






背景介绍
某应用使用schedulerx来做定时任务执行,每隔一小时执行一次,每次执行5分钟左右,执行任务期间CPU使用率90%+。
问题现象
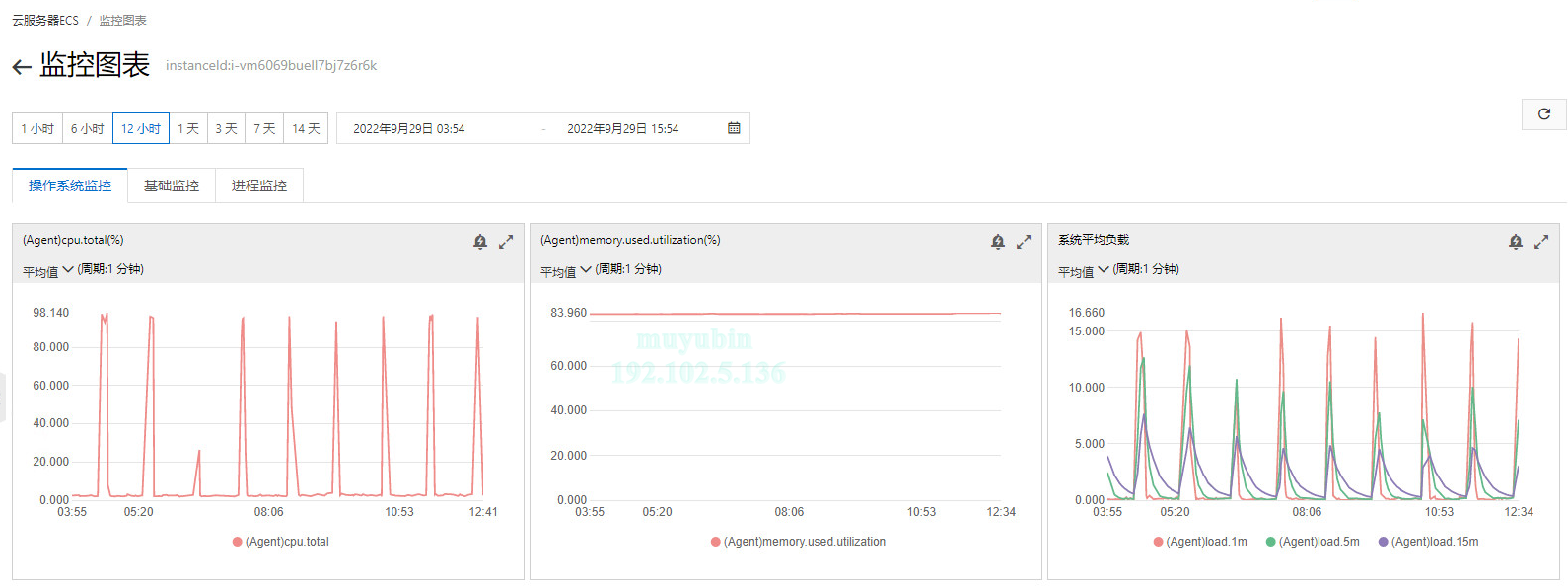
ECS配置是4c8g,从上图来看系统负载已经非常高了。
分析过程
寻找热点代码
arthas profiler比较适用CPU使用率持续较高的场景。通过对热点火焰图的分析,NoSuchMethodException异常相关代码占用了很多CPU时间。
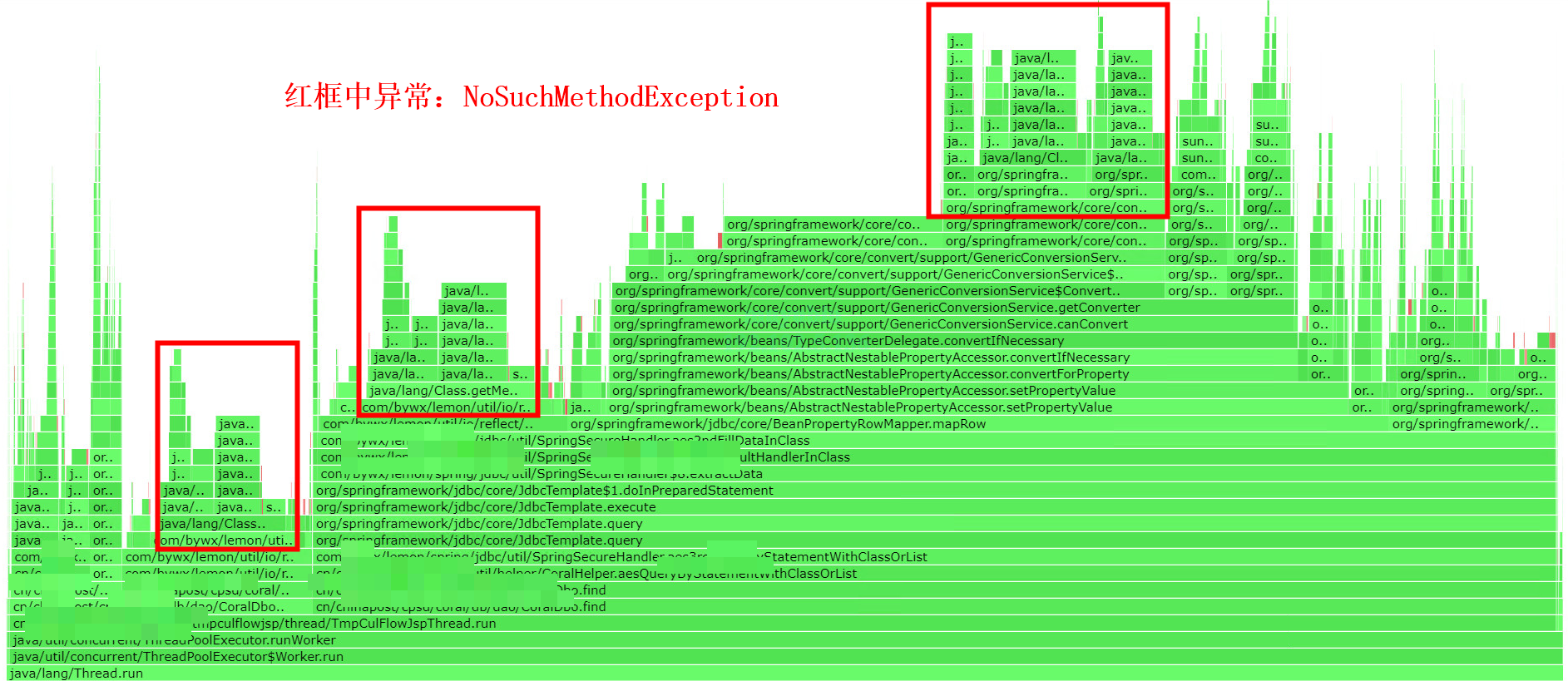
上图红框中NoSuchMethodException展开后如下图:
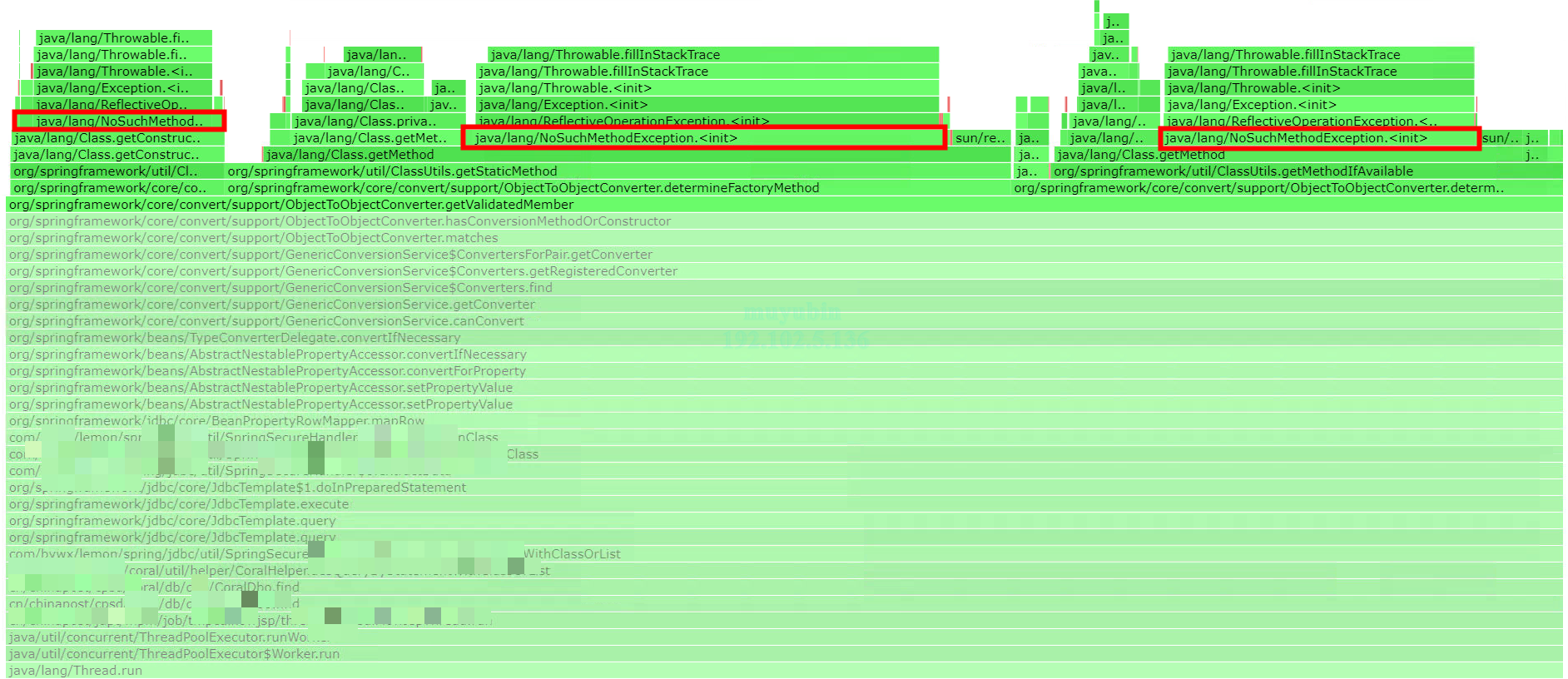
分析异常
ClassUtils
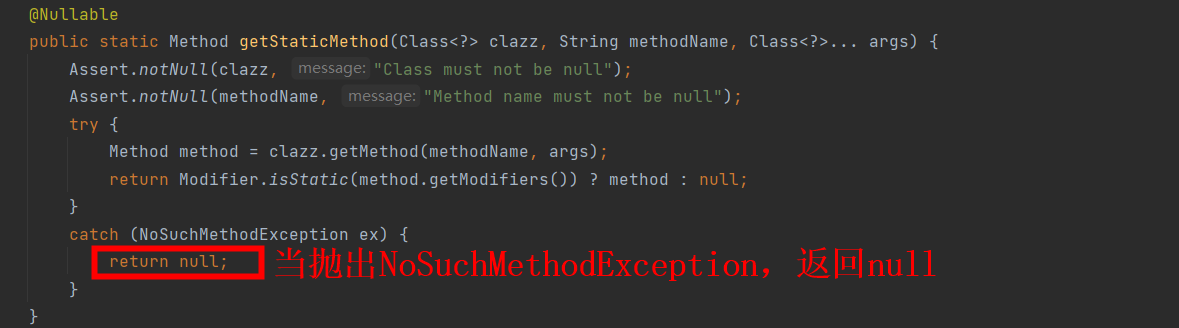
从上图可以看出org.springframework.util.ClassUtils.getStaticMethod调用了Class.getMethod,Class.getMethod抛出了NoSuchMethodException,代码如下。
为了进一步定位问题,需要知道ClassUtils.getStaticMethod方法的入参:

从上图看出ClassUtils.getStaticMethod方法入参分别是:
**clazz:java.util.Date;_methodName:_valueOf;args[0]:**java.sql.Timestamp。上面图片只是截取了一部分,其中methodName还有of、from。
ObjectToObjectConverter
调用ClassUtils.getStaticMethod的地方是org.springframework.core.convert.support.ObjectToObjectConverter.determineFactoryMethod:
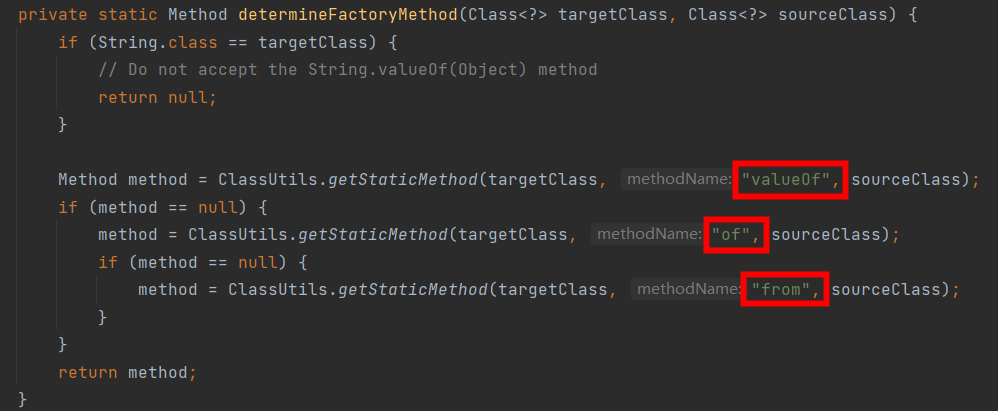
调用ObjectToObjectConverter.determineFactoryMethod的地方是ObjectToObjectConverter.getValidateMember:
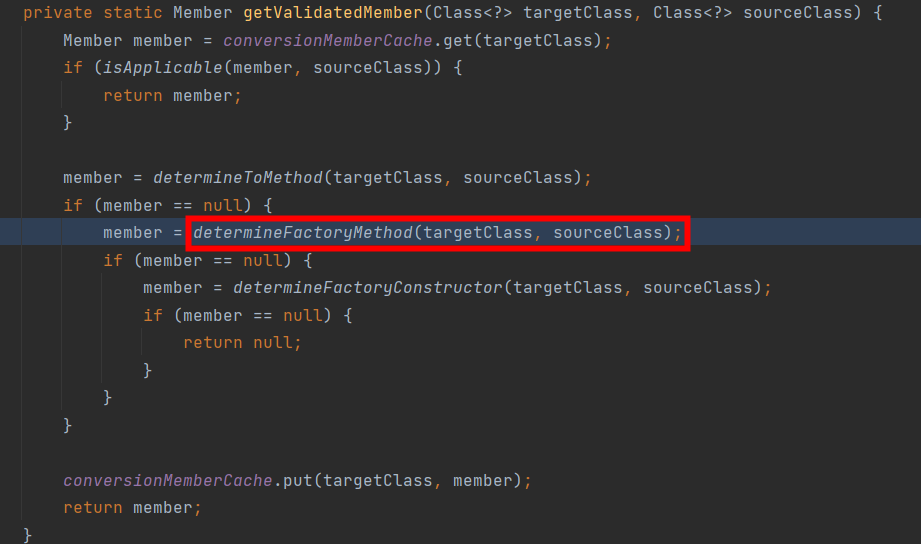
虽然java.sql.Timestamp是java.util.Date的子类,但是从上面代码可以看出进行了很多次无效的调用。
定位业务代码
定位业务代码
为了更准确的定位相关业务代码,我们需要知道抛出NoSuchMethodException的线程栈,可以使用arthas stack,从线程栈我们可以知道在【哪个类哪个方法哪行】发出的调用。
stack org.springframework.util.ClassUtils getStaticMethod 'returnObj==null'
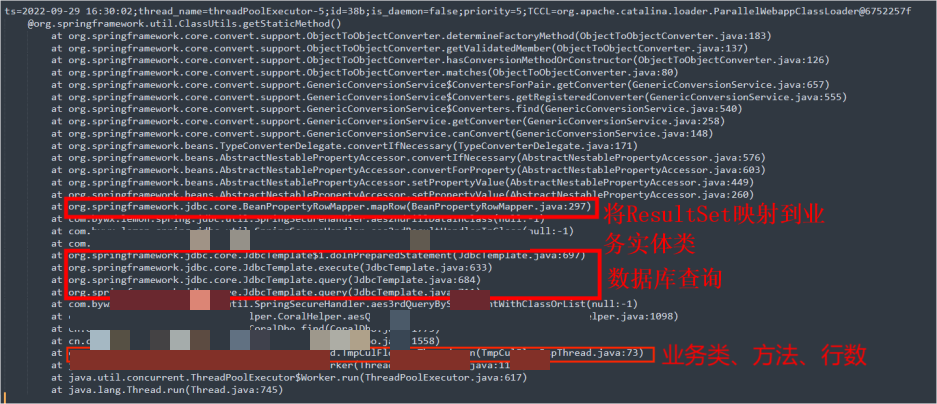
分析业务代码
在我们没有源代码的情况,我们可以使用arthas jad反编译定位到的类,进而分析业务代码,到这里就可以具体定位到问题了。
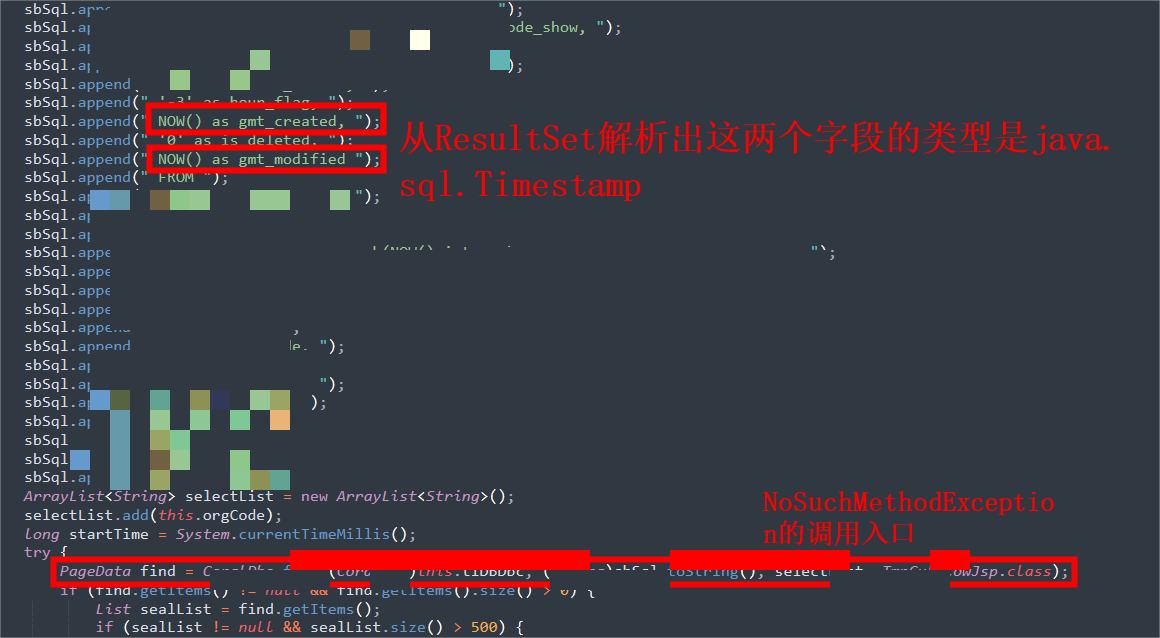
gmt_created、gmt_modified在实体类中的定义:
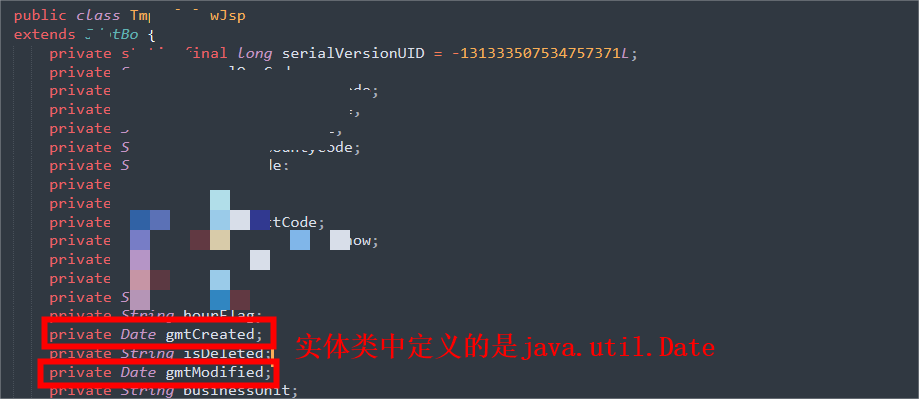
异常场景回顾
- 查询数据库,数据库返回ResultSet对象
- 遍历ResultSet,将ResultSet每一行映射到相应的业务实体类
- 实例化业务实体类,根据ResultSet.getMetaData()获取每一列的值并将该值set到实体类对应属性上
- 在将gmt_created、gmt_modified解析为java.sql.Timestamp类实例,接着使用ObjectToObjectConverter将java.sql.Timestamp转换为java.util.Date的时候抛出了NoSuchMethodException
- 实例化业务实体类,根据ResultSet.getMetaData()获取每一列的值并将该值set到实体类对应属性上
异常场景复现示例代码
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import java.util.List;
public class TimestampToDateTest {
public static void main(String[] args){
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:mysql://localhost/world?useSSL=false&serverTimezone=UTC");
dataSource.setUsername("root");
dataSource.setPassword("");
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
String sql = "select now() as gmt_created,now() as gmt_modified";
RowMapper rowMapper = new BeanPropertyRowMapper(TimestampToDate.class);
List<TimestampToDate> list = jdbcTemplate.query(sql,rowMapper);
for(TimestampToDate timestampToDate : list){
System.out.println(timestampToDate.getGmtCreated().getClass().getName());
}
}
}
import java.util.Date;
public class TimestampToDate {
private Date gmtCreated;
private Date gmtModified;
public Date getGmtCreated() {
return gmtCreated;
}
public void setGmtCreated(Date gmtCreated) {
this.gmtCreated = gmtCreated;
}
public Date getGmtModified() {
return gmtModified;
}
public void setGmtModified(Date gmtModified) {
this.gmtModified = gmtModified;
}
}
解决办法
数据库表中gmt_created、gmt_modified类型与实体类中对应字段类型的定义保持一致,可以解决异常。
延申阅读
通过提高BeanPropertyRowMapper相关逻辑的缓存命中率可以进一步优化性能,如提前将转换逻辑放到GenericConversionService类的converters中:
BeanPropertyRowMapper rowMapper = new BeanPropertyRowMapper(TimestampToDate.class);
DefaultConversionService conversionService = (DefaultConversionService)rowMapper.getConversionService();
conversionService.addConverter(Timestamp.class, Date.class, new Converter<Timestamp, Date>() {
@Override
public Date convert(Timestamp source) {
return source;
}
});
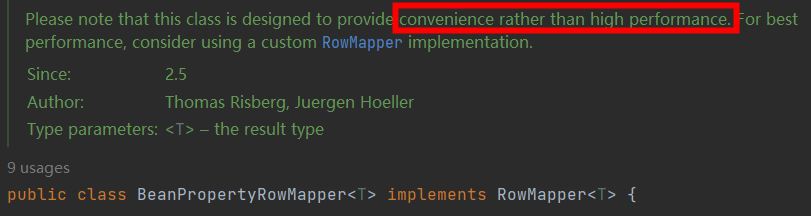
另外可以通过自定义RowMapper来提高性能,因为BeanPropertyRowMapper并不是高性能的一种实现:















 1721
1721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









