







Speech Recognition (1)-How to change wav files to array.
Author: u5461177-Xiaotong GU (personal notes)
Wav File
Index:
1. Sample rate:
The hertz (symbol Hz) is the unit of frequency in the International System of Units (SI) and is defined as one cycle per second.8000Hz is used in phone, therefore, its enough to recognise the people speech.
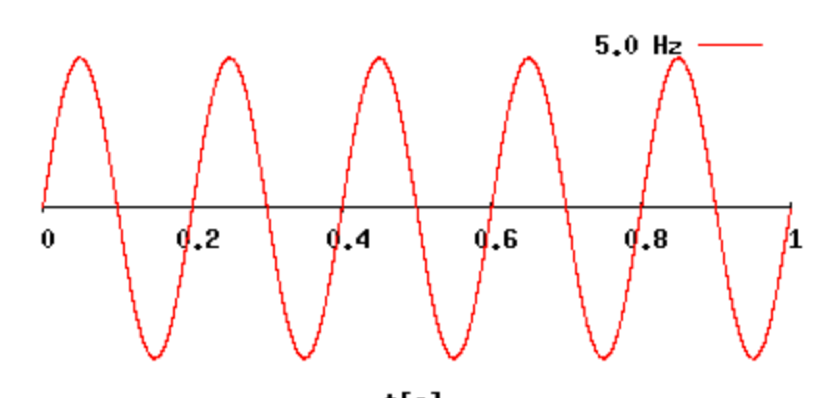
This picture is the example of 5Hz. 5 vibrations per second.
2. Simple:
The Wav Files are signed 16 bit raw, sample rate 8000 which we used.
Coding
Import wav files
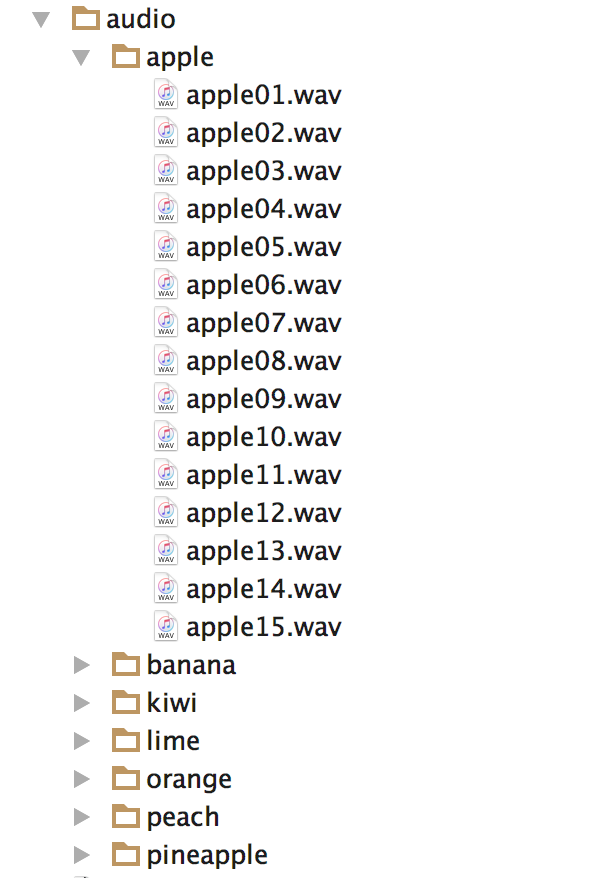
Put the paths of wav to the array ‘fpths’, and store its label in array ‘labels’.
import os
import matplotlib.pyplot as plt
fpaths = []
labels = []
spoken = []
for f in os.listdir('audio'):
for w in os.listdir('audio/' + f):
fpaths.append('audio/' + f + '/' + w)
labels.append(f)
if f not in spoken:
spoken.append(f)
print 'Words spoken:',spokenThe ‘audio ’ is a folder which stores the wav files.
Extra data from wave files
Put the paths of wav on the array ‘fpths’, and store its label in array ‘labels’.
# Files can be heard in Linux using the following commands from the command line
# cat kiwi07.wav | aplay -f S16_LE -t wav -r 8000
# Files are signed 16 bit raw, sample rate 8000
from scipy.io import wavfile
import numpy as np
import scipy
data = np.zeros((len(fpaths), 32000))
maxsize = -1
for n,file in enumerate(fpaths):
_, d = wavfile.read(file)
data[n, :d.shape[0]] = d
if d.shape[0] > maxsize:
maxsize = d.shape[0]
data = data[:, :maxsize]The structure of the ‘data’:
| Number | Data |
|---|---|
| 1 | 23,45,…,45 |
| … | 32,45,…,2234 |
| N | 456,3,…,345 |
N=number of labels, The length of data= the maxsize of the wavfile.
Establish Training label array
代码块语法遵循标准markdown代码,例如:
#Each sample file is one row in data, and has one entry in labels
print 'Number of files total:',data.shape[0]
all_labels = np.zeros(data.shape[0])# the number of lables are equal to the number of columns
for n, l in enumerate(set(labels)):
all_labels[np.array([i for i, _ in enumerate(labels) if _ == l])] = n
print 'Labels and label indices',all_labelsThe array is :

The number is its label.
Python: Relevant knowledge
Scipy:
SciPy (pronounced “Sigh Pie”) is an open source Python library used by scientists, analysts, and engineers doing scientific computing and technical computing.
SciPy contains modules for optimization, linear algebra, integration, interpolation, special functions, FFT, signal and image processing, ODE solvers and other tasks common in science and engineering.[3]
• SciPy.Wavfile[1]:

Numpy
NumPy[2] is the fundamental package for scientific computing with Python. It contains among other things:
• a powerful N-dimensional array object
• sophisticated (broadcasting) functions
• tools for integrating C/C++ and Fortran code
• useful linear algebra, Fourier transform, and random number capabilities
Besides its obvious scientific uses, NumPy can also be used as an efficient multi-dimensional container of generic data. Arbitrary data-types can be defined. This allows NumPy to seamlessly and speedily integrate with a wide variety of databases.
Numpy.zero((2,3)): create a array of 2 row 3 column [[0,0,0],[0,0,0]]
Data.shape[0]: the number of rows, shape [1]: the number of columns
HTK
HTK
It can be used.
What is HTK?
The Hidden Markov Model Toolkit (HTK) is a portable toolkit for building and manipulating hidden Markov models. HTK is primarily used for speech recognition research although it has been used for numerous other applications including research into speech synthesis, character recognition and DNA sequencing. HTK is in use at hundreds of sites worldwide.
HTK是指隐式马尔科夫链工具箱。此工具箱还可以建立和调整控制马尔科夫链模型。HTK是语音识别的主要开源工具包。其还可以用于其他的应用,如语音的合成以及特征提取和DNA序列的识别。
HTK consists of a set of library modules and tools available in C source form. The tools provide sophisticated facilities for speech analysis, HMM training, testing and results analysis. The software supports HMMs using both continuous density mixture Gaussians and discrete distributions and can be used to build complex HMM systems. The HTK release contains extensive documentation and examples.
HTK 由一系列的模型包和工具组成,这些包是由C语言所撰写的。这些工具包提供了一些成熟的用于语音识别的功能,其提供了HMM的training, testing 和results analysis的工具。 并且他支持HMM混合高斯距离和离散距离的距离计算,以此来构建更加复杂的HMM系统。
VoxForge
http://www.voxforge.org/
VoxForge was set up to collect transcribed speech for use with Free and Open Source Speech Recognition Engines (on Linux, Windows and Mac).
Reference:
[1]”Scipy.Io.Wavfile.Read — Scipy V0.18.0 Reference Guide”. Docs.scipy.org. N.p., 2016. Web. 13 Aug. 2016.
[2]”Numpy — Numpy”. Numpy.org. N.p., 2016. Web. 14 Aug. 2016.
[3] “Scipy”. Wikipedia. N.p., 2016. Web. 14 Aug. 2016.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









