







一 摘要
地区房价分析,地域价值分析等,需要大量样本数据作为分析源。一些互联网网站上汇聚了大量房源信息,用户可以通过复制粘贴方式直观的将信息复制到表格中,只是操作及其繁琐,工作量较大。
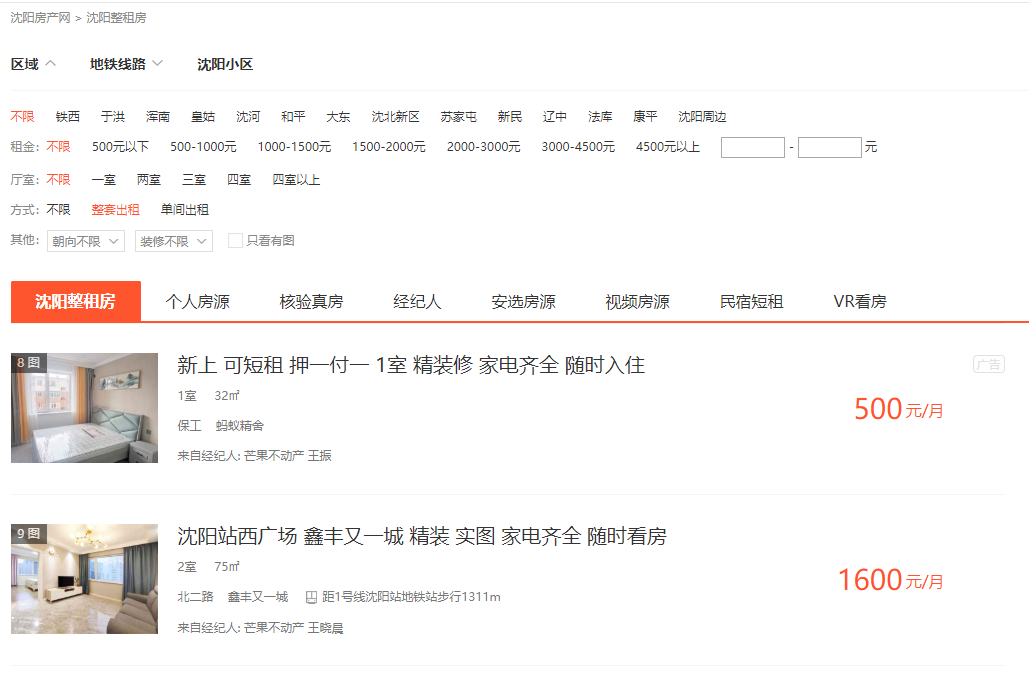
使用小O网兜,通过可视化、自助式配置,能够快速的将网页内容自动化的复制到表格中。
下面介绍操作步骤。
二 操作步骤
1 新建任务文件
此步骤无需多言,直接看图,新建的任务文件扩展名为 xop,备份或迁移文件可以复制该文件即可。
接下来所有步骤产生的数据都会保存在此XOP文件中。

2 新建任务
在浏览器上访问目标页码,复制网页地址,新建任务,在界面上粘贴网页地址,点击确定新建任务。
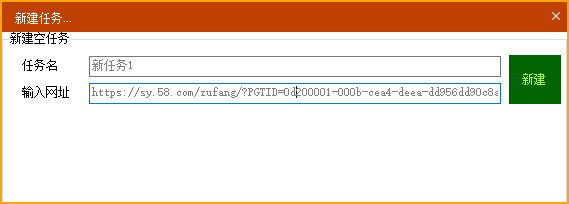
3 配置字段
双击打开网页,网页显示后,在中间的配置栏中配置需要复制的数据项。
数据块的概念,如图,红色块表示一个数据块,蓝色表示数据项
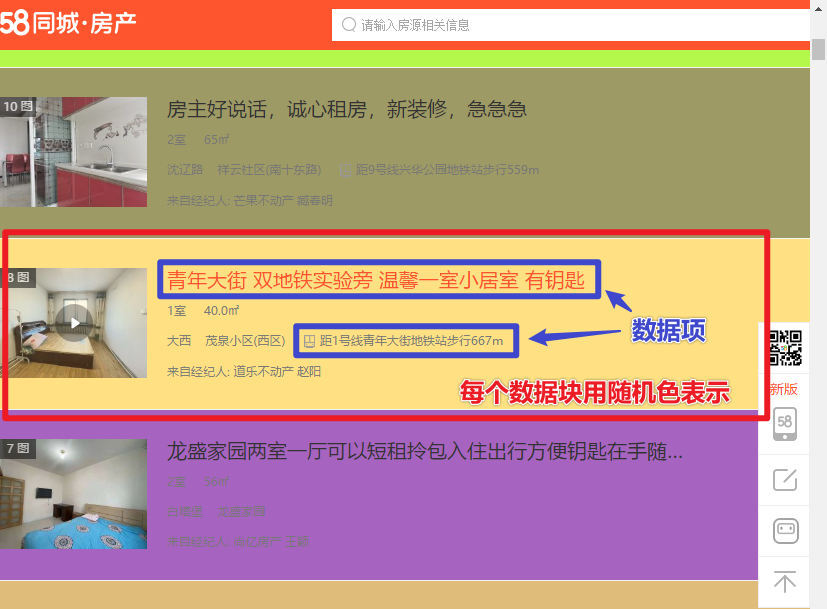
依次配置数据项保存至字段,重点是数据块的选取。

参考上图配置数据块的数据项完毕。
4 配置翻页
配置翻页信息,目的是让程序自动翻页执行,逐页复制数据。
参考下图,选择分页数据块
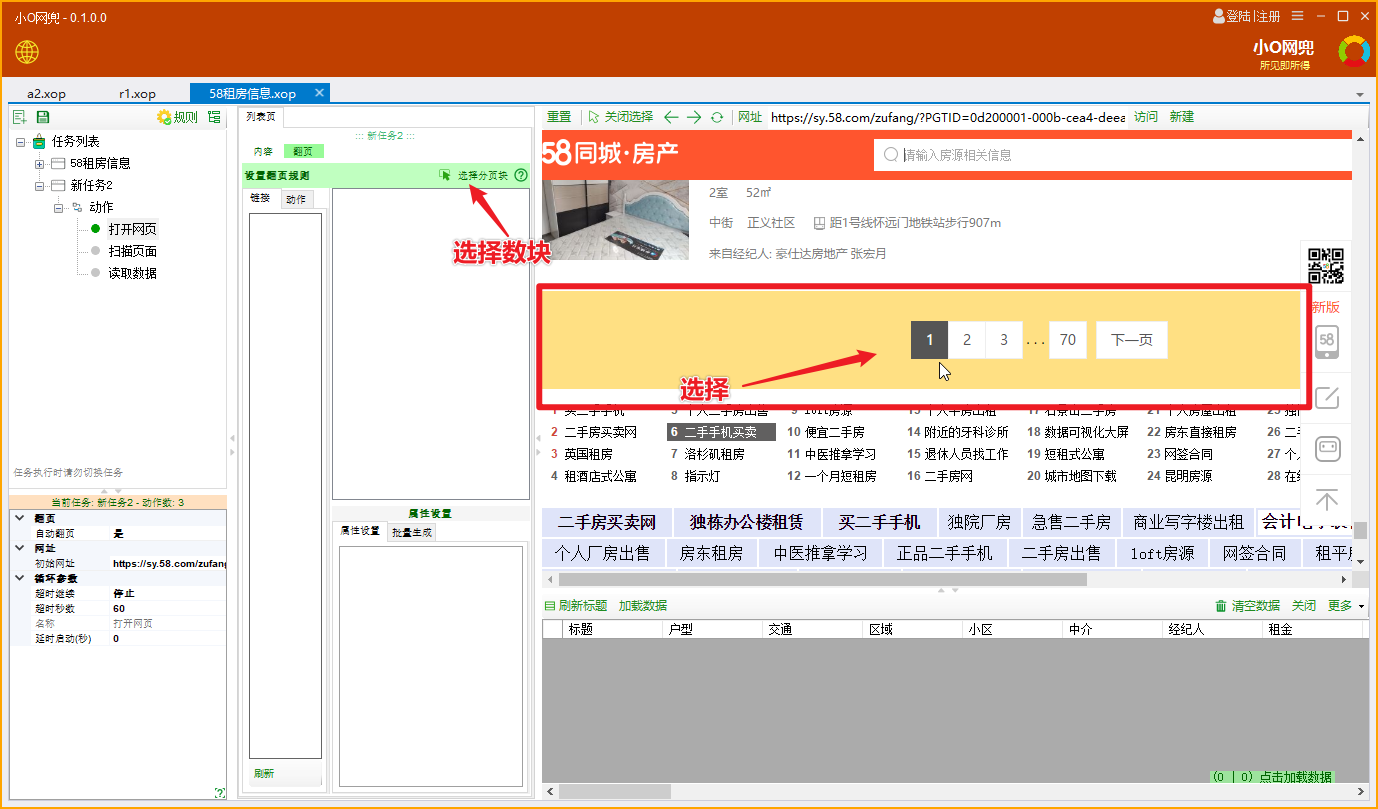
参考下图创建翻页链接
每个翻页项会依次自动执行。
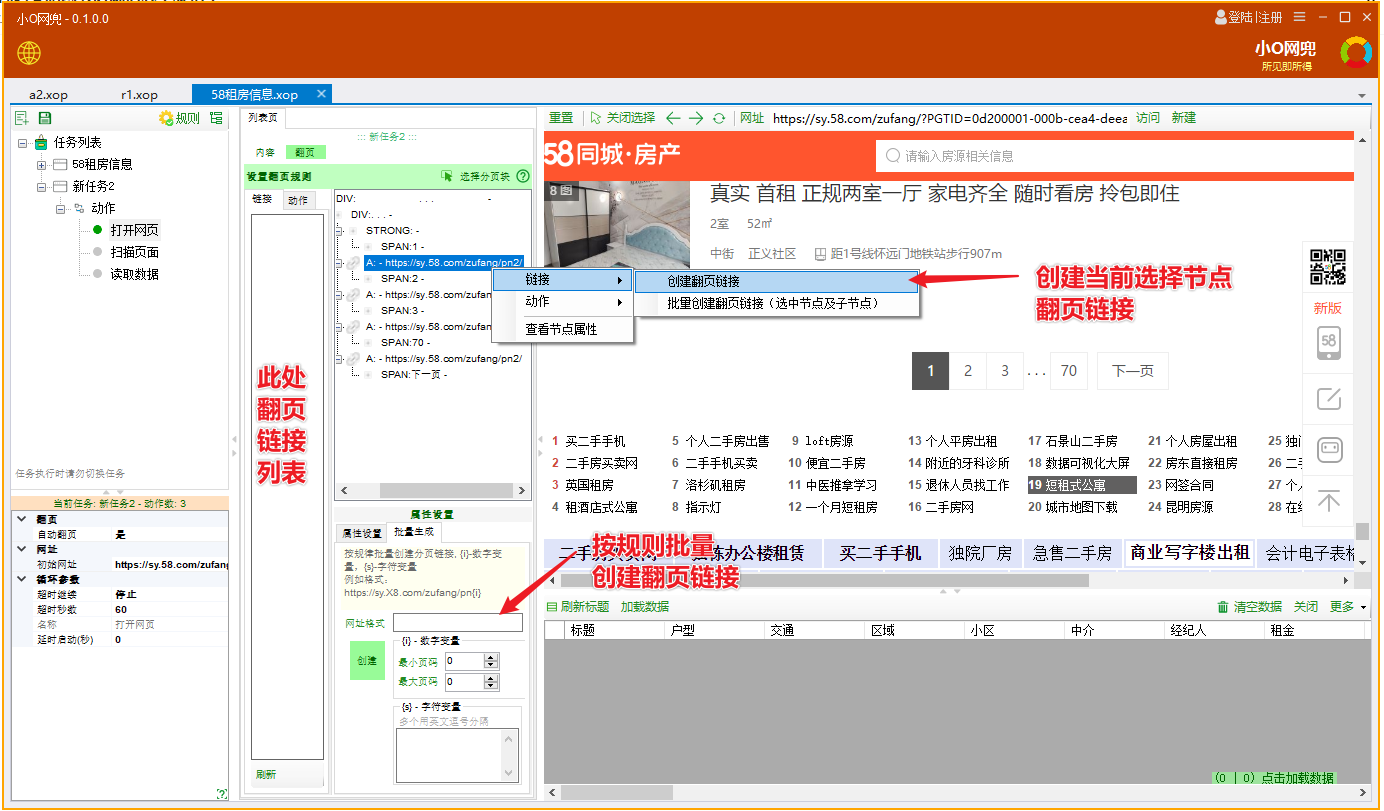
所有配置i完成后,下面开始执行。
3 执行任务
1 单步执行
根据需要,可以手动翻页后,单步执行动作,进行数据复制操作。
如下图步骤
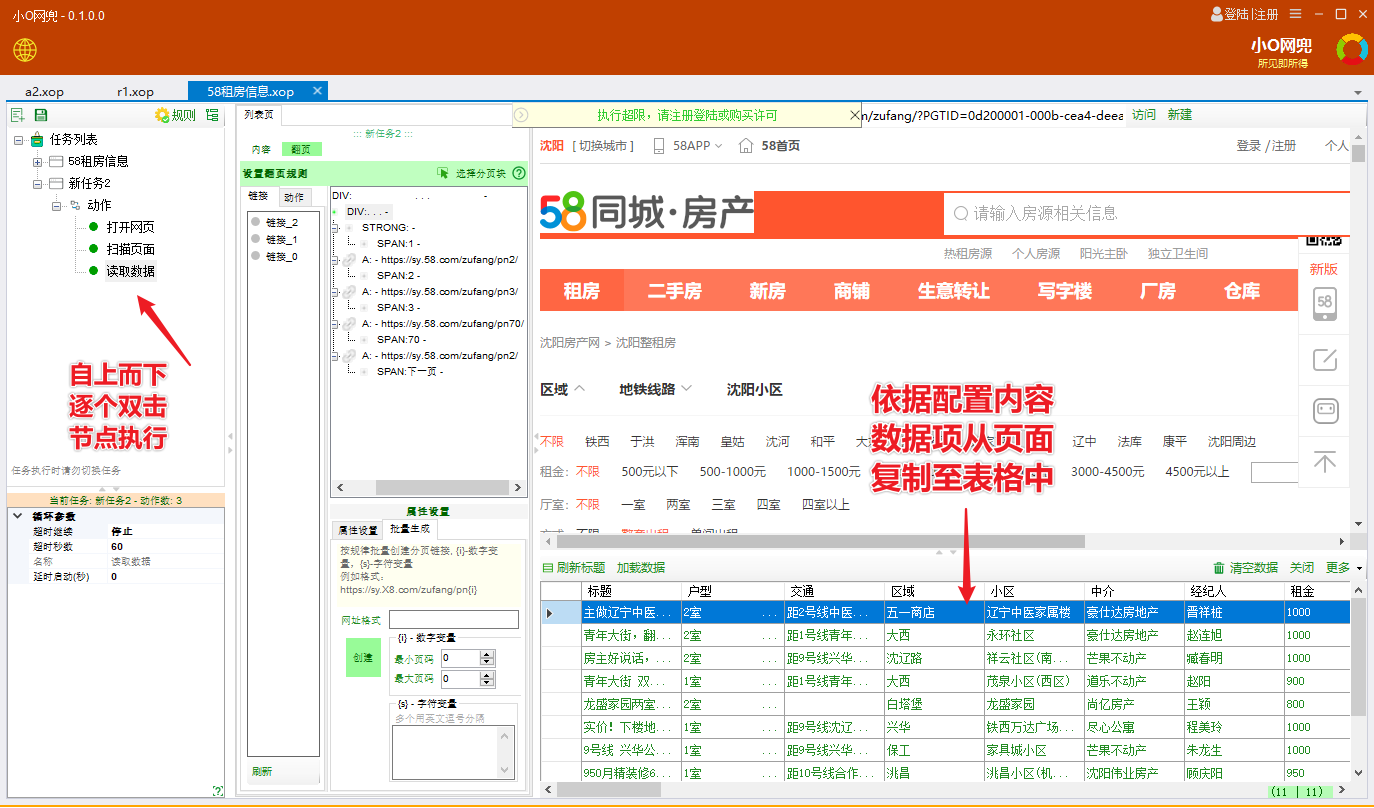
手动翻页,如下图,再次执行【扫描页面】和【读取数据】两个动作节点,将下一页信息复制至表格中。

重复上述步骤,手动翻页后,执行动作,将每个页面内容复制至表格中。
2 循环执行(无人留守运行)
除手动翻页,我们也可以让程序自动翻页执行动作,进行数据复制操作。
配置完毕翻页项后,在任务树上右键点击【打开网页】节点,如下图
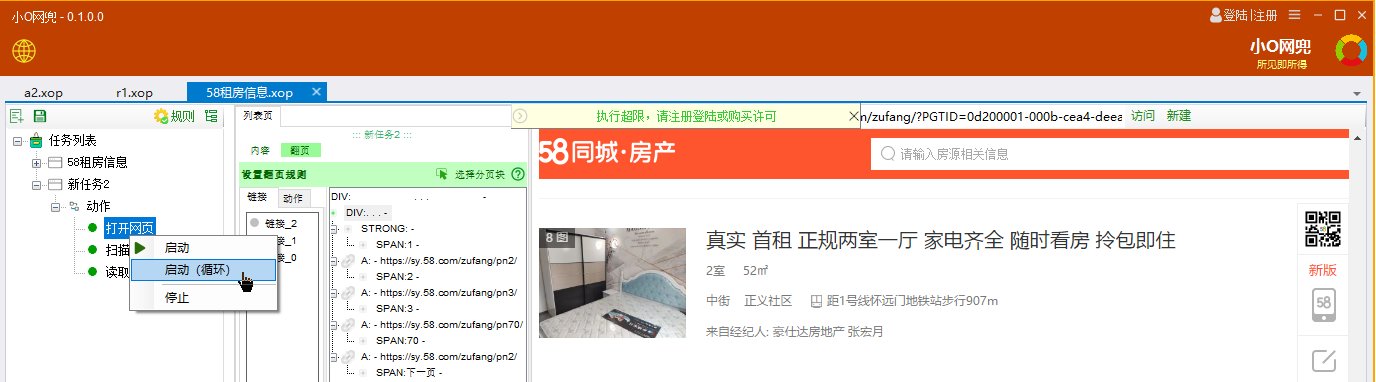
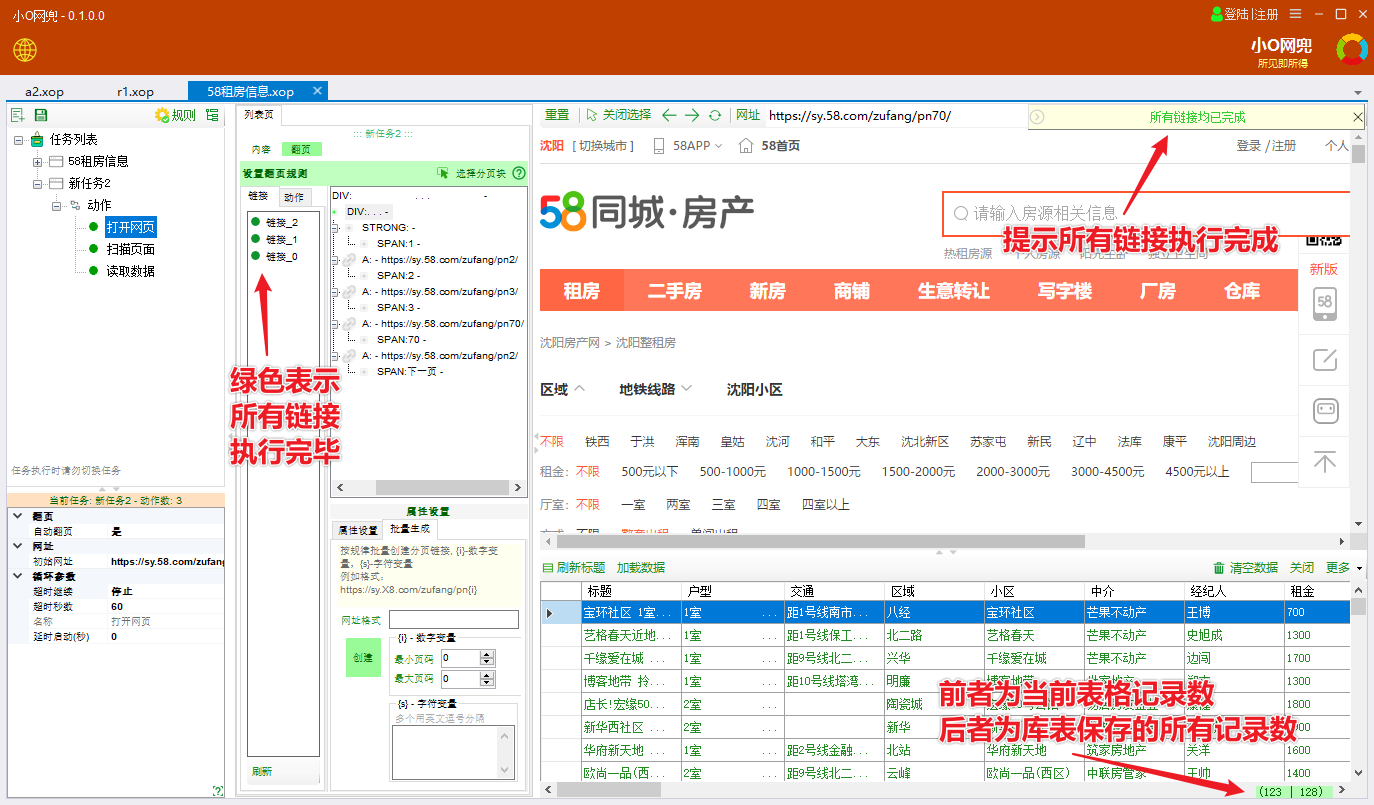
程序会进入自动循环模式,依次执行链接列表中的链接,每个链接会执行【扫描】和【读取】数据动作,直至所有翻页均执行完成。
如下图,绿色表示完成,黄色表示正在执行。

所有链接执行完毕后,如下图
三 导出数据
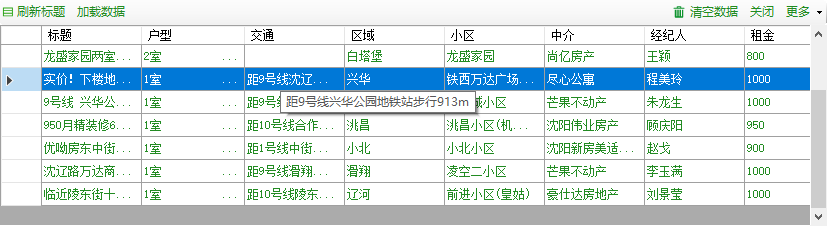
我们可以将数据导出成CSV格式数据,可以在EXCEL中打开。
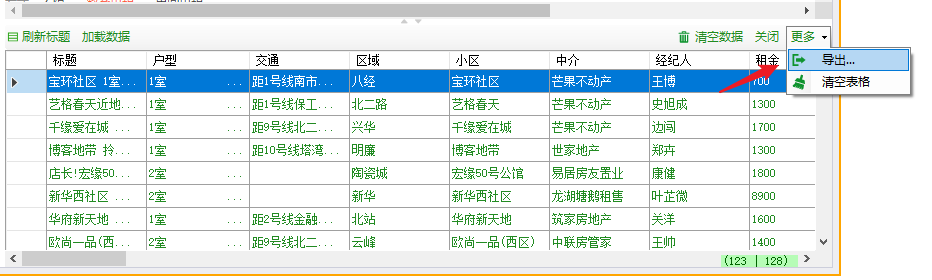
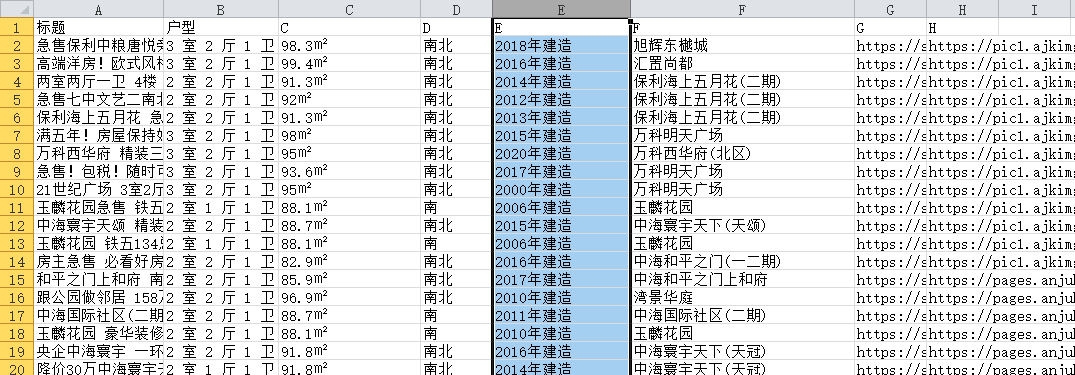
导出数据在EXCEL中查看
到此就是小O网兜复制网页信息的全过程,感兴趣的朋友可登陆官网下载软件。
【完】















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









