







Compare-Aggregate模型
SEQ2SEQ模型
即:输入输出均为序列的模型为seq2seq模型。例如生成式聊天机器人、机器翻译。

文本间attention应用
假设有两个输入文本:text_a和text_b,两个文本经LSTM后有输出向量A、B(A和B维度一致)。
A关注B生成A的新特征表示:
首先计算attention系数:
a
l
p
h
a
=
s
o
f
t
m
a
x
(
A
∗
B
T
)
alpha = softmax(A*B^T)
alpha=softmax(A∗BT)
求取A的attention向量:
A
′
=
a
l
p
h
a
T
∗
A
A' = alpha^T * A
A′=alphaT∗A
def att(A,B):
score = torch.mm(A, B.T)
alpha = torch.softmax(score, dim=1)
return torch.mm(alpha.T, A)
Compare-Aggregate模型
比较聚合网络:
比较:即交互,如下图。C和D的生成都用到了A和B,那么C和D都是A和B交互后的产物。

聚合:即提取特征,如全连接网络、CNN、RNN等特征提取器。聚合过程一般把文本的特征矩阵转化为特征向量。
整体结构:

预处理层: 利用词嵌入作为输入,并利用简化的门控机制输出特征信息
注意力层:A关注B生成A的新特征表示
比较层:作者尝试了多种不同的比较方式
聚合层:利用CNN网络作为特征提取器
比较层
比较函数:
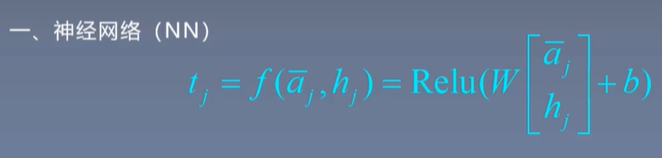




代码
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from data_load import load_char_data
class Preprocess(nn.Module):
def __init__(self, in_features, out_features):
super(Preprocess, self).__init__()
self.wi = nn.Parameter(torch.randn(in_features, out_features))
self.bi = nn.Parameter(torch.randn(out_features))
self.wu = nn.Parameter(torch.randn(in_features, out_features))
self.bu = nn.Parameter(torch.rand(out_features))
def forward(self,x ):
gate = torch.matmul(x, self.wi)
gate = torch.sigmoid(gate + self.bi.expand_as(gate))
out = torch.matmul(x, self.wu)
out = torch.tanh(out + self.bu.expand_as(out))
return gate * out
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.wg = nn.Parameter(torch.randn(hidden_size, hidden_size))
self.bg = nn.Parameter(torch.randn(hidden_size))
def forward(self, q, a):
G = torch.matmul(q, self.wg)
G = G + self.bg.expand_as(G)
G = torch.matmul(G, a.permute(0, 2, 1))
G = torch.softmax(G, dim=1)
H = torch.matmul(G.permute(0, 2, 1), q)
return H
class Compare(nn.Module):
def __init__(self, hidden_size):
super(Compare, self).__init__()
self.w = nn.Parameter(torch.randn(hidden_size * 2, hidden_size))
self.b = nn.Parameter(torch.randn(hidden_size))
def forward(self, h, a):
sub = (h - a) * (h - a)
mult = h * a
T = torch.matmul(torch.cat([sub, mult], dim=2), self.w)
T = torch.relu(T + self.b.expand_as(T))
return T
class ComAgg(nn.Module):
def __init__(self, config):
super(ComAgg, self).__init__()
self.config = config
self.embedding = nn.Embedding(config.voacb_size, config.embedding_size)
self.embedding.weight.data.copy_(torch.from_numpy(config.embed))
self.preprocess = Preprocess(config.embedding_size, config.hidden_size)
self.attention = Attention(config.hidden_size)
self.compare = Compare(config.hidden_size)
self.aggregte = nn.Conv1d(in_channels=config.maxa_len,
out_channels=config.window,
kernel_size=(3,),
stride=(1,),
padding=(1,))
self.predict = nn.Linear(config.window * config.hidden_size, config.classes)
def forward(self, q, a):
emb_q = self.embedding(q)
emb_a = self.embedding(a)
q_bar = self.preprocess(emb_q)
a_bar = self.preprocess(emb_a)
# 注意力层
H = self.attention(q_bar, a_bar)
# 比较层
T = self.compare(H, a_bar)
# 聚合层
r = self.aggregte(T)
r = r.view(-1, self.config.window * self.config.hidden_size)
out = self.predict(r)
return out















 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









