







一、容器的概念
为什么使用集合框架?
假设我们要存储一个班的学员信息,假定一个班容纳20名学员。

那么如何存储每天的新闻信息?

如果并不知道程序运行时会需要多少个对象,或者需要更复杂的方式存储对象–可以使用Java集合框架。
Java集合框架包含的内容: Java集合框架提供了一套性能优良、使用方便的接口和类,它们位于java.util包中。
1、接口
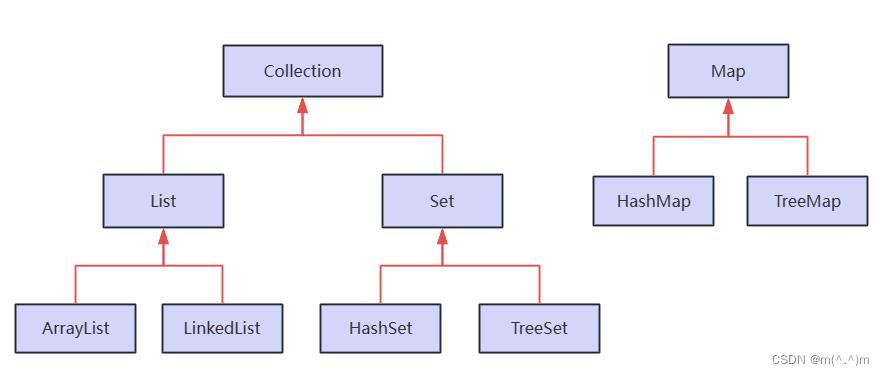
2、具体类
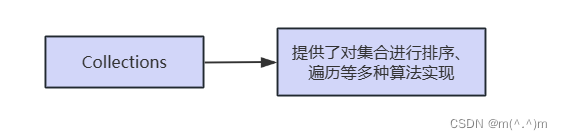
3、算法
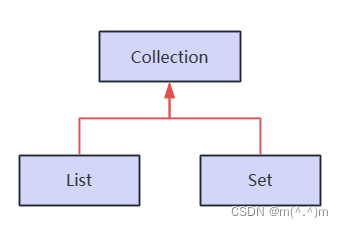
二、Collection接口
Collection存放的都是单一的值。
Collection接口的常用方法
- 集合作为容器应该具有的功能(增、删、改、查),不一定全有。
- 集合的基本操作:增加,删除,判断,取出。
特点:
1、可以存放不同类型的数据,而数组只能存放固定类型的数据。
2、当使用arraylist子类实现的时候,初始化的长度是10,当长度不够的时候会自动进行扩容操作。
| 序号 | 方法名 | 作用 |
|---|---|---|
| 1 | add(Object obj) | 添加,存储的是对象的引用 |
| 2 | size() | 容器中元素的实际个数 |
| 3 | remove(Object obj) clear() removeAll(Collection<?> c) retain(Collection<?> c) | 删除 |
| 4 | contains(Object obj) isEmpty() | 判断元素 |
| 5 | iterator() | 遍历元素 |
增加操作的示例代码:
/*
* 增加数据的方法
* add:要求必须传入的参数是Object对象,因此当写入进本数据类型的时候,包含自动拆箱和自动装箱的过程
* addAll:添加另一个集合的元素到此集合中
* */
import java.util.ArrayList;
import java.util.Collection;
public class Test {
public static void main(String[] args) {
Collection collection = new ArrayList();
collection.add(1);
collection.add(true);
collection.add(1.23);
collection.add("abc");
System.out.println(collection);
((ArrayList)collection).add(0,"liyunfei");
System.out.println(collection);
Collection collection1 = new ArrayList();
collection1.add("a");
collection1.add("b");
collection1.add("c");
collection1.add("d");
collection.addAll(collection1);
System.out.println(collection);
}
}
// 输出的结果是:
// [1, true, 1.23, abc]
// [liyunfei, 1, true, 1.23, abc]
// [liyunfei, 1, true, 1.23, abc, a, b, c, d]
删除操作的示例代码:
/*
* 删除数据的方法
* clear:只是清空集合中的元素,但是此集合对象并没有被回收
* remove:删除指定元素
* removeAll:删除集合元素
*
* */
import java.util.ArrayList;
import java.util.Collection;
public class Test {
public static void main(String[] args) {
Collection collection = new ArrayList();
collection.add(1);
collection.add(true);
collection.add(1.23);
collection.add("abc");
System.out.println(collection);
Collection collection1 = new ArrayList();
collection1.add("a");
collection1.add("b");
collection1.add("c");
collection1.add("d");
collection.addAll(collection1);
System.out.println(collection);
collection.remove("a");
System.out.println(collection);
collection.removeAll(collection1);
System.out.println(collection);
collection.clear();
System.out.println(collection);
}
}
// 输出的结果是:
// [1, true, 1.23, abc]
// [1, true, 1.23, abc, a, b, c, d]
// [1, true, 1.23, abc, b, c, d]
// [1, true, 1.23, abc]
// []
查询操作的示例代码:
/*
* 查询数据的方法
* contains:判断集合中是否包含指定的元素值
* containsAll:判断此集合中是否包含另一个集合
* isEmpty:判断集合是否等于空
* retainAll:若集合中拥有另一个集合的所有元素,则返回true,否则返回false
* size:返回当前集合的大小
* */
import java.util.ArrayList;
import java.util.Collection;
public class Test {
public static void main(String[] args) {
Collection collection = new ArrayList();
collection.add(1);
collection.add(true);
collection.add(1.23);
collection.add("abc");
System.out.println(collection);
((ArrayList)collection).add(0,"liyunfei");
System.out.println(collection);
Collection collection1 = new ArrayList();
collection1.add("a");
collection1.add("b");
collection1.add("c");
collection1.add("d");
collection.addAll(collection1);
System.out.println(collection);
System.out.println(collection.contains("a"));
System.out.println(collection.containsAll(collection1));
System.out.println(collection.isEmpty());
System.out.println(collection1.retainAll(collection));
System.out.println(collection.size());
}
}
// 输出的结果是:
// [1, true, 1.23, abc]
// [liyunfei, 1, true, 1.23, abc]
// [liyunfei, 1, true, 1.23, abc, a, b, c, d]
// true
// true
// false
// false
// 9
其它操作的示例代码:
/*
* 集合转数组的操作
* toArray:将集合转换成数组
* */
import java.util.ArrayList;
import java.util.Collection;
public class Test {
public static void main(String[] args) {
Collection collection = new ArrayList();
collection.add(1);
collection.add(true);
collection.add(1.23);
collection.add("abc");
System.out.println(collection);
((ArrayList)collection).add(0,"liyunfei");
System.out.println(collection);
Object[] objects = collection.toArray();
for (Object object : objects) {
System.out.println(object);
}
collection.add("a");
System.out.println(collection);
}
}
// 输出的结果是:
// [1, true, 1.23, abc]
// [liyunfei, 1, true, 1.23, abc]
// liyunfei
// 1
// true
// 1.23
// abc
// [liyunfei, 1, true, 1.23, abc, a]
List和Set接口
- Collection接口存储一组不唯一,无序的对象。
- List接口存储一组不唯一,有序(插入顺序)的对象。
- Set接口存储一组唯一,无序的对象。
- Map接口存储一组键值对象,提供key到value的映射。
List接口
List接口的实现类
- List特点:有序,不唯一(可重复)
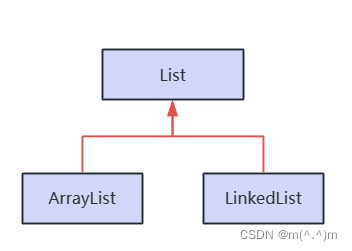
- ArrayList实现了长度可变的数组,在内存中分配连续的空间。
优点:遍历元素和随机访问元素的效率比较高。
缺点:添加和删除元素需要大量移动元素效率低,按照内容查询效率低。
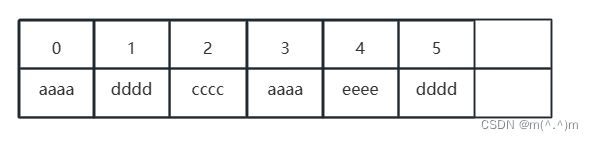
- LinkedList采用链表存储方式。
优点:插入、删除元素时效率比较高。
缺点:遍历和随机访问元素效率低下。

- Vector跟ArrayList一样,底层都是使用数组进行实现的。
优点:线程是安全的。
缺点:效率低。
List接口特有的方法
凡是可以操作索引的方法都是该体系特有的方法。
| 序号 | 方法名 | 作用 |
|---|---|---|
| 增 | add(index,element) | 在指定索引的位置插入上元素 |
| 增 | addAll(index,Collection) | 在指定的索引位置上插入整个集合的元素 |
| 增 | addAll(Collection) | 在结束插入整个集合的元素 |
| 删 | remove(index) | 根据索引删除指定的元素 |
| 改 | set(index,element) | 使用element替换指定索引位置上的元素 |
| 查 | get(index) subList(from,to) listlterator() | 获取元素 |
Dog类:
import java.util.Objects;
public class Dog {
private String name;
private String color;
public Dog(){
}
public Dog(String name, String color){
this.name = name;
this.color = color;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Dog dog = (Dog) o;
return Objects.equals(name, dog.name) && Objects.equals(color, dog.color);
}
@Override
public int hashCode() {
return Objects.hash(name, color);
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", color='" + color + '\'' +
'}';
}
}
ArrayList示例代码:
import java.awt.*;
import java.util.ArrayList;
import java.util.List;
public class ListTest {
public static void main(String[] args) {
List list = new ArrayList();
Dog d1 = new Dog("大黄","red");
Dog d2 = new Dog("二黄","blue");
Dog d3 = new Dog("小黄","green");
list.add(d1);
list.add(d2);
list.add(d3);
System.out.println(list);
System.out.println(list.size());
list.remove(d1);
System.out.println(list);
Dog d4 = new Dog("二黄","blue");
System.out.println(list.contains(d4));// 如果集合中有该元素则返回true,反之则返回false
}
}
// 输出的结果是:
// [Dog{name='大黄',color='red'},Dog{name='二黄',color='blue'},Dog{name='小黄',color='green'}]
// 3
// [Dog{name='二黄', color='blue'}, Dog{name='小黄',color='green'}]
// true
Vector示例代码:
import java.util.Vector;
public class VectorDemo {
public static void main(String[] args) {
Vector vector = new Vector();
vector.add(1);
vector.add("abc");
System.out.println(vector);
}
}
// 输出的结果是:
// [1, abc]
LinkedList特有的方法
| 序号 | 方法名 | 作用 |
|---|---|---|
| 增 | addFirst(Object obj) | 添加头 |
| 增 | addLast(Object obj) | 添加尾 |
| 增 | offerFirst(Object obj) | 1.6版本之后的添加头 |
| 增 | offerLast(Object obj) | 1.6版本之后的添加尾 |
| 删 | removeFirst() | 删除头,获取元素并删除元素 |
| 删 | removeLast() | 删除尾,获取元素并删除元素 |
| 删 | pollFirst() | 1.6版本之后的删除头,获取元素并删除元素 |
| 删 | pollLast() | 1.6版本之后的删除头,获取元素并删除元素 |
| 查 | getFirst() | 获取头,获取元素但不删除 |
| 查 | getLast() | 获取头,获取元素但不删除 |
| 查 | peekFirst() | 1.6版本之后的获取头,获取元素但不删除 |
| 查 | peekLast() | 1.6版本之后的获取头,获取元素但不删除 |
示例代码:
import java.util.LinkedList;
public class LinkedlistDemo {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add(123);
linkedList.add(false);
linkedList.add("abc");
System.out.println(linkedList);
linkedList.add(2,"liyunfei");
System.out.println(linkedList);
linkedList.addFirst("1111");
System.out.println(linkedList);
linkedList.addLast("2222");
System.out.println(linkedList);
System.out.println(linkedList.element());
linkedList.offer("3333");
System.out.println(linkedList);
System.out.println(linkedList.peek());
System.out.println(linkedList.poll());
}
}
// 输出的结果是:
// [123, false, abc]
// [123, false, liyunfei, abc]
// [1111, 123, false, liyunfei, abc]
// [1111, 123, false, liyunfei, abc, 2222]
// 1111
// [1111, 123, false, liyunfei, abc,2222,3333]
// 1111
// 1111
小结
- ArrayList
1、遍历元素和随机访问元素的效率比较高。
2、插入、删除等操作频繁时性能低下。 - LinkedList
1、插入、删除元素时效率较高。
2、查找效率较低。 - Vector
1、ArrayList是线程不安全的,效率高;Vector是线程安全的,效率低。
2、ArrayList在进行扩容的时候,是扩容1.5倍,Vector扩容的时候扩容原来的两倍
Iterator接口
- 实现了Collection接口的容器类都有一个iterator方法用以返回一个实现了Iterator接口的对象。
- Iterator对象称作迭代器,用以方便的实现对容器内元素的遍历操作。
Iterator接口的方法
Iterator接口定义了如下方法:
boolean hasNext(); // 判断是否有元素,没有被遍历
Object next(); // 返回游标当前位置的元素并将游标移动到下一个位置
void remove(); // 删除游标左面的元素,在执行完next之后该操作只能执行一次
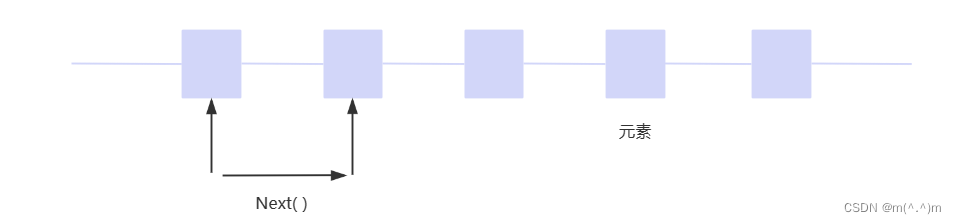
- 所有的集合类均未提供相应的遍历方法,而是把遍历交给迭代器完成。迭代器为集合而生,专门实现集合遍历。
- Iterator是迭代器设计模式的具体实现。
增强For循环(For-each)
所有的集合类都默认实现了Iterable的接口,实现此接口意味着具备了增强for循环的能力,也就是for-each。
For-each循环:
1、增强的for循环,遍历array或Collection的时候相当简便。
2、无需获得集合和数组的长度,无需使用索引访问元素,无需循环条件。
3、遍历集合时底层调用Iterator完成操作。
For-each缺陷:
1、数组
- 不能方便的访问下标值。
- 不要再for-each中尝试对变量赋值,只是一个临时变量。
2、集合
- 与使用Iterator相比,不能方便的删除集合中的内容。
For-each总结:
除了简单的遍历并读出其中的内容外,不建议使用增强for。
普通For循环遍历集合:
public class Test {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
for (int i = 0;i < list.size();i++){
System.out.println(list.get(i));
}
}
}
// 输出的结果是:
// 1
// 2
// 3
// 4
增强For循环遍历集合:
public class Test {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
for(Object i : list){
System.out.println(i);
}
}
}
// 输出的结果是:
// 1
// 2
// 3
// 4
ListIterator
在使用iterator进行迭代的过程中如果删除其中的某个元素会报错,并发操作异常,因此如果遍历的同时需要修改元素,建议使用listIterator()。
public class Test {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
//迭代器
Iterator iterator = list.iterator();
while(iterator.hasNext()){
Object o = iterator.next();
if (o.equals(1)){
list.add(2);
}
System.out.println(o);
}
}
}
// 输出的结果是:
// 1
// Exception in thread "main" java.util.ConcurrentModificationException
// at java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1013)
// at java.base/java.util.ArrayList$Itr.next(ArrayList.java:967)
// at com.liyunfei.Test.main(Test.java:48)
ListIterator的作用:解决并发操作异常。
在迭代时,不可能通过集合对象的方法(list.add(?))操作集合中的元素,会发生并发修改异常。所以,在迭代时只能通过迭代器的方法操作元素,但是Iterator的方法是有限的,只能进行判断(hasNext),取出(next),删除(remove)的操作,如果想要在迭代的过程中进行向集合中添加,修改元素等就需要使用ListIterator接口中的方法。
public class Test {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
ListIterator iterator = list.listIterator();
while(iterator.hasNext()){
Object o = iterator.next();
if (o.equals(1)){
iterator.remove();
}
System.out.println(o);
}
System.out.println("------------------");
for(Object i : list){
System.out.println(i);
}
}
}
// 输出的结果是:
// 1
// 2
// 3
// 4
// ------------------
// 2
// 3
// 4
ListIterator迭代器提供了向前和向后两种遍历的方式。始终是通过cursor和lastret的指针来获取元素值及向下的遍历索引,当使用向前遍历的时候必须要保证指针在迭代器的结尾,否则无法获取结果值。
public class Test {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
ListIterator iterator = list.listIterator();
while(iterator.hasNext()){
Object o = iterator.next();
if (o.equals(1)){
iterator.remove();
}
System.out.println(o);
}
System.out.println("------------------");
while (iterator.hasPrevious()){
System.out.println(iterator.previous());
}
}
}
// 输出的结果是:
// 1
// 2
// 3
// 4
// ------------------
// 4
// 3
// 2
Set接口
- set中存放的是无序,唯一的数据。(存入和取出的顺序不一定一致)
- set不可以通过下标获取对应位置的元素值,因为无序的特点。
- 使用treeset底层的实现是treemap,利用红黑树来进行实现。
- 设置元素的时候,如果是自定义对象,会查找对象中的equals和hashcode的方法,如果没有,比较的是地址。
- 树中的元素是要默认进行排序操作的,如果是基本数据类型,自动比较,如果是引用类型的话,需要自定义比较器。
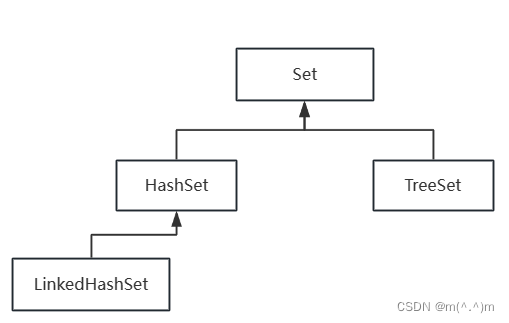
Set接口中的实现类
- HashSet:采用Hashtable哈希表存储结构
优点:添加速度快,查询速度快,删除速度快。
缺点:无序。 -
- LinkedHashSet:采用哈希表存储结构,同时使用链表维护次序;有序。
- LinkedHashSet:采用哈希表存储结构,同时使用链表维护次序;有序。
- TreeSet:采用二叉树(红黑树)的存储结构
优点:有序(排序后的升序)查询速度比List快。
缺点:查询速度没有HashSet快。
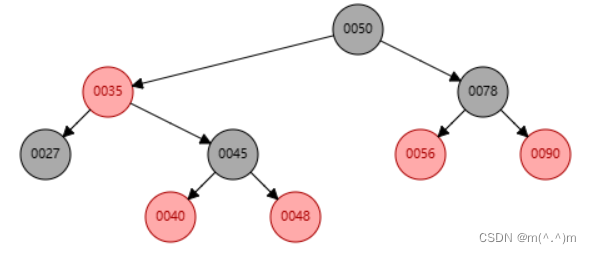
HashSet
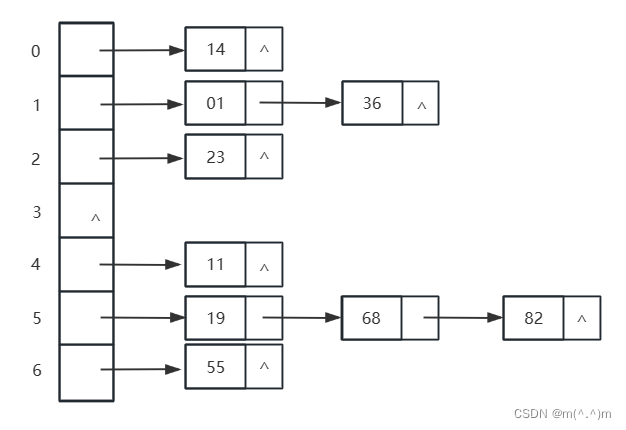
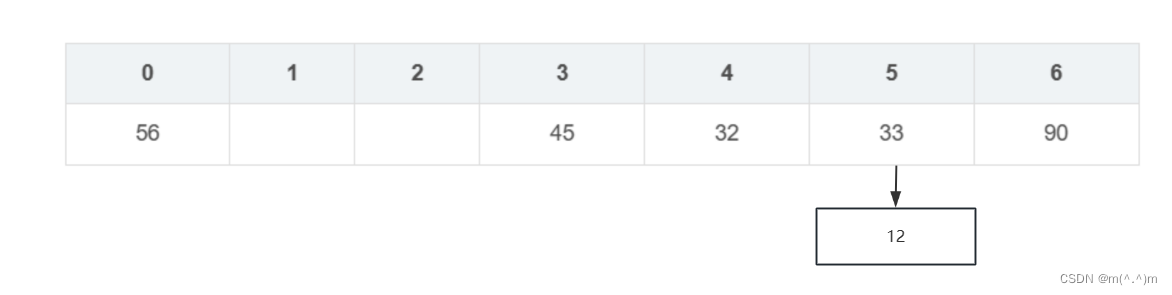
Hash表原理
| num | 45 | 33 | 12 | 45 | 32 | 56 | 90 |
|---|
| num | 45 | 33 | 12 | 45 | 32 | 56 | 90 |
|---|---|---|---|---|---|---|---|
| hashCode | 45 | 33 | 12 | 45 | 32 | 56 | 90 |
| Y=k(x)=x%7 | 3 | 5 | 5 | 3 | 4 | 0 | 6 |
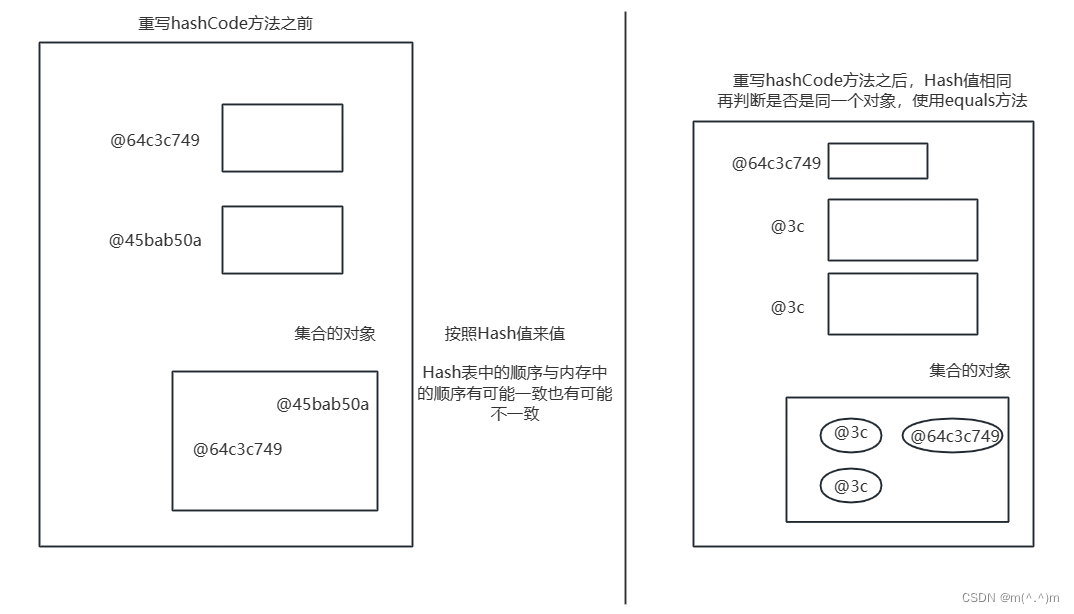
- 代码验证HashSet的无序性与唯一性。
- 使用HashSet存储自定义对象,重写hashCode方法与equals方法。
关键代码:
HashSet hashSet = new HashSet();
hashSet.add(new Person("zhangsan",12));
hashSet.add(new Person("lisi",12));
hashSet.add(new Person("zhangsan",12));
System.out.println(hashSet);
// [Person{name='lisi', age=12}, Person{name='zhangsan', age=12}, Person{name='zhangsan', age=12}]
HashSet存储进了相同的对象,不符合实际情况。
解决方案: 重写equals方法和hashCode方法。
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
总结:
HashSet是如何保证元素的唯一性的呢?
答:是通过元素的两个方法,hashCode和equals方法来完成的。如果元素的HashCode值相同,才会判断equals是否为true;如果元素的hashCode值不同,才会调用equals方法。
Comparable接口
问题:上面的算法什么确定集合中对象的“大小”顺序?
答:所有可以“排序”的类都实现了java.lang.Comparable接口,Comparable接口只有一个方法:public int compareTo(Object obj);
返回 0 表示 this == obj
返回正数 表示 this > obj
返回负数 表示 this < obj
实现了Comparable接口的类通过实现compareTo方法从而确定该类对象的排序方式。
示例代码:
/*
* 此比较器按照name的长度来进行比较
* */
@Override
public int compareTo(Object o) {
Person p = (Person)o;
if (p.name.length() > this.name.length()){
return -1;
}else if(p.name.length() < this.name.length()){
return 1;
}else {
return 0;
}
}
TreeSet treeSet = new TreeSet();
treeSet.add(new Person("wangwu",15));
treeSet.add(new Person("maliu",13));
treeSet.add(new Person("zhangsan",17));
treeSet.add(new Person("lisi",19));
System.out.println(treeSet);
// [Person{name='lisi', age=19}, Person{name='maliu', age=13}, Person{name='wangwu', age=15}, Person{name='zhangsan', age=17}]
sort排序
需要实现Comparator接口中的compare方法。
示例代码:
// 按年龄大小排序
@Override
public int compare(Person o1, Person o2) {
if(o1.getAge() > o2.getAge()){
return -1;
}else if(o1.getAge() < o2.getAge()){
return 1;
}else {
return 0;
}
}
TreeSet treeSet = new TreeSet(new Test());
treeSet.add(new Person("wangwu",15));
treeSet.add(new Person("maliu",13));
treeSet.add(new Person("zhangsan",17));
treeSet.add(new Person("lisi",19));
treeSet.add(new Person("zhangsan",12));
System.out.println(treeSet);
// [Person{name='lisi', age=19}, Person{name='zhangsan', age=17}, Person{name='wangwu', age=15}, Person{name='maliu', age=13}, Person{name='zhangsan', age=12}]
三、泛型
概念: 当做一些集合的统一操作的时候,需要保证集合的类型是统一的,此时需要泛型来进行限制。
优点:
1、数据安全。
2、获取数据时效率比较高。
作用:给集合中的元素设置相同的类型就是泛型的基本需求。
使用:在定义对象的时候,通过<>中设置的类型来进行实现。
泛型的高阶应用
泛型类
在定义类的时候在类名的后面添加<E,K,V,A,B>,起到占位的作用,类中的方法的返回值类型和属性的类型都可以使用。
泛型类示例代码:
public class FanXingClass<A> {
private int id;
private A a;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public A getA() {
return a;
}
public void setA(A a) {
this.a = a;
}
public void show(){
System.out.println("id: " + id + "A: " + a);
}
public A get(){
return a;
}
public void set(A a){
System.out.println("执行set方法" + a);
}
}
测试类:
public class Test {
public static void main(String[] args) {
FanXingClass<String> fxc = new FanXingClass<String>();
fxc.setA("liyunfei");
fxc.setId(1);
fxc.show();
FanXingClass<Integer> fxc2 = new FanXingClass<Integer>();
fxc2.setA(22);
fxc2.setId(2);
fxc2.show();
FanXingClass<Person> fxc3 = new FanXingClass<Person>();
fxc3.setA(new Person("lyf",123));
fxc3.setId(3);
fxc3.show();
System.out.println(fxc3.get());
fxc3.set(new Person("hehe",123));
}
}
// 输出的结果是:
// id: 1A: liyunfei
// id: 2A: 22
// id: 3A: Person{name='lyf', age=123}
// Person{name='lyf', age=123}
// 执行set方法Person{name='hehe', age=123}
泛型接口
在定义接口的时候,在接口的名称后添加<E,K,V,A,B>。
注意:
1、子类在进行实现的时候,可以不填写泛型的类型,此时在创建具体的子类对象的时候才决定使用什么类型。
2、 子类在实现泛型接口的时候,只在实现父类接口的时候指定父类的泛型类型即可,此时,测试方法中的泛型类型必须要跟子类保持一致。
泛型接口示例代码:
public interface FanXingInterface<B> {
public B test();
public void test2(B b);
}
子类实现的示例代码:
public class FanXingInterfaceSub implements FanXingInterface<String>{
@Override
public String test() {
return null;
}
@Override
public void test2(String o) {
System.out.println(o);
}
}
测试类:
public class Test {
public static void main(String[] args) {
FanXingInterfaceSub fxi = new FanXingInterfaceSub();
fxi.test2("123");
}
}
// 输出的结果是:
// 123
泛型方法
在定义方法的时候,指定方法的返回值和参数是自定义的占位符,可以是类名中的T,也可以是自定义的Q,只不过在使用Q的时候需要使用定义在返回值的前面。
public class FanXingMethod<T> {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
public <Q> void show(Q q){
System.out.println(q);
System.out.println(t);
}
}
测试类:
public class Test {
public static void main(String[] args) {
FanXingMethod<String> fxm = new FanXingMethod<>();
fxm.setT("ttt");
fxm.show(123);
fxm.show(true);
}
}
// 输出的结果是:
// 123
// ttt
// true
// ttt
泛型的拓展使用(工作中不用)
- 泛型的上限
如果父类确定了,所有子类都可以直接使用。 - 泛型的下限
如果子类确定了,子类的所有父类都可以直接传递参数使用。
四、Map接口
Map接口的实现类
Map接口的特点是key-value映射。
- HashMap
Key无序唯一(Set);Value无序不唯一(Collection)。 - LinkedHashMap
有序的HashMap,速度快。 - TreeMap
有序,速度没有hash快。
问题:Set与Map有关系吗?
答:采用了相同的数据结构,只用于map和key存储结构,以上是Set。
Map接口的方法
| 序号 | 方法 | 作用 |
|---|---|---|
| 添加 | put(key,value) | 添加元素 |
| 删除 | clear() | 清除所有 |
| 删除 | remove(key) | 根据key去移除 |
| 判断 | containsKey(key) | 是否包含指定的key |
| 判断 | containsValue(valus) | 是否包含指定的值 |
| 判断 | isEmpty() | 判断集合中元素是否为空 |
| 遍历 | get(key) | 返回与指定 key 相关联的 value |
| 遍历 | size() | 返回map的大小 |
| 遍历 | values() | 返回一个包含 Map 中所有值的 Collection |
| 遍历 | entrySet() | 返回一个包含 Map 中所有键值对的 Set 集合,每个键值对都表示为一个 Map.Entry 对象 |
| 遍历 | keySet() | 返回一个包含 Map 中所有键的 Set 集合,可以通过这个集合来遍历所有键,并执行其他操作 |
实例代码:
import java.util.*;
public class Test {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<String,Integer>(13);
map.put("a",1);
map.put("b",2);
map.put("c",3);
map.put("d",4);
System.out.println(map);// {a=1, b=2, c=3, d=4}
System.out.println(map.isEmpty());// false
System.out.println(map.size());// 4
System.out.println(map.containsKey("a"));// true
System.out.println(map.containsValue(2));// true
System.out.println(map.get("a"));// 1
map.remove("a");
System.out.println(map);// {b=2, c=3, d=4}
map.clear();
System.out.println(map);// {}
}
}
public class Test {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<String,Integer>(13);
map.put("a",1);
map.put("b",2);
map.put("c",3);
map.put("d",4);
//遍历操作
Set<String> keys = map.keySet();
for (String key:keys){
System.out.println(key + "=" + map.get(key));
}
// a=1
// b=2
// c=3
// d=4
//只能获取对应的value值,不能根据value来获取key
Collection<Integer> values = map.values();
for (Integer i:values){
System.out.println(i);
}
// 1
// 2
// 3
// 4
//迭代器
Set<String> keys2 = map.keySet();
Iterator<String> iterator = keys2.iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println(key + "=" + map.get(key));
}
// a=1
// b=2
// c=3
// d=4
//Map.entry
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Iterator<Map.Entry<String, Integer>> iterator1 = entries.iterator();
while (iterator1.hasNext()){
Map.Entry<String, Integer> next = iterator1.next();
System.out.println(next.getKey() + "--" + next.getValue());
}
// a--1
// b--2
// c--3
// d--4
}
}
hashmap跟hashtable的区别:
1、hashmap线程不安全,效率比较高,hashtable线程安全,效率低。
2、hashmap中key和value都可以为空,hashtable不允许为空。
hashmap初始值为2的N次幂:
1、方便进行&操作,提高效率,&要比取模运算效率要高:hash & (initCapacity-1)。
2、在扩容之后涉及到元素的迁移过程,迁移的时候只需要判断二进制的前一位是0还是1即可;如果是0,表示新数组和旧数组的下标位置不变,如果是1,只需要将索引位置加上旧的数组的长度值即为新数组的下标。
五、Collections工具类
Collections和Collection不同,前者是集合的操作类,后者是集合接口。
Collections提供的静态方法:
addAll():批量添加
sort():排序
binarySearch():二分查找
shuffle():随机排序
reverse():逆序
fill():替换成一个元素
示例代码:
import java.util.*;
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("af");
list.add("bg");
list.add("acssf");
list.add("bdsdfasd");
// 批量添加
Collections.addAll(list,"cefsaf","cfsfaf","cgasdf");
System.out.println(list);
// [af, bg, acssf, bdsdfasd, cefsaf, cfsfaf, cgasdf]
// 按照字母序顺序排序
Collections.sort(list);
System.out.println(list);
// [acssf, af, bdsdfasd, bg, cefsaf, cfsfaf, cgasdf]
// 按照字符串长度进行升序排序
Collections.sort(list,new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
if(o1.length() > o2.length()){
return 1;
}else if (o1.length() < o2.length()){
return -1;
}else {
return 0;
}
}
});
System.out.println(list);
// [af, bg, acssf, cefsaf, cfsfaf, cgasdf, bdsdfasd]
//二分查找的时候需要先进行排序操作,如果没有排序的话,是找不到指定元素的
Collections.sort(list);
System.out.println(Collections.binarySearch(list,"acssf"));
// 0
// 按照字母序逆序排序
Collections.reverse(list);
System.out.println(list);
// [cgasdf, cfsfaf, cefsaf, bg, bdsdfasd, af, acssf]
// 随机排序
Collections.shuffle(list);
System.out.println(list);
// [af, cfsfaf, bdsdfasd, cgasdf, cefsaf, acssf, bg]
// 将集合中所有元素替换成一个元素
Collections.fill(list,"liyunfei");
System.out.println(list);
// [liyunfei, liyunfei, liyunfei, liyunfei, liyunfei, liyunfei, liyunfei]
}
}
六、集合总结
| 名称 | 存储结构 | 顺序 | 唯一性 | 查询效率 | 添加/删除效率 |
|---|---|---|---|---|---|
| ArrayList | 顺序表 | 有序(添加) | 不唯一 | 索引查询效率高 | 低 |
| LinkedList | 链表 | 有序(添加) | 不唯一 | 低 | 最高 |
| HashSet | 哈希表 | 无序 | 唯一 | 最高 | 最高 |
| HashMap | 哈希表 | Key无序 | Key唯一 | 最高 | 最高 |
| LinkedHashSet | 哈希表 | 有序(添加) | 唯一 | 最高 | 最高 |
| LinkedHashMap | 哈希表 | Key有序(添加) | Key唯一 | 最高 | 最高 |
| TreeSet | 二叉树 | 有序(升序) | 唯一 | 中等 | 中等 |
| TreeMap | 二叉树 | 有序(升序) | Key唯一 | 中等 | 中等 |
| 特性 | Collection | Map |
|---|---|---|
| 无序不唯一 | Conllection | Map.values() |
| 有序不唯一 | ArrayList — LinkedList | |
| 无序唯一 | HashSet | HashMap keySet |
| 有序唯一 | LinkedHashSet — TreeSet | LinkedHashMap keySet — TreeMap keySet |
七、面试题
集合与数组的比较
数组不是面向对象的,存在明显的缺陷,集合弥补了数组的一些缺点,比数组更灵活更实用,可以大大提高软件的开发效率,而且不同的集合框架类可适用不同场合。具体如下:
- 数组能存放基本数据类型和对象,而集合类中只能存放对象。
- 数组容易固定无法动态改变,集合类容易动态改变。
- 数组无法判断其中实际存放多少元素,length只告诉了数组的容量,而集合的size()可以确切知道元素的个数。
- 集合有多种实现方式和不同适用场合,不像数组仅采用顺序表方式。
- 集合以类的形式存在,具有封装、继承、多态等类的特性,通过简单的方法和属性即可实现各种复杂操作,大大提高了软件的开发效率。
Collection和Collections的区别
- Collection是Java提供的集合接口,存储一组不唯一,无序对象。它有两个子接口List和Set。
- Java还有一个Collections类,专门用来操作集合类,它提供了一系列的静态方法实现对各种集合的搜索、排序、线程安全化等操作。
ArrayList和LinkedList的联系和区别
- ArrayList实现了长度可变的数组,在内存中分配连续空间。遍历元素和随机访问元素效率比较高。
- LinkedList采用链表存储方式。插入、删除元素效率比较高。
Vector和ArrayList的联系和区别
联系: 实现原理相同,功能相同,都是长度可变的数组结构,很多时候可以互用。
区别:
1、 Vector是早期的JDK接口,ArrayList是替代Vector的新接口。
2、Vector线程安全,ArrayList重速度轻安全,线程非安全。
3、长度需要增加时,Vector默认增加一倍,ArrayList增长50%。
HashMap和Hashtable的联系和区别
联系: 实现原理相同,功能相同,底层都是哈希表结构,查询速度快,在很多情况下可以互用。
区别:
1、Hashtable是早期的JDK提供的接口,HashMap是新版JDK提供的接口。
2、Hashtable继承Dictionary类,HashMap实现Map接口。
3、Hashtable是线程安全,HashMap线程非安全。
4、Hashtable不允许null值,HashMap允许null值。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









