







一、分类过程
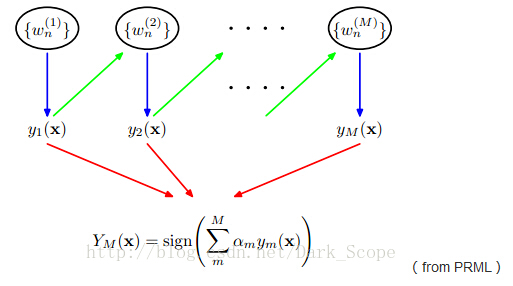
这就是Adaboost的结构,最后的分类器YM是由数个弱分类器(weak classifier)组合而成的,相当于最后m个弱分类器来投票决定分类,而且每个弱分类器的“话语权”α不一样。
这里阐述下算法的具体过程:

二、分类原理
可以看到整个过程就是和最上面那张图一样,前一个分类器改变权重w,同时组成最后的分类器
如果一个训练样例 在前一个分类其中被误分,那么它的权重会被加重,相应地,被正确分类的样例的权重会降低
使得下一个分类器 会更在意被误分的样例,那么其中那些α和w的更新是怎么来的呢?
下面我们从前项分步算法模型的角度来看看Adaboost:

三、C代码实现
adaboost.h
#ifndef _ADABOOST_H_
#define _ADABOOST_H_
#define MAX_FEATURE 100
#define MAX_SAMPLES 500
//#define DEBUG
struct Sample
{
double weight;
double feature[MAX_FEATURE];
int indicate;
};
struct SampleHeader
{
int samplesNum;
int featureNum;
//double feature[MAX_SAMPLES][MAX_FEATURE];
struct Sample samples[MAX_SAMPLES];
};
struct Stump
{
int left;
int right;
double alpha;
int fIdx;
double ft;
};
struct Classifier
{
struct Stump stump;
struct Classifier* next;
};
struct ClassifierHeader
{
int classifierNum;
struct Classifier* classifier;
};
struct IdxHeader
{
int samplesNum;
int featureNum;
double feature[MAX_FEATURE][MAX_SAMPLES];
};
#endifadaboost.c
#include "stdio.h"
#include "assert.h"
#include "string.h"
#include "stdlib.h"
#include "math.h"
#include "adaboost.h"
//#define DEBUG
#define DATA_NAME ".//ionospheredata.txt"
SampleHeader sampleHeader;
IdxHeader idx;
int k = 0;
//==================================================================
//函数名: sort
//作者: qiurenbo
//日期: 2014-11-25
//功能: 冒泡排序
//输入参数:double a[]
// n 数组长度
//返回值: 无
//修改记录:
//==================================================================
//将弱分类器对每个样本的输出值进行排序
void sort(double a[], int n)
{
double tmp;
for (int i = 0; i < n - 1; i++)
{
for (int j = 0; j < n - i - 1; j++)
{
if (a[j] > a[j + 1])
{
tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
}
}
//==================================================================
//函数名: countFeature
//作者: qiurenbo
//日期: 2014-11-25
//功能: 计算一行上有多少特征
//输入参数:char* buf 文本的一行
//返回值: 特征个数
//修改记录:
//==================================================================
//计算特征数目
int countFeature(const char* buf)
{
const char* p = buf;
int cnt = 0;
while (*p != NULL)
{
if (*p == ',')
cnt++;
p++;
}
return cnt;
}
//==================================================================
//函数名: setFeature
//作者: qiurenbo
//日期: 2014-11-25
//功能: 将读取的特征分配到正负样本结构体上
//输入参数:char* buf 文本的一行
//返回值: 无
//修改记录:
//==================================================================
//将从文件中读取的特征分配到idx.feature和sampleHeader.samples
//sampleHeader.samples保存原始特征数据,idx.feature用于对特征进行排序
//g和b分别表示正样本和负样本
void setFeature(char* buf)
{
int i = 0;
struct Sample sample;
char*p = strtok(buf, ",");
sample.feature[i++] = atof(p);
k++;
while (1)
{
if (*p != 'g' && *p != 'b')
sample.feature[i++] = atof(p);
else
break;
p = strtok(NULL, ",");
}
if (*p == 'g')
sample.indicate = 1;
else if (*p == 'b')
sample.indicate = -1;
else
assert(0);
//idx 每行是所有样本的同一特征
for (i = 0; i < sampleHeader.featureNum; i++)
idx.feature[i][idx.samplesNum] = sample.feature[i];
sampleHeader.samples[sampleHeader.samplesNum] = sample;
sampleHeader.samplesNum++;
idx.samplesNum++;
};
//==================================================================
//函数名: loadData
//作者: qiurenbo
//日期: 2014-11-25
//功能: 读取文本数据
//输入参数:char* buf 文本的一行
//返回值: 无
//修改记录:
//==================================================================
//按行读取特征文件,并用setFeature函数处理特征,再对每个特征下所有样本值进行排序
void loadData()
{
FILE *fp = NULL;
char buf[1000];
int featureCnt = 0;
double* featrue = NULL;
double* featruePtr = NULL;
int i = 0;
fp = fopen(DATA_NAME, "r");
assert(fp);
//fgets从文件结构体指针fp中读取一行,保存到buf指向的字符数组中,每次最多读取1000个字符。
//如果文件中的该行,不足bufsize个字符,则读完该行就结束。
//如若该行(包括最后一个换行符)的字符数超过bufsize-1,则fgets只返回一个不完整的行,但是,缓冲区总是以NULL字符结尾,对fgets的下一次调用会继续读该行。
//函数成功将返回buf,失败或读到文件结尾返回NULL。因此我们不能直接通过fgets的返回值来判断函数是否是出错而终止的,应该借助feof函数或者ferror函数来判断。
fgets(buf, 1000, fp);
idx.featureNum = sampleHeader.featureNum = countFeature(buf);
setFeature(buf);
//统计样本数
while (!feof(fp)) //feof(fp)有两个返回值:如果遇到文件结束,函数feof(fp)的值为非零值,否则为0。
{
fgets(buf, 1000, fp);
setFeature(buf);
}
fclose(fp);
for (i = 0; i < idx.featureNum; i++)
sort(idx.feature[i], idx.samplesNum);
}
//==================================================================
//函数名: CreateStump
//作者: qiurenbo
//日期: 2014-11-26
//功能: 创建一个stump分类器
//输入参数:无
//返回值: stump
//修改记录:
//==================================================================
//遍历所有样本的所有特征,以当前样本的特征作为阈值计算error,选取具有最小error的特征作为弱分类器
//stump:fIdx--feature index
//stump: ft--feature value
//stumo: alpha--1/2log(1/error-1)
//stump: left,right = [-1 1] -- left=1,right=-1表示小于阈值的是正样本,left=-1,right=1表示大于阈值的是正样本
//error:计算分类错误样本的权重的和,认为小于阈值的是正样本,大于阈值的是负样本
//flipErr:计算分类错误样本的权重的和,认为小于阈值的是负样本,大于阈值的是正样本
Stump CreateStump()
{
int i, j, k;
Stump stump;
double min = 0xffffffff;
double err = 0;
double flipErr = 0;
double feature;
int indicate;
double weight;
double pre;
for (i = 0; i < idx.featureNum; i++)
{
pre = 0xffffffff;
for (j = 0; j < idx.samplesNum; j++)
{
err = 0;
double rootFeature = idx.feature[i][j];
//跳过相同的值
if (pre == rootFeature)
continue;
for (k = 0; k < sampleHeader.samplesNum; k++)
{
feature = sampleHeader.samples[k].feature[i];
indicate = sampleHeader.samples[k].indicate;
weight = sampleHeader.samples[k].weight;
if ((feature < rootFeature && indicate != 1) || \
(feature >= rootFeature && indicate != -1)
)
err += weight;
}
//左边是1,还是右边是1,选取error最小的组合
flipErr = 1 - err;
err = err < flipErr ? err : flipErr;
//选取具有最小err的特征rootFeature
if (err < min)
{
min = err;
stump.fIdx = i;
stump.ft = rootFeature;
if (err < flipErr)
{
stump.left = 1;
stump.right = -1;
}
else
{
stump.left = -1;
stump.right = 1;
}
}
pre = rootFeature;
}
}
stump.alpha = 0.5*log(1.0 / min - 1);
return stump;
}
//==================================================================
//函数名: reSetWeight
//作者: qiurenbo
//日期: 2014-11-26
//功能: 每次迭代重新调整权重
//输入参数:stump
//返回值: 无
//修改记录:
//==================================================================
//rs表示样本按照阈值分类结果
//
void reSetWeight(struct Stump stump)
{
int i;
double z = 0;
//计算规范化因子z
for (i = 0; i < sampleHeader.samplesNum; i++)
{
double feature = (sampleHeader.samples[i]).feature[stump.fIdx];
double rs = feature < stump.ft ? stump.left : stump.right;
rs = stump.alpha * rs * sampleHeader.samples[i].indicate;
z += sampleHeader.samples[i].weight * exp(-1.0 * rs);
}
//调整各个样本的权值
for (i = 0; i < sampleHeader.samplesNum; i++)
{
double feature = (sampleHeader.samples[i]).feature[stump.fIdx];
double rs = feature < stump.ft ? stump.left : stump.right;
rs = stump.alpha * rs * sampleHeader.samples[i].indicate;
sampleHeader.samples[i].weight = sampleHeader.samples[i].weight * exp(-1.0 * rs) / z;
}
#ifdef DEBUG
//debug
for (i = 0; i < 10; i++)
{
double feature = (sampleHeader.samples[i]).feature[stump.fIdx];
double rs = feature < stump.ft ? stump.left : stump.right;
rs = stump.alpha * rs * sampleHeader.samples[i].indicate;
printf("weight:%lf, rs:%lf\n", sampleHeader.samples[i].weight, rs);
}
//getchar();
#endif
}
//==================================================================
//函数名: AdaBoost
//作者: qiurenbo
//日期: 2014-11-26
//功能: adaboost训练弱分类器
//输入参数:interation 迭代次数
//返回值: 无
//修改记录:
//==================================================================
void AdaBoost(int interation)
{
int i;
struct ClassifierHeader head;
struct Classifier* pCls = NULL;
struct Classifier* tmp = NULL;
head.classifierNum = interation;
loadData();
//设置初始样本权重
for (i = 0; i < sampleHeader.samplesNum; i++)
sampleHeader.samples[i].weight = 1.0 / sampleHeader.samplesNum;
head.classifier = (struct Classifier*)malloc(sizeof(struct Classifier));
pCls = head.classifier;
pCls->stump = CreateStump();
reSetWeight(pCls->stump);
//printf("completed:%lf%%\r", 1.0/head.classifierNum*100);
printf("+-----------+--+-------+\n");
printf("| alpha |id| ft |\n");
printf("+-----------+--+-------+\n");
printf("|%.9lf|%2d|%+.4lf|\n", pCls->stump.alpha, pCls->stump.fIdx, pCls->stump.ft);
printf("+-----------+--+-------+\n");
for (i = 1; i < head.classifierNum; i++)
{
pCls = pCls->next = (struct Classifier*)malloc(sizeof(struct Classifier));
pCls->stump = CreateStump();
reSetWeight(pCls->stump);
printf("|%.9lf|%2d|%+.4lf|\n", pCls->stump.alpha, pCls->stump.fIdx, pCls->stump.ft);
printf("+-----------+--+-------+\n");
//printf("completed:%lf%%\r", 1.0*(i+1)/head.classifierNum*100);
}
printf("\n");
for (i = 0, pCls = head.classifier; i < head.classifierNum; i++)
{
tmp = pCls;
pCls = tmp->next;
free(tmp);
}
}
void main()
{
AdaBoost(100);
system("pause");
}














 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









