







本文讲述如何在Mali-T600系列GPU和CPU之间高效共享内存。
介绍
当处理大量数据时(在OpenCL应用中这是典型的情况),确保主机与OpenCL设备之间尽可能高效地共享内存是非常重要的。我们已在hello world样例中看到了如何使用内存缓冲区。hello world例程遵循了我们认为的对于在主机和OpenCL设备之间共享内存的“最佳实践”。这一教程讲述这些最佳实践方法。除非另作说明,否则所有代码片段来自"hello_world_vector.cpp"。
共享内存系统
典型地,OpenCL运行在应用处理器和GPU具有独立内存的系统上。为了在这些系统中共享CPU与GPU之间的内存,你必须分配缓冲区,拷贝数据从/来自独立内存。
典型地,带Mali GPU的系统具有共享内存,因此你无需拷贝数据。然而,OpenCL假设内存是分开的,缓冲区分配涉及内存拷贝。这相当浪费,因为拷贝需要时间并且消耗能量。
跨设备数据共享
为了避免拷贝,使用OpenCL API来分配内存缓冲区,并使用映射操作。这些操作同时使能了应用处理器和Mali GPU来访问数据而无需任何拷贝。注意:在分配内存缓冲区之前,必须先初始化OpenCL。
1. 分配内存缓冲区
应用程序通过调用clCreateBuffer(),来创建可以传递数据从/到内核的缓冲区对象。所有的内存都分配在一个共享的内存系统上,该共享的内存系统在物理上可以同时被CPU和GPU核访问。然而,只有由clCreateBuffer()分配的内存,才会被同时映射到CPU和GPU的虚拟内存空间。因此,由malloc()等函数分配的内存,只会被映射到CPU上(如图1)。
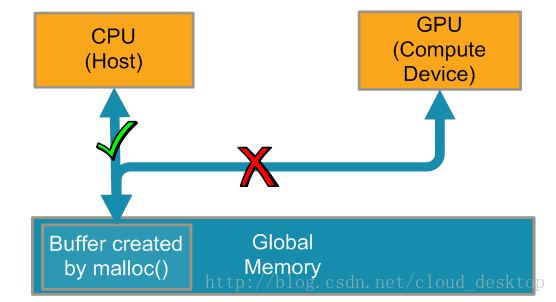
图1:由用户(malloc)分配的内存不会被映射到GPU内存空间
因此,使用CL_MEM_USE_HOST_PTR标志调用clCreateBuffer(),传递到用户创建的缓冲区,需要创建一个新的缓冲区并拷贝数据(同CL_MEM_COPY_HOST_PTR)。这个拷贝使得性能下降(如图2)。
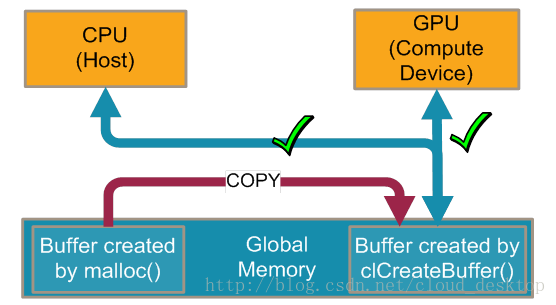
图2:clCreateBuffer(CL_MEM_USE_HOST_PTR)创建一个新的缓冲区,然后复制数据(拷贝操作是代价高昂的)
所以,总是尽可能地使用CL_MEM_ALLOC_HOST_PTR标志。这样就分配了一块CPU和GPU都可以访问的内存,无需拷贝(如图3)。
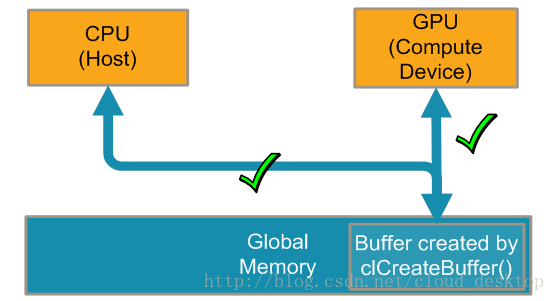
图3:clCreateBuffer(CL_MEM_ALLOC_HOST_PTR)创建了一个同时对CPU和GPU可见的缓冲区
memoryObjects[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_ALLOC_HOST_PTR, bufferSize, NULL, &errorNumber);
createMemoryObjectsSuccess &= checkSuccess(errorNumber);
memoryObjects[1] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_ALLOC_HOST_PTR, bufferSize, NULL, &errorNumber);
createMemoryObjectsSuccess &= checkSuccess(errorNumber);
memoryObjects[2] = clCreateBuffer(context, CL_MEM_WRITE_ONLY | CL_MEM_ALLOC_HOST_PTR, bufferSize, NULL, &errorNumber);
createMemoryObjectsSuccess &= checkSuccess(errorNumber);
2. 映射内存对象
如前面所述,我们映射由OpenCL实现创建的内存缓冲区到指针,从而可以在CPU端访问它们。
cl_int* inputA = (cl_int*)clEnqueueMapBuffer(commandQueue, memoryObjects[0], CL_TRUE, CL_MAP_WRITE, 0, bufferSize, 0, NULL, NULL, &errorNumber);
mapMemoryObjectsSuccess &= checkSuccess(errorNumber);
cl_int* inputB = (cl_int*)clEnqueueMapBuffer(commandQueue, memoryObjects[1], CL_TRUE, CL_MAP_WRITE, 0, bufferSize, 0, NULL, NULL, &errorNumber);
mapMemoryObjectsSuccess &= checkSuccess(errorNumber);3. 使用C指针初始化数据
一旦缓冲区被映射到一个cl_int类型的指针,它们可以像普通的C指针那样来使用,以初始化数据。
for (int i = 0; i < arraySize; i++)
{
inputA[i] = i;
inputB[i] = i;
}4. 取消内存对象的映射
当我们结束使用内存对象,从CPU端对它们取消映射。之所以这么做是因为:
(1). 在OpenCL端的内核内部,读写那个内存的行为是未定义的;
(2). 在完成时,OpenCL实现无法释放那个内存。
if (!checkSuccess(clEnqueueUnmapMemObject(commandQueue, memoryObjects[0], inputA, 0, NULL, NULL)))
{
cleanUpOpenCL(context, commandQueue, program, kernel, memoryObjects, numberOfMemoryObjects);
cerr << "Unmapping memory objects failed " << __FILE__ << ":"<< __LINE__ << endl;
return 1;
}
if (!checkSuccess(clEnqueueUnmapMemObject(commandQueue, memoryObjects[1], inputB, 0, NULL, NULL)))
{
cleanUpOpenCL(context, commandQueue, program, kernel, memoryObjects, numberOfMemoryObjects);
cerr << "Unmapping memory objects failed " << __FILE__ << ":"<< __LINE__ << endl;
return 1;
}补充建议
除了上面的建议,我们附加下述建议:
(1).请勿使用私有(private)或局部(local)内存,使用这些在Mali-T600系列GPU上并无性能增益。
(2). 如果你的内核是在有限内存带宽的情况下,使用一个公式来计算变量,而不是从内存中读取。















 2155
2155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









