起使用,从已排序的文件中删除完全相同的行。uniq 命令在管道中经常跟在 sort 命令的后面,还可以使用 -c 选项来计算
某一行所出现的次数,或者使用 -d 选项,只报告完全相同的行:
例如 统计出各个地址有多少人, 命令为:awk '{print $4}' test.txt | sort | uniq -c | sort -rn |more
结果为:
2 China
1 USA
1 UK
有点SQL的感觉了,其中SQL常用统计分析在 AWK中的实现参考这篇文章。
10,其它
将shell命令的执行结果送给awk处理 如:
例:示例awk处理shell命令的执行结果
$who -u | awk ‘{printf(“%s正在执行%s\n”,$2,$1)}’
此外 shell script和awk的互调用等。
好了,awk需要经常使用练习才能熟练,留下的作者自己练习了。
参考资料:
http://fanqiang.chinaunix.net/program/other/2005-09-07/3621.shtml
http://coolshell.cn/articles/9070.html/comment-page-1
http://m.blog.csdn.net/blog/djy1135/2574080
sed awk学习:
https://github.com/arganzheng/arganzheng.github.com/blob/master/_posts/2011-08-12-ifttt-patern-language-sed-and-awk-in-depth.md














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









