






推荐开源项目:MolT5 —— 分子与自然语言之间的转换神器
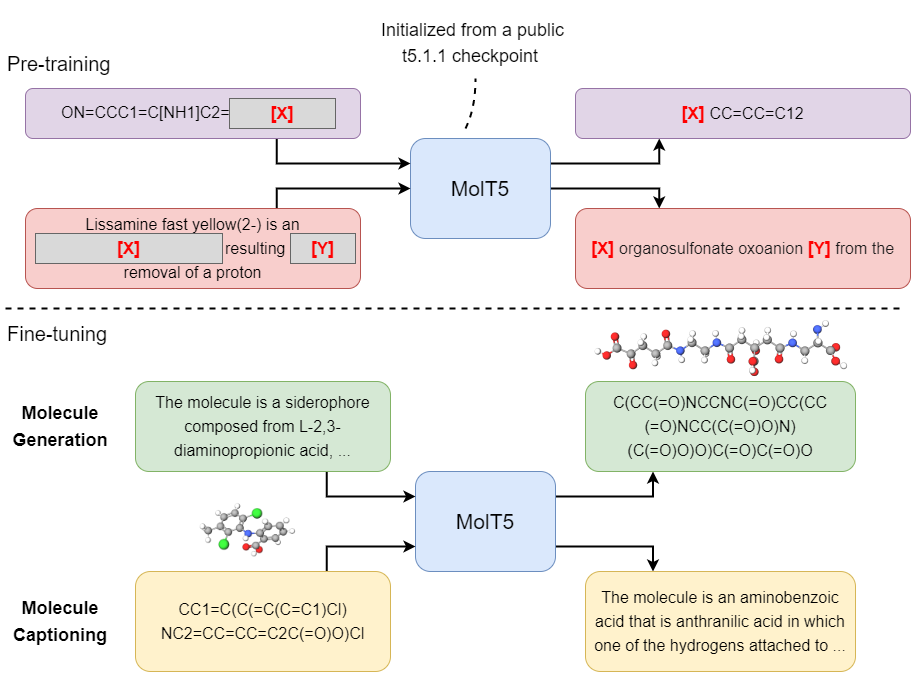
项目介绍 MolT5是一个创新的深度学习模型,它在2022年EMNLP会议上首次亮相。这个开源项目旨在实现分子结构(如SMILES表示)与自然语言之间的无缝转换,为化学和生物信息学领域带来革命性的变化。MolT5结合了T5预训练模型的强大功能,使研究人员和开发者能够利用自然语言处理技术来理解和生成复杂的化学分子。
项目技术分析 MolT5基于T5序列到序列模型的架构,通过两个关键任务——smiles2caption(分子描述生成)和caption2smiles(自然语言转分子)进行扩展。该模型在大规模数据集上进行了预训练,并且可以在HuggingFace Transformers库中轻松使用。它的实施还包括使用Google的t5x框架进行预训练和微调,确保高效且灵活的实验流程。
应用场景 MolT5的应用广泛,包括但不限于:
- 药物发现:帮助科学家快速生成新分子并理解其属性。
- 化学教育:将复杂的分子结构以易于理解的语言解释给学生。
- 数据库检索:通过自然语言查询来搜索化学数据库,提高效率。
- 机器翻译:在不同的化学术语之间建立桥梁,促进国际交流。
项目特点
- 强大的转换能力:MolT5可以准确地将化学分子转换成自然语言描述,反之亦然。
- 多规模模型:提供了小型、基础型和大型三个不同参数量的版本,满足不同计算资源需求。
- 开放源代码:所有模型和训练代码均开源,便于社区研究和应用。
- 易用性:支持HuggingFace Transformers API,只需几行代码即可进行推理或微调。
- 全面的数据集:提供的数据集覆盖多个领域,增强了模型的泛化能力。
要体验MolT5带来的便利,你可以直接从HuggingFace模型仓库中加载预训练和微调后的模型,或者下载T5X模型检查点进行自定义训练。项目文档详细说明了如何进行评估、预训练和微调,对于想要在自然语言处理和化学交叉领域探索的开发者来说,这是一个不容错过的机会。如果你的工作得益于这个项目,请引用论文,共同推动科研进步。
引用:
@inproceedings{edwards-etal-2022-translation,
title = "Translation between Molecules and Natural Language",
author = "Edwards, Carl and
Lai, Tuan and
Ros, Kevin and
Honke, Garrett and
Cho, Kyunghyun and
Ji, Heng",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.26",
pages = "375--413",
}
现在就加入MolT5的世界,让分子和自然语言的沟通无界!





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











