






推荐开源项目:Html2Article - 高效HTML正文提取利器
项目介绍
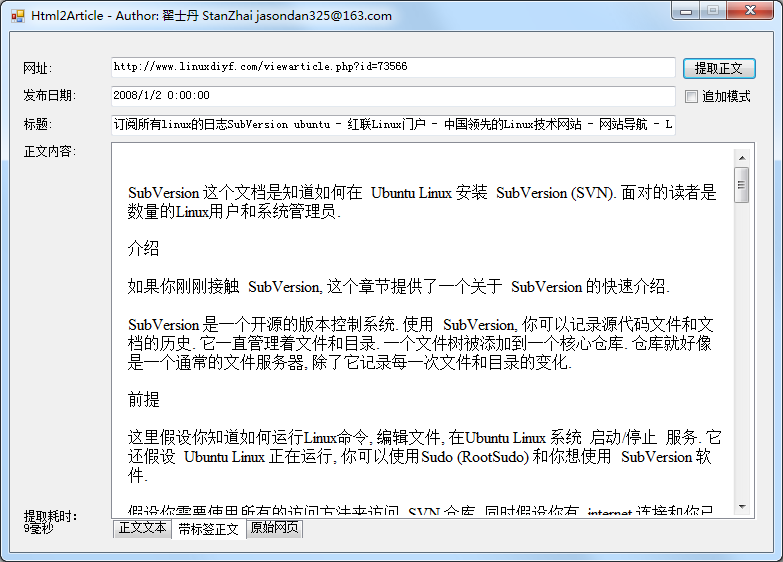
在信息爆炸的时代,我们经常需要处理大量的网页数据,如何快速准确地从HTML文档中提取出关键的正文内容是一个重要的任务。Html2Article 是一个.NET平台下的优秀开源项目,专为此需求而设计。它采用了一种基于文本密度的智能算法,能够高效地从HTML文档中提取正文,并且支持从压缩的HTML中进行处理。这个小巧但强大的工具,平均处理速度仅需30毫秒,正确率高达95%以上,大大提高了工作效率。
项目技术分析
Html2Article的核心是其标签无关的正文提取算法。这意味着它不依赖HTML结构中的特定标签来确定正文,而是通过分析文本的密度和分布来判断。这种算法确保了即使面对布局各异的网页,也能稳定提供高质量的正文提取结果。此外,项目还提供了多个可配置参数,如分析深度、字符限定数等,以适应不同的网页结构和用户需求。
项目及技术应用场景
Html2Article适用于各种需要从HTML中抽取内容的场景,包括但不限于:
- 新闻聚合器:快速提取新闻网站的内容,方便整合展示。
- 搜索引擎优化(SEO):分析和提取网页主要信息,提升索引效率。
- 数据挖掘和分析:预处理大量网页数据,提取有价值的信息。
- 学术研究:自动化提取论文摘要或重要观点。
- 内容管理系统:自动整理导入的外部HTML内容。
项目特点
- 高效:平均30ms的处理速度,让正文提取变得即时。
- 高精度:超过95%的正确率,确保提取内容的准确性。
- 标签无关:无需依赖HTML标签,适应性强。
- 压缩HTML支持:直接处理压缩过的HTML文件,减少解压环节。
- 简单易用:一键安装包管理器,只需几行代码即可集成到项目中。
- 自定义配置:可根据需要调整分析参数,提高处理效果。
如果你的项目需要处理HTML正文提取,那么Html2Article无疑是一个值得尝试的工具。借助这个库,你可以轻松实现复杂网页数据的智能化处理,从而专注于更重要的业务逻辑开发。立即通过Install-Package Html2Article将其添加到你的项目中,享受高效正文提取带来的便利吧!
License: Apache 2.0

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











