





基于强化学习的方面级情感分类
2021 IEEE International Conference on Data Mining
- 基于强化学习的方面级情感分类
- 摘要
- 1.导言
- 2.相关工作
- 2.1基于方面的情感分类
- 2.2图的情感分析句法依存树
- 2.3 NLP中的强化学习
- 3.我们的方法
- 3.1准备工作
- 3.2依赖图抽取
- 3.3基于强化学习的路径搜索
- 3.4语义理解模块
- 3.5策略网络
- 3.6情感分类器
- 3.7奖励
- 3.8实现与优化
- 4.实验
- 4.1数据集
- 4.2基线
- 4.3结果分析
- 5.结论
- 参考文献
基于强化学习的方面级情感分类
摘要
方面级情感分类旨在预测文本中一个或多个方面的情感极性。由于文本中总是包含大量与任务无关的单词,因此如何将所描述的方面与其情感描述精确对齐是最关键、最具挑战性的一步。目前最先进的方法是基于从循环神经网络变体(例如, LSTM)或图神经网络中学习到的单词级注意力。从另一个角度来看,这些方法本质上是对所有可能的对齐进行加权和聚合。然而,这种机制严重依赖于大规模的监督训练,如果没有足够的标签,它很容易过度拟合并且难以泛化。为了应对这一挑战,我们提出了一个基于强化学习的方面情感分类框架SentRL。在该框架中,输入文本被转换为依赖图,然后部署一个代理在图上行走,探索从目标方面节点到其潜在情感区域的路径,并区分不同路径的有效性。我们的方法通过限制智能体的探索步数,鼓励智能体跳过与任务无关的信息,专注于最有效的路径进行对齐。我们的方法大大降低了任务无关词的影响,提高了泛化性能。与竞争性基线方法相比,我们的方法在公共基准数据集上取得了最高提升了3.7%的性能。
关键字: 自然语言处理、情感分类、强化学习
1.导言
方面级情感分类的目标是预测单个方面的情感极性。如图1所示,给定一个句子:I like this computer but do not like the screen,这个句子对“电脑”的情感是积极,对“屏幕”的情感是消极。与传统的情感分类任务相比,方面级场景是一个更细粒度和更具挑战性的任务,其中的核心问题是正确地将方面与它们的情感描述对齐。最先进的方法依赖于监督信号来自动学习这种对齐。通过利用文献[1][2] 提出的深度模型学习到的文本上下文和单词级别的注意力,现有方法在特定方面的情感分析中取得了很大的进展。
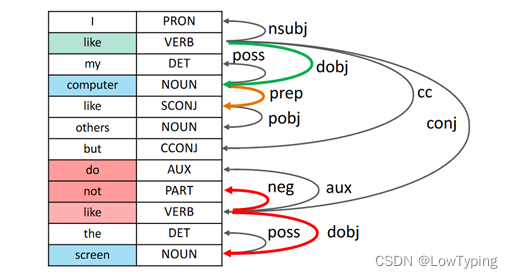
图1 给定句子的依赖图(蓝色词语表示方面,即computer和screen;绿色和红色分别表示正面和负面情绪。依赖图有效地减少了方面和情感描述之间的距离且有效避免了多义词(例如:like)。在我们的方法中,部署一个代理从方面词走到情感区域,避免了与任务无关的信息,获得了更有效和高效的性能)
同时,从机器学习的角度来看,由于自然语言中不可避免地包含了大量与任务无关的文本或者噪声,现有的方法会出现严重的过拟合问题。理想情况下,如果有足够数量的训练标签,现有的方法可以有效遏制这种与任务无关的信息的负面影响。在实践中,由于语言表达的高差异性,收集大量特定任务的标签成本很高,而且很难保证满足预期足够的标签。在标签有限的情况下,现有的方法很容易将与任务无关的信息纳入决策过程,过度拟合训练数据,并最终导致数据的泛化性能较差。
为了有效地抑制任务无关信息的影响,我们提出了基于强化学习的方面级情感分类框架SentRL。在我们的方法中,输入文本首先被转换为图对象(例如,依赖图),其中节点是单词,边表示它们之间的句法依赖关系。接下来,我们部署了一个基于策略的智能体来发现图中与方面相关的情感描述,该智能体带有语言理解模块,使其能够更新探索状态并针对个体方面进行情感决策。不同于现有方法从所有可能的文本上下文或单词中聚合潜在的情感信息,我们的智能体力求在有限的步数预算下利用最相关的探索路径。这种策略不仅要求智能体关注最有效的路径,而且还鼓励智能体跳过与任务无关的区域。在公开的基准数据集中,我们的方法与最先进的方法相比可以实现高达3.6%的提升。我们工作的主要贡献列举如下:
- 提出了一种基于强化学习的方面级情感分类框架。它准确地指出了情感描述和目标方面之间最有效的路径,有效地避免了任务无关区域的影响。
- 开发了一个政策网络为智能体提供探索指导。该网络迭代地提供关于下一跳选择的建议。特别地,该框架具有置换不变性,保证了模型的一致性和可靠性。
- 开发了一个语言理解模块,帮助智能体“记住”其探索的历史,并进行最终情感预测。
据我们所知,这是第一个探索强化学习在情感依赖图中的有效性并取得最新性能的工作。我们的方法是一种更人性化的探索知识和排除无关信息的机制。
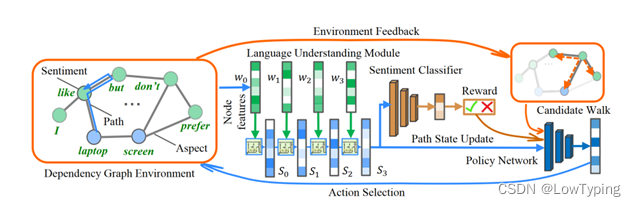
图2 Sentrl方法的框架(首先得到一个依赖图。与原始句子空间相比,依赖图中的相关情感线索可能更加接近。智能体从一个方面节点出发并穿过图的边,行走方向由策略网络决定,该策略网络利用当前的行走状态和候选方向进行决策。使用语义理解模块更新路径状态,并设计情感分类器基于游走状态进行最终的情感预测)
2.相关工作
2.1基于方面的情感分类
基于方面的情感分类是识别给定文本中一个或多个方面的情感极性[4]。方面可以是实体对象(例如,计算机),也可以是观念对象(例如,服务),通常有积极、中性和消极三种情绪类别。传统方法[5]将输入文本视为词序列,并部署单独的特征提取模块和分类模块。基于深度学习的方法[6]通过使用LSTM来考虑词序的上下文信息。文献[7]提出了一个深度记忆网络,显式地捕捉每个上下文单词的重要性。[8]提出了注意力交叉注意力模块来改进传统的注意力策略。[9]引入了另一个注意力交叉注意力模块,该模块对方面和句子进行显式联合建模。文献[10]提出了一种新的模型,使用CNN层从转换后的单词表示中提取显著特征。文献[11]提出的方法需要大量具有非平凡方差训练标签 (例如,不相关语境词占多数的长句)。
2.2图的情感分析句法依存树
文献[3]提出一种广泛使用的数据结构,它编码输入文本中单词之间的句法依存关系。基于方面的情感分类问题可以转化为节点分类问题。图结构数据被广泛用于各种学习应用[12],[13]。例如,文献[2]利用图神经网络来聚合情感信息;为了进一步提高性能,文献[14]提出了基于Transformer的方法。[15] 探索句子的语法方面并使用自注意力机制进行句法学习。[16]提出了一种简洁有效的基于多个CRF的结构化注意力模型。然而,这些模型通常在直推式的设置下执行,也就是说应该给出完整的句子或段落。
2.3 NLP中的强化学习
强化学习( Reinforcement Learning,RL ) [17] 是一种自动、主动探索环境并实现最终任务优化策略的方法[18][22]。RL已经在基于文本[18]和问答系统[19]等NLP相关任务中得到探索。[23]Deep Path旨在寻找推理路径,动作空间是知识图谱中的关系空间。文献[24]提出了一种新颖的Hierarchical RL方法,模拟分析文档中方面情感的步骤。文献[25] 提出了一个可视化推理框架,该框架由一个程序生成器组成,构建了推理过程的显式表示。与以前的工作不同,我们是第一个研究从句法依赖图中智能地收集信息并用于方面级情感分析的RL方法。这是一个更具挑战性的任务,因为智能体在大量的动作空间中只提供有限的监督信息。
3.我们的方法
3.1准备工作
给定目标文本c,其中 表示c中的第i个单词,n为单词总数。记c的目标方面为ac,其中r+1表示方面的起始位置,m为方面的长度。方面可以是单词格式(例如,计算机、服务和屏幕),也可以是多词格式(例如HDMI端口和运动模式)。c中可以有一个或多个方面,不同方面可以有不同或相反的情感类别。方面级情感分类的目标是找到每个方面对应的情感极性(即积极、中性和消极)。
3.2依赖图抽取
依赖图是一种被广泛采用的数据结构,它编码输入文本中单词之间的句法依赖关系。给定一个描述c,从c中提取一个依赖图 =(V,E)。V表示所有顶点/节点,每个顶点对应c中的一个单词。E表示边, 中的每条边表示句法关系类别。通过部署依赖图,我们将序列文本数据转换为图结构格式。文本中的长距离词对在图中可以很接近。这提供了额外的句法知识,使得下游算法更容易定位情感词,我们通过现有的图解析算法来获取依赖图。
3.3基于强化学习的路径搜索
与GCN和注意力等其他图学习算法相比,我们提出了一个RL框架来探索依赖图上最有效的方面级情感路径。首先,智能体从目标方面节点开始行走。然后,部署一个策略网络根据先前的游走历史和所有可行的游走候选路径选择最有效路径。接着,部署语义理解模块对路径状态进行聚合,并使用情感分类器得到最终的情感预测。综上所述,我们的框架包含3个部分:一是语义理解模块,聚合游走状态;二是策略网络,进行游走决策;三是情感分类器,得到最终的情感类别预测。
3.4语义理解模块
语义理解模块有两个作用,一是让策略网络做出有效的游走动作,二是让情感分类器获得最终的预测。状态更新机制要求行走过程为马尔可夫决策过程( MDP )。表达式如下:
式中:Si、Ai、Ri分别为第i个动作的状态、动作和奖励。公式1表明(t+1)步的路径状态St+1应该只与当前状态St和动作At有关,与之前的状态无关。为此,需要St同时保留当前和所有之前的游走信息。为了实现这一目标,我们在框架中部署了通用的LSTM结构,因为LSTM及其变化模型在给定样本中捕获特征和序列知识十分有效,模型中函数如下所示:
式中St为当前状态,是每个循环中更新的隐藏状态。At是对应的第t步的节点特征,即词嵌入,表示智能体行走的第t步,语义理解模块为每次行走不断更新St。
3.5策略网络
策略网络的目标是指导智能体在得到的依赖图中找到最有效的路径。具体来说,它被设计为基于前一个行走路径和下一个移动候选来选择动作。有两个挑战,首先政策网络应该感知所有可能的候选路径,以便做出最有效的行动。一般的深度网络结构需要一致的数据格式作为输入,而在 中,每个节点可以有不同数量的邻居节点,即1跳的距离。其次,政策网络应该是与候选输入无关的排列。
为此,我们提出了一种结构输入机制。当智能体到达一个节点时,它获得所有的连通节点(包括先前行走的节点和自身)。假设节点集合为V={v1,v2,…,vm},其中m为第i个节点周围所有候选节点的个数。将当前状态St与每个节点vi(i={1,2,…,m})级联得到一个向量。我们将向量放入策略网络中,得到节点vi的候选得分si。
式中:cat函数表示级联操作。该策略分别考虑每个候选的概率,在保留依赖图局部结构信息的同时缓解了输入不一致的问题。当获得所有候选节点的分数后,智能体将前往分数最高的节点。
在我们的实验中,设置一致的行走长度以停止行走过程,将步行长度设定为3用于实现高性能(具体细节将在第四节中讨论)。与其他潜在的解决方案如设置一个停止动作来终止行走过程相比,我们目前的策略是最有效且复杂度较低的。
3.6情感分类器
在智能体完成一条路径搜索后,部署情感分类器得到最终的情感预测。
上述公式为单层网络,其中δ 函数为非线性激活。在我们的方法中,我们部署Softmax激活函数从候选池中预测情感极性。Wp为权重,bp为偏置。
3.7奖励
奖励提供了直接指导训练过程的信息。传统的RL框架对每一步都有明确的奖励设计。然而在我们的框架中,最终目标是依赖多个模块的高分类性能。为此,我们直接将正确的预测作为优化所有模块的奖励。我们使用均方误差( Mean Squared Error,MSE )作为精度奖励(均方误差可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度)
其中racc是精度奖励,y是真值标签,racc只在行走结束后计算一次。这是一个简单而有效的奖励。在训练过程中,同时优化这3个模块以获得最佳性能。其他评价指标如交叉熵等也可以部署,我们实证评估了不同的指标发现大多数指标是有效的,而MSE是性能最好。
3.8实现与优化
我们使用2层全连接神经网络来参数化策略网络,该网络将状态向量St映射到所有可能动作的概率分布。ReLU激活部署在第一层,而第二层没有激活。然而,为了在不同的候选对象之间获得一个平滑的分数,sigmoid函数被部署到所有动作中。在优化过程中,采用了一些策略来提高其效率和效果。对于政策网络而言,简单地选择得分最高的候选者是一种不可微的采样策略,使得无法计算权重梯度。文献[26]提出的Gumbel Softmax使用连续分布来近似不可微样本,这样,我们可以有一个one-hot向量作为智能体的输出,同时仍然保留参数梯度。Gumbel Softmax的核心功能如下。
式中gi为从Gumbel(0,1)分布中抽取的独立同分布样本, 为类别概率,zi为生成样本,τ为温度参数。τ越小,最终结果越接近one-hot向量。输出将是一个one-hot向量,而梯度是由Gumbel Softmax计算的。在实验过程中,由于不需要计算梯度和增加多样性,我们使用argmax函数来得到one-hot向量。
4.实验
4.1数据集
我们使用了5个公开数据集。表1是它们的统计信息。具体而言,LAP14 [27]包括用户对笔记本电脑的评论,主要是计算机的特点,如屏幕、速度等方面。TWITTER[1]是公共可用推文,包括名人、企业等。REST14[27]关注餐厅评论,包括风味、风格、服务、环境等方面,在句子中出现的方面术语的注释。REST15 [28]与上述REST14有相似的方面,同时包含了对笔记本电脑、餐厅和酒店的评论。REST16[29]包含关于餐厅的更全面的评论,用于帮助企业衡量满意度和改进产品。
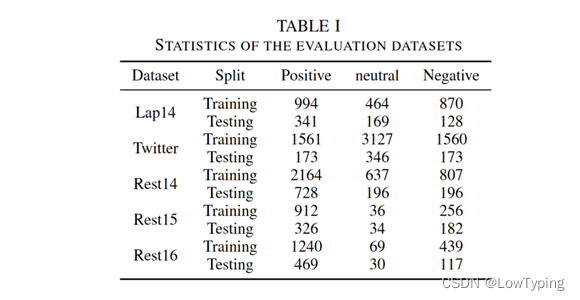
表1 评价数据集的统计
4.2基线
我们考虑以下最先进的方法作为基线。SVM[5]是一种常规的分类方法,使用传统的特征提取管道和内部序列标注器来检测方面术语。LSTM [6]提出了对一般LSTM框架的扩展,它融合了目标信息以充分挖掘相关语境词。MemNet[7]使用外部记忆和多跳架构来学习上下文单词的重要性,其中输入文本被建模为自然排序的单词序列。AOA[9]将注意力交叉注意力( AOA )策略引入到情感分类中。它同时考虑了文本到方面和方面到文本的预测。IAN[8]将注意力网络同时应用于方面和上下文来学习情感表示。TNet-LF[10]引入了目标特定转换组件来获取方面文本的上下文信息,然后提出上下文保持变换层来学习抽象特征。ASGCN[2]通过利用依赖图来考虑上下文信息,并使用GCN和注意力机制来学习情感表征。
在实验中,我们遵循文献[7]中描述的普遍采用的实验设置。使用GloVe词嵌入[30]提取初始表征,并通过双向LSTM[2]进一步微调。使用ADAM优化器训练SentRL,学习率为0.0005。我们采用与文献[2]相同的评价指标,即准确性(ACC)和宏观F1,依赖关系图从spcCy获得。
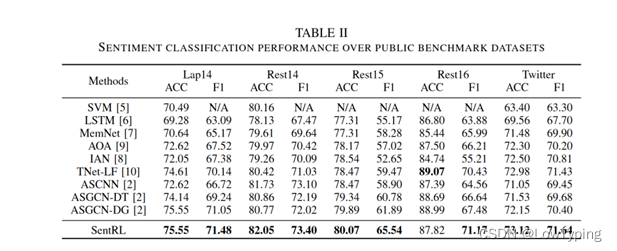
表2 公共基准数据集上的情感分类性能
4.3结果分析
结果表现总体见表2,我们观察到SentRL在5个案例中,有4个案例的准确率( ACC )优于所有基线方法。在宏观F1方面,SentRL在所有情况下都优于最佳基线方法,最高提升3.7 %。
我们将学到的情感表征可视化,并与表现次之的模型ASGCN[2]通过t-SNE[31]生成的情感表征进行比较。如图3所示,红色、绿色和蓝色的点分别表示负面、中性和正面的情绪。
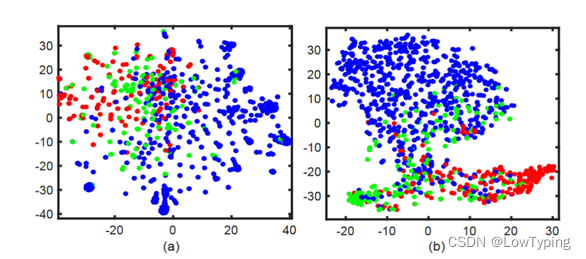
图3 对学习到的情感表示进行T - SNE可视化(其中( a )是ASGCN方法,( b )是我们的方法。不同的颜色代表不同的情绪类别,包括积极、中性和消极)
我们观察到,我们的方法可以更好地分离不同的情绪。步行长度是另一个关键参数。我们用不同的行走长度(即从2到5)来评估该模型,结果如图4所示。我们假设如果游走长度小于3,智能体无法到达情感词,性能显著下降。如果步行长度超过3,性能只有轻微的下降,我们猜测这是由于不必要的步行聚集了额外的信息。
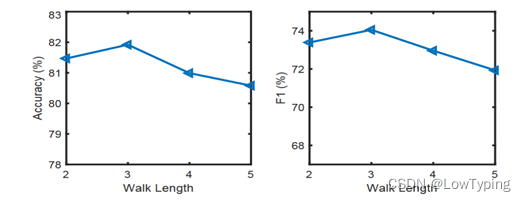
图4 依赖图中不同游走长度的表现
为了证明RL模块的有效性,我们让智能体在保持其他模块不变的情况下随机游走依赖图。结果见表3,我们观察到当行走长度为1时,性能显著下降,但仍高于随机猜测。当行走长度增加时,性能不能持续增加。从结果中我们可以得出结论:一是我们的RL方法是有效和必要的,二是方面节点对于不同的情感极性确实存在偏向性,而遍历依存图可以更有效地捕获句法知识。
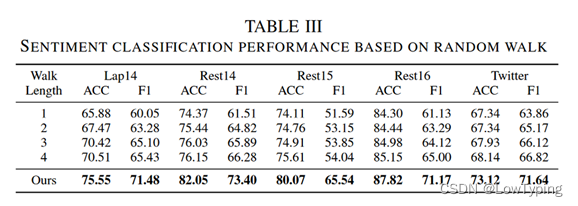
表3 基于随机游走的情感分类性能
我们提出了一个案例研究,并可视化从方面词到其相关情感词的轨迹。三个正确预测和一个错误预测如图5所示,其中蓝色框中的单词是方面,灰色边表示单词之间的句法依赖关系,红色边是智能体学习留下的痕迹。例如,在情形1中,按照预期在三跳内收集必要的信息,智能体从方面词food开始,以单词Fresh结束。如果策略网络认为这是最后一个词而且不需要额外的动作,那么智能体就一直走到同一个词直到行走停止。案例3和案例4说明了智能体的这种操作,在案例3中,当智能体到达great并认识到不需要额外的行走,那么它就一直走到同一个单词。在案例4中,智能体在最后一次行走中又走到了单词 terrible。
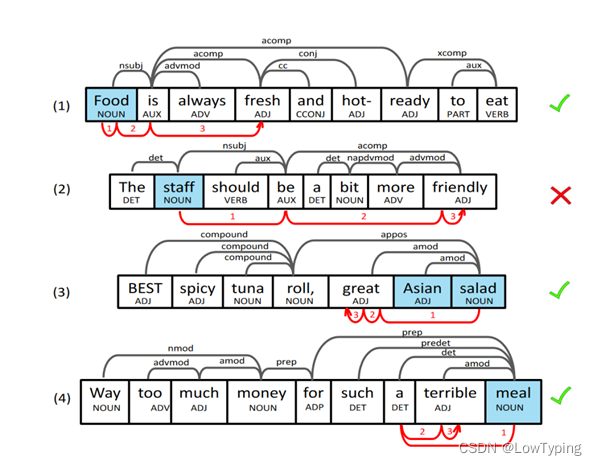
图5 一个案例研究展示了从方面词到其相关情感词的轨迹(例如,在情形1中,代理迹为Food→Food→is→Fresh,灰色边表示提取的句法依存关系,红色边表示学习到的代理生成的轨迹。情形1、3、4为SentRL正确预测的样本,情形2为错误预测)
5.结论
本文提出了一种基于强化学习的方面情感分类方法SentRL。通过研究输入文本的句法结构依赖图,能够有效减少自然语言中不同表达式引入的输入差异。在句法结构之上,部署一个智能体来发现将方面与其情感描述联系起来的最有效路径,SentRL中的语义理解模块通过学习收集路径中的知识,从而实现准确的情感分类,SentRL中的所有模块以端到端的方式同时训练。实验结果表明了该方法的高效性,广泛的案例研究证明了该模型的有效性和高效性。
参考文献
[1]: L. Dong, F. Wei, C. Tan, D. Tang, M. Zhou, and K. Xu, “Adaptive recursive neural network for target-dependent twitter sentiment classification,” in ACL, 2014, pp. 49–54.
[2]: C. Zhang, Q. Li, and D. Song, “Aspect-based sentiment classification with aspect-specific graph convolutional networks,” in EMNLP, 2019, pp. 4567–4577.
[3]: M. A. Covington, “A fundamental algorithm for dependency parsing,” in ACM Southeast Conference, 2001, pp. 95–102.
[4]: T. T. Thet, J.-C. Na, and C. S. Khoo, “Aspect-based sentiment analysis of movie reviews on discussion boards,” Journal of Information Science, vol. 36, no. 6, pp. 823–848, 2010.
[5]: S. Kiritchenko, X. Zhu, C. Cherry, and S. Mohammad, “NRC-Canada2014: Detecting aspects and sentiment in customer reviews,” in ACL, 2014, pp. 437–442.
[6]: D. Tang, B. Qin, X. Feng, and T. Liu, “Effective LSTMs for targetdependent sentiment classification,” in International Conference on Computational Linguistics, 2016, pp. 3298–3307.
[7]: D. Tang, B. Qin, and T. Liu, “Aspect level sentiment classification with deep memory network,” in EMNLP, 2016, pp. 214–224.
[8]: D. Ma, S. Li, X. Zhang, and H. Wang, “Interactive attention networks for aspect-level sentiment classification,” in IJCAI, 2017.
[9]: B. Huang, Y. Ou, and K. M. Carley, “Aspect level sentiment classification with attention-over-attention neural networks,” in International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation. Springer, 2018, pp. 197–206.
[10]: X. Li, L. Bing, W. Lam, and B. Shi, “Transformation networks for target-oriented sentiment classification,” in ACL, 2018.
[11]: G. Mittal, C. Liu, N. Karianakis, V. Fragoso, M. Chen, and Y. Fu, “HyperSTAR: Task-aware hyperparameters for deep networks,” in CVPR, 2020, pp. 8736–8745.
[12]: L. Wang, B. Zong, Q. Ma, W. Cheng, J. Ni, W. Yu, Y. Liu, D. Song, H. Chen, and Y. Fu, “Inductive and unsupervised representation learning on graph structured objects,” in ICLR, 2020.
[13]: Q. Ma and A. Olshevsky, “Adversarial crowdsourcing through robust rank-one matrix completion,” in NeurIPS, 2020.
[14]: H. Tang, D. Ji, C. Li, and Q. Zhou, “Dependency graph enhanced dualtransformer structure for aspect-based sentiment classification,” in ACL, 2020, pp. 6578–6588.
[15]: M. H. Phan and P. O. Ogunbona, “Modelling context and syntactical features for aspect-based sentiment analysis,” in ACL, 2020, pp. 32113220.
[16]: L. Xu, L. Bing, W. Lu, and F. Huang, “Aspect sentiment classification with aspect-specific opinion spans,” in EMNLP. Online: Association for Computational Linguistics, Nov. 2020, pp. 3561–3567.
[17]: R. S. Sutton, D. A. McAllester, S. P. Singh, and Y. Mansour, “Policy gradient methods for reinforcement learning with function approximation,” in NeurIPS, 2000, pp. 1057–1063.
[18]: K. Narasimhan, T. Kulkarni, and R. Barzilay, “Language understanding for text-based games using deep reinforcement learning,” in EMNLP, 2015, pp. 1–11.
[19]: W. Y. Wang, J. Li, and X. He, “Deep reinforcement learning for NLP,” in ACL, 2018, pp. 19–21.
[20]: Q. Ma, Y.-Y. Liu, and A. Olshevsky, “Optimal lockdown for pandemic control,” arXiv:2010.12923, 2020.
[21]: L. Wang, Y. Liu, C. Qin, G. Sun, and Y. Fu, “Dual relation semisupervised multi-label learning,” in AAAI, 2020.
[22]: L. Wang, Z. Ding, S. Han, J.-J. Han, C. Choi, and Y. Fu, “Generative correlation discovery network for multi-label learning,” in IEEE ICDM, 2019, pp. 588–597.
[23]: W. Xiong, T. Hoang, and W. Y. Wang, “DeepPath: A reinforcement learning method for knowledge graph reasoning,” in EMNLP, 2017, pp. 564–573.
[24]: J. Wang, C. Sun, S. Li, J. Wang, L. Si, M. Zhang, X. Liu, and G. Zhou, “Human-like decision making: Document-level aspect sentiment classification via hierarchical reinforcement learning,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2019.
[25]: J. Johnson, B. Hariharan, L. Van Der Maaten, J. Hoffman, L. Fei-Fei, C. Lawrence Zitnick, and R. Girshick, “Inferring and executing programs for visual reasoning,” in ICCV, 2017, pp. 2989–2998.
[26]: E. Jang, S. Gu, and B. Poole, “Categorical reparametrization with Gumble-Softmax,” in ICLR, 2017.
[27]: M. Pontiki, D. Galanis, J. Pavlopoulos, H. Papageorgiou, I. Androutsopoulos, and S. Manandhar, “SemEval-2014 task 4: Aspect based sentiment analysis,” in ACL Workshop on Semantic Evaluation, 2014, pp. 27–35.
[28]: M. Pontiki, D. Galanis, H. Papageorgiou, S. Manandhar, and I. Androutsopoulos, “Semeval-2015 task 12: Aspect based sentiment analysis,” in ACL Workshop on Semantic Evaluation, 2015, pp. 486–495.
[29]: M. Pontiki, D. Galanis, H. Papageorgiou, I. Androutsopoulos, S. Manandhar, M. Al-Smadi, M. Al-Ayyoub, Y. Zhao, B. Qin, O. De Clercq et al., “Semeval-2016 task 5: Aspect based sentiment analysis,” in ACL Workshop on Semantic Evaluation, 2016.
[30]: J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in EMNLP, 2014, pp. 1532–1543.
[31]: L. v. d. Maaten and G. Hinton, “Visualizing data using t-SNE,” Journal of Machine Learning Research, pp. 2579–2605, 2008.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









