







一、hive的框架
hadoop是一个海量分布式存储和计算的框架,hdfs负责存储,yarn调度,MapReduce计算。
相对于MapReduce编程的不足,产生了hive的框架:
1)MapReduce繁琐:要写mapper,reducer,driver,package
2)海量数据存放在hdfs,如何快速对hdfs上的文件进行统计分析操作。
①学java,学mapr
②DBA:sql
③HDFS是一个纯文本的文件系统,没有schema,就无法使用sql进行查询。
如何为HDFS上的文件添加schema信息?是否就可以使用SQL?
以上就是hive产生的背景。
Hive:使用一种类似于SQL的查询语言,直接作用在分布式存储系统的文件之上。
由facebook开源,解决海量结构化的日志数据统计问题。
构建在hadoop之上的数据仓库
Hive的数据是存放在HDFS
Hive的计算是通过yarn和mr
引擎: Hive QL ==>MapReduce
Hive底层:支持MapReduce【生产用】、Spark(Hive onSpark)【生产不用】、Tez(Hive on Tez)【生产不用】
压缩/存储格式:
***为什么选择Hive***
1、简单易上手,
2、扩展简单
3、调整需求不用修改代码,可以基于多存储方式hdfs,本地。。。。
4、统一的元数据管理
hive的架构:
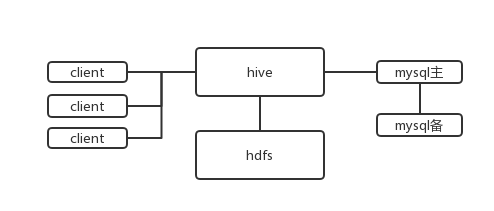
Hive 和 RDBMS 的关系:
没有任何关系,只是sql有点像
hive对于延迟没有要求
insert,update 有功能,但是用的少。
节点可以很多
设备要求低
数据体量不同
hive环境部署参考这边博客
http://blog.csdn.net/ggwxk1990/article/details/77973395
注:hive控制台默认看不到日志信息
可以通过hive下conf下配置hive-log4j.properties.template,默认是/tmp/用户
二、hive的DDL
hivesqoop等都是客户端式的
hive 是类似于一个sql到MapReduce的翻译器。
HiveQLDDL statements are documented here, including:
CREATE DATABASE/SCHEMA, TABLE, VIEW,FUNCTION, INDEX
DROP DATABASE/SCHEMA, TABLE, VIEW,INDEX
TRUNCATE TABLE
ALTER DATABASE/SCHEMA, TABLE, VIEW
MSCKREPAIR TABLE (or ALTER TABLE RECOVER PARTITIONS)
SHOWDATABASES/SCHEMAS, TABLES, TBLPROPERTIES, VIEWS, PARTITIONS, FUNCTIONS,INDEX[ES], COLUMNS, CREATE TABLE
DESCRIBEDATABASE/SCHEMA, table_name, view_name
PARTITIONstatements are usually options of TABLE statements, except for SHOW PARTITIONS.
表默认放在/user/hivewarehouse
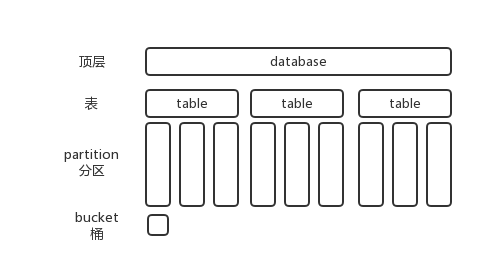
不管哪层,在hdfs上都有相对应的目录存在。
默认的default数据库在hdfs上没有显示,例如emp表,warehouse 就是default的库。
创建数据库:
CREATE(DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES(property_name=property_value, ...)];
hive>create database IF NOT EXISTS hive;
[hadoop-single@hadoop001~]$ hadoop fs -ls /user/hive/warehouse
drwxr-xr-x - hadoop-single supergroup 0 2017-09-05 05:06/user/hive/warehouse/hive.db
先创建文件夹
[hadoop-single@hadoop001~]$ hadoop fs -mkdir -p /wxk /directory
再创建库
hive>create database IF NOT EXISTS hive2 LOCATION "/wxk/directory";
注意:默认不用location的话,会默认创建一个文件名为 .db 的文件夹,但是如果自己指定的话,那个文件夹就是我们的库文件夹。
hive>create database IF NOT EXISTS hive3 comment 'it is my database' withdbproperties('creator'='wxk','date'='2018-01-01')";
查询相关:
show databases;#查询
showdatabases like 'hive*'; #模糊查询
descdatabase hive2; #结构查询
hive2 hdfs://hadoop001:9000/wxk/directory hadoop-single USER
hive>desc database extended hive3; #更详细查询
hive3 it is my database hdfs://hadoop001:9000/user/hive/warehouse/hive3.db hadoop-single USER {date=2018-01-01, creator=wxk}
这时,元数据中能看到database
注意mysql中的几个表,dbs ,database_params。
dbs 能提现hive中建的库信息,存放位置等等。
dbproperties在database_params中体现。
修改数据库:
AlterDatabase
ALTER(DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value,...); -- (Note: SCHEMA added in Hive0.14.0)
ALTER(DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; -- (Note: Hive 0.13.0 and later; SCHEMAadded in Hive 0.14.0)
ALTER(DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; -- (Note: Hive 2.2.1,2.4.0 and later)
hive>alter database hive3 set dbproperties ("edited-by"="ppp");
删数据库:
DROP(DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
hive>drop database if exists hive3;
hive>drop database if exists hive2;
FAILED: Execution Error, return code 1from org.apache.hadoop.hive.ql.exec.DDLTask.
InvalidOperationException(message:Databasehive2 is not empty. One or more tables exist.)
hive>drop database if exists hive2 cascade ;
如果某hive库下有表,需要加cascade,级联删除。
Hive基本数据类型和分隔符:
数据类型
stringint bigint float double boolean date timestamp
分隔符
\n, \t,^A=\001[默认]
【注意】一般情况下,在创建表的时候直接指定分隔符:\t 或者 ,
hive>create table emp (empno int,ename string) row formatdelimited fields terminated by '\t';
hive>create table emp2 as select * from emp; #可以从指定的sql中建表,带数据
hive>create table emp2 like emp; #只创建表结构
hive>show tables 'emp*'; #模糊查询
hive>desc emp; #查看表结构
hive>desc formatted emp; #可以查详细信息
改表名:
hive>alter table emp2 rename to emp2_bak;
#此时,hdfs上的文件也跟着改名了。
删除表操作
droptable emp3; #内部表的话hdfs上数据也删除了
截断表
hive>truncate table emp2_bak;
内部表和外部表
managed (内部表)和external (外部表)
默认情况下创建的表都是managed表。
hive 里面有两类数据:data 和 metadata
元数据存在metadata
内部表:hive.metastore.warehouse.dir=/user/hive/warehous
如果drop table -->date + metadata 都会被drop
外部表: 通过create table +location
如果drop table -->data not drop + metadata drop
内部表
hive>create table emp_managed as select * from emp; # 在hdfs上会创建文件
hive>drop table emp_managed; #mysql和hdfs上均删除
外部表
create externaltable emp_external(
empnoint,ename string,job string,mgr int,hiredate string,sal double,commdouble,deptno int
) rowformat delimited fields terminated by '\t'
location'/hive_external/emp'; #会在hdfs上创建文件夹,但是没有表文件,相当于这个表就是这个文件夹仓库。
[root@hadoop002data]# hadoop fs -put emp.txt /hive_external/emp/ #上传后表中会有数据
[root@hadoop002data]# hadoop fs -put emp2.txt /hive_external/emp/#上传后表中会追加数据
[root@hadoop002data]# hadoop fs -put dept.txt /hive_external/emp/ #上传不同格式的文件,会继续追加,不足的地方为null,多的地方会被截断,不会多出列。
hive>drop table emp_external; #删除外部表,mysql元数据删除,但是hdfs数据还在
注意:一般来说,在建表的时候加上external 表示建立外部表,但是如果没有这个关键字,有可能在tblproperties里面有external属性为true,这样这个表也是外部表。
外部表在什么地方使用呢?
(1)元数据和数据分离,更安全
(2)不同团队间实现业务上数据上传
(3)多业务表共享一份数据
(4)类似 S3 方式的使用
查看建表语句:
hive>show create table emp;
修改列
AlterTable/Partition/Column
ALTERTABLE table_name RENAME TO new_table_name;
ALTERTABLE table_name SET TBLPROPERTIES table_properties;
ALTERTABLE table_name SET TBLPROPERTIES ('comment' = new_comment);
详细的hive DDL 语句用法见官网
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









