






无声之锥:基于定位的语音分离技术
Cone-of-SilenceThe Cone of Silence: 项目地址:https://gitcode.com/gh_mirrors/co/Cone-of-Silence
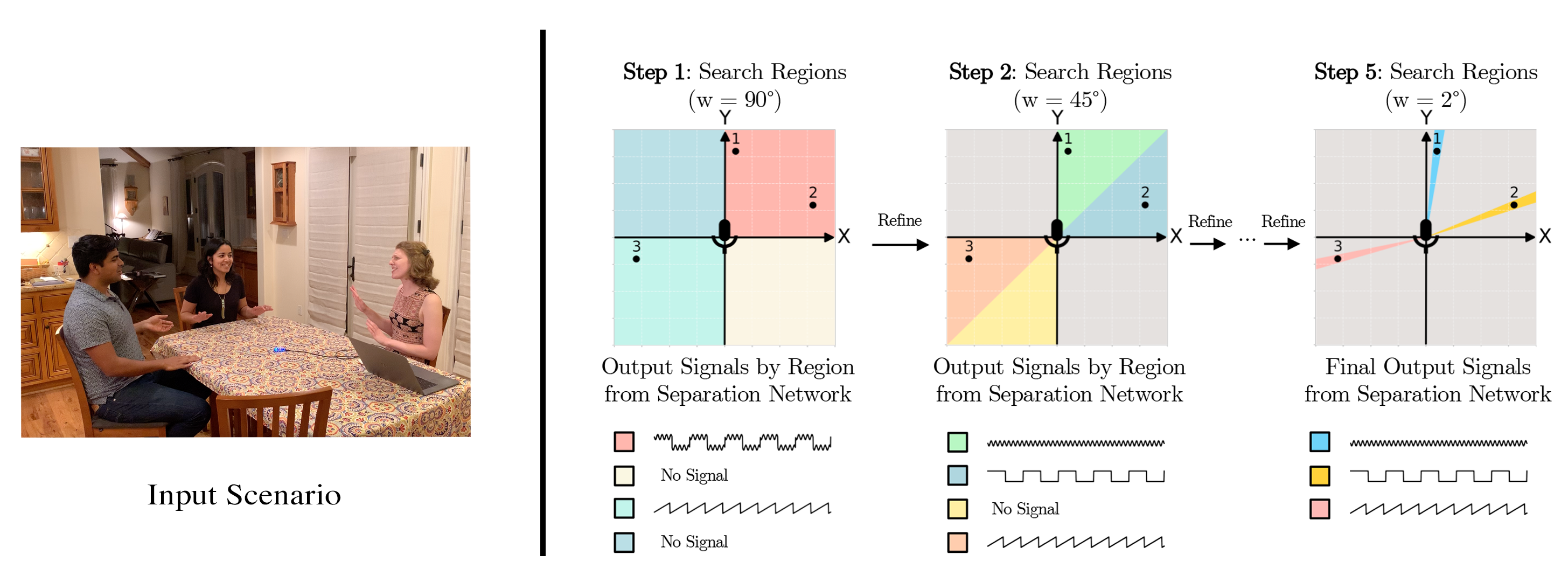
近年来,随着人工智能和信号处理技术的飞速发展,如何在复杂的音频环境中精确地分离并定位多个说话者成为了一个引人注目的研究课题。今天,我们有幸向大家推介来自华盛顿大学的一项杰出成果——“无声之锥:基于定位的语音分离”。
项目介绍
无声之锥是由Teerapat Jenrungrot、Vivek Jayaram等人共同开发,它旨在实现复杂场景下的多声源分离与定位。这项技术尤其亮点在于,仅通过一个神经网络就能处理任意数量的移动说话者,无需对每位说话者的特定模型进行训练。项目代码公开,让每个人都能探索和评估其在合成数据上的效果,并且,如果你拥有一个多麦克风阵列,甚至能够复现项目视频中展示的惊人结果。
技术分析
该技术的核心是一个深度学习模型,设计巧妙地结合了声音源分离与空间定位功能。利用PyTorch框架,它能够处理从合成数据到真实环境录音的广泛情况。这背后的关键是运用声学原理模拟房间内声音传播特性,包括到达时间差(TDOA)和级联差异,通过pyroomacoustics库实现。训练过程强调了预训练模型的重要性,允许快速适应不同的麦克风配置和环境条件,减少了从零开始训练的需求。
应用场景
无声之锥的应用潜力无限广阔。无论是语音识别系统中的背景噪声去除,直播会议中的个性化音频流提取,还是音频制作领域中的复杂音轨分离,都有着极为重要的应用价值。对于科研人员来说,它提供了研究声场建模和人类听觉感知的新工具;而对于开发者,则意味着能在产品中实现更精准的语音交互体验,特别是在智能助手和远程会议解决方案中。
项目特点
- 灵活处理多说话者:无论说话者数量多少或是否移动,都能有效分离。
- 单一网络架构:简化了传统的多步骤处理流程,降低了应用门槛。
- 适应性强:从合成数据到实际录制,无缝切换,轻松适配不同麦克风布局。
- 开源共享:提供详细的文档、预训练模型和实用脚本,便于开发者迅速上手。
- 科学验证:经过严格测试,实证了其在多声源定位与分离方面的准确度和实用性。
无声之锥项目不仅代表了当前语音处理技术的一个高度,更是未来智能家居、虚拟会议等领域不可或缺的技术基石。它的开源发布,无疑为科研界和工业界打开了一扇新的大门,邀请着每一位对此感兴趣的你,一起探索声音的世界,创造更加清晰、个性化的听觉未来。赶快加入这个激动人心的旅程,探索和贡献于这个卓越的开源项目吧!
Cone-of-SilenceThe Cone of Silence: 项目地址:https://gitcode.com/gh_mirrors/co/Cone-of-Silence





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











