






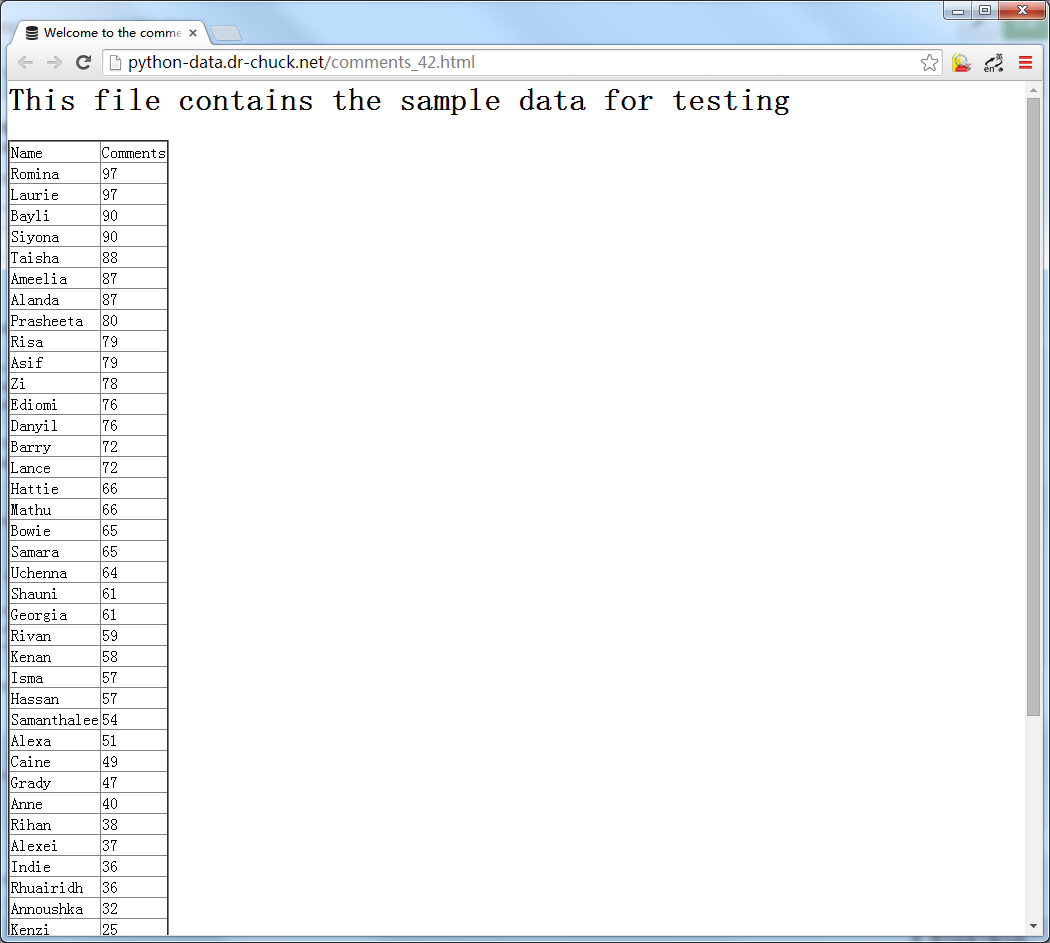
这次的Assignment是统计如图所示中的所有comments的总和和数量
代码如下
# Note - this code must run in Python 2.x and you must download
# http://www.pythonlearn.com/code/BeautifulSoup.py
# Into the same folder as this program
import urllib
from BeautifulSoup import *
su=int()
count=int()
url = raw_input('Enter - ')
html = urllib.urlopen(url).read()
soup = BeautifulSoup(html)
# Retrieve all of the anchor tags
tags = soup('span')
for tag in tags:
# Look at the parts of a tag
su=su+int(tag.contents[0])
count=count+1
print 'count ',count
print 'sum ',su
# print 'URL:',tag.get('href', None)
# print 'Contents:',tag.contents[0]
# print 'Attrs:',tag.attrs
首先是BeautifulSoup,这次用的是课程中提供的代码,如果自己去http://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/#id5下载的话,运行代码时会报错。
一、
html = urllib.urlopen(url).read()这个返回的是一个句柄,类似于open() file
二、
soup = BeautifulSoup(html)这是对html进行处理,应该是转换成可处理的类型,关于beautifulsoup还不是太理解,课程中是说soup is a lot of stuffs。
三、
tags = soup('span')返回一个标签,以span作为开头,如下图:
<span class="comments">97</span>这里结合下面的代码说一下关于上面tag的组成
print 'URL:',tag.get('href', None)
#利用get()查找tag中的链接‘href’,没有返回none
print 'Contents:',tag.contents[0]
#文档上的解释是查找子链接,这里是查找那个number
print 'Attrs:',tag.attrs
#查找属性,返回一个list,里面存放class和“comments”
*这里还有个问题,不能用idle跑程序,会报错,得用shell来跑。
关于这方面了解的还是太少,比如tag.contents返回的值并不是int行而是[u’98’](Unicode string),不知道为什么直接用tag.contents[0]就可以返回一个 NavigableString(可以遍历的字符串)的值,然后才能强制转换。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









