







 本文介绍了一种在使用HashSet和HashMap时的小技巧,通过直接利用add/put方法的返回值来判断元素是否已存在,以此避免额外的contains调用,从而在一定程度上提高代码的执行效率。
本文介绍了一种在使用HashSet和HashMap时的小技巧,通过直接利用add/put方法的返回值来判断元素是否已存在,以此避免额外的contains调用,从而在一定程度上提高代码的执行效率。
当要在HashSet或者HashMap中add/put之前判断是否存在key时,可以直接使用add/put方法然后根据返回值来判断,因为put/add方法会将以前节点的value返回(对于Set来说会将Object对象返回,涉及到HashSet的实现方式:用HashMap实现,然后每一个节点的value放的都是同一个Object对象) 如果不存在则返回null说明不包含这个key,否则返回非空说明包含这个key。这样可以避免contain的多余使用,当这样的操作(开头所说的操作)较多时会提高时间效率~~~
这个是leetcode上的一道题 https://leetcode.com/problems/contains-duplicate-ii/,可以看到效果:
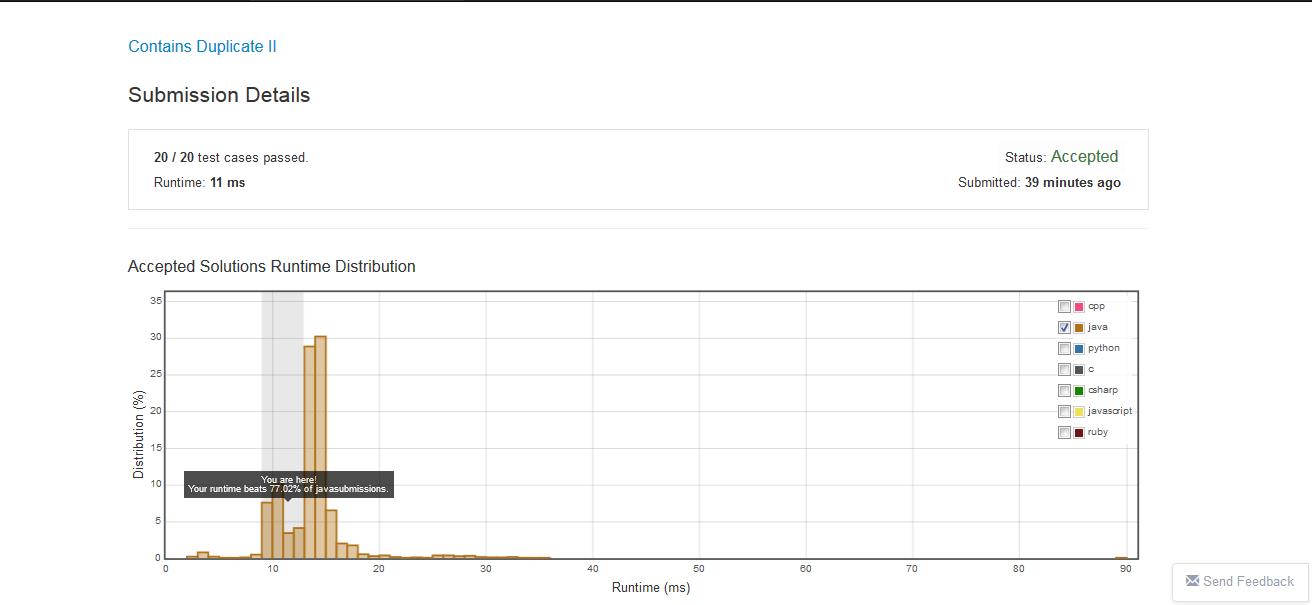
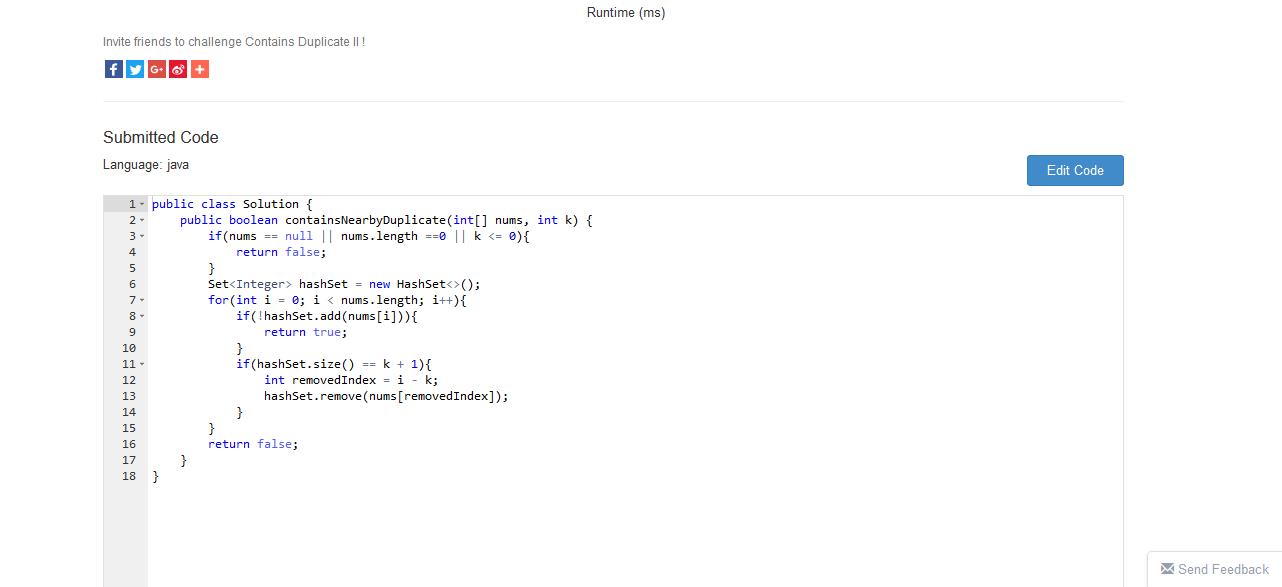
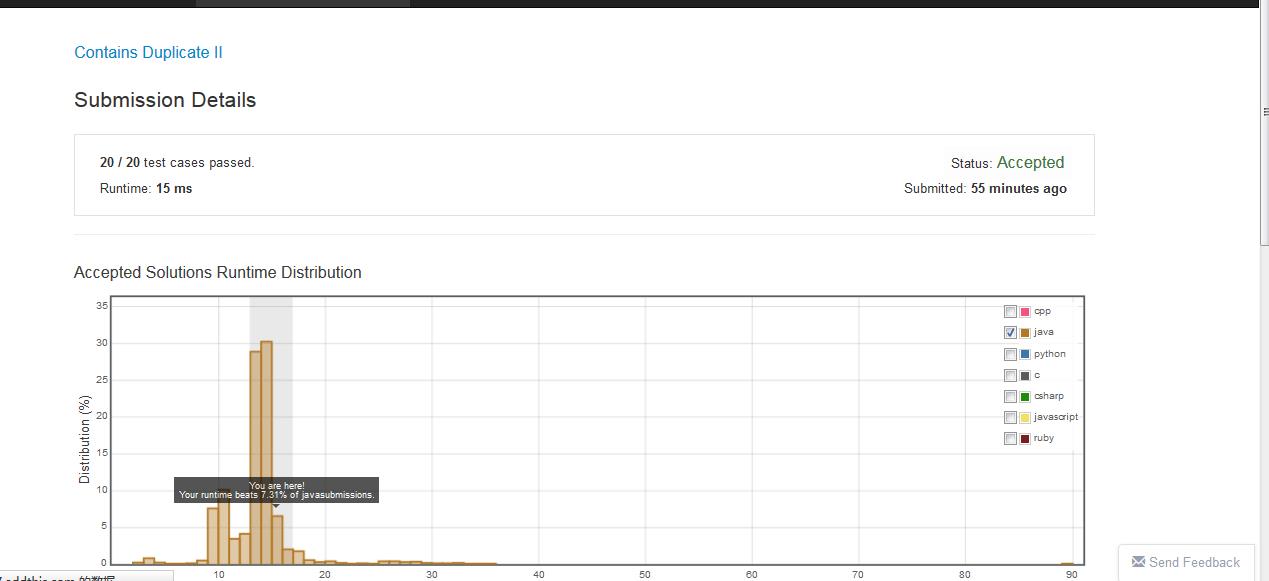
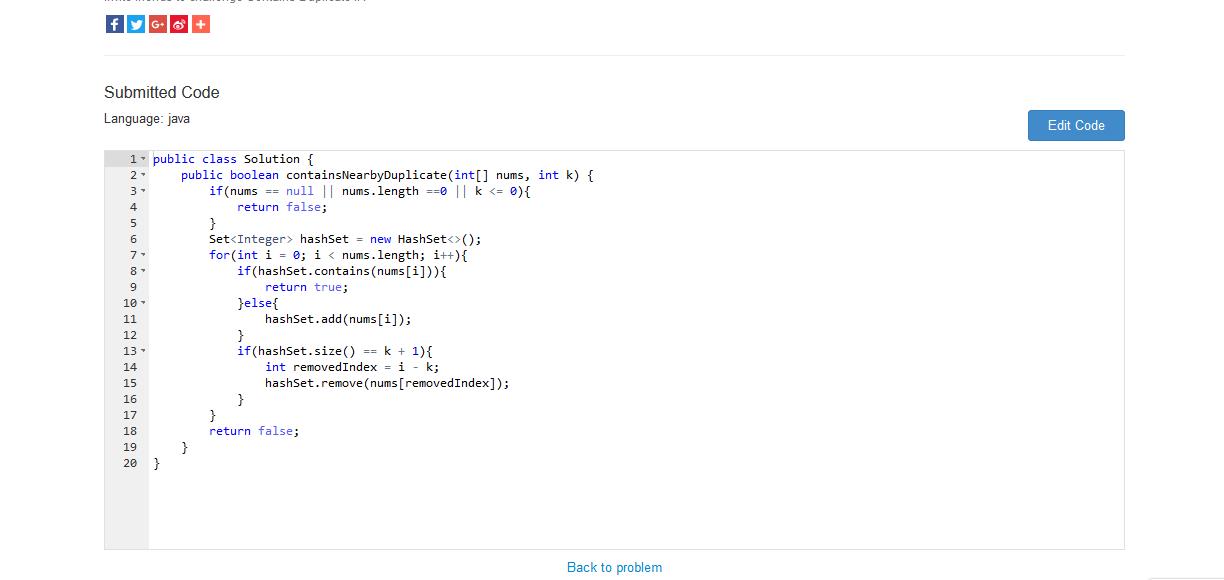
从图中可以看出,前者(11ms)比后者(15ms)效率提升了不少(这个还是在测试情况不多的情况下-20个测试用例),同理,使用Map的时候也是一样~~~
这个只是在做题和研究源码过程中一个小小的优化技巧(虽然微不足道吧,但是个人觉得细节还是挺重要的),大家有什么意见可以多多交流~欢迎~

















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









