









今天我们要来学习ElasticSearch的搜索方面的api,在开始之前,为了便于演示,我们先要创建一些索引数据。
Search APIs官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/5.3/search.html
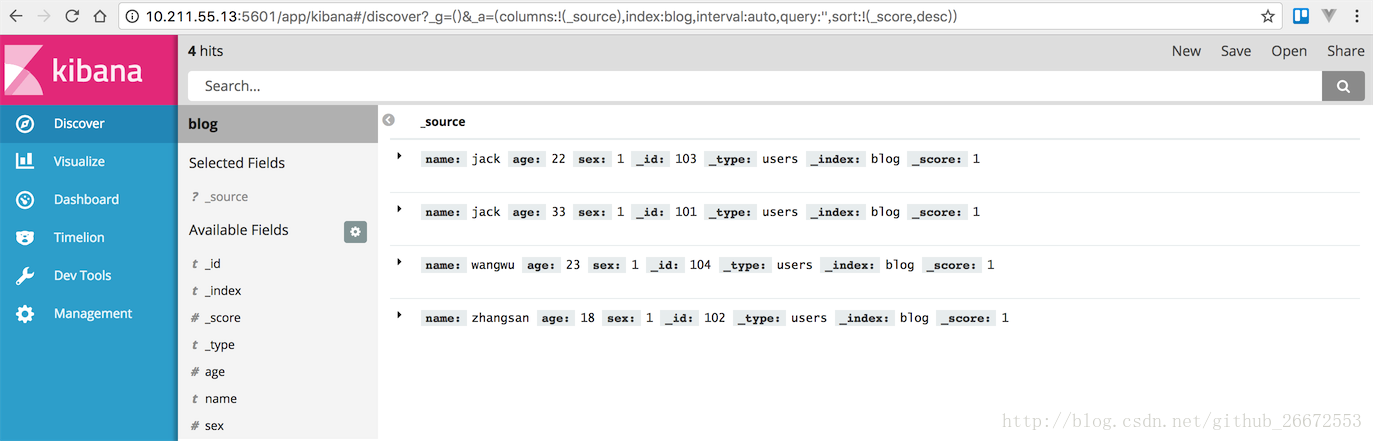
1、按name搜索,搜索jack
GET blog/users/_search?q=name:jack结果如下:
{
"took": 77,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.47000363,
"hits": [
{
"_index": "blog",
"_type": "users",
"_id": "103",
"_score": 0.47000363,
"_source": {
"name": "jack",
"age": 22,
"sex": 1
}
},
{
"_index": "blog",
"_type": "users",
"_id": "101",
"_score": 0.47000363,
"_source": {
"name": "jack",
"age": 33,
"sex": 1
}
}
]
}
}
使用场景:
1、后台新增一个“客户信息”,除了插入数据库,同时也要插入es索引
2、假设客户类型是”vip”
3、前台取出属于vip类型的客户,那么就要….
2、更常用的方式 Request Body Search
https://www.elastic.co/guide/en/elasticsearch/reference/5.3/search-request-body.html
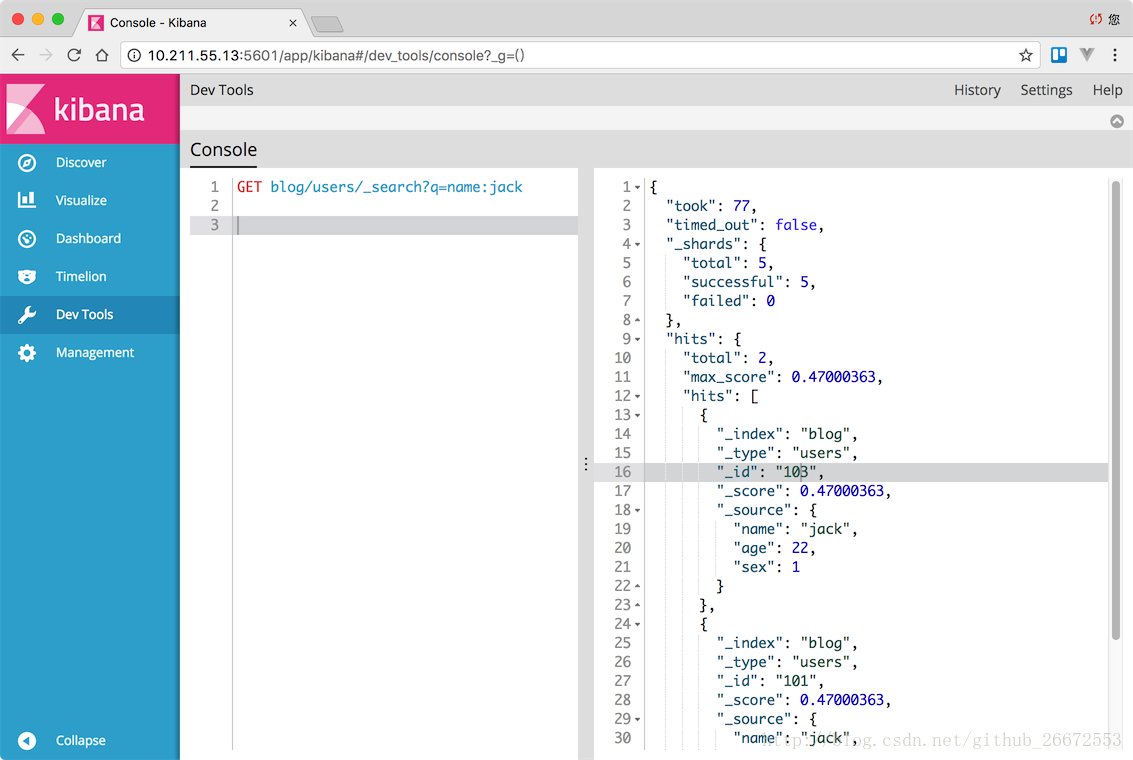
GET blog/users/_search
{
"query":{
"term":{
"name":"jack"
}
}
}搜索结果:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.47000363,
"hits": [
{
"_index": "blog",
"_type": "users",
"_id": "103",
"_score": 0.47000363,
"_source": {
"name": "jack",
"age": 22,
"sex": 1
}
},
{
"_index": "blog",
"_type": "users",
"_id": "101",
"_score": 0.47000363,
"_source": {
"name": "jack",
"age": 33,
"sex": 1
}
}
]
}
}3、全文检索
GET blog/users/_search
{
"query":{
"match":{
"name":"我是jack"
}
}
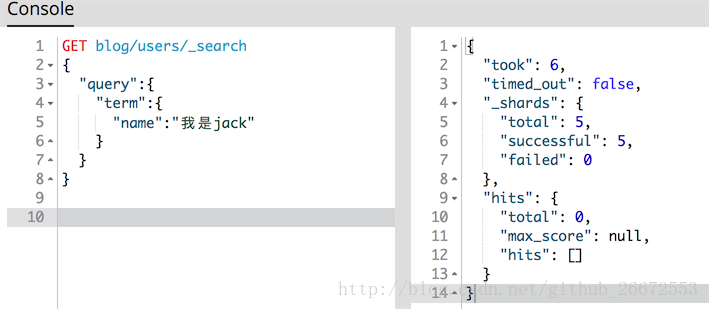
}注意我们这里参数的变化match也能搜到,如果我们用之前term就搜不到啦:
GET blog/users/_search
{
"query":{
"term":{
"name":"我是jack"
}
}
}
分析器(Analyzer)
三部分构成:
1、字符过滤器(Character Filters)
2、分词器(Tokenizers)
3、分词过滤器(Token Filters)
ES给我们内置啦若干分析器类型,其中常用的是标准分析器,叫做”standard”。我们肯定需要扩展,并使用一些第三方分析器。
不过我们得先了解分析器是怎么工作的:
analyzer通常由一个Tokenizer(怎么分词),以及若干个TokenFilter(过滤分词)、Character Filter(过滤字符)组成。
https://www.elastic.co/guide/en/elasticsearch/reference/5.3/analysis-analyzers.html
1、分析一下“我是jack“这句话
POST _analyze
{
"analyzer": "standard",
"text": "我是jack"
}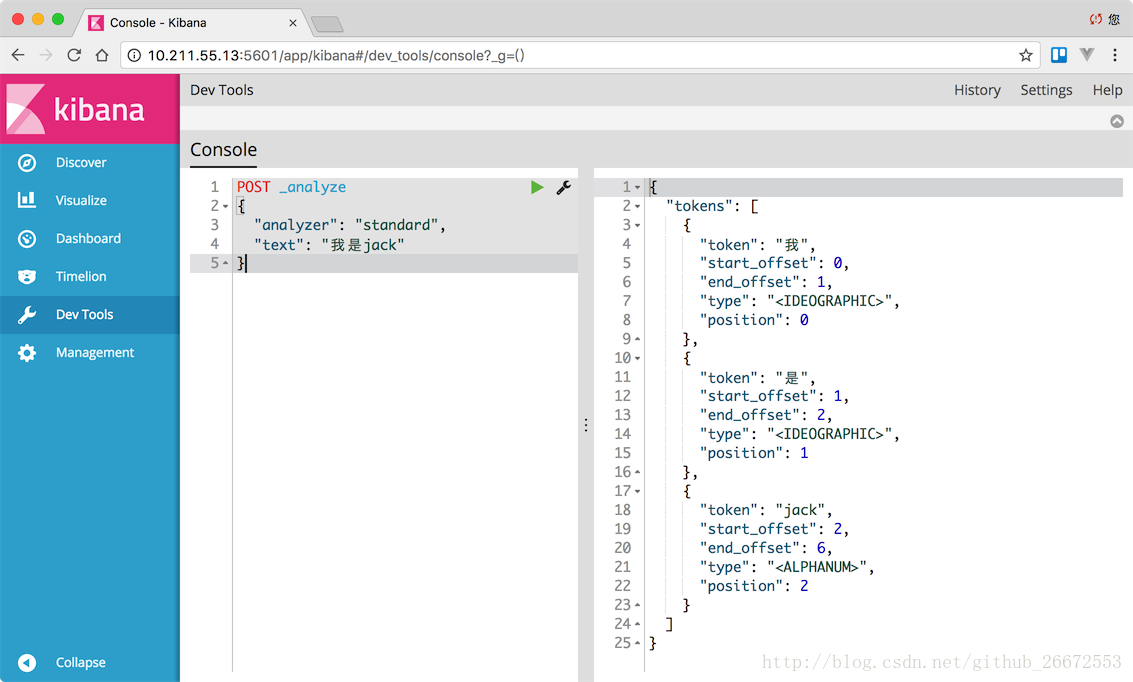
被分成了3个词:我、是、jack。
区分大小写?
POST _analyze
{
"analyzer": "standard",
"text": "我是JACK"
}分词结果一样,说明标准分析内部会给我们转成小写。
2、如果是simple分词呢
POST _analyze
{
"analyzer": "simple",
"text": "我是JACK"
}分词结果就是这样的:
{
"tokens": [
{
"token": "我是jack",
"start_offset": 0,
"end_offset": 6,
"type": "word",
"position": 0
}
]
}可见simple和standard的不同。
但simple效率肯定是最高的,我们可以分析下面字符串:
POST _analyze
{
"analyzer": "simple",
"text": "我 是 JACK"
}注意字符串的空格,这样分词结果如下:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "word",
"position": 0
},
{
"token": "是",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1
},
{
"token": "jack",
"start_offset": 4,
"end_offset": 8,
"type": "word",
"position": 2
}
]
}3、Standard Tokenizer
https://www.elastic.co/guide/en/elasticsearch/reference/5.3/analysis-standard-tokenizer.html
POST _analyze
{
"tokenizer": "standard",
"text": "我是JACK"
}分词结果和"analyzer": "standard",一样。
4、如果仅仅是转小写
POST _analyze
{
"tokenizer": "lowercase",
"text": "我是JACK"
}最后转小写,并没有分词:
{
"tokens": [
{
"token": "我是jack",
"start_offset": 0,
"end_offset": 6,
"type": "word",
"position": 0
}
]
}5、如果我们既想分词,又想转小写
POST _analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "我是JACK"
}结果如下:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "jack",
"start_offset": 2,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 2
}
]
}6、html字符过滤
如果我们搜索我是<br>JACK</b>,其中有html字符,我们想过滤html字符怎么办。
https://www.elastic.co/guide/en/elasticsearch/reference/5.3/analysis-htmlstrip-charfilter.html
POST _analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"char_filter": [ "html_strip" ],
"text": "我是<br>JACK</b>"
}














 1937
1937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









