






Gecco:轻量级Java网络爬虫框架
项目简介
Gecco是一个由Java语言编写的简单易用的轻量级网页抓取框架。它集成了jsoup、httpclient、fastjson、spring、htmlunit和redisson等优秀框架,让开发者只需配置一些类似jQuery的选择器就能快速构建起爬虫。Gecco具备出色的扩展性,遵循“开闭原则”,允许修改封闭,开放扩展。此外,该框架基于非常开放的MIT开源协议,无论是用户还是希望共同改进Gecco的开发者,都欢迎发起Pull Request或进行贡献。
项目技术分析
主要特性:
- 易于使用:采用jQuery风格的选择器提取网页元素,让爬虫开发变得简单。
- 支持异步Ajax请求:能够处理页面中的动态加载内容。
- JavaScript变量提取:可以捕获并处理页面中执行后的JavaScript变量。
- 分布式爬虫:通过Redis实现,参考gecco-redis项目。
- Spring集成:使用Spring开发业务逻辑,参考gecco-spring项目。
- HTMLUnit扩展:增强HTML解析能力,参考gecco-htmlunit项目。
- 扩展机制:提供灵活的插件系统,方便定制化需求。
- UserAgent随机选择:模拟不同浏览器进行下载。
- 代理服务器随机选择:支持通过代理服务器进行下载。
框架结构:
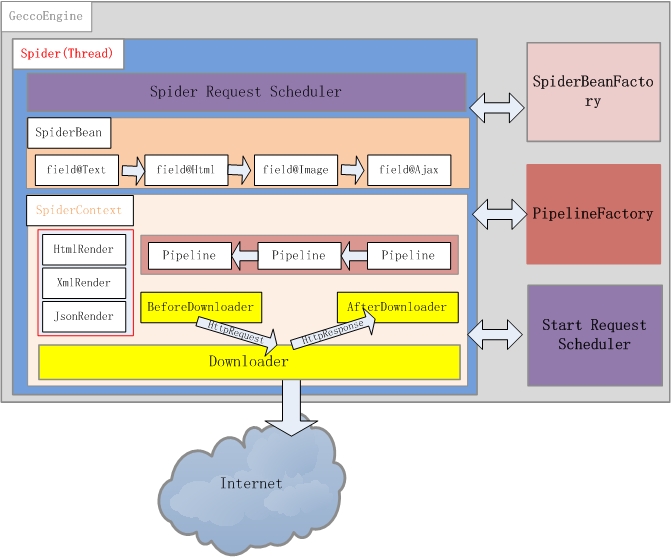
Gecco的设计遵循模块化原则,包括HTTP请求、HTML解析、数据提取和结果处理四大核心部分,使得各组件间解耦合,易于维护和扩展。
应用场景
- 数据挖掘:从网站上批量获取并分析特定类型的信息,如新闻、产品价格等。
- 监控:跟踪网站更新,例如博客发布、社交媒体活动等。
- SEO优化:分析竞争对手的关键词策略,评估网站在搜索引擎中的排名。
- 自动化测试:配合HTMLUnit,用于网页应用的自动化功能测试。
项目特点
- 简洁高效:通过简单的注解和配置,即可定义爬虫规则,减少代码编写工作量。
- 强大扩展:内置多种扩展点,如自定义pipeline、filter等,可根据需求实现各种高级功能。
- 分布式支持:利用Redis实现分布式爬虫,提高抓取速度和稳定性。
- 社区活跃:作者保持活跃的博客更新和问题解答,且社区有一定活跃度,便于问题求助和经验分享。
- 开源友好:遵循MIT协议,免费且无商业限制,可自由使用和二次开发。
开始使用
要尝试Gecco,请按照Maven方式添加依赖,并查看提供的快速启动示例代码,开始您的爬虫之旅:
<dependency>
<groupId>com.geccocrawler</groupId>
<artifactId>gecco</artifactId>
<version>x.x.x</version>
</dependency>
为了体验动态规则配置,你可以使用DynamicGecco类,无需预先定义SpiderBean,通过其API直接创建和修改爬虫规则。
对于更多示例和详细教程,参见项目GitHub页面和作者的博客文章,它们将帮助你深入了解如何使用Gecco进行实际开发。
最后,如果你对Gecco有任何疑问或者想为项目做出贡献,可以通过博客、邮件等方式与作者联系。也别忘了,如果觉得这个项目对你有所帮助,不妨给它点个赞或fork支持一下!
一起探索爬虫的世界,Gecco与你同行!
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











