







 HBase是一种运行在Hadoop上的NoSQL数据库,具备分布式和可扩展特性,支持实时查询和离线批处理。谷歌的BigTable、GFS和MapReduce技术启发了HBase的开发,使其成为Apache顶级项目。文章详细介绍了HBase的数据模型,包括行键、列簇、列修饰符和版本的概念,并阐述了如何设计行键以支持高效的数据获取和分布式存储。
HBase是一种运行在Hadoop上的NoSQL数据库,具备分布式和可扩展特性,支持实时查询和离线批处理。谷歌的BigTable、GFS和MapReduce技术启发了HBase的开发,使其成为Apache顶级项目。文章详细介绍了HBase的数据模型,包括行键、列簇、列修饰符和版本的概念,并阐述了如何设计行键以支持高效的数据获取和分布式存储。
Hbase是运行在Hadoop上的NoSQL数据库,它是一个分布式的和可扩展的大数据仓库,也就是说HBase能够利用HDFS的分布式处理模式,并从Hadoop的MapReduce程序模型中获益。这意味着在一组商业硬件上存储许多具有数十亿行和上百万列的大表。除去Hadoop的优势,HBase本身就是十分强大的数据库,它能够融合key/value存储模式带来实时查询的能力,以及通过MapReduce进行离线处理或者批处理的能力。总的来说,Hbase能够让你在大量的数据中查询记录,也可以从中获得综合分析报告。
谷歌曾经面对过一个挑战的问题:如何能在整个互联网上提供实时的搜索结果?答案是它本质上需要将互联网缓存,并重新定义在这样庞大的缓存上快速查找的新方法。为了达到这个目的,定义如下技术:
- 谷歌文件系统GFS:可扩展分布式文件系统,用于大型的、分布式的、数据密集型的应用程序。
- BigTable:分布式存储系统,用于管理被设计成规模很大的结构化数据:来自数以千计商用服务器的PB级别的数据。
- MapReduce:一个程序模型,用于处理和生成大数据集的相关实现。
在谷歌发布这些技术的文档之后, 不久以后我们就看到了它们的开源实现版本 ,就在2007年,Mike Cafarella发布了BigTable开源实现的代码,他称其为HBase,自此,HBase成为Apache的顶级项目,并运行在Facebook,Twitter,Adobe……仅举几个例子。
HBase不是一个关系型数据库,它需要不同的方法定义你的数据模型,HBase实际上定义了一个四维数据模型,下面就是每一维度的定义:
- 行键:每行都有唯一的行键,行键没有数据类型,它内部被认为是一个字节数组。
- 列簇:数据在行中被组织成列簇,每行有相同的列簇,但是在行之间,相同的列簇不需要有相同的列修饰符。在引擎中,HBase将列簇存储在它自己的数据文件中,所以,它们需要事先被定义,此外,改变列簇并不容易。
- 列修饰符:列簇定义真实的列,被称之为列修饰符,你可以认为列修饰符就是列本身。
- 版本:每列都可以有一个可配置的版本数量,你可以通过列修饰符的制定版本获取数据
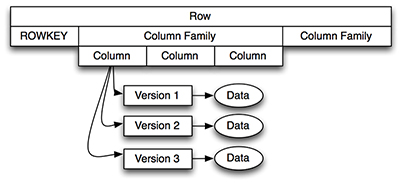
如图1中所示,通过行键获取一个指定的行,它由一个或多个列簇构成,每个列簇有一个或多个列修饰符(图1中称为列),每列又可以有一个或多个版本。为了获取指定数据,你需要知道它的行键、列簇、列修饰符以及版本。当设计HBase数据模型时,对考虑数据是如何被获取是十分有帮助的。你可以通过以下两种方式获得HBase数据:
- 通过他们的行键,或者一系列行键的表扫描。
- 使用map-reduce进行批操作
这种双重获取数据的方法使得HBase变得十分强大,典型地,在Hadoop中存储数据意味着它对离线或批处理方式分析是有益的(尤其是批处理分析),但是,对实时获取是不必要的。HBase通过key/value存储来支持实时分析,以及通过map-reduce支持批处理分析。让我们首先来看实时数据获取,作为key/value存储,key是行键,value是列簇的集合,如图2所示。
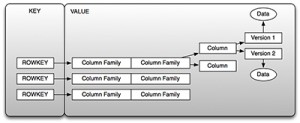
如你在图2中看到的,key是我们所提到过的行键,value是列簇的集合。你可以通过key检索到value,或者换句话说,你可以通过行键“得到”行,或者你能通过给定起始和终止行键检索一系列行,这就是前面提到的表扫描。你不能实时的查询一个列的值,这就引出了一个重要的话题:行键的设计。
有两个原因令行键的设计十分重要:
- 表扫描是对行键的操作,所以,行键的设计控制着你能够通过HBase执行的实时/直接获取量。
- 当在生产环境中运行HBase时,它在HDFS上部运行,数据基于行键通过HDFS,如果你所有的行键都是以user-开头,那么很有可能你大部分数据都被分配一个节点上(违背了分布式数据的初衷),因此,你的行键应该是有足够的差异性以便分布式地通过整个部署。
你定义行键的方式取决于你想怎样存取那些行。如果你想以用户为基础存储数据,那么一个策略是利用字节队列在HBase中存储行键,所以我们可以创建一个用户ID的哈希(例如MD5或SHA-1),然后在哈希后面附上时间(long类型)。使用哈希有两个重点:(1)是它能够将value分散开,数据能够分布式地通过簇,(2)是它确保key的长度是一致的,以更加容易在表扫描中使用。















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









